JMeter(十四)-JMeter后置处理器
十四、JMeter后置处理器
1.简介
后置处理器是在发出“取样器请求”之后执行一些操作。取样器用来模拟用户请求,有时候服务器的响应数据在后续请求中需要用到,我们的势必要对这些响应数据进行处理,后置处理器就是来完成这项工作的。例如系统登录成功以后我们需要获取SessionId,在后面的业务操作中服务器会验证这个SessionId,获取SessionId这个功能过程就可以用后置处理器中的正则表达式提取器来完成。
2.预览后置处理器
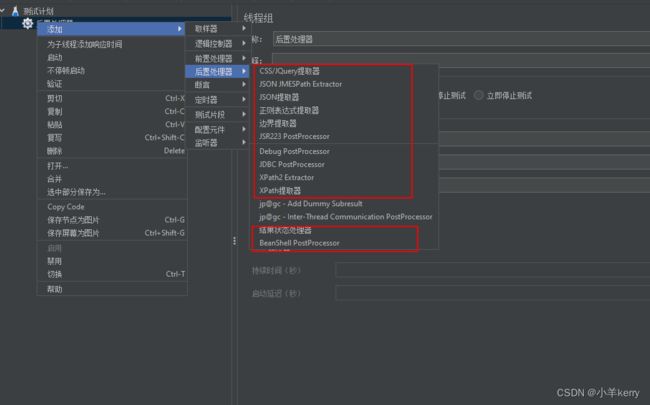
首先我们来看一下JMeter的后置处理器,路径:线程组(用户)->添加->后置处理器();我们可以清楚地看到共有11个后置处理器(不包括jp@gc开头的后置处理器,这个是安装的插件),如下图所示:
3.常用后置处理器详解
3.1CSS/JQuery提取器
CSS/JQuery提取器,是通过css选择器定位页面元素并读取数据 。
3.1.1新建:线程组 > 添加 > 后置处理器 > CSS/JQuery提取器,如下图所示:
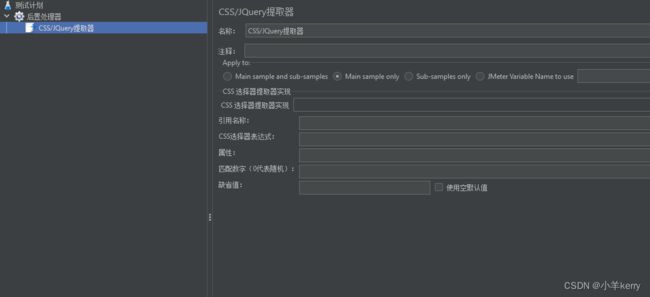
3.1.2关键参数说明如下:
Apply to:
- Main sample and sub-samples 主要样本和子样本
- Main sample only 仅适用于主要样本(默认)
- Sub-samples only 仅适用于子样本
- JMeter Variable Name to use 用作Jmeter变量名称
CSS选择器提取器实现:
- JSOUP:不选时默认为JSOUP
- JODD:JODD格式
引用名称:也就是jmeter里面的变量
CSS选择器表达式:CSS表达式
属性:要提取的元素的属性,提取内容可以不填。示例:蓝色
,那么这里的属性就是value,因为我们要提取blue
匹配数字:0 代表随机取值,n取第几个匹配值,-1匹配所有;比如:取1表示报文中的第1个对象匹配,取2表示报文中的第2个对象匹配)
缺省值:在无法提取内容的情况下放入变量的值。
3.1.3CSS选择器或JQuery选择器是Jmeter支持的两种语法,下面对其两种语法进行简单介绍
CSS选择器
| 选择 |
例 |
选择 |
| .class |
.intro |
All elements with class="intro" |
| #id |
#firstname |
The element with id="firstname" |
| * |
* |
All elements |
| element |
p |
All elements |
| element,element |
div, p |
All elements and all elements |
| element element |
div p |
All elements inside elements |
JQuery选择器
| 选择 |
例 |
选择 |
| * |
$("*") |
All elements |
| #id |
$("#lastname") |
The element with id="lastname" |
| .class |
$(".intro") |
All elements with class="intro" |
| .class,.class |
$(".intro,.demo") |
All elements with the class "intro" or "demo" |
| element |
$("p") |
All elements |
| el1,el2,el3 |
$("h1,div,p") |
All ,elements |
3.1.4实例(提取指定文本)
1、新建测试计划,线程组下添加访问 csdn主页的取样器
2、然后再添加CSS/JQuery提取器,如下图所示
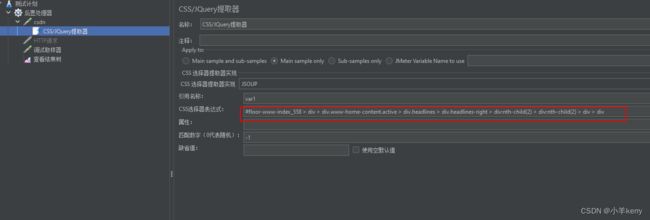
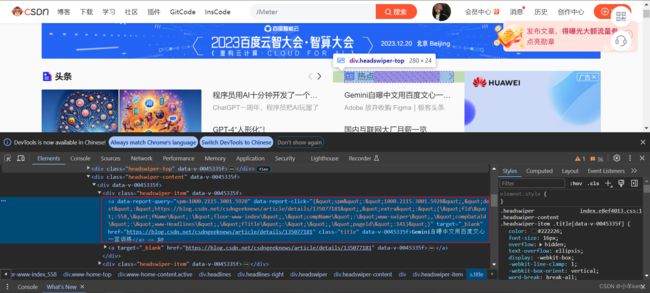
其中CSS选择器表达式就按如下图的方法获取,右键copy>copy selector,如下图所示:
3、接着再添加一个调试取样器 用来确认是否提取到我们要提取的东西
4、配置好以后,运行JMeter,查看结果,如下图所示:
var1_x:可以看到,获取的文本信息
var1_matchNr:统计匹配的个数,如图,一共5个
3.1.5实例(提取指定链接)
1、新建测试计划,线程组下添加访问 csdn首页的取样器
2、然后再添加CSS/JQuery提取器,如下图所示:
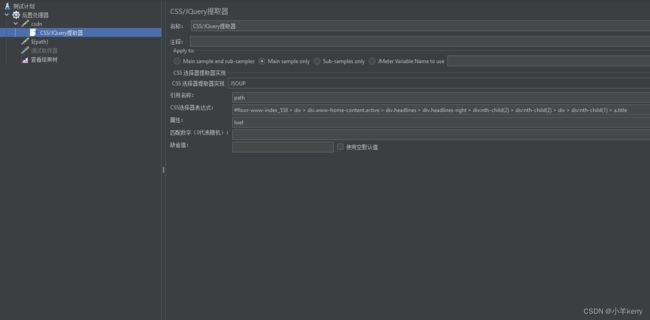
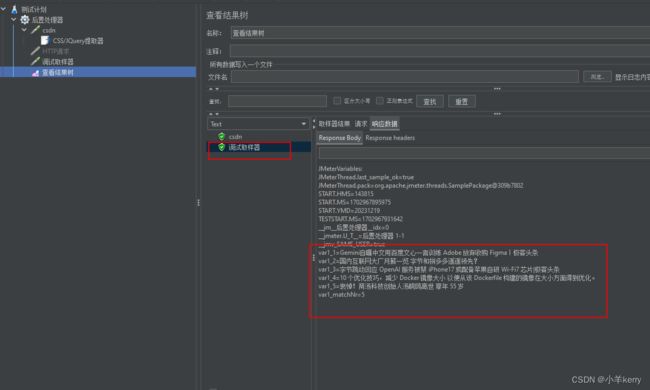
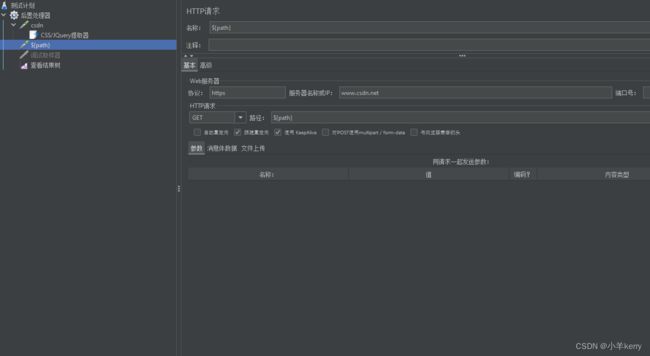
3、接着再添加一个取样器 用来确认是否提取到我们要提取的东西,提取出来的值用来传参,如下图所示:
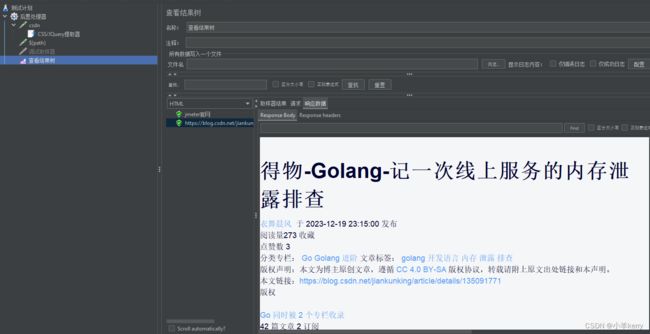
4、配置好以后,运行JMeter,查看结果,如下图所示:
3.1.6实例(随机提取链接)
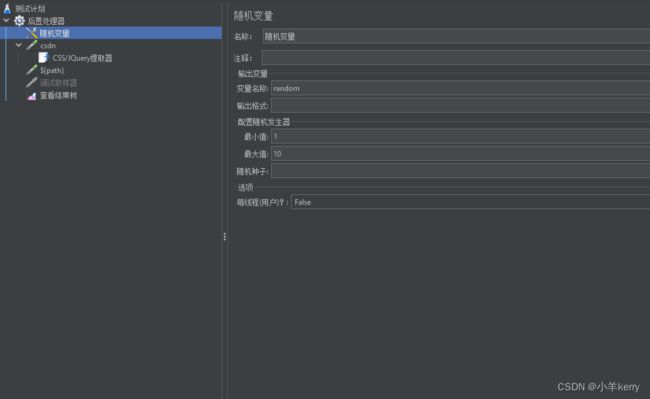
1、新建测试计划,线程组循环5次,添加随机变量和访问 csdn主页的取样器,如下图所示:
随机变量
2、然后再添加CSS/JQuery提取器,如下图所示:
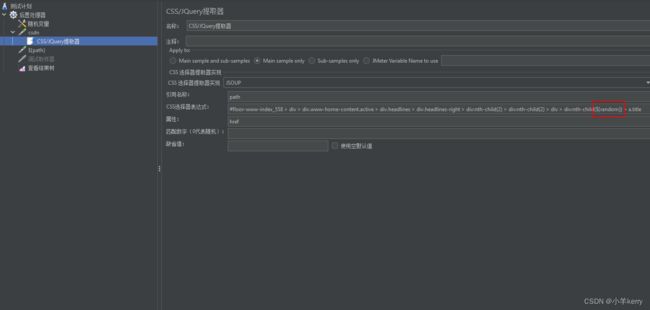
3、接着再添加一个取样器 用来确认是否提取到我们要提取的东西,提取出来的值用来传参
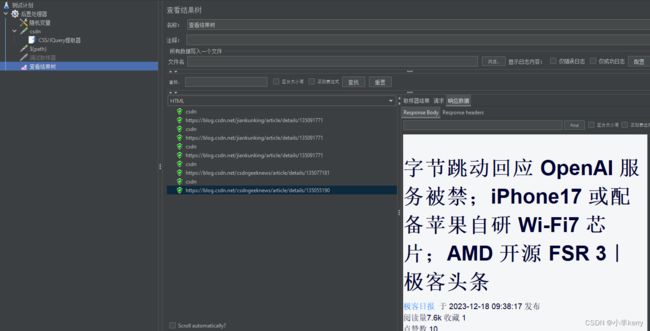
4、配置好以后,运行JMeter,查看结果,如下图所示:
3.2JSON JMESPath Extractor
作为5.2版本之后加入的后置处理器,其功能与JSON提取器类似,都是对JSON格式的返回数据进行提取,但使用的语法不同。JSON JMESPath Extractor使用JMESPath查询语言从Json结果中提取值。
3.2.1新建:线程组 > 添加 > 后置处理器 > JSON JMESPath Extractor,如下图所示:
3.2.2关键参数说明如下:
Apply to(应用范围):
- Main sample and sub-samples:主要样本和子样本
- Main sample only:默认的是这个,应用于主要样本
- Sub-samples only:应用于子样本
- JMeter Variable Name to use:应用于变量命名的内容
- Name of created Variable:保存的变量名,后面使用${Variable names}引用
JSON Path Expression:json表达式
Match No.(0 or Random):匹配的值是哪一个,默认不填写是获取符合条件的第一个,这个与正则表达式的类似(0为随机、N为获取第N个、-1获取所有)
Default Values:当没有获取到参数值时的默认值
3.2.3实例
1、新建测试计划,线程组下添加微博的热搜接口请求,如图所示:

2、然后再在取样器下添加JSON JMESPath Extractor,如下图所示:
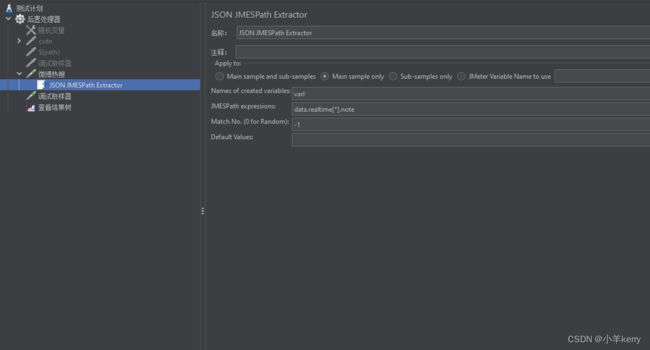
3、取一个调试取样器查看运行结果,如图所示:

3.3JSON提取器
JSON提取器可以使用JSON-PATH语法从JSON格式的响应中提取数据。
该后处理器与正则表达式提取器非常相似。必须将其放置为HTTP Sampler或具有JSON响应的任何其他取样器的子级,可以以非常简单的方式提取JSON文本内容。这里不再进行举例说明。
3.3.1JSON path expression 语法
| JsonPath |
描述 |
| $ |
根节点 |
| @ |
当前节点 |
| .or[] |
子节点 |
| .. |
选择所有符合条件的节点 |
| * |
所有节点 |
| [] |
迭代器标示,如数组下标 |
| [,] |
支持迭代器中做多选 |
| [start:end:step] |
数组切片运算符 |
| ?() |
支持过滤操作 |
| () |
支持表达式计算 |
3.3.2JSON JMESPath Extractor与JsonPath提取器对比
一个JsonPath提取器可以通过 ; 分离的方式,提取多个变量表达式
JSON JMESPath Extractor只支持提取一个变量,如果要提取多个变量,则需要添加多个JSON JMESPath Extractor
JsonPath提取器不支持函数,JSON JMESPath Extractor支持使用函数length()、max_by()、min_by(),可应用于部分特殊场景,所以可以根据场景实际需要,选择要用的提取器类型
3.3.3举例说明
{ “store”:{ “book”:[ { “category”: “reference”, “author”: “Nigel Rees”, “title”: “Sayings of the Century”, “price”: 8.95 }, { “category”: “fiction”, “author”: “Evelyn Waugh”, “title”: “Sword of Honour”, “price”: 12.99 }, { “category”: “fiction”, “author”: “Herman Melville”, “title”: “Moby Dick”, “isbn”: “0-553-21311-3”, “price”: 8.99 }, { “category”: “fiction”, “author”: “J. R. R. Tolkien”, “title”: “The Lord of the Rings”, “isbn”: “0-395-19395-8”, “price”: 22.99 } ], “bicycle”: { “color”: “red”, “price”: 19.95 } }, “expensive”: 10 }
| JSO JMESPath Extractor |
JSON提取器 |
|
| 提取所有书的作者 |
store.book[*].author |
$.store.book[*].author |
| 提取store包含的所有分类数据 |
store.* |
$.store.* |
| 提取所有物品的价格 |
store.[bicycle.price,book[*].price] |
$.store..price |
| 提取第三本书的数据 |
store.book[2] |
$..book[2] |
| 提取倒数第二本书的数据 |
store.book[-2] |
$..book[-2] |
| 提取前两本书的数据 |
store.book[:2] |
$..book[1,2] |
| 提取索引1(包括)到索引2(不包括)的书的数据 |
store.book[1:2] |
$..book[1:2] |
| 提取最后两本书 |
store.book[-2:] |
$..book[-2:] |
| 所有带有isbn属性的书 |
store.book[?(@.isbn)] |
$..book[?(@.isbn)] |
| 所有书种类的数量 |
length(store.book[*]) |
|
| 价格最高的书名 |
max_by(store.book, &price).title |
|
| 价格最低的书信息 |
min_by(store.book, &price) |
|
| 所有价格小于10的书 |
$..book[?(@.price < 10)] |
|
| 所有价格小于属性“expensive”的书 |
$..book[?(@.price |
3.4正则表达式提取器
允许用户使用正则表达式从服务器响应中提取值。作为后处理器,此元素将在其范围内的每个Sample请求之后执行,应用正则表达式,提取请求的值,生成模板字符串,并将结果存储到给定的变量名称中。
3.4.1新建:线程组 > 添加 > 后置处理器 > 正则表达式提取器,如下图所示:
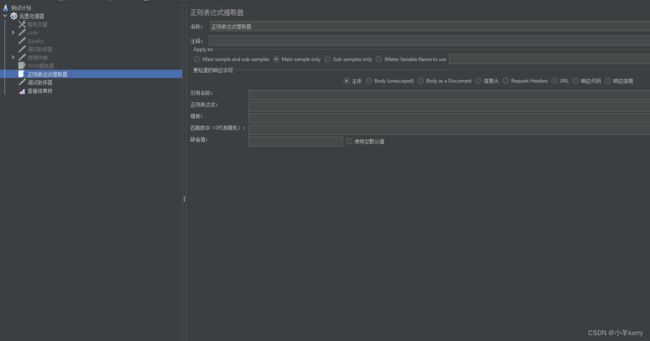
3.4.2关键参数说明如下:
要检查的响应字段:要提取的字段范围
- 主体:响应体,不包含响应头;最常用
- body(unescaped):响应体,替换了所有HTML转义符;不建议使用
- body as a Document:从不同类型的文件中提取文本;影响性能
- 信息头:响应头
- Requeste Headers:请求头
- URL:URL
- 响应代码:响应码(Response code)
- 响应信息:响应信息(Response message)
引用名称:接收提取值的变量名,*必传
正则表达式:正则表达式
模板:从找到的匹配项中创建字符串的模板
如果一条正则表达式有多个提取结果,则提取结果是数组形式,模板1、2…表示把解析到的第几个值赋值给变量,从1开始匹配,0表示整个表达式匹配的内容,若只有一个结果,只能是1
匹配数字(0代表随机):取第几个值(0:随机,默认;-1所有;1第一个值),非必传
缺省值:缺省值,匹配不到值的时候取该值,非必传
使用空默认值:勾选后,提取不到值时,则返回空字符串
3.4.3实例
1、新建测试计划,线程组下添加百度取样器
2、使用正则表达式提取器提取度娘取样器响应中(百度一下,你就知道),如下图所示:
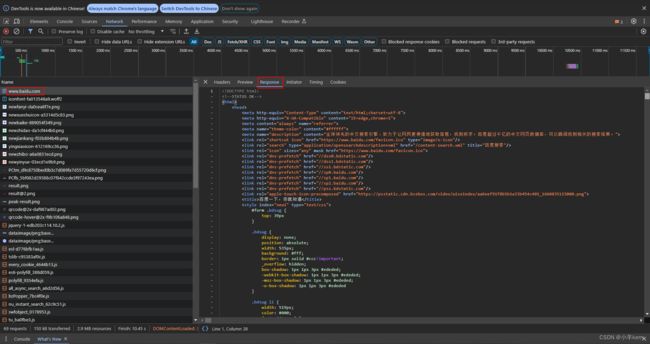
3、然后再在取样器下添加正则表达式提取器,如下图所示:
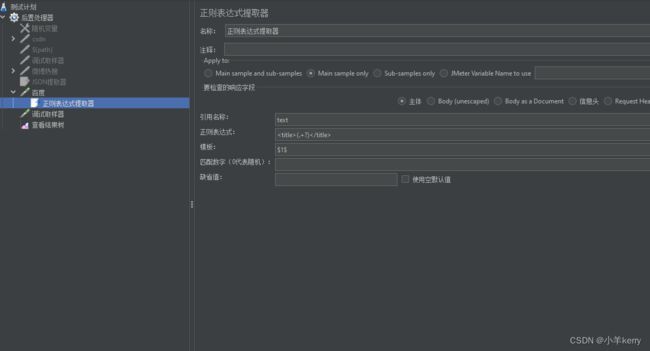
说明:
(1)引用名称:下一个请求要引用的参数名称,如填写title,则可用${title}引用它。
(2)正则表达式:
():括起来的部分就是要提取的。
.:匹配任何字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
4、紧接着再添加一个调试取样器 用来查看结果
5、配置好以后,运行JMeter,查看表格结果,如下图所示:
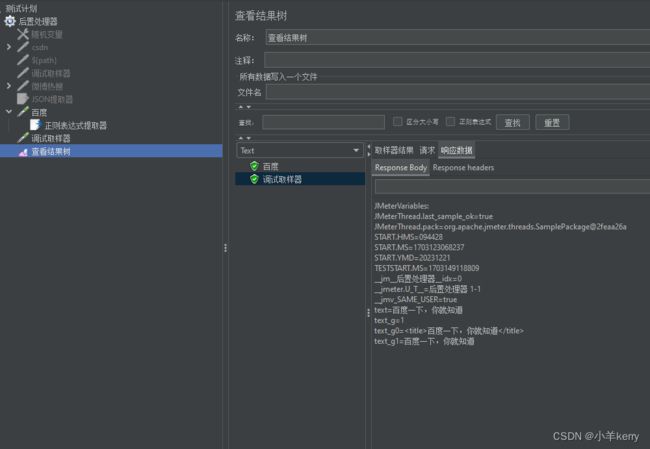
3.5边界提取器
边界提取器,使用JMeter5.0的边界提取器,不需要写复杂的正则表达式,只要填写左右边界即可,我们想从接口中提取一些想用的东西,不习惯用正则提取器和json提取器,可以使用边界提取器,相对前者较简单些。它通过左右边界来提取需要的内容,它可以匹配任何格式的内容,如文本、json、xpath、html等等,使用也很简单,分别填写要提取内容的左右边界即可,很灵活。
3.5.1新建:线程组 > 添加 > 后置处理器 > 边界提取器,如下图所示:
2、关键参数说明如下:
Apply to(应用范围):
Main sample and sub-samples:主要样本和子样本
Main sample only:默认的是这个,应用于主要样本
Sub-samples only:应用于子样本
JMeter Variable Name to use:应用于变量命名的内容
Name of created Variable:保存的变量名,后面使用${Variable names}引用
要检查的响应字段:要提取的字段范围
- 主体:响应体,不包含响应头;最常用
- body(unescaped):响应体,替换了所有HTML转义符;不建议使用
- body as a Document:从不同类型的文件中提取文本;影响性能
- 信息头:响应头
- Requeste Headers:请求头
- URL:URL
- 响应代码:响应码(Response code)
- 响应信息:响应信息(Response message)
引用名称:请求要引用的变量名称,如填写 result_num
左边界:要匹配的左边界值
右边界:要匹配的右边界值
Match No.(0 or Random):匹配的值是哪一个,默认不填写是获取符合条件的第一个,这个与正则表达式的类似(0为随机、N为获取第N个、-1获取所有)
Default Values:当没有获取到参数值时的默认值
3.5.3实例
1、新建测试计划,线程组下添加百度取样器
2、使用边界提取器提取度娘取样器响应中(百度一下,你就知道)
3、然后再在取样器下添加边界提取器,如下图所示:
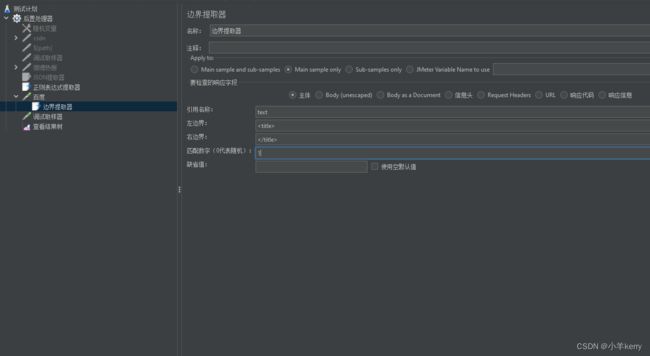
说明:
(1)Apply to:选Main sample only。
(2)要检查的响应字段:选主体。
(3)引用名称:提取出来参数引用的名称。
(4)提取值左边界 :要匹配的左边界值。
(5)提取值右边界 :要匹配的右边界值。
(6)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
(7)缺省值:如果参数没有取得到值,那默认给一个值让它取。
3、紧接着再添加一个调试取样器 用来获取结果
4、配置好以后,运行JMeter,查看表格结果,如下图所示:
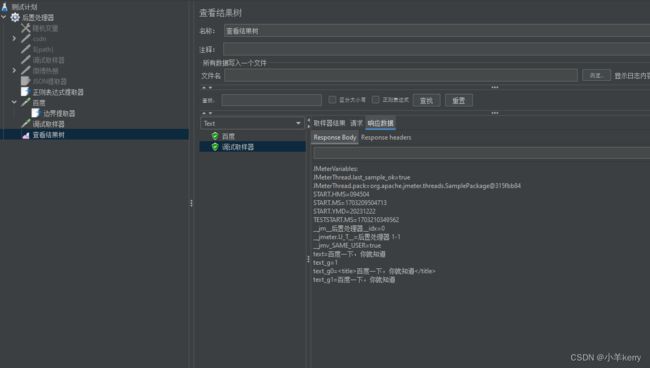
3.6JSR223 后置处理程序
JSR223后置处理程序,用法和JSR223 PreProcessor类似,可以参考:JMeter(十三)-JMeter前置处理器
3.6.1新建:线程组 > 添加 > 后置处理器 > JSR223 后置处理程序,如下图所示:
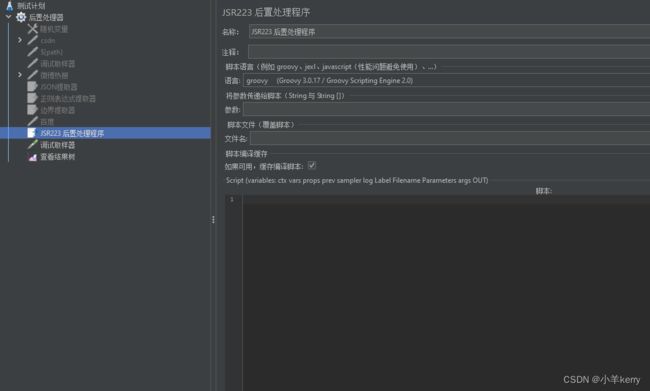
3.6.2关键参数说明如下:
参数:要传递到脚本文件或脚本的参数列表;
文件名:用于执行的脚本文件,若没有脚本文件,将执行脚本;
Script:传递给JSR223执行的脚本;如果提供了脚本文件,则执行脚本文件,否则执行脚本。
3.7调试后置处理程序
调试后置处理程序,使用正则表达式为从另一个HTTP请求中提取的HTTP参数指定动态值,配合regular expression extractor使用。暂时没找到好的例子,后面想到补充。。
3.7.1新建:线程组 > 添加 > 后置处理器 > 调试后置处理程序,如下图所示:
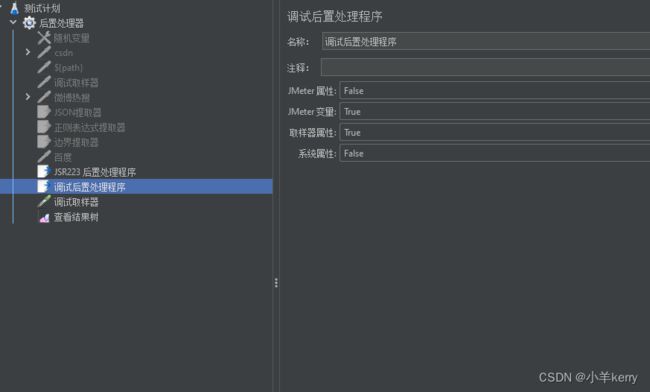
3.7.2关键参数说明如下:
JMeter 属性:jmeter.properties定义的系统级的属性变量。因其变化不大,所以脚本调试时通常不显示,默认False(不显示)
JMeter 变量:JMeter中定义的变量。常用的四种变量定义可参考文章:JMeter常见四种变量简介,默认为True(显示)
取样器属性:样本属性及变量信息。默认为True(显示)
系统属性:系统配置的环境变量等。若系统环境变量在当前脚本中有用到,可以设置为True(显示),默认为False(不显示)
3.7.3实例
1、新建测试计划,线程组下添加调试取样器,如下图所示:
3、然后再在取样器下添加调试后置处理程序,如下图所示:
4、配置好以后,运行JMeter,查看表格结果,如下图所示:

如图,响应数据,响应体中获取到了 JMeter 变量。JMeterVariables
调试取样器中,只有JMeter 变量选了 True,所以只获取 JMeter 变量
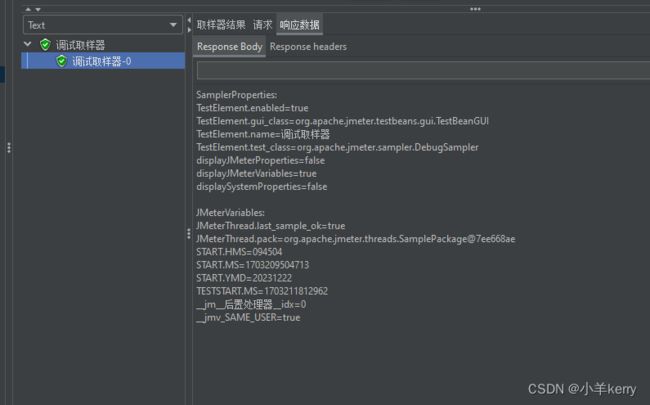
如图,这个调试取样器-0获取到的就是调试后置处理程序
如图,响应数据,响应体中获取到了取样器属性和 JMeter 变量。SamplerProperties、JMeterVariables
调试后置处理程序中,只有JMeter 变量和取样器属性选了 True,所以只获取 JMeter 变量和取样器属性
3.8JDBC 后置处理程序
JDBC 后置处理程序,实际上JIBC PostProcessor就是一个JDBC Request,它与JDBC Request功能相同,都可以执行SQL语句。在测试的过程中可能会遇到这样的测试场景:我们用JDBC Request修改了一些数据,当测试完成后,我们希望还原到原先状态,此时我们可以用JDBC PostProcessor来完成,当然用JDBC Request也可以完成。具体的JDBC PostProcessor的使用参考:JMeter(六)-建立数据库测试计划实战。
3.8.1新建:线程组 > 添加 > 后置处理器 > JDBC 后置处理程序,如下图所示:

3.9XPath2 Extractor
Xpath2提取器,虽然JMeter官方文档说可以使用XPath2查询语言从结构化响应(XML或(X)HTML)中提取值,但目前测试只支持从XML响应中提取值;从HTML中提取会报错,这个可以通过查看结果树中选择XPath2 Tester来验证。
3.9.1新建:线程组 > 添加 > 前置处理器 > Xpath2提取器,如下图所示:

3.9.2关键参数说明如下:
APPly to:作用范围(返回内容的断言范围)
- Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
- Main sample only:仅作用于父节点的取样器
- Sub-samples only:仅作用于子节点的取样器
- JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
引用名称:存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。
Match No 匹配数字:取第几个匹配结果,0随机,-1全部,1代表第一个,2代表第二个,....以此类推
Default Value:参数的默认值。
Namespaces aliases list:命名空间别名列表。就是这个功能,能让使用命名空间比使用旧的XPath提取器更方便。关于命名空间含义,可以看官方文档:XML命名空间。由于XPath2对于表达式的要求比较严格,对于带命名空间的XML(包括默认的命名空间),使用不带命名空间前缀的表达式是查询不到结果的。
Return entire XPath fragment of text content:返回文本内容的整个XPath片段。
3.10XPath提取器
Xpath提取器,如果请求返回的消息为xml或html格式的,可以用XPath提取器来提取需要的数据。
3.10.1新建:线程组 > 添加 > 后置处理器 > Xpath提取器,如下图所示:
3.10.2关键参数说明如下:
APPly to:作用范围(返回内容的断言范围)
- Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
- Main sample only:仅作用于父节点的取样器
- Sub-samples only:仅作用于子节点的取样器
- JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:要解析的XML参数
- UseTidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
- Quiet表示只显示需要的HTML页面
- 报告异常表示显示响应报错
- 显示警告;
- Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
- Validate XML:根据页面元素模式进行检查解析;
- Ignore Whitespace:忽略空白内容;
- Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
引用名称:存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。语法参考:XPath
匹配数字:取第几个匹配结果,0随机,-1全部,1代表第一个,2代表第二个,....以此类推
Default Value:参数的默认值。
xpath语法参考:xpath语法
3.10.3实例
1、新建测试计划,线程组下添加1个取样器 csdn首页
2、返回HTML,然后再添加xpath提取器,如下图所示:
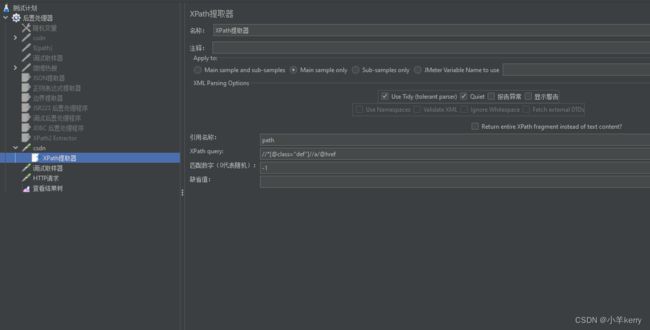
举例://*[@class="def"]//a/@href
选取带有class属性为de的href属性节点。 注释://*选取文档中的所有元素。 @选取属性 /@href 从根节点选取所有的href属性
Xpath提取器设置
3、继续添加调试取样器、http请求,获取xpath提取到的参数,如下图所示:
4、配置好以后,运行JMeter,查看表格结果,如下图所示:
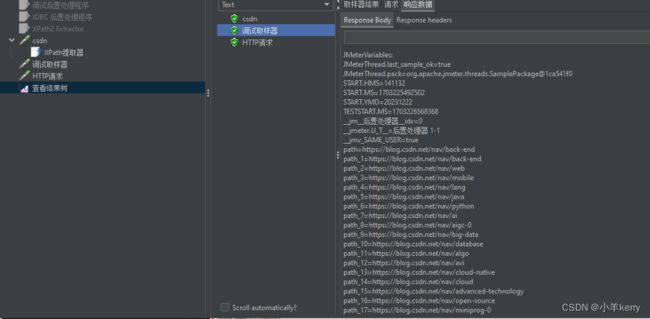
调试取样器:
http请求:
3.11结果状态处理器
结果状态处理器,实际上在测试的时候我们也经常会遇到这样的测试场景:在一些测试用例失败之后我们需要进行一些操作,例如停止测试,这里可以使用结果状态处理器。
3.9.1新建:线程组 > 添加 > 后置处理器 > 结果状态处理器,如下图所示:
2、关键参数说明如下:
在取样器错误后要执行的动作:
- 继续:忽略错误继续执行。
- Break Current Loop:跳出当前迭代
- 启动下一进程循环:本次线程不执行,开始执行下一个线程迭代
- Go to the next iteration of Current Loop:继续当前线程的下一个迭代,报错后,本次迭代不执行,执行本线程的下一个迭代
- 停止测试:执行完本次迭代,再停止测试
- 立即停止测试:立刻停止线程组
- 停止线程:将异常的线程移出线程组,不再执行,其他线程继续执行。
3.12BeanShell 后置处理程序
BeanShell 后置处理程序,用法和BeanShell PreProcessor类似,可以参考:JMeter(十三)-JMeter前置处理器
BeanShell 后置处理程序,如果请求返回的消息为xml或html格式的,可以用XPath2提取器来提取需要的数据。这个估计是JMeter5.0新加的吧,具体用法和Xpath提取器的应该差不多的,可以参考上边Xpath提取器的用法。
3.12.1新建:线程组 > 添加 > 后置处理器 > BeanShell 后置处理程序,如下图所示:
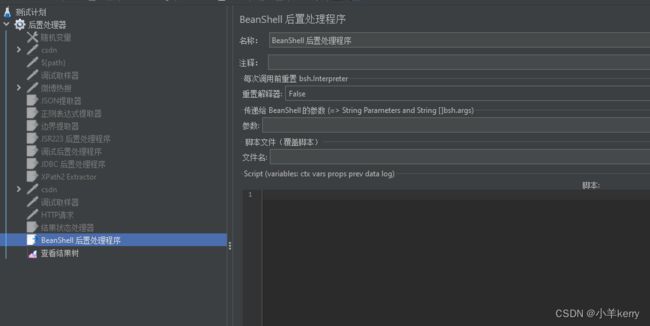
3.12.2关键参数说明如下:
重置解释器: 每次迭代是否重置解释器
参数:传递给脚本的参数;
文件名:本地开发的脚本文件(会覆盖在JMeter里编写的脚本);
Script:要运行脚本。编写脚本的区域。