基于docker-compose快速搭建Prometheus+Grafana监控系统
前言
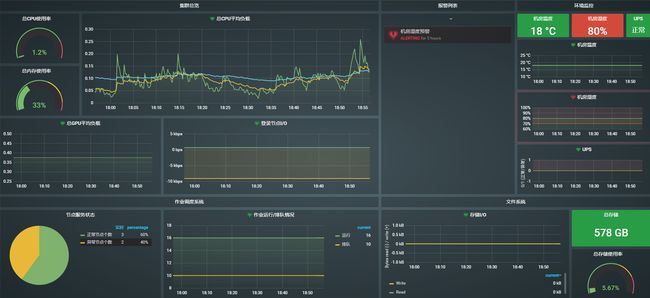
先附两张使用Prometheus+grafana+node-exporter方案搭建的监控环境的实际效果图:
- CPU资源总览+CPU资源监控
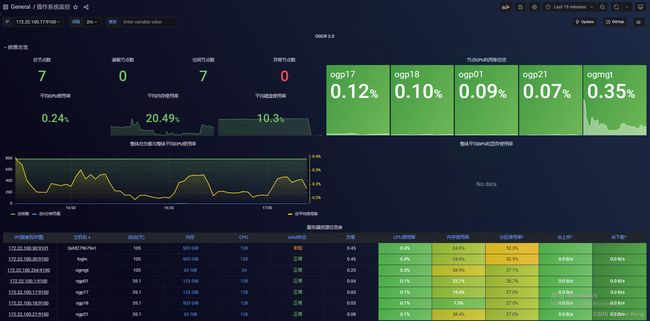
- 系统总览监控
监控领域虽有类似Zabbix等强大的监控工具,但是在一些实际场景下总是感觉还是太重了,且对二开的支持也不够友好,无法灵活适应HPC环境下较为多变的需求和场景,而Prometheus+grafana+node-exporter相对来说更轻量,更灵活,只需要简单的搭建即可实现所需效果,且默认支持特定格式的自研数据采集,通过grafana强大的panel开放设计能力,能较好地支持各类实际场景,本篇我们介绍下如何通过docker-compose快速搭建一个Prometheus+grafana+node-exporter架构的基本监控系统。
一、基本概念介绍
1.1 简介
Prometheus 负责数据收集处理,Grafana 负责前台展示数据。其中采用 Prometheus 中对接的各 Exporter 包含:
- Node Exporter(核心组件),负责收集所属节点的硬件和操作系统数据,可外挂客制化收集数据文件。它将以容器方式运行在所有节点上;
- 其他各专属类型Exporter,例如上篇介绍的HPC高性能计算环境下,有针对调度系统专用的Exporter;
- Alertmanager(可选组件),负责告警,它将以容器方式运行在所有节点上;
- 其他组件,如cadvisor监控容器等
1.2 界面展示示意
让我们通过以下截图进一步了解各个组件:
-
Prometheus

-
Node-exporter

-
Grafana
二、安装 docker和docker-compose
2.1 安装 docker
教程较多,这里采用的常见安装方式:
# 安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加Docker软件包源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 安装Docker CE
yum install docker-ce -y
# 启动
systemctl start docker
# 开机启动
systemctl enable docker
# 查看Docker信息
docker info
2.2 安装 docker-compose
# 直接下载到/usr/local/bin/下即可
curl -L https://github.com/docker/compose/releases/download/1.25.4/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
# 这是一个基于python编写的可执行脚本文件,下载后需要赋予可执行权限,运行需要依赖python环境
chmod +x /usr/local/bin/docker-compose
2.3 添加配置文件
mkdir -p /usr/local/src/config
cd /usr/local/src/config
2.4 添加 prometheus.yml 配置文件
# 添加 prometheus.yml 配置文件
vim prometheus.yml
prometheus.yml 文件示例如下:
本例中,192.168.0.106 为部署主机的 ip,其他 ip 为局域网其他节点(如需监控,需自行安装 Node-exporter,默认情况可通过 docker 安装)
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.0.106:9093']
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.0.106:9090']
- job_name: 'cadvisor'
static_configs:
- targets: ['192.168.0.106:8080']
# 以下为各节点类型分组
# 管理节点组
- job_name: 'mgt'
scrape_interval: 8s
static_configs:
- targets: ['192.168.0.106:9100']
# IO存储节点组
- job_name: 'io'
scrape_interval: 8s
static_configs:
- targets: ['192.168.0.176:9100']
# 登录节点组
- job_name: 'login'
scrape_interval: 8s
static_configs:
- targets: ['192.168.0.186:9100']
# 计算节点组
- job_name: 'cal'
scrape_interval: 8s
static_configs:
# 可添加多个target
- targets: ['192.168.0.109:9100']
- targets: ['192.168.0.83:9100']
- targets: ['192.168.0.93:9100']
2.5 添加邮件告警配置文件
添加配置文件 alertmanager.yml,配置收发邮件邮箱
vim alertmanager.yml
global:
smtp_smarthost: 'smtp.163.com:25' #163服务器
smtp_from: '[email protected]' #你的发邮件的邮箱
smtp_auth_username: '[email protected]' #你的发邮件的邮箱用户名,也就是你的邮箱
smtp_auth_password: '*********' #发邮件的邮箱密码
smtp_require_tls: false #不进行tls验证
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: live-monitoring
receivers:
- name: 'live-monitoring'
email_configs:
- to: '[email protected]' #收邮件的邮箱
2.3 添加报警规则
添加一个 node_down.yml 为 prometheus targets 监控
vim node_down.yml
groups:
- name: node_down
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
user: test
annotations:
summary: 'Instance {{ $labels.instance }} down'
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes.'
四、编写 docker-compose
vim docker-compose-monitor.yml
注意:下述只是早期一个示例,具体需要根据每个环境自行调整,包括节点组、节点信息等关键配置
version: '2'
networks:
monitor:
driver: bridge
services:
# 核心组件
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
volumes:
- /usr/local/src/config/prometheus.yml:/etc/prometheus/prometheus.yml
- /usr/local/src/config/node_down.yml:/etc/prometheus/node_down.yml
ports:
- '9090:9090'
networks:
- monitor
# 告警组件
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: always
volumes:
- /usr/local/src/config/alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- '9093:9093'
networks:
- monitor
# 前端展示
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
ports:
- '3000:3000'
networks:
- monitor
# 节点监控
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
ports:
- '9100:9100'
networks:
- monitor
# 容器监控
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- '8080:8080'
networks:
- monitor
五、启动 docker-compose#启动容器:
# 使用docker-composer命令启动yml里配置好的各容器
docker-compose -f /usr/local/src/config/docker-compose-monitor.yml up -d
# 删除容器:
docker-compose -f /usr/local/src/config/docker-compose-monitor.yml down
#重启容器:
docker restart id
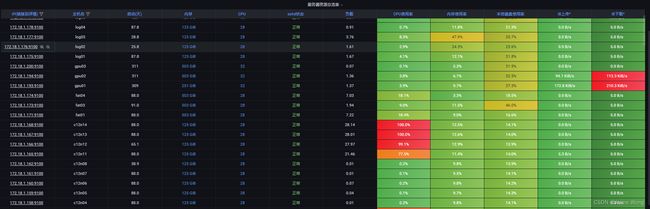
再附几张实际场景示例:
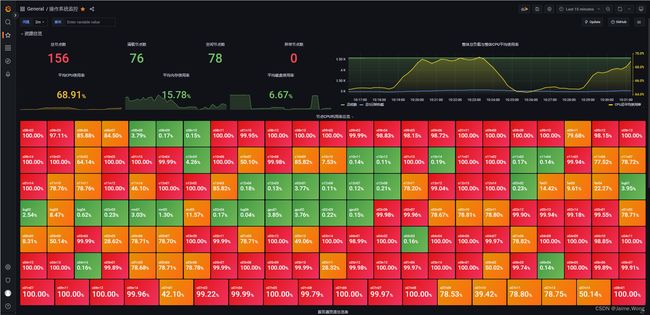
- 服务器节点列表及资源监控
- 用户登录情况监控
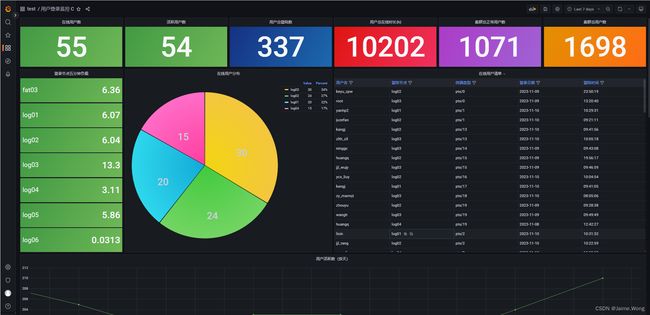
以上即为通过 docker-composer 快速搭建监控系统的简单介绍。
下一篇我们将介绍基于实际场景的grafana二次开发重新封装打包,及数据采集自研开发。
【星猿科技】:在这里我们共同探索科技新趋势,分享积累的点滴,从人工智能到高性能计算,我们追求技术的进步,同时珍视分享的力量。欢迎关注我们,在科技与影视的精彩世界中一起遨游,发现更多未知!