Json和Xml
一、前言
学习心得:C# 入门经典第8版书中的第21章《Json和Xml》
二、Xml的介绍
Xml的含义:
可标记性语言,它将数据以一种特别简单文本格式储存。让所有人和几乎所有的计算机都能理解。
XML文件示例:
C# 入门经典
C# 高级编程
C# 深入解析
WPF 编程宝典
提示:
节点:在Xml文件中有多个节点,节点就是<节点>:用来声明一个节点 结束当前节点。如果在当前的节点中创建了节点那么就是称呼为给当前的节点创建了一个子节点。元素和特性可以统称为节点。
元素:元素的含义是指<>这样的标签。
特性:特性指某某元素的特性。如上述 Time 就是 Csharp的特性
三、Json的介绍
Json的含义:
Json在我们C#开发当中会使用到的第二种数据语言。它主要使用在Wen服务中和Wen浏览器中。
Json文件示例:
{
"?xml": {
"@version": "1.0",
"@encoding": "utf-8"
},
"Books": {
"CSharp": {
"@Time": "2019",
"book": [ "C# 入门经典", "C# 高级编程", "C# 深入解析", "WPF 编程宝典" ]
},
"Java": ""
}
}示例解释:Json中使用{}表示数据块, 逗号分隔数据。[]为鉴定为数组。 冒号指定当前元素的值
提示:当前的Json示例与上面Xml示例存储的数据是一致的。
四、Xml 模式介绍和创建
1 Xml 模式的介绍
Xml模式是指在我们创建Xml文档时对文档的一种格式规范,使当前Xml文档不会出现不打算处理的数据。C#使用的标准模式xml格式时XSD(XML Schema Definition)
2 Xml 模式的创建
上述介绍可能不太能理解,我们创建一下就能理解了。共三步
2.1 打开Visual Studio 创建Xml文件
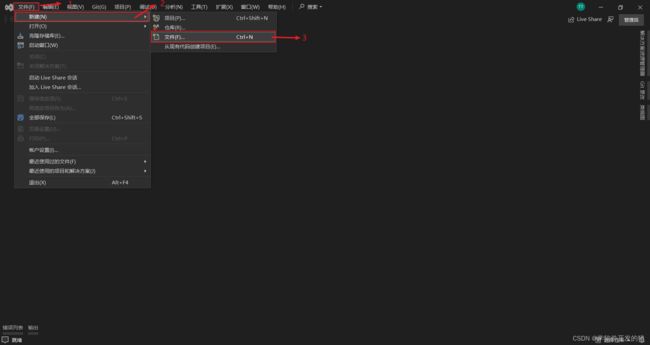

看到下面的页面则代表创建成功了
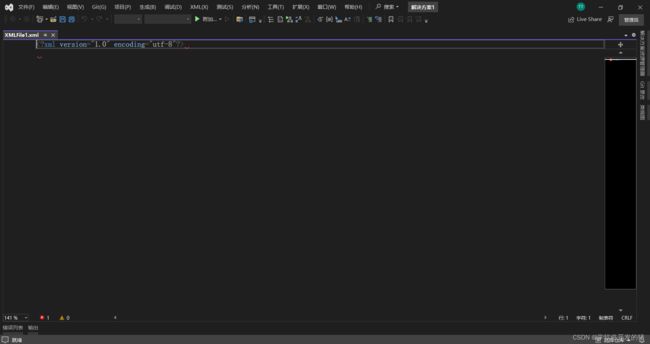
2.2 输入想要的Xml格式。(创建一个规范的Xml格式)
示例:
保存
 输入保存的名字以及路径
输入保存的名字以及路径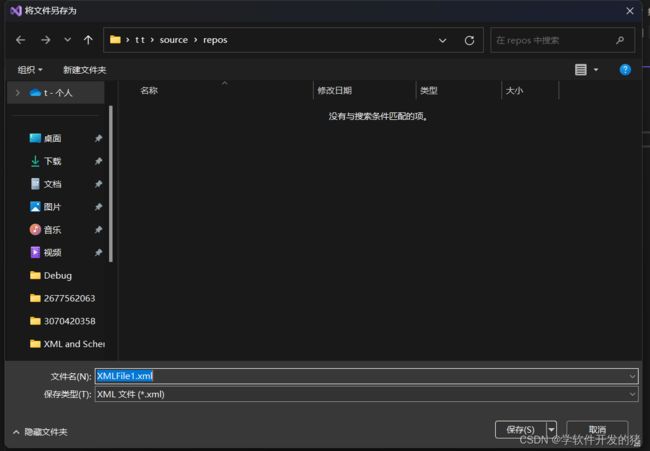
2.3 创建XML模式(XML架构)

随后编译器为我们生成了一个Xsd后缀的一个文件
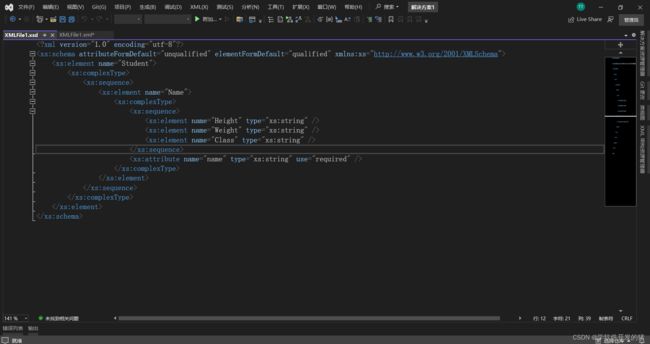 一样的将当前文件保存。
一样的将当前文件保存。
 创建结束(创建了一个StudentXml 模式)
创建结束(创建了一个StudentXml 模式)
3 Xml 文件模式使用
将上面我们创建的模式使用起来
3.1 先创建一个Xml文件(同样的方式)
3.2 指定使用的模式(使用的架构)
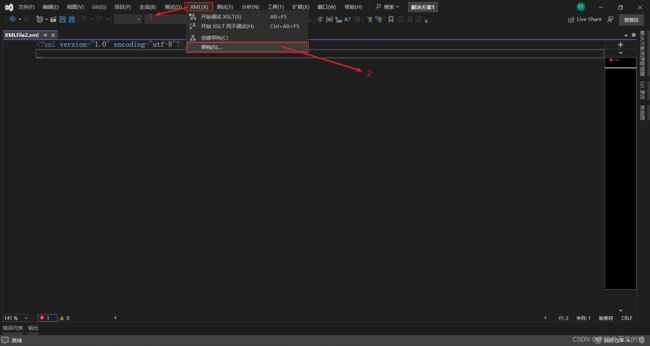
 如果表格中没有您创建的架构可以,在右侧添加。
如果表格中没有您创建的架构可以,在右侧添加。
3.3 使用Xml模式(架构)
在我们输入的时,智能提示就显示了我们之前的格式,可以帮助我们快速创建一个刚刚一样格式的Xml文件。

示例:
188
75kg
1805
注意:如果您添加我们模式中没有的节点我们的编译器会报警告。

提示:如果您需要反复使用当前的模式建议把当前模式添加到Visual Studio中的XML架构中
五、读取和处理Xml文件
1 访问和处理Xml文件的类
| 类名 | 描述 |
|---|---|
| XmlNode | 表示文档中的一个元素。 |
| XmlDocument | 读取存储在磁盘或网络地址上的Xml文件。 |
| XmlElement | 表示一个元素,通常用来储存根目录。 |
| XmlAttribute | 表示节点中的特性。 |
| XmlText | 表示节点中的文本数据。 |
| XmlComment | 表示特殊类型元素,不是Xml文件的一部分,用于便于阅读的其他拓展信息。 |
| XmlNodeList | 表示一个元素集合。 |
举个例子:
//XmlDocument 继承 XmlNode
XmlDocument document = new XmlDocument();
document.Load(@"C:\Users\Administrator\Desktop\XMLFile2.xml");示例解释:
XmlDocument 通过方法Load读取数据文件,参数为指定的Xml文件的路径,无返回类型。
//获取文档的根目录 也就获取了XML的所有文件内容。
XmlElement xmlElement= document.DocumentElement;示例解释:
(XmlDocument类型) DocumentElement属性返回当前Xml文件的根目录,如果没有则返回Null。
//获取当前节点中后面的第一个节点
XmlNode xmlNode = xmlElement.FirstChild;
//获取当前节点中的最后一个节点
XmlNode xmlNode1 = xmlElement.LastChild;
//获取当前节点中的父节点
XmlNode xmlNode2 = xmlElement.ParentNode;
// 访问同一层级的下一个节点,而不考虑节点类型
XmlNode xmlNode3 = xmlElement.NextSibling;
//获取当前 是否有子节点
Boolean IshaveXmlNode = xmlElement.HasChildNodes;示例解释:
我使用到了多种属性,类型都是一个节点XmlNode类型,代码当中都有相关注释。
其中:
XmlText、XmlComment、XmlAttribute、XmlNode 是没有公共的无参构造函数或是抽象的类。但我们都可以通过 XmlDocument实例来创建

示例(读取Xml文件的节点)
//获取所有节点
foreach (XmlNode item in xmlElement.ChildNodes)
{
Console.WriteLine("根节点下有"+ item.Name + "节点");
foreach (XmlNode item2 in item.ChildNodes)
{
Console.WriteLine($"{item.Name}节点下有"+ item2.Name+"节点");
}
}示例解释:ChildNodes是获取当前节点的所有子节点 。
输出 :

2 示例(获取Xml内容,书上示例)
private string FormatText(XmlNode node, string text, string indent)
{
if (node is XmlText)
{
text += node.Value;
return text;
}
if (string.IsNullOrEmpty(indent))
indent = "";
else
{
text += "\r\n" + indent;
}
if (node is XmlComment)
{
text += node.OuterXml;
return text;
}
text += "<" + node.Name;
if (node.Attributes.Count > 0)
{
AddAttributes(node, ref text);
}
if (node.HasChildNodes)
{
text += ">";
foreach (XmlNode child in node.ChildNodes)
{
text = FormatText(child, text, indent + " ");
}
if (node.ChildNodes.Count == 1 &&
(node.FirstChild is XmlText || node.FirstChild is XmlComment))
text += "";
else
text += "\r\n" + indent + "";
}
else
text += " />";
return text;
} private void AddAttributes(XmlNode node, ref string text)
{
foreach (XmlAttribute xa in node.Attributes)
{
text += " " + xa.Name + "='" + xa.Value + "'";
}
}使用方式:
XmlDocument document = new XmlDocument();
document.Load(booksFile);
textBlockResults.Text = FormatText(document.DocumentElement as XmlNode, "", "");示例解释:
如其中的node is XmlText 来判断当前节点是否包含了文本 如前面的示例Class Weight Height 这三个是XmlText 因为只有他们是实际包含了文本。其中的XmlComment判断也类似。
3 节点的操作
3.1 修改:
可以通过Value 属性来获取,但如果不是实际包含了文本,那么返回结果就是Null
3.2 插入:
前面提到 XmlText、XmlComment、XmlAttribute、XmlNode 其中我们可以通过XmlDocument使用方法来创建
举个例子:
XmlDocument document = new XmlDocument();
document.Load(booksFile);
//创建一个特性
document.CreateAttribute("特性");
//创建一个节点 是什么类型,节点名称,"节点的Uri"
document.CreateNode(XmlNodeType.Text,"名字","节点的名称空间 Uri");
//创建一个XmlElement类型的节点 "
document.CreateElement("节点名称");
//创建一个XmlText类型的节点
document.CreateTextNode("节点中显示的内容");
//创建注释
document.CreateComment("示例节点");示例解释:展示了创建节点的多个方法。
将创建的节点添加进去:
// 加载当前Xml文件
XmlDocument document = new XmlDocument();
document.Load(@"C:\Users\Administrator\Desktop\XMLFile3.xml");
//获取根节点
XmlElement root = document.DocumentElement;
//创建节点
XmlElement newOther = document.CreateElement("Other");
XmlComment comment = document.CreateComment("其他");
XmlElement newXmlNode = document.CreateElement("FatherAndMother");
XmlElement father = document.CreateElement("father");
XmlElement mother = document.CreateElement("mother");
XmlText liu = document.CreateTextNode("刘女士");
XmlText li = document.CreateTextNode("李男士");
//Other 节点下的节点
newOther.AppendChild(newXmlNode);
//Other节点的注释
newOther.AppendChild(comment);
//father and mother节点下的节点
newXmlNode.AppendChild(father);
newXmlNode.AppendChild(mother);
//节点的文本
mother.AppendChild(liu);
father.AppendChild(li);
root.InsertAfter(newOther,root.FirstChild);
//保存文件
document.Save(@"C:\Users\Administrator\Desktop\XMLFile3.xml");效果:

3.3 删除
XmlDocument document = new XmlDocument();
document.Load(booksFile);
XmlElement root = document.DocumentElement;
if (root.HasChildNodes)
{
XmlNode book = root.LastChild;
root.RemoveChild(book);
document.Save(booksFile);
}3.4 选择
SerializeXmlNode返回第一个匹配的节点
XmlDocument document = new XmlDocument();
document.Load(booksFile);
//返回根目录
string str = Newtonsoft.Json.JsonConvert.SerializeXmlNode(document);六、XML转换为JSON
1安装Newtonsoft.Json 包


2 转换代码
XmlDocument document = new XmlDocument();
document.Load(@"C:\Users\Administrator\Desktop\XMLFile3.xml");
string json = Newtonsoft.Json.JsonConvert.SerializeXmlNode(document);
System.IO.File.WriteAllText(@"C:\Users\Administrator\Desktop\XMLFile2.json", json);转换结果:
{
"?xml": {
"@version": "1.0",
"@encoding": "utf-8"
},
"Student": {
"Name": {
"@name": "张三",
"Height": " 188 ",
"Weight": "75kg",
"Class": "1805"
},
"Other": {
"FatherAndMother": {
"father": "李男士",
"mother": "刘女士"
} /*其他*/
}
}
}七、XPath搜索XML文件
SelectNodes方法通过Xpath表达式来对Xml进行查找
XmlDocument document = new XmlDocument();
document.Load(@"C:\Users\Administrator\Desktop\XMLFile3.xml");
XmlNodeList xmlNodeList= document.DocumentElement.SelectNodes(".") ;示例解释:
在XPath中,
.代表当前节点。当你使用.时,它指代的是上下文中的当前节点。这通常用于在XPath表达式中指明相对位置,而不是从根节点开始定位节点。
1 Xpath表达式示例:
-
选择节点:
- 选择所有节点:
//* - 选择特定节点:
/bookstore/book(选择根节点下的所有book节点) - 选择当前节点:
.
- 选择所有节点:
-
按名称选择:
- 选择所有名称为
title的节点://title - 选择当前节点的父节点:
.. - 选择根节点:
/
- 选择所有名称为
-
按属性选择:
- 选择所有具有特定属性的节点:
//*[@attribute] - 选择特定属性值的节点:
//*[@attribute='value']
- 选择所有具有特定属性的节点:
-
按位置选择:
- 选择第一个节点:
(//book)[1] - 选择最后一个节点:
(//book)[last()] - 选择前几个节点:
(//book)[position() <= 3]
- 选择第一个节点:
-
按条件选择:
- 选择价格大于 50 的书籍:
//book[price > 50] - 选择作者为"Author Name"的书籍:
//book[author='Author Name'] - 选择第一个
book节点的title:/bookstore/book[1]/title
- 选择价格大于 50 的书籍:
这些表达式可以帮助你根据需要定位XML文档中的不同节点。