Slurm作业调度系统的简介及基本使用
文章目录
- 1. Slurm简介
- 2. Slurm使用
-
- 2.1 查看节点与分区
-
- 2.1.1 管理分区与节点的状态 – sinfo
- 2.1.2 查看配置
- 2.1.3 查看分区
- 2.1.4 查看节点
- 2.1.5 查看作业
- 2.1.6 查看队列
- 2.2 管理作业
-
- 2.2.1 提交单个作业 srun
- 2.2.2 提交脚本
- 2.2.3 作业跟踪
- 2.2.4 更新任务
- 2.2.5 取消作业 scancel
- 3. Slurm配置文件
-
- 配置文件结构
- 编辑配置文件
- 示例
1. Slurm简介

Slurm是一个广泛使用的开源作业调度系统,专为Linux集群设计,无论是大型还是小型。它的主要优点在于其开源性质、容错能力和高度可伸缩的架构。与其他作业调度系统(如IBM的LSF和PBS)相比,Slurm的一个显著特点是它不需要修改操作系统内核,使其更易于集成和使用。
在高性能计算(HPC)领域,Slurm被广泛用于管理集群资源和调度作业。不同于在登录节点上执行任务,Slurm允许用户将计算任务提交到专门的计算节点上。这样不仅提高了资源的使用效率,还保证了任务的有效管理和调度。由于Slurm的开源特性,它为学术界和工业界提供了灵活性和可定制性,使其成为HPC资源管理的首选工具之一。
本文旨在为初学者提供Slurm的基础使用指南,从基本概念到实际命令,帮助您快速上手并有效利用Slurm进行作业调度。
2. Slurm使用
2.1 查看节点与分区
2.1.1 管理分区与节点的状态 – sinfo
在Slurm中,您可以通过 sinfo 命令来查看集群中的节点和分区信息。这个命令会显示节点的状态、分区名、可用性等重要信息,帮助您了解当前集群的状态。例如,输入 sinfo 可以获得集群中各个节点的详细信息。

进阶用法(格式化输出):
sinfo -N -o "%8P %3N %.6D %.11T %12C %.8z %.6m %.8d %.6w %.8f %20E"

2.1.2 查看配置
scontrol show config
2.1.3 查看分区
scontrol show partition
2.1.4 查看节点
scontrol show node
2.1.5 查看作业
# 查看所有作业
scontrol show jobs
# 查看具体某个作业
scontrol show job jobid
2.1.6 查看队列
squeue -a
2.2 管理作业
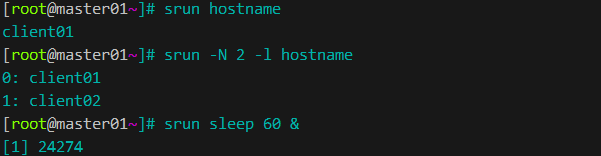
2.2.1 提交单个作业 srun
2.2.2 提交脚本
Slurm允许您使用 sbatch 命令提交脚本作业。例如,要提交一个名为 job_script.sh 的作业脚本,您可以使用命令 sbatch job_script.sh。这个脚本应包含Slurm能够理解的作业指令和执行的命令
vim run.slurm,内容如下:
#!/bin/bash
#SBATCH -J test_2023-03-22
#SBATCH --cpus-per-task=1
#SBATCH -N 1
#SBATCH -t 3:00
sleep 100
echo test_2021-03-22
chmod 775 run.slurm
sbatch run.slurm
![]()
注:
- 指定运行节点: –nodelist=g03
- 更多参数说明:SLURM sbatch官网文档
2.2.3 作业跟踪
要查看您提交的作业的状态,可以使用 squeue 命令。这个命令提供了作业的队列状态、运行状态等信息。通过 squeue,您可以实时监控作业的执行情况。
# 查看某个作业,须知道jobid
scontrol show job ${JOBID}
# 查看某用户的作业
squeue -u ${USERNAME}
2.2.4 更新任务
我们可以使用scontrol update选项来更新已提交的作业,示例如下:
# 使用方法:
scontrol update jobid=${JOBID} <TAB> <TAB>
# 举例:
scontrol update jobid=938 partition=gpu gres=gpu:1
2.2.5 取消作业 scancel
如果您需要取消一个已经提交的作业,可以使用 scancel 命令。通过指定作业ID,您可以轻松地停止作业的执行。例如,如果要取消作业ID为123的作业,您可以使用 scancel 123 命令。
# 取消具体某作业id对应作业
scancel ${jobid}
# 取消某用户的作业
scancel -u ${username}
3. Slurm配置文件
Slurm的配置文件是Slurm集群管理的核心,通常名为slurm.conf。这个文件位于Slurm安装目录的etc子目录下 /etc/slurm/slurm.conf。 配置文件中包含了集群的重要设置,如节点定义、分区配置、调度策略等。
配置文件结构
Slurm配置文件通常包含以下几个关键部分:
- 控制节点:定义Slurm控制守护进程的主机。
- 计算节点:定义集群中的计算节点及其属性。
- 分区:定义作业分区,用于组织和管理作业队列。
- 调度策略:设置作业调度的参数和策略。
编辑配置文件
编辑配置文件时,需要具备管理员权限。修改配置后,通常需要重启Slurm守护进程以应用更改。为确保配置的正确性,建议在修改前备份原始文件。
例如,您可以通过以下命令编辑配置文件:
sudo vim /etc/slurm/slurm.conf
示例
以下是一个简单的配置文件示例:
#
# Example slurm.conf file. Please run configurator.html
# (in doc/html) to build a configuration file customized
# for your environment.
#
#
# slurm.conf file generated by configurator.html.
#
# See the slurm.conf man page for more information.
#
ClusterName=develop
ControlMachine=master01
ControlAddr=10.10.12.10
#BackupController=
#BackupAddr=
#
SlurmUser=root
SlurmdUser=root
SlurmctldPort=6817
SlurmdPort=6818
AuthType=auth/munge
#JobCredentialPrivateKey=
#JobCredentialPublicCertificate=
StateSaveLocation=/var/spool/slurm/ctld
SlurmdSpoolDir=/var/spool/slurm/d
SwitchType=switch/none
MpiDefault=none
SlurmctldPidFile=/var/run/slurmctld.pid
SlurmdPidFile=/var/run/slurmd.pid
ProctrackType=proctrack/pgid
#PluginDir=
#FirstJobId=
ReturnToService=2
#MaxJobCount=
#PlugStackConfig=
#PropagatePrioProcess=
#PropagateResourceLimits=
#PropagateResourceLimitsExcept=
#Prolog=
#Epilog=
#SrunProlog=
#SrunEpilog=
#TaskProlog=
#TaskEpilog=
#TaskPlugin=
#TrackWCKey=no
#TreeWidth=50
#TmpFS=
#UsePAM=
#
# TIMERS
SlurmctldTimeout=300
SlurmdTimeout=300
InactiveLimit=0
MinJobAge=300
KillWait=30
Waittime=0
#
# SCHEDULING
SchedulerType=sched/backfill
#SchedulerAuth=
#SelectType=select/linear
FastSchedule=1
#PriorityType=priority/multifactor
#PriorityDecayHalfLife=14-0
#PriorityUsageResetPeriod=14-0
#PriorityWeightFairshare=100000
#PriorityWeightAge=1000
#PriorityWeightPartition=10000
#PriorityWeightJobSize=1000
#PriorityMaxAge=1-0
#
# LOGGING
SlurmctldDebug=3
SlurmctldLogFile=/var/log/slurmctld.log
SlurmdDebug=3
SlurmdLogFile=/var/log/slurmd.log
#JobCompType=jobcomp/none
#JobCompLoc=
#
# ACCOUNTING
#JobAcctGatherType=jobacct_gather/linux
#JobAcctGatherFrequency=30
#
#AccountingStorageType=accounting_storage/slurmdbd
#AccountingStorageHost=
#AccountingStorageLoc=
#AccountingStoragePass=
#AccountingStorageUser=
#
AccountingStorageTRES=gres/gpu
DebugFlags=CPU_Bind,gres
AccountingStorageType=accounting_storage/slurmdbd
AccountingStorageHost=slurmmaster
AccountingStorageLoc=slurm
AccountingStoragePort=7031
AccountingStoragePass=/var/run/munge/munge.socket.2
AccountingStorageUser=slurm
# COMPUTE NODES
NodeName=master01 NodeAddr=10.10.12.10 CPUs=2 Procs=1 State=UNKNOWN
NodeName=client01 NodeAddr=10.10.12.11 CPUs=2 Procs=1 State=UNKNOWN
NodeName=client02 NodeAddr=10.10.12.12 CPUs=2 Procs=1 State=UNKNOWN
PartitionName=control Nodes=master01 Default=YES MaxTime=INFINITE State=UP
PartitionName=compute Nodes=client01,client02 Default=YES MaxTime=INFINITE State=UP
JobCompHost=127.0.0.1
JobCompLoc=mysql
JobCompPass=147258
JobCompPORT=3306
JobCompType=jobcomp/mysql
JobCompUser=root
在此示例中,定义了一个名为master01的控制节点,2个计算节点(client01到client02),以及一个名为compute的队列分区。
【星猿科技】:在这里我们共同探索科技新趋势,分享积累的点滴,从人工智能到高性能计算,我们追求技术的进步,同时珍视分享的力量。欢迎关注我们,在科技与影视的精彩世界中一起遨游,发现更多未知!