乐优商城笔记-商城系统功能编写
索引数据库导入
创建搜索微服务
new module
Group id:com.leyou.search
Artifactid: leyou-search
Module name:leyou-search
pom文件:配置
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>leyouartifactId>
<groupId>com.leyou.parentgroupId>
<version>1.0.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<groupId>com.leyou.searchgroupId>
<artifactId>leyou-searchartifactId>
<version>1.0.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
dependencies>
project>
application.yml:
server:
port: 8083
spring:
application:
name: search-service
data:
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: 192.168.59.128:9300
cloud:
inetutils:
timeout-seconds: 10
eureka:
client:
service-url:
defaultZone: http://localhost:10086/eureka
registry-fetch-interval-seconds: 10
instance:
lease-renewal-interval-in-seconds: 5 # 每隔5秒发送一次心跳
lease-expiration-duration-in-seconds: 10 # 10秒不发送就过期
引导类:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
@EnableDiscoveryClient
@EnableFeignClients
public class LeyouSearchApplication {
public static void main(String[] args) {
SpringApplication.run(LeyouSearchApplication.class);
}
}
索引数据库数据格式分析
接下来,我们需要商品数据导入索引库,便于用户搜索。
那么问题来了,我们有SPU和SKU,到底如何保存到索引库?
以结果为导向
搜索结果每一个搜索结果都有至少1个商品,当我们选择大图下方的小图,商品会跟着变化。
因此,搜索的结果是SPU,即多个SKU的集合。
既然搜索的结果是SPU,那么我们索引库中存储的应该也是SPU,但是却需要包含SKU的信息。
需要什么数据

直观能看到的:图片、价格、标题、副标题
暗藏的数据:spu的id,sku的id
另外,页面还有过滤条件:

这些过滤条件也都需要存储到索引库中,包括:
商品分类、品牌、可用来搜索的规格参数等
综上所述,我们需要的数据格式有:
spuId、SkuId、商品分类id、品牌id、图片、价格、商品的创建时间、sku信息集、可搜索的规格参数
最终的数据结构
我们创建一个类,封装要保存到索引库的数据,并设置映射属性:
@Document(indexName = "goods", type = "docs", shards = 1, replicas = 0)
public class Goods {
@Id
private Long id; // spuId
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String all; // 所有需要被搜索的信息,包含标题,分类,甚至品牌
@Field(type = FieldType.Keyword, index = false)
private String subTitle;// 卖点
private Long brandId;// 品牌id
private Long cid1;// 1级分类id
private Long cid2;// 2级分类id
private Long cid3;// 3级分类id
private Date createTime;// 创建时间
private List<Long> price;// 价格
@Field(type = FieldType.Keyword, index = false)
private String skus;// List信息的json结构
private Map<String, Object> specs;// 可搜索的规格参数,key是参数名,值是参数值
}
一些特殊字段解释:
-
all:用来进行全文检索的字段,里面包含标题、商品分类信息
-
price:价格数组,是所有sku的价格集合。方便根据价格进行筛选过滤
-
skus:用于页面展示的sku信息,不索引,不搜索。包含skuId、image、price、title字段
-
specs:所有规格参数的集合。key是参数名,值是参数值。
例如:我们在specs中存储 内存:4G,6G,颜色为红色,转为json就是:
{ "specs":{ "内存":[4G,6G], "颜色":"红色" } }当存储到索引库时,elasticsearch会处理为两个字段:
- specs.内存:[4G,6G]
- specs.颜色:红色
另外, 对于字符串类型,还会额外存储一个字段,这个字段不会分词,用作聚合。
- specs.颜色.keyword:红色
商品微服务提供接口
索引库中的数据来自于数据库,我们不能直接去查询商品的数据库,因为真实开发中,每个微服务都是相互独立的,包括数据库也是一样。所以我们只能调用商品微服务提供的接口服务。
先思考我们需要的数据:
-
SPU信息
-
SKU信息
-
SPU的详情
-
商品分类名称(拼接all字段)
-
品牌名称
-
规格参数
再思考我们需要哪些服务:
- 第一:分批查询spu的服务,已经写过。
- 第二:根据spuId查询sku的服务,已经写过
- 第三:根据spuId查询SpuDetail的服务,已经写过
- 第四:根据商品分类id,查询商品分类名称,没写过
- 第五:根据商品品牌id,查询商品的品牌,没写过
- 第六:规格参数接口
因此我们需要额外提供一个查询商品分类名称的接口。
商品分类名称查询与品牌查询
item-service中的方法
在CategoryController中添加接口:
@GetMapping("names")
public ResponseEntity<List<String>> queryNamesByIds(@RequestParam("ids")List<Long> ids){
List<String> names = this.categoryService.queryNamesByIds(ids);
if (CollectionUtils.isEmpty(names)) {
return ResponseEntity.notFound().build();
}
return ResponseEntity.ok(names);
}
BrandController
@GetMapping("{id}")
public ResponseEntity<Brand> queryBrandById(@PathVariable("id")Long id){
Brand brand = this.brandService.queryBrandById(id);
if(brand==null){
return ResponseEntity.notFound().build();
}
return ResponseEntity.ok(brand);
BrandService
public Brand queryBrandById(Long id) {
return this.brandMapper.selectByPrimaryKey(id);
}
编写FeignClient
问题展现
操作leyou-search工程
现在,我们要在搜索微服务调用商品微服务的接口。
第一步要在leyou-search工程中,引入商品微服务依赖:leyou-item-interface。
<dependency>
<groupId>com.leyou.itemgroupId>
<artifactId>leyou-item-interfaceartifactId>
<version>${leyou.latest.version}version>
dependency>
<dependency>
<groupId>com.leyou.commongroupId>
<artifactId>leyou-commonartifactId>
<version>1.0.0-SNAPSHOTversion>
dependency>
第二步,编写FeignClient

@FeignClient(value = "item-service")
public interface GoodsClient {
/**
* 分页查询商品
* @param page
* @param rows
* @param saleable
* @param key
* @return
*/
@GetMapping("/spu/page")
PageResult querySpuByPage(
@RequestParam(value = "page", defaultValue = "1") Integer page,
@RequestParam(value = "rows", defaultValue = "5") Integer rows,
@RequestParam(value = "saleable", defaultValue = "true") Boolean saleable,
@RequestParam(value = "key", required = false) String key);
/**
* 根据spu商品id查询详情
* @param id
* @return
*/
@GetMapping("/spu/detail/{id}")
SpuDetail querySpuDetailById(@PathVariable("id") Long id);
/**
* 根据spu的id查询sku
* @param id
* @return
*/
@GetMapping("sku/list")
List querySkuBySpuId(@RequestParam("id") Long id);
}
以上的这些代码直接从商品微服务中拷贝而来,完全一致。差别就是没有方法的具体实现。大家觉得这样有没有问题?
而FeignClient代码遵循SpringMVC的风格,因此与商品微服务的Controller完全一致。这样就存在一定的问题:
- 代码冗余。尽管不用写实现,只是写接口,但服务调用方要写与服务controller一致的代码,有几个消费者就要写几次。
- 增加开发成本。调用方还得清楚知道接口的路径,才能编写正确的FeignClient。
解决方案
因此,一种比较友好的实践是这样的:
- 我们的服务提供方不仅提供实体类,还要提供api接口声明
- 调用方不用自己编写接口方法声明,直接继承提供方给的Api接口即可,
第一步:服务的提供方在leyou-item-interface中提供API接口,并编写接口声明:

商品分类服务接口:
@RequestMapping("category")
public interface CategoryApi {
@GetMapping
public List queryNameByIds(@RequestParam("ids")List ids);
}
商品服务接口,返回值不再使用ResponseEntity:
public interface GoodsApi {
//在此接口中调用哪个controller方法,直接复制进来即可,而且这里的接口可以被其他微服务同时使用,避免了代码冗余
/**
* 根据spuid查询spudetail
* 返回中的ResponseEntity可写也可不写
* 如果写,则需要对ResponseEntity进行解析/包,
*/
@GetMapping("spu/detail/{spuId}")
public SpuDetail querySpuDetailBySpuId(@PathVariable("spuId")Long spuId);
/**
* 根据条件分页查询spu
* @param key
* @param saleable
* @param page
* @param rows
* @return
*/
@GetMapping("spu/page")
public PageResult querySpuByPage(
@RequestParam(value="key",required = false) String key,
@RequestParam (value="saleable",required = false) Boolean saleable,
@RequestParam (value="page",defaultValue = "1") Integer page,
@RequestParam (value="rows",defaultValue = "5") Integer rows
);
/**
* 根据spuid查询sku集合
*/
@GetMapping("sku/list")
public List querySkusBySpuId(@RequestParam("id")Long spuId);
}
品牌的接口:
@RequestMapping("brand")
public interface BrandApi {
@GetMapping("{id}")
public Brand queryBrandById(@PathVariable("id")Long id);
}
规格参数的接口:
@RequestMapping("spec")
public interface SpecificationApi {
/**
* 根据条件查询规格参数
* @param gid
* @return
*/
@GetMapping("params")
public List queryParams(
@RequestParam(value = "gid",required = false) Long gid,
@RequestParam(value = "cid",required = false) Long cid,
@RequestParam(value = "generic",required = false) Boolean generic,
@RequestParam(value = "searching",required = false) Boolean searching
);
}
需要引入springMVC及leyou-common的依赖:
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-webmvcartifactId>
<version>5.0.6.RELEASEversion>
dependency>
<dependency>
<groupId>com.leyou.commongroupId>
<artifactId>leyou-commonartifactId>
<version>1.0.0-SNAPSHOTversion>
dependency>
上述是笔记,下面是实际代码依赖
<dependencies>
<dependency>
<groupId>javax.persistencegroupId>
<artifactId>persistence-apiartifactId>
<version>1.0version>
dependency>
<dependency>
<groupId>tk.mybatisgroupId>
<artifactId>mapper-spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>com.leyou.commongroupId>
<artifactId>leyou-commonartifactId>
<version>1.0.0-SNAPSHOTversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-webmvcartifactId>
<version>5.0.6.RELEASEversion>
dependency>
dependencies>
第二步:在调用方leyou-search中编写FeignClient,但不要写方法声明了,直接继承leyou-item-interface提供的api接口:

商品的FeignClient:
@FeignClient("item-service")
public interface GoodsClient extends GoodsApi {
}
商品分类的FeignClient:
@FeignClient("item-service")
public interface CategoryClient extends CategoryApi {
}
品牌的FeignClient:
@FeignClient("item-service")
public interface BrandClient extends BrandApi {
}
规格参数的FeignClient:
@FeignClient("item-service")
public interface SpecificationClient extends SpecificationApi {
}
是不是简单多了?
导入数据
创建GoodsRepository

java代码:
public interface GoodsRepository extends ElasticsearchRepository<Goods, Long> {
}
导入数据
导入数据其实就是查询数据,然后把查询到的Spu转变为Goods来保存,因此我们先编写一个SearchService,然后在里面定义一个方法, 把Spu转为Goods
@Service
public class SearchService {
@Autowired
private CategoryClient categoryClient;
@Autowired
private BrandClient brandClient;
@Autowired
private SpecificationClient specificationClient;
@Autowired
private GoodsClient goodsClient;
@Autowired
private GoodsRepository goodsRepository;
private static final ObjectMapper MAPPER =new ObjectMapper();
public Goods buildGoods(Spu spu) throws Exception {
Goods goods = new Goods();
//根据分类的id查询分类名称
List<String> names = this.categoryClient.queryNameByIds(Arrays.asList(spu.getCid1(), spu.getCid2(), spu.getCid3()));
//根据品牌id查询品牌
Brand brand = this.brandClient.queryBrandById(spu.getBrandId());
//根据spuid查询所有的sku
List<Sku> skus = this.goodsClient.querySkusBySpuId(spu.getId());
//初始化一个价格集合,搜集所有sku的价格
List<Long>prices=new ArrayList<>();
//收集sku的必要字段信息
List<Map<String,Object>> skuMapList =new ArrayList<>();
skus.forEach(sku -> {
prices.add(sku.getPrice());
Map<String,Object> map=new HashMap<>();
map.put("id",sku.getId());
map.put("title",sku.getTitle());
map.put("price",sku.getPrice());
//获取sku中的数据库中的图片,可能有多张,以","分割,所以我们用","来切割.所以也用逗号来切割返回图片数组,获取第一张图片
map.put("image", StringUtils.isBlank(sku.getImages())?"":StringUtils.split(sku.getImages(),",")[0]);
skuMapList.add(map);
});
//根据spu中的cid3查询所有的搜素规格参数
List<SpecParam> params = this.specificationClient.queryParams(null, spu.getCid3(), null, true);
//根据spuId查询spuDetail
SpuDetail spuDetail = this.goodsClient.querySpuDetailBySpuId(spu.getId());
//把通用的规格参数值进行反序列化
Map<String,Object> genericSpecMap=MAPPER.readValue(spuDetail.getGenericSpec(), new TypeReference<Map<String,Object>>(){});
//把特殊的规格参数进行反序列化
Map<String,List<Object>> specialSpecMap=MAPPER.readValue(spuDetail.getSpecialSpec(), new TypeReference<Map<String,List<Object>>>(){});
Map<String,Object> specs=new HashMap<>();
params.forEach(param ->{
//判断规格参数的类型,是否是通用的规格参数
if(param.getGeneric()){
//如果是通用类型的参数,从genericSpecMap获取规格参数值
String value=genericSpecMap.get(param.getId().toString()).toString();
//判断是否是数值类型,如果是数值类型,应该返回一个区间
if(param.getNumeric()){
value = chooseSegment(value, param);
}
specs.put(param.getName(),value);
}else {
//如果是特殊的规格参数,从specialSpecMap获取
List<Object> value = specialSpecMap.get(param.getId().toString());
specs.put(param.getName(),value);
}
} );
goods.setId(spu.getId());
goods.setCid1(spu.getCid1());
goods.setCid2(spu.getCid2());
goods.setCid3(spu.getCid3());
goods.setBrandId(spu.getBrandId());
goods.setCreateTime(spu.getCreateTime());
goods.setSubTitle(spu.getSubTitle());
//拼接all字段,需要分类名称和品牌名称
goods.setAll(spu.getTitle()+" "+ StringUtils.join(names," ")+" "+brand.getName());//空格是防止分词出现失误
//获取spu下所有sku价格
goods.setPrice(prices);
//获取spu下的所有sku,并转化成json字符串。序列化为String,用writeValueAsString。反序列化用readValue
goods.setSkus(MAPPER.writeValueAsString(skuMapList));
//获取所有查询的规格参数{name:value} 因为返回的是map 知道key即可
goods.setSpecs(specs);
return goods;
}
private String chooseSegment(String value, SpecParam p) {
double val = NumberUtils.toDouble(value);
String result = "其它";
// 保存数值段
for (String segment : p.getSegments().split(",")) {
String[] segs = segment.split("-");
// 获取数值范围
double begin = NumberUtils.toDouble(segs[0]);
double end = Double.MAX_VALUE;
if(segs.length == 2){
end = NumberUtils.toDouble(segs[1]);
}
// 判断是否在范围内
if(val >= begin && val < end){
if(segs.length == 1){
result = segs[0] + p.getUnit() + "以上";
}else if(begin == 0){
result = segs[1] + p.getUnit() + "以下";
}else{
result = segment + p.getUnit();
}
break;
}
}
return result;
}
创建索引
我们新建一个测试类,在里面进行数据的操作:

编写测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticsearchTest {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Autowired
private GoodsRepository goodsRepository;
@Autowired
private SearchService searchService;
@Autowired
private GoodsClient goodsClient;
@Test
public void test(){
this.elasticsearchTemplate.createIndex(Goods.class);
this.elasticsearchTemplate.putMapping(Goods.class);
Integer page=1;
Integer rows=100;
do{//分页查询spu,获取分页结果集
PageResult result = this.goodsClient.querySpuByPage(null, true, page, rows);
//获取当前页数据
List items =result.getItems();
//处理List变为 List
List goodsList=items.stream().map(spubo -> {
try {
return this.searchService.buildGoods(spubo);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}).collect(Collectors.toList());
//执行新增数据的方法
this.goodsRepository.saveAll(goodsList);
rows=items.size();
page++;
}while (rows==100);
}
}
测试中直接对内容进行注入,所以不需要再额外注入数据
基本搜索
页面分析
页面跳转
在首页的顶部,有一个输入框:
当我们输入任何文本,点击搜索,就会跳转到搜索页search.html了:
并且将搜索关键字以请求参数携带过来:
我们打开search.html,在最下面会有提前定义好的Vue实例:
<script type="text/javascript">
var vm = new Vue({
el: "#searchApp",
data: {
},
components:{
// 加载页面顶部组件
lyTop: () => import("./js/pages/top.js")
}
});
script>
这个Vue实例中,通过import导入的方式,加载了另外一个js:top.js并作为一个局部组件。top其实是页面顶部导航组件,我们暂时不管
发起异步请求
要想在页面加载后,就展示出搜索结果。我们应该在页面加载时,获取地址栏请求参数,并发起异步请求,查询后台数据,然后在页面渲染。
我们在data中定义一个对象,记录请求的参数:
data: {
search:{
key:"", // 搜索页面的关键字
}
}
我们通过钩子函数created,在页面加载时获取请求参数,并记录下来。
created(){
// 判断是否有请求参数
if(!location.search){
return;
}
// 将请求参数转为对象
const search = ly.parse(location.search.substring(1));
// 记录在data的search对象中
search.page=parseInt(search.page)||1;
this.search = search;
// 发起请求,根据条件搜索
this.loadData();
}
然后发起请求,搜索数据。
methods: {
loadData(){
// ly.http.post("/search/page", ly.stringify(this.search)).then(resp=>{
ly.http.post("/search/page", this.search).then(resp=>{
console.log(resp);
});
}
}
- 我们这里使用
ly是common.js中定义的工具对象。 - 这里使用的是post请求,这样可以携带更多参数,并且以json格式发送
在leyou-gateway中的CORS配置类中,添加允许信任域名:

并在leyou-gateway工程的Application.yml中添加网关映射:

刷新页面试试:

因为后台没有提供接口,所以无法访问。没关系,接下来我们实现后台接口
后台提供搜索接口
controller
首先分析几个问题:
-
请求方式:Post
-
请求路径:/search/page,不过前面的/search应该是网关的映射路径,因此真实映射路径page,代表分页查询
-
请求参数:json格式,目前只有一个属性:key-搜索关键字,但是搜索结果页一定是带有分页查询的,所以将来肯定会有page属性,因此我们可以用一个对象来接收请求的json数据:
public class SearchRequest { private String key;// 搜索条件 private Integer page;// 当前页 private static final Integer DEFAULT_SIZE = 20;// 每页大小,不从页面接收,而是固定大小 private static final Integer DEFAULT_PAGE = 1;// 默认页 public String getKey() { return key; } public void setKey(String key) { this.key = key; } public Integer getPage() { if(page == null){ return DEFAULT_PAGE; } // 获取页码时做一些校验,不能小于1 return Math.max(DEFAULT_PAGE, page); } public void setPage(Integer page) { this.page = page; } public Integer getSize() { return DEFAULT_SIZE; } } -
返回结果:作为分页结果,一般都两个属性:当前页数据、总条数信息,我们可以使用之前定义的PageResult类
@Controller
public class SearchController {
@Autowired
private SearchService searchService;
@PostMapping("page")
public ResponseEntity<PageResult<Goods>> search(@RequestBody SearchRequest request){
PageResult<Goods> result=this.searchService.search(request);
if (result==null|| CollectionUtils.isEmpty(result.getItems())){
return ResponseEntity.notFound().build();
}
return ResponseEntity.ok(result);
}
}
service

添加方法
public PageResult<Goods> search(SearchRequest request) {
if (StringUtils.isBlank(request.getKey())){
return null;
}
//自定义查询构建器
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加查询条件 对key进行全文检索查询
queryBuilder.withQuery(QueryBuilders.matchQuery("all",request.getKey()).operator(Operator.AND));
//添加分页,分页页码从0开始
queryBuilder.withPageable(PageRequest.of(request.getPage()-1,request.getSize()));
//添加结果集过过滤,通过sourceFilter设置返回的结果字段,我们只需要id、skus、subTitle
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{"id","skus","subTitle"},null));
//执行查询,获取结果集
Page<Goods> goodsPage = this.goodsRepository.search(queryBuilder.build());
return new PageResult<>(goodsPage.getTotalElements(),goodsPage.getTotalPages(),goodsPage.getContent());
}
注意点:我们要设置SourceFilter,来选择要返回的结果,否则返回一堆没用的数据,影响查询效率。
测试
刷新页面测试
数据是查到了,但是因为我们只查询部分字段,所以结果json 数据中有很多null,这很不优雅。
解决办法很简单,在leyou-search的application.yml中添加一行配置,json处理时忽略空值:
spring:
jackson:
default-property-inclusion: non_null # 配置json处理时忽略空值
页面渲染
html页面中
标签名后加:变为动态加载
比如
在loadData的异步查询中,将结果赋值给goodsList:

循环展示商品
在search.html的中部,有一个div,用来展示所有搜索到的商品:
可以看到,div中有一个无序列表ul,内部的每一个li就是一个商品spu了。
我们删除多余的,只保留一个li,然后利用vue的循环来展示搜索到的结果:

多sku展示
分析
这里我们可以发现,一个商品位置,是多个sku的信息集合。当用户鼠标选择某个sku,对应的图片、价格、标题会随之改变!
我们先来实现sku的选择,才能去展示不同sku的数据。
可以看到,在列表中默认第一个是被选中的,那我们就需要做两件事情:
-
在搜索到数据时,先默认把第一个sku作为被选中的,记录下来
-
记录当前被选中的是哪一个sku,记录在哪里比较合适呢?显然是遍历到的goods对象自己内部,因为每一个goods都会有自己的sku信息。
导入图片
现在商品表中虽然有数据,但是所有的图片信息都是无法访问的,我们需要把图片导入到虚拟机:
首先,把课前资料提供的数据上传到虚拟机下:/leyou/static目录:在leyou下创建static目录
然后,使用命令解压缩:
unzip images.zip
修改Nginx配置,使nginx反向代理这些图片地址:
vim /opt/nginx/config/nginx.conf
修改成如下配置:
server {
listen 80;
server_name image.leyou.com;
# 监听域名中带有group的,交给FastDFS模块处理
location ~/group([0-9])/ {
ngx_fastdfs_module;
}
# 将其它图片代理指向本地的/leyou/static目录
location / {
root /leyou/static/;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
不要忘记重新加载nginx配置
nginx -s reload
html页面加:变成动态属性
初始化sku
查询出的结果集skus是一个json类型的字符串,不是js对象

我们在查询成功的回调函数中,对goods进行遍历,把skus转化成json对象集合,并添加一个selected属性保存被选中的sku:
methods:{
loadData(){
ly.http.post("/search/page",this.search).then(({data}) => {
data.items.forEach(goods =>{
//转换sku,把字符转变为对象
goods.skus=JSON.parse(goods.skus);
//添加默认选中项
goods.selected =goods.skus[0];
});
this.goodsList = data.items;
}).catch(()=>{
});
}
},

多sku图片列表
查询字符串 key=value&&key1=value1
json对象 {key:“value”,key1:“value1”}
查询字符串=》json对象 ly.pase(查询字符串)
json对象=》 查询字符串 ly.stringify(json对象)
json字符串: “{‘key’:‘value’,‘key1’:‘value1’}”
json字符串=》json对象 JSON.pase stringify
接下来,我们看看多个sku的图片列表位置:
看到又是一个无序列表,这里我们也一样删掉多余的,保留一个li,需要注意选中的项有一个样式类:selected
我们的代码:
-
![]()
注意:
- class样式通过 goods.selected的id是否与当前sku的id一致来判断
- 绑定了鼠标事件,鼠标进入后把当前sku赋值到goods.selected
页面分页
刚才的查询中,我们默认了查询的页码和每页大小,因此所有的分页功能都无法使用,接下来我们一起看看分页功能条该如何制作。
这里要分两步,
- 第一步:如何生成分页条
- 第二步:点击分页按钮,我们做什么
生成分页条
需要的数据
分页数据应该是根据总页数、当前页、总条数等信息来计算得出。
- 当前页:肯定是由页面来决定的,点击按钮会切换到对应的页
- 总页数:需要后台传递给我们
- 总条数:需要后台传递给我们
我们首先在data中记录下这几个值:page-当前页,total-总条数,totalPage-总页数
将后台代码中
PageResult提供的totalPage写入data
data: {
ly,
search:{
key:"",
page: 1
},
goodsList:[],
total:0,
totalPage: 1
},
loadData(){
ly.http.post("/search/page",this.search).then(({data}) => {
data.items.forEach(goods =>{
//转换sku,把字符转变为对象
goods.skus=JSON.parse(goods.skus);
//添加默认选中项
goods.selected =goods.skus[0];
});
this.goodsList = data.items;
this.totalPage=data.totalPage;赋值分页页数
}).catch(()=>{
});
},
页面计算分页条
a标签中的分页数字通过index函数来计算,需要把i传递过去:
index(i){
if(this.search.page<=3|| this.totalPage <=5){
return i;
}else if(this.search.page>= this.totalPage -2){
return this.totalPage-5+i;
}else {
return this.search.page -3+i;
}
}
点击分页跳转
点击分页按钮后,自然是要修改page的值
所以,我们在上一页、下一页按钮添加点击事件,对page进行修改,在数字按钮上绑定点击事件,点击直接修改page:
具体方法
prev(){
if(this.search.page>1){
this.search.page--;
}
},
next(){
if(this.search.page当page发生变化,我们应该去后台重新查询数据。
不过,如果我们直接发起ajax请求,那么浏览器的地址栏中是不会有变化的,没有记录下分页信息。如果用户刷新页面,那么就会回到第一页。
这样不太友好,我们应该把搜索条件记录在地址栏的查询参数中。
因此,我们监听search的变化,然后把search的过滤字段拼接在url路径后:
watch:{
search:{
deep:true,
handler(val){
// 把search对象变成请求参数,拼接在url路径
window.location.href = "http://www.leyou.com/search.html?" + ly.stringify(val);
}
}
},
刷新页面测试,然后就出现重大bug:页面无限刷新!为什么?
因为Vue实例初始化的钩子函数中,我们读取请求参数,赋值给search的时候,也触发了watch监视!也就是说,每次页面创建完成,都会触发watch,然后就会去修改window.location路径,然后页面被刷新,再次触发created钩子,又触发watch,周而复始,无限循环。
所以,我们需要在watch中进行监控,如果发现是第一次初始化,则不继续向下执行。
那么问题是,如何判断是不是第一次?
第一次初始化时,search中的key值肯定是空的,所以,我们这么做:
watch: {
search: {
deep:true,
handler(newVal,oldVal){
if(!oldVal||!oldVal.key){
return ;
}
window.location="http://www.leyou.com/search.html?" + ly.stringify(this.search);
}
}
},
顶部分页条
首先将总商品数目加载进数据中
loadData(){
ly.http.post("/search/page",this.search).then(({data}) => {
data.items.forEach(goods =>{
//转换sku,把字符转变为对象
goods.skus=JSON.parse(goods.skus);
//添加默认选中项
goods.selected =goods.skus[0];
});
this.goodsList = data.items;
this.total=data.total;
this.totalPage=data.totalPage;
}).catch(()=>{
});
},
修改分页条的数据
搜索过滤
过滤功能分析
要实现的结果

整个过滤部分有3块:
- 顶部的导航,已经选择的过滤条件展示:
- 商品分类面包屑,根据用户选择的商品分类变化
- 其它已选择过滤参数
- 过滤条件展示,又包含3部分
- 商品分类展示
- 品牌展示
- 其它规格参数
- 展开或收起的过滤条件的按钮
顶部导航要展示的内容跟用户选择的过滤条件有关。
- 比如用户选择了某个商品分类,则面包屑中才会展示具体的分类
- 比如用户选择了某个品牌,列表中才会有品牌信息。
所以,这部分需要依赖第二部分:过滤条件的展示和选择。因此我们先不着急去做。
展开或收起的按钮是否显示,取决于过滤条件有多少,如果很少,那么就没必要展示。所以也是跟第二部分的过滤条件有关。
这样分析来看,我们必须先做第二部分:过滤条件展示。
生成分类和品牌过滤
先来看分类和品牌。在我们的数据库中已经有所有的分类和品牌信息。在这个位置,是不是把所有的分类和品牌信息都展示出来呢?
显然不是,用户搜索的条件会对商品进行过滤,而在搜索结果中,不一定包含所有的分类和品牌,直接展示出所有商品分类,让用户选择显然是不合适的。
无论是分类信息,还是品牌信息,都应该从搜索的结果商品中进行聚合得到。
扩展返回的结果
原来,我们返回的结果是PageResult对象,里面只有total、totalPage、items3个属性。但是现在要对商品分类和品牌进行聚合,数据显然不够用,我们需要对返回的结果进行扩展,添加分类和品牌的数据。
那么问题来了:以什么格式返回呢?
看页面:
分类:页面显示了分类名称,但背后肯定要保存id信息。所以至少要有id和name
品牌:页面展示的有logo,有文字,当然肯定有id,基本上是品牌的完整数据
我们新建一个类,继承PageResult,然后扩展两个新的属性:分类集合和品牌集合:

package com.leyou.search.pojo;
import com.leyou.common.pojo.PageResult;
import com.leyou.item.pojo.Brand;
import java.util.List;
import java.util.Map;
public class SearchResult extends PageResult<Goods>{
private List<Map<String,Object>> categories;
private List<Brand> brands;
private List<Map<String,Object>> specs;
public List<Map<String, Object>> getCategories() {
return categories;
}
public SearchResult() {
}
public SearchResult(List<Map<String, Object>> categories, List<Brand> brands, List<Map<String, Object>> specs) {
this.categories = categories;
this.brands = brands;
this.specs = specs;
}
public SearchResult(Long total, List<Goods> items, List<Map<String, Object>> categories, List<Brand> brands, List<Map<String, Object>> specs) {
super(total, items);
this.categories = categories;
this.brands = brands;
this.specs = specs;
}
public SearchResult(Long total, Integer totalPage, List<Goods> items, List<Map<String, Object>> categories, List<Brand> brands, List<Map<String, Object>> specs) {
super(total, totalPage, items);
this.categories = categories;
this.brands = brands;
this.specs = specs;
}
public void setCategories(List<Map<String, Object>> categories) {
this.categories = categories;
}
public List<Brand> getBrands() {
return brands;
}
public void setBrands(List<Brand> brands) {
this.brands = brands;
}
public List<Map<String, Object>> getSpecs() {
return specs;
}
public void setSpecs(List<Map<String, Object>> specs) {
this.specs = specs;
}
}
聚合商品分类和品牌
我们修改搜索的业务逻辑,对分类和品牌聚合。
因为索引库中只有id,所以我们根据id聚合,然后再根据id去查询完整数据。
所以,商品微服务需要提供一个接口:根据品牌id集合,批量查询品牌。
修改SearchService:添加search、getgetBrandAggResult、getCategoryAggResult 三个方法
public SearchResult search(SearchRequest request) {
if (StringUtils.isBlank(request.getKey())){
return null;
}
Integer page = request.getPage();
Integer size = request.getSize();
//自定义查询构建器
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加查询条件
//QueryBuilder basicQuery = QueryBuilders.matchQuery("all", request.getKey()).operator(Operator.AND); //无过滤查询语句
BoolQueryBuilder basicQuery = buildBoolQueryBuilder(request);
queryBuilder.withQuery(basicQuery);
//添加分页,分页页码从0开始
queryBuilder.withPageable(PageRequest.of(request.getPage() - 1,request.getSize()));
//添加结果集过过滤
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{"id","skus","subTitle"},null));
//添加分类和品牌聚合
String categoryAggName="categories";
String brandAggName="brands";
queryBuilder.addAggregation(AggregationBuilders.terms(categoryAggName).field("cid3"));
queryBuilder.addAggregation(AggregationBuilders.terms(brandAggName).field("brandId"));
//执行查询,获取结果集
AggregatedPage<Goods> goodsPage = (AggregatedPage<Goods>)this.goodsRepository.search(queryBuilder.build());
//获取聚合结果集并解析
List<Map<String,Object>> categories=getCategoryAggResult(goodsPage.getAggregation(categoryAggName));
List<Brand> brands =getBrandAggResult(goodsPage.getAggregation(brandAggName));
//判断是否是一个分类,只有一个分类时才做规格参数聚合
List<Map<String,Object>> specs=null;
if(!CollectionUtils.isEmpty(categories) && categories.size()==1){
//对规格参数进行聚合
specs=getParamAggResult((Long)categories.get(0).get("id"),basicQuery);
}
return new SearchResult(goodsPage.getTotalElements(),goodsPage.getTotalPages(),goodsPage.getContent(),categories,brands,specs);
}
/**
* 解析品牌的聚合结果集
* @param aggregation
* @return
*/
private List<Brand> getBrandAggResult(Aggregation aggregation) {
LongTerms terms = (LongTerms)aggregation;
//获取聚合中的桶
return terms.getBuckets().stream().map(bucket -> {
return this.brandClient.queryBrandById(bucket.getKeyAsNumber().longValue());
}).collect(Collectors.toList());
}
/**
* 解析分类的聚合结果集
* @param aggregation
* @return
*/
private List<Map<String,Object>> getCategoryAggResult(Aggregation aggregation) {
LongTerms terms = (LongTerms)aggregation;
//获取聚合中的桶,转化成Map测试:

页面渲染数据
过滤参数数据结构

虽然分类、品牌内容都不太一样,但是结构相似,都是key和value的结构。
而且页面结构也极为类似:
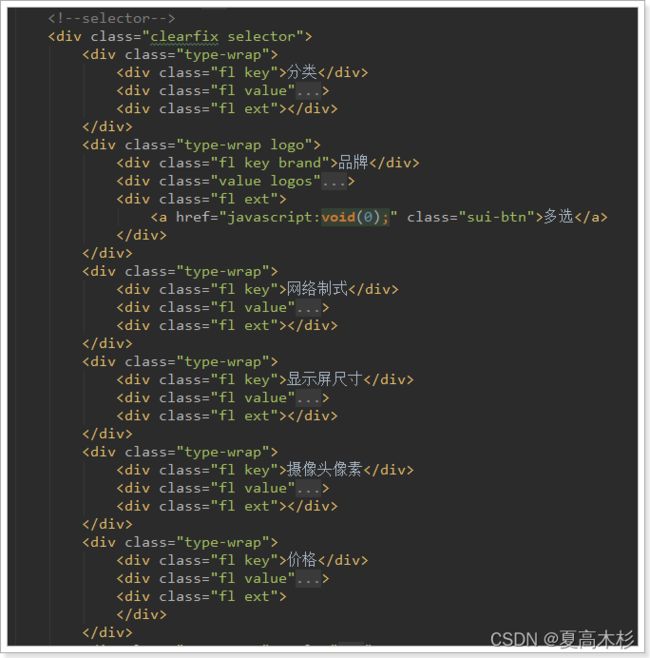
所以,我们可以把所有的过滤条件放入一个数组中,然后在页面利用v-for遍历一次生成。
其基本结构是这样的:
[
{
k:"过滤字段名",
options:[{/*过滤字段值对象*/},{/*过滤字段值对象*/}]
}
]
我们先在data中定义数组:filters,等待组装过滤参数:
data: {
ly,
search:{
key: "",
page: 1
},
goodsList:[], // 接收搜索得到的结果
total: 0, // 总条数
totalPage: 0, // 总页数
filters:[] // 过滤参数集合
},
然后在查询搜索结果的回调函数中,对过滤参数进行封装:
this.goodsList = data.items;
this.total=data.total;
this.totalPage=data.totalPage;
this.filters.push({
k: "分类",
options: data.categories
});
this.filters.push({
k: "品牌",
options: data.brands
});
然后刷新页面,通过浏览器工具,查看封装的结果:

页面渲染数据
首先看页面原来的代码:

我们注意到,虽然页面元素是一样的,但是品牌会比其它搜索条件多出一些样式,因为品牌是以图片展示。需要进行特殊处理。数据展示是一致的,我们采用v-for处理:
<!--selector-->
<div class="clearfix selector">
<div class="type-wrap" v-for="(f,index) in filters" :key="index" v-if="f.k !== '品牌'" v-show="index < 5 || show">
<div class="fl key">{{f.k}}</div>
<div class="fl value">
<ul class="type-list">
<li v-for="(o,j) in f.options" :key="j" @click="selectFilter(f.k, o)">
<a>{{o.name}}</a>
</li>
</ul>
</div>
<div class="fl ext"></div>
</div>
<div class="type-wrap logo" v-else>
<div class="fl key brand">{{f.k}}</div>
<div class="value logos">
<ul class="logo-list">
<li v-for="(o,j) in f.options" :key="j" v-if="o.image" @click="selectFilter(f.k, o)">
<img :src="o.image" /></li>
<li style="text-align: center" v-else @click="selectFilter(f.k, o)"><a style="line-height: 30px; font-size: 12px" href="#">{{o.name}}</a></li>
</ul>
</div>
<div class="fl ext">
<a href="javascript:void(0);" class="sui-btn">多选</a>
</div>
</div>
<div class="type-wrap" style="text-align: center">
<v-btn small flat @click="show = true" v-show="!show">
更多<v-icon>arrow_drop_down</v-icon>
</v-btn>
<v-btn small="" flat @click="show = false" v-show="show">
收起<v-icon>arrow_drop_up</v-icon>
</v-btn>
</div>
</div>
生成规格参数过滤
分析
有四个问题需要先思考清楚:
- 什么时候显示规格参数过滤? 分类只有一个
- 如何知道哪些规格需要过滤?
- 要过滤的参数,其可选值是如何获取的?
- 规格过滤的可选值,其数据格式怎样的?
什么情况下显示有关规格参数的过滤?
如果用户尚未选择商品分类,或者聚合得到的分类数大于1,那么就没必要进行规格参数的聚合。因为不同分类的商品,其规格是不同的。
因此,我们在后台需要对聚合得到的商品分类数量进行判断,如果等于1,我们才继续进行规格参数的聚合。
如何知道哪些规格需要过滤?
我们不能把数据库中的所有规格参数都拿来过滤。因为并不是所有的规格参数都可以用来过滤,参数的值是不确定的。
值的庆幸的是,我们在设计规格参数时,已经标记了某些规格可搜索,某些不可搜索。
因此,一旦商品分类确定,我们就可以根据商品分类查询到其对应的规格,从而知道哪些规格要进行搜索。
要过滤的参数,其可选值是如何获取的?
虽然数据库中有所有的规格参数,但是不能把一切数据都用来供用户选择。
与商品分类和品牌一样,应该是从用户搜索得到的结果中聚合,得到与结果品牌的规格参数可选值。
规格过滤的可选值,其数据格式怎样的?
我们直接看页面效果:

我们之前存储时已经将数据分段,恰好符合这里的需求
实战后台
接下来,我们就用代码实现刚才的思路。
总结一下,应该是以下几步:
- 1)用户搜索得到商品,并聚合出商品分类
- 2)判断分类数量是否等于1,如果是则进行规格参数聚合
- 3)先根据分类,查找可以用来搜索的规格
- 4)对规格参数进行聚合
- 5)将规格参数聚合结果整理后返回
扩展返回结果
返回结果中需要增加新数据,用来保存规格参数过滤条件。这里与前面的品牌和分类过滤的json结构类似:
[
{
"k":"规格参数名",
"options":["规格参数值","规格参数值"]
}
]
因此,在java中我们用List
扩展SearchResult内的get和set方法
package com.leyou.search.pojo;
import java.util.Map;
public class SearchRequest {
private String key;// 搜索条件
private Integer page;// 当前页
private Map<String,Object> filter;
private static final Integer DEFAULT_SIZE = 20;// 每页大小,不从页面接收,而是固定大小
private static final Integer DEFAULT_PAGE = 1;// 默认页
public Map<String, Object> getFilter() {
return filter;
}
public void setFilter(Map<String, Object> filter) {
this.filter = filter;
}
public static Integer getDefaultSize() {
return DEFAULT_SIZE;
}
public static Integer getDefaultPage() {
return DEFAULT_PAGE;
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public Integer getPage() {
if(page == null){
return DEFAULT_PAGE;
}
// 获取页码时做一些校验,不能小于1
return Math.max(DEFAULT_PAGE, page);
}
public void setPage(Integer page) {
this.page = page;
}
public Integer getSize() {
return DEFAULT_SIZE;
}
}
判断是否需要聚合
首先,在聚合得到商品分类后,判断分类的个数,如果是1个则进行规格聚合:SearchService中的search方法
//获取聚合结果集并解析
List<Map<String,Object>> categories=getCategoryAggResult(goodsPage.getAggregation(categoryAggName));
List<Brand> brands =getBrandAggResult(goodsPage.getAggregation(brandAggName));
//判断是否是一个分类,只有一个分类时才做规格参数聚合
List<Map<String,Object>> specs=null;
if(!CollectionUtils.isEmpty(categories) && categories.size()==1){
//对规格参数进行聚合
specs=getParamAggResult((Long)categories.get(0).get("id"),basicQuery);
}
return new SearchResult(goodsPage.getTotalElements(),goodsPage.getTotalPages(),goodsPage.getContent(),categories,brands,specs);
在此方法中定义查询
//自定义查询构建器
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加查询条件
//QueryBuilder basicQuery = QueryBuilders.matchQuery("all", request.getKey()).operator(Operator.AND); //无过滤查询语句
BoolQueryBuilder basicQuery = buildBoolQueryBuilder(request);
queryBuilder.withQuery(basicQuery);
//添加结果集过过滤
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{"id","skus","subTitle"},null));
我们将聚合的代码抽取到了一个getParamAggResult方法中。
获取需要聚合的规格参数
然后,我们需要根据商品分类,查询所有可用于搜索的规格参数:
/**
* 根据查询条件聚合规格参数
* @param cid
* @param basicQuery
* @return
*/
private List<Map<String,Object>> getParamAggResult(Long cid, QueryBuilder basicQuery) {
//自定义查询对象构建
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加基本查询条件
queryBuilder.withQuery(basicQuery);
//查询要聚合的规格参数
List<SpecParam> params = this.specificationClient.queryParams(null, cid,null, true);
//添加规格参数的聚合
params.forEach(param->{
queryBuilder.addAggregation(AggregationBuilders.terms(param.getName()).field("specs." + param.getName() + ".keyword"));
});
//添加结果集过滤
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{},null));
//执行聚合查询,获取聚合结果集
AggregatedPage<Goods> goodsPage = (AggregatedPage<Goods>) this.goodsRepository.search(queryBuilder.build());
List<Map<String,Object>> specs =new ArrayList<>();
//解析聚合结果集,key-聚合名称(规格参数名) value-聚合对象
Map<String, Aggregation> aggregationMap = goodsPage.getAggregations().asMap();
for (Map.Entry<String, Aggregation> entry : aggregationMap.entrySet()) {
//初始化一个map {k:规格参数名 options:聚合的规格参数值}
Map<String,Object> map=new HashMap<>();
map.put("k",entry.getKey());
//初始化一个options集合,收集桶中的key
List<String> options = new ArrayList<>();
//获取聚合
StringTerms terms = (StringTerms) entry.getValue();
//获取桶集合
terms.getBuckets().forEach(bucket -> {
options.add(bucket.getKeyAsString());
});
map.put("options",options);
specs.add(map);
}
return specs;
}
要注意的是,这里我们需要根据分类id查询规格,而规格参数接口需要从商品微服务提供
聚合规格参数
因为规格参数保存时不做分词,因此其名称会自动带上一个.keyword后缀:
解析聚合结果
最终代码如上
页面渲染
渲染规格过滤条件
首先把后台传递过来的specs添加到filters数组:
要注意:分类、品牌的option选项是对象,里面有name属性,而specs中的option是简单的字符串,所以需要进行封装,变为相同的结构:
///search.html中的代码 loadData方法中的
data.specs.forEach(spec => {
spec.options = spec.options.map(o => ({name:o}))
this.filters.push(spec);
})
最后的结果

展示或收起过滤条件
是不是感觉显示的太多了,我们可以通过按钮点击来展开和隐藏部分内容:

我们在data中定义变量,记录展开或隐藏的状态:

然后在按钮绑定点击事件,以改变show的取值:
<!--selector-->
<div class="clearfix selector">
<div class="type-wrap" v-for="(f,index) in filters" :key="index" v-if="f.k !== '品牌'" v-show="index < 5 || show">
<div class="fl key">{{f.k}}</div>
<div class="fl value">
<ul class="type-list">
<li v-for="(o,j) in f.options" :key="j" @click="selectFilter(f.k, o)">
<a>{{o.name}}</a>
</li>
</ul>
</div>
<div class="fl ext"></div>
</div>
<div class="type-wrap logo" v-else>
<div class="fl key brand">{{f.k}}</div>
<div class="value logos">
<ul class="logo-list">
<li v-for="(o,j) in f.options" :key="j" v-if="o.image" @click="selectFilter(f.k, o)">
<img :src="o.image" /></li>
<li style="text-align: center" v-else @click="selectFilter(f.k, o)"><a style="line-height: 30px; font-size: 12px" href="#">{{o.name}}</a></li>
</ul>
</div>
<div class="fl ext">
<a href="javascript:void(0);" class="sui-btn">多选</a>
</div>
</div>
<div class="type-wrap" style="text-align: center">
<v-btn small flat @click="show = true" v-show="!show">
更多<v-icon>arrow_drop_down</v-icon>
</v-btn>
<v-btn small="" flat @click="show = false" v-show="show">
收起<v-icon>arrow_drop_up</v-icon>
</v-btn>
</div>
过滤条件的筛选
保存过滤项
定义属性
我们把已选择的过滤项保存在search中:

要注意,在created构造函数中会对search进行初始化,所以要在构造函数中对filter进行初始化:

search.filter是一个对象,结构:
{
"过滤项名":"过滤项值"
}
绑定点击事件

要注意,点击事件传2个参数:
- k:过滤项的key
- option:当前过滤项对象
在点击事件中,保存过滤项到selectedFilter:
selectFilter(k, o){
const obj = {};
Object.assign(obj, this.search);
if(k === '分类' || k === '品牌'){
o = o.id;
}
obj.filter[k] = o.name || o;
this.search = obj;
}
另外,这里search对象中嵌套了filter对象,请求参数格式化时需要进行特殊处理,修改common.js中的一段代码:

我们刷新页面,点击后通过浏览器功能查看search.filter的属性变化:

并且,此时浏览器地址也发生了变化:
http://www.leyou.com/search.html?key=%E6%89%8B%E6%9C%BA&page=1&filter.%E5%93%81%E7%89%8C=2032&filter.CPU%E5%93%81%E7%89%8C=%E6%B5%B7%E6%80%9D%EF%BC%88Hisilicon%EF%BC%89&filter.CPU%E6%A0%B8%E6%95%B0=%E5%8D%81%E6%A0%B8
网络请求也正常发出:

后台添加过滤条件
既然请求已经发送到了后台,那接下来我们就在后台去添加这些条件:
拓展请求对象
我们需要在请求类:SearchRequest中添加属性,接收过滤属性。过滤属性都是键值对格式,但是key不确定,所以用一个map来接收即可。

同时添加get和set方法
添加过滤条件
目前,我们的基本查询是这样的:

现在,我们要把页面传递的过滤条件也加入进去。
因此不能在使用普通的查询,而是要用到BooleanQuery,基本结构是这样的:
GET /heima/_search
{
"query":{
"bool":{
"must":{ "match": { "title": "小米手机",operator:"and"}},
"filter":{
"range":{"price":{"gt":2000.00,"lt":3800.00}}
}
}
}
}
所以,我们对原来的基本查询进行改造:(SearchService中的search方法)


因为比较复杂,我们将其封装到一个方法中:
/**
* \构建布尔查询
* @param request
* @return
*/
private BoolQueryBuilder buildBoolQueryBuilder(SearchRequest request) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//给布尔查询添加基本查询条件
boolQueryBuilder.must(QueryBuilders.matchQuery("all",request.getKey()).operator(Operator.AND));
//添加过滤条件
//获取用户选择的过滤信息
Map<String,Object> filter=request.getFilter();
for (Map.Entry<String, Object> entry : filter.entrySet()) {
String key = entry.getKey();
if(StringUtils.equals("品牌",key)){
key="brandId";
}else if(StringUtils.equals("分类",key)) {
key="cid3";
}else {
key="specs." + key+".keyword";
}
boolQueryBuilder.filter(QueryBuilders.termQuery(key,entry.getValue()));
}
return boolQueryBuilder;
}
页面测试
我们先不点击过滤条件,直接搜索手机:

接下来,我们点击一个过滤条件:
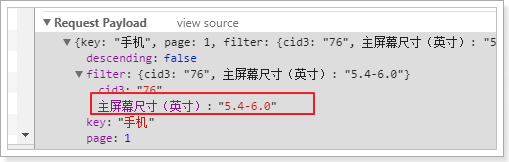
得到的结果:

优化
搜索系统需要优化的点:
- 查询规格参数部分可以添加缓存
- 聚合计算interval变化频率极低,所以可以设计为定时任务计算(周期为天),然后缓存起来。
- elasticsearch本身有查询缓存,可以不进行优化
- 商品图片应该采用缩略图,减少流量,提高页面加载速度
- 图片采用延迟加载
- 图片还可以采用CDN服务器
- sku信息应该在页面异步加载,而不是放到索引库
商品详情和页面静态化
商品详情
当用户搜索到商品,肯定会点击查看,就会进入商品详情页,接下来我们完成商品详情页的展示,
Thymeleaf
官方网站:https://www.thymeleaf.org/index.html
Thymeleaf是用来开发Web和独立环境项目的现代服务器端Java模板引擎。
Thymeleaf的主要目标是为您的开发工作流程带来优雅的自然模板 - HTML。可以在直接浏览器中正确显示,并且可以作为静态原型,从而在开发团队中实现更强大的协作。
借助Spring Framework的模块,可以根据自己的喜好进行自由选择,可插拔功能组件,Thymeleaf是现代HTML5 JVM Web开发的理想选择 - 尽管它可以做的更多。
Spring官方支持的服务的渲染模板中,并不包含jsp。而是Thymeleaf和Freemarker等,而Thymeleaf与SpringMVC的视图技术,及SpringBoot的自动化配置集成非常完美,几乎没有任何成本,你只用关注Thymeleaf的语法即可。
Thymeleaf的主要作用是把model中的数据渲染到html中,因此其语法主要是如何解析model中的数据。语法方面从以下方面来学习:
- 变量
- 方法
- 条件判断
- 循环
- 运算
- 逻辑运算
- 布尔运算
- 比较运算
- 条件运算
- 其它
变量
变量案例
我们先新建一个实体类:User
public class User {
String name;
int age;
User friend;// 对象类型属性
}
然后在模型中添加数据
@GetMapping("show2")
public String show2(Model model){
User user = new User();
user.setAge(21);
user.setName("Jack Chen");
user.setFriend(new User("李小龙", 30));
model.addAttribute("user", user);
return "show2";
}
语法说明:
Thymeleaf通过${}来获取model中的变量,注意这不是el表达式,而是ognl表达式,但是语法非常像。
示例:
我们在页面获取user数据:
<h1>
欢迎您:<span th:text="${user.name}">请登录span>
h1>
效果:

感觉跟el表达式几乎是一样的。不过区别在于,我们的表达式写在一个名为:th:text的标签属性中,这个叫做指令
动静结合
指令:
Thymeleaf崇尚自然模板,意思就是模板是纯正的html代码,脱离模板引擎,在纯静态环境也可以直接运行。现在如果我们直接在html中编写 ${}这样的表达式,显然在静态环境下就会出错,这不符合Thymeleaf的理念。
Thymeleaf中所有的表达式都需要写在指令中,指令是HTML5中的自定义属性,在Thymeleaf中所有指令都是以th:开头。因为表达式${user.name}是写在自定义属性中,因此在静态环境下,表达式的内容会被当做是普通字符串,浏览器会自动忽略这些指令,这样就不会报错了!
现在,我们不经过SpringMVC,而是直接用浏览器打开页面看看:

- 静态页面中,
th指令不被识别,但是浏览器也不会报错,把它当做一个普通属性处理。这样span的默认值请登录就会展现在页面 - 如果是在Thymeleaf环境下,
th指令就会被识别和解析,而th:text的含义就是替换所在标签中的文本内容,于是user.name的值就替代了span中默认的请登录
指令的设计,正是Thymeleaf的高明之处,也是它优于其它模板引擎的原因。动静结合的设计,使得无论是前端开发人员还是后端开发人员可以完美契合。
向下兼容
但是要注意,如果浏览器不支持Html5怎么办?
如果不支持这种th:的命名空间写法,那么可以把th:text换成 data-th-text,Thymeleaf也可以兼容。
escape
另外,th:text指令出于安全考虑,会把表达式读取到的值进行处理,防止html的注入。
例如, 你好$lt;p$gt;你好$lt;/p$lt;。
如果想要不进行格式化输出,而是要输出原始内容,则使用th:utext来代替.
ognl表达式的语法糖
刚才获取变量值,我们使用的是经典的对象.属性名方式。但有些情况下,我们的属性名可能本身也是变量,怎么办?
ognl提供了类似js的语法方式:
例如:${user.name} 可以写作${user['name']}
自定义变量
场景
看下面的案例:
<h2>
<p>Name: <span th:text="${user.name}">Jackspan>.p>
<p>Age: <span th:text="${user.age}">21span>.p>
<p>friend: <span th:text="${user.friend.name}">Rosespan>.p>
h2>
我们获取用户的所有信息,分别展示。
当数据量比较多的时候,频繁的写user.就会非常麻烦。
因此,Thymeleaf提供了自定义变量来解决:
示例:
<h2 th:object="${user}">
<p>Name: <span th:text="*{name}">Jackspan>.p>
<p>Age: <span th:text="*{age}">21span>.p>
<p>friend: <span th:text="*{friend.name}">Rosespan>.p>
h2>
- 首先在
h2上 用th:object="${user}"获取user的值,并且保存 - 然后,在
h2内部的任意元素上,可以通过*{属性名}的方式,来获取user中的属性,这样就省去了大量的user.前缀了
方法
ognl表达式中的方法调用
ognl表达式本身就支持方法调用,例如:
<h2 th:object="${user}">
<p>FirstName: <span th:text="*{name.split(' ')[0]}">Jackspan>.p>
<p>LastName: <span th:text="*{name.split(' ')[1]}">Lispan>.p>
h2>
- 这里我们调用了name(是一个字符串)的split方法。
Thymeleaf内置对象
Thymeleaf中提供了一些内置对象,并且在这些对象中提供了一些方法,方便我们来调用。获取这些对象,需要使用#对象名来引用。
- 一些环境相关对象
| 对象 | 作用 |
|---|---|
#ctx |
获取Thymeleaf自己的Context对象 |
#requset |
如果是web程序,可以获取HttpServletRequest对象 |
#response |
如果是web程序,可以获取HttpServletReponse对象 |
#session |
如果是web程序,可以获取HttpSession对象 |
#servletContext |
如果是web程序,可以获取HttpServletContext对象 |
- Thymeleaf提供的全局对象:
| 对象 | 作用 |
|---|---|
#dates |
处理java.util.date的工具对象 |
#calendars |
处理java.util.calendar的工具对象 |
#numbers |
用来对数字格式化的方法 |
#strings |
用来处理字符串的方法 |
#bools |
用来判断布尔值的方法 |
#arrays |
用来护理数组的方法 |
#lists |
用来处理List集合的方法 |
#sets |
用来处理set集合的方法 |
#maps |
用来处理map集合的方法 |
- 举例
我们在环境变量中添加日期类型对象
@GetMapping("show3")
public String show3(Model model){
model.addAttribute("today", new Date());
return "show3";
}
在页面中处理
<p>
今天是: <span th:text="${#dates.format(today,'yyyy-MM-dd')}">2018-04-25span>
p>
效果:

字面值
有的时候,我们需要在指令中填写基本类型如:字符串、数值、布尔等,并不希望被Thymeleaf解析为变量,这个时候称为字面值。
-
字符串字面值
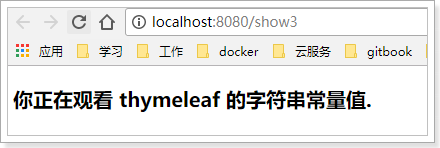
使用一对
'引用的内容就是字符串字面值了:<p> 你正在观看 <span th:text="'thymeleaf'">templatespan> 的字符串常量值. p>th:text中的thymeleaf并不会被认为是变量,而是一个字符串
数字字面值
数字不需要任何特殊语法, 写的什么就是什么,而且可以直接进行算术运算
<p>今年是 <span th:text="2018">1900span>.p>
<p>两年后将会是 <span th:text="2018 + 2">1902span>.p>

- 布尔字面值
布尔类型的字面值是true或false:
<div th:if="true">
你填的是true
div>
这里引用了一个th:if指令,跟vue中的v-if类似
拼接
我们经常会用到普通字符串与表达式拼接的情况:
<span th:text="'欢迎您:' + ${user.name} + '!'">span>
字符串字面值需要用'',拼接起来非常麻烦,Thymeleaf对此进行了简化,使用一对|即可:
<span th:text="|欢迎您:${user.name}|">span>
与上面是完全等效的,这样就省去了字符串字面值的书写。

运算
需要注意:${}内部的是通过OGNL表达式引擎解析的,外部的才是通过Thymeleaf的引擎解析,因此运算符尽量放在${}外进行。
-
算术运算
支持的算术运算符:
+ - * / %<span th:text="${user.age}">span> <span th:text="${user.age}%2 == 0">span>
-
比较运算
支持的比较运算:
>,<,>=and<=,但是>,<不能直接使用,因为xml会解析为标签,要使用别名。注意
==and!=不仅可以比较数值,类似于equals的功能。可以使用的别名:
gt (>), lt (<), ge (>=), le (<=), not (!). Also eq (==), neq/ne (!=). -
条件运算
- 三元运算
<span th:text="${user.sex} ? '男':'女'">span>三元运算符的三个部分:conditon ? then : else
condition:条件
then:条件成立的结果
else:不成立的结果
其中的每一个部分都可以是Thymeleaf中的任意表达式。

-
默认值
有的时候,我们取一个值可能为空,这个时候需要做非空判断,可以使用
表达式 ?: 默认值简写:
<span th:text="${user.name} ?: '二狗'">span>
当前面的表达式值为null时,就会使用后面的默认值。
注意:?:之间没有空格。

循环
循环也是非常频繁使用的需求,我们使用th:each指令来完成:
假如有用户的集合:users在Context中。
<tr th:each="user : ${users}">
<td th:text="${user.name}">Onionstd>
<td th:text="${user.age}">2.41td>
tr>
- ${users} 是要遍历的集合,可以是以下类型:
- Iterable,实现了Iterable接口的类
- Enumeration,枚举
- Interator,迭代器
- Map,遍历得到的是Map.Entry
- Array,数组及其它一切符合数组结果的对象
在迭代的同时,我们也可以获取迭代的状态对象:
<tr th:each="user,stat : ${users}">
<td th:text="${user.name}">Onionstd>
<td th:text="${user.age}">2.41td>
tr>
stat对象包含以下属性:
- index,从0开始的角标
- count,元素的个数,从1开始
- size,总元素个数
- current,当前遍历到的元素
- even/odd,返回是否为奇偶,boolean值
- first/last,返回是否为第一或最后,boolean值
逻辑判断
有了if和else,我们能实现一切功能_。
Thymeleaf中使用th:if 或者 th:unless ,两者的意思恰好相反。
<span th:if="${user.age} < 24">小鲜肉span>
如果表达式的值为true,则标签会渲染到页面,否则不进行渲染。
以下情况被认定为true:
- 表达式值为true
- 表达式值为非0数值
- 表达式值为非0字符
- 表达式值为字符串,但不是
"false","no","off" - 表达式不是布尔、字符串、数字、字符中的任何一种
其它情况包括null都被认定为false

分支控制switch
这里要使用两个指令:th:switch 和 th:case
<div th:switch="${user.role}">
<p th:case="'admin'">用户是管理员p>
<p th:case="'manager'">用户是经理p>
<p th:case="*">用户是别的玩意p>
div>
需要注意的是,一旦有一个th:case成立,其它的则不再判断。与java中的switch是一样的。
另外th:case="*"表示默认,放最后。


JS模板
模板引擎不仅可以渲染html,也可以对JS中的进行预处理。而且为了在纯静态环境下可以运行,其Thymeleaf代码可以被注释起来:
<script th:inline="javascript">
const user = /*[[${user}]]*/ {};
const age = /*[[${user.age}]]*/ 20;
console.log(user);
console.log(age)
script>
-
在script标签中通过
th:inline="javascript"来声明这是要特殊处理的js脚本 -
语法结构:
const user = /*[[Thymeleaf表达式]]*/ "静态环境下的默认值";因为Thymeleaf被注释起来,因此即便是静态环境下, js代码也不会报错,而是采用表达式后面跟着的默认值。
看看页面的源码:

我们的User对象被直接处理为json格式了,非常方便。
控制台:

商品详情页服务
商品详情浏览量比较大,并发高,我们会独立开启一个微服务,用来展示商品详情。
new Module-maven
Group:com.leyou.goods
Artifact:leyou-goods-web
Version:1.0.0-SNAPSHOT
Module name:leyou-goods-web
pom依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>leyouartifactId>
<groupId>com.leyou.parentgroupId>
<version>1.0.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<groupId>com.leyou.goodsgroupId>
<artifactId>leyou-goods-webartifactId>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
<version>2.0.2.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
<dependency>
<groupId>com.leyou.itemgroupId>
<artifactId>leyou-item-interfaceartifactId>
<version>1.0.0-SNAPSHOTversion>
dependency>
<dependency>
<groupId>com.leyou.commongroupId>
<artifactId>leyou-commonartifactId>
<version>1.0.0-SNAPSHOTversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
dependencies>
project>
启动类
配置exclude可以覆盖配置
package com.leyou;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
@EnableDiscoveryClient
@EnableFeignClients
public class LeyouGoodsWebApplication {
public static void main(String[] args) {
SpringApplication.run(LeyouGoodsWebApplication.class);
}
}
application.yml文件
server:
port: 8084
spring:
application:
name: goods-web
thymeleaf:
cache: false
eureka:
client:
service-url:
defaultZone: http://localhost:10086/eureka
registry-fetch-interval-seconds: 5
页面模板
我们从leyou-portal中复制item.html模板到当前项目resource目录下的templates中:
加入模板:在第二行覆盖
<html lang="en" xmlns:th="http://www.thymeleaf.org">
页面跳转
修改页面跳转路径
首先我们需要修改搜索结果页的商品地址,目前所有商品的地址都是:http://www.leyou.com/item.html
我们应该跳转到对应的商品的详情页才对。
那么问题来了:商品详情页是一个SKU?还是多个SKU的集合?
通过详情页的预览,我们知道它是多个SKU的集合,即SPU。
所以,页面跳转时,我们应该携带SPU的id信息。
例如:http://www.leyou.com/item/2314123.html
这里就采用了路径占位符的方式来传递spu的id,我们打开search.html,修改其中的商品路径:
<div class="goods-list">
<ul class="yui3-g">
<li class="yui3-u-1-5" v-for="(goods,index) in goodsList":key="index">
<div class="list-wrap">
<div class="p-img">
<a :href="'item/' + goods.id + '.html'" target="_blank"><img :src="goods.selected.image" height="200"/>a>
<ul class="skus">
<li :class="{selected: goods.selected.id==sku.id}" v-for="(sku,j) in goods.skus" @mouseOver="goods.selected=sku">
<img :src="sku.image">
li>
ul>
div>
nginx反向代理
接下来,我们要把这个地址指向我们刚刚创建的服务:leyou-goods-web,其端口为8084
我们在nginx.conf中添加一段逻辑:
把以/item开头的请求,代理到我们的8084端口。
编写跳转controller
在leyou-goods-web中编写controller,接收请求,并跳转到商品详情页:
@Controller
@RequestMapping("item")
public class GoodsController {
/**
* 跳转到商品详情页
* @param model
* @param id
* @return
*/
@GetMapping("{id}.html")
public String toItemPage(Model model, @PathVariable("id")Long id){
return "item";
}
}
封装模型数据
首先我们一起来分析一下,在这个页面中需要哪些数据
我们已知的条件是传递来的spu的id,我们需要根据spu的id查询到下面的数据:
- spu信息
- spu的详情
- spu下的所有sku
- 品牌
- 商品三级分类
- 商品规格参数、规格参数组
商品微服务提供接口
查询spu
以上所需数据中,根据id查询spu的接口目前还没有,我们需要在商品微服务中提供这个接口:
GoodsApi
/**
* 根据spu的id查询spu
* @param id
* @return
*/
@GetMapping("{id}")
public Spu querySpuById(@PathVariable("id") Long id);
GoodsController
@GetMapping("{id}")
public ResponseEntity<Spu> querySpuById(@PathVariable("id") Long id){
Spu spu = this.goodsService.querySpuById(id);
if(spu == null){
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
return ResponseEntity.ok(spu);
}
GoodsService
public Spu querySpuById(Long id) {
return this.spuMapper.selectByPrimaryKey(id);
}
查询规格参数组
我们在页面展示规格时,需要按组展示:

组内有多个参数,为了方便展示。我们在leyou-item-service中提供一个接口,查询规格组,同时在规格组内的所有参数。
拓展
SpecGroup类:
我们在SpecGroup中添加一个SpecParam的集合,保存该组下所有规格参数
@Table(name = "tb_spec_group")
public class SpecGroup {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long cid;
private String name;
@Transient
private List<SpecParam> params; // 该组下的所有规格参数集合
}
然后提供查询接口:
SpecificationAPI:
@RequestMapping("spec")
public interface SpecificationApi {
@GetMapping("groups/{cid}")
public ResponseEntity<List<SpecGroup>> querySpecGroups(@PathVariable("cid") Long cid);
@GetMapping("/params")
public List<SpecParam> querySpecParam(
@RequestParam(value = "gid", required = false) Long gid,
@RequestParam(value = "cid", required = false) Long cid,
@RequestParam(value = "searching", required = false) Boolean searching,
@RequestParam(value = "generic", required = false) Boolean generic);
// 查询规格参数组,及组内参数
@GetMapping("{cid}")
List<SpecGroup> querySpecsByCid(@PathVariable("cid") Long cid);
}
SpecificationController
@GetMapping("{cid}")
public ResponseEntity<List<SpecGroup>> querySpecsByCid(@PathVariable("cid") Long cid){
List<SpecGroup> list = this.specificationService.querySpecsByCid(cid);
if(list == null || list.size() == 0){
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
return ResponseEntity.ok(list);
}
SpecificationService
public List<SpecGroup> querySpecsByCid(Long cid) {
// 查询规格组
List<SpecGroup> groups = this.querySpecGroups(cid);
groups.forEach(g -> {
// 查询组内参数
g.setParams(this.querySpecParams(g.getId(), null, null, null));
});
return groups;
}
在service中,我们调用之前编写过的方法,查询规格组,和规格参数,然后封装返回。
创建FeignClient
我们在leyou-goods-web服务中,创建FeignClient:

BrandClient:
@FeignClient("item-service")
public interface BrandClient extends BrandApi {
}
CategoryClient
@FeignClient("item-service")
public interface CategoryClient extends CategoryApi {
}
GoodsClient:
@FeignClient("item-service")
public interface GoodsClient extends GoodsApi {
}
SpecificationClient:
@FeignClient(value = "item-service")
public interface SpecificationClient extends SpecificationApi{
}
封装数据模型
我们创建一个GoodsService,在里面来封装数据模型。
这里要查询的数据:
-
SPU
-
SpuDetail
-
SKU集合
-
商品分类
- 这里值需要分类的id和name就够了,因此我们查询到以后自己需要封装数据
-
品牌对象
-
规格组
- 查询规格组的时候,把规格组下所有的参数也一并查出,上面提供的接口中已经实现该功能,我们直接调
-
sku的特有规格参数
有了规格组,为什么这里还要查询?
因为在SpuDetail中的SpecialSpec中,是以id作为规格参数id作为key,如图:

但是,在页面渲染时,需要知道参数的名称,如图:
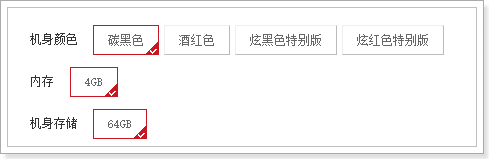
我们就需要把id和name一一对应起来,因此需要额外查询sku的特有规格参数,然后变成一个id:name的键值对格式。也就是一个Map,方便将来根据id查找!
leyou-goods-web
service
package com.leyou.goods.service;
import com.leyou.goods.client.BrandClient;
import com.leyou.goods.client.CategoryClient;
import com.leyou.goods.client.GoodsClient;
import com.leyou.goods.client.SpecificationClient;
import com.leyou.item.pojo.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.*;
@Service
public class GoodsService {
@Autowired
private BrandClient brandClient;
@Autowired
private CategoryClient categoryClient;
@Autowired
private GoodsClient goodsClient;
@Autowired
private SpecificationClient specificationClient;
public Map<String,Object> loadData(Long spuId){
Map<String,Object> model = new HashMap<>();
//根据spuId查询spu
Spu spu = this.goodsClient.querySpuById(spuId);
//查询spuDetail
SpuDetail spuDetail = this.goodsClient.querySpuDetailBySpuId(spuId);
//查询分类Map然后在controller中把数据放入model:
@Controller
@RequestMapping("item")
public class GoodsController {
@Autowired
private GoodsService goodsService;
/**
* 跳转到商品详情页
* @param model
* @param id
* @return
*/
@GetMapping("{id}.html")
public String toItemPage(Model model, @PathVariable("id")Long id){
// 加载所需的数据
Map<String, Object> modelMap = this.goodsService.loadModel(id);
// 放入模型
model.addAllAttributes(modelMap);
return "item";
}
}
页面测试数据
我们在页面中先写一段JS,把模型中的数据取出观察,看是否成功:
<script th:inline="javascript">
const a = /*[[${groups}]]*/ [];
const b = /*[[${params}]]*/ [];
const c = /*[[${categories}]]*/ [];
const d = /*[[${spu}]]*/ {};
const e = /*[[${spuDetail}]]*/ {};
const f = /*[[${skus}]]*/ [];
const g = /*[[${brand}]]*/ {};
script>
然后查看页面源码:

渲染面包屑
在商品展示页的顶部,有一个商品分类、品牌、标题的面包屑

其数据有3部分:
- 商品分类
- 商品品牌
- spu标题
我们的模型中都有,所以直接渲染即可(页面101行开始):
<div class="crumb-wrap">
<ul class="sui-breadcrumb">
<li th:each="category : ${categories}">
<a href="#" th:text="${category.name}">手机a>
li>
<li>
<a href="#" th:text="${brand.name}">Applea>
li>
<li class="active" th:text="${spu.title}">Apple iPhone 6sli>
ul>
div>
渲染商品列表
先看下整体效果:

这个部分需要渲染的数据有5块:
- sku图片
- sku标题
- 副标题
- sku价格
- 特有规格属性列表
其中,sku 的图片、标题、价格,都必须在用户选中一个具体sku后,才能渲染。而特有规格属性列表可以在spuDetail中查询到。而副标题则是在spu中,直接可以在页面渲染
因此,我们先对特有规格属性列表进行渲染。等用户选择一个sku,再通过js对其它sku属性渲染
副标题
副标题是在spu中,所以我们直接通过Thymeleaf渲染:
在第146行左右:
<div class="news"><span th:utext="${spu.subTitle}">span>div>
副标题中可能会有超链接,因此这里也用th:utext来展示,效果:

渲染规格属性列表
规格属性列表将来会有事件和动态效果。我们需要有js代码参与,不能使用Thymeleaf来渲染了。
因此,这里我们用vue,不过需要先把数据放到js对象中,方便vue使用
初始化数据
我们在页面的head中,定义一个js标签,然后在里面定义变量,保存与sku相关的一些数据:
<script th:inline="javascript">
// sku集合
const skus = /*[[${skus}]]*/ [];
// 规格参数id与name对
const paramMap = /*[[${params}]]*/ {};
// 特有规格参数集合
const specialSpec = JSON.parse(/*[[${spuDetail.specialSpec}]]*/ "");
script>
-
specialSpec:这是SpuDetail中唯一与Sku相关的数据
因此我们并没有保存整个spuDetail,而是只保留了这个属性,而且需要手动转为js对象。
-
paramMap:规格参数的id和name键值对,方便页面根据id获取参数名
-
skus:sku集合
我们来看下页面获取的数据:

通过Vue渲染
我们把刚才获得的几个变量保存在Vue实例中:
 然后在页面中渲染:
然后在页面中渲染:
<div id="specification" class="summary-wrap clearfix">
<dl v-for="(v,k) in specialSpec" :key="k">
<dt>
<div class="fl title">
<i>{{paramMap[k]}}i>
div>
dt>
<dd v-for="(str,j) in v" :key="j">
<a href="javascript:;" class="selected">
{{str}}<span title="点击取消选择"> span>
a>
dd>
dl>
div>
然后刷新页面查看:

数据成功渲染了。不过我们发现所有的规格都被勾选了。这是因为现在,每一个规格都有样式:selected,我们应该只选中一个,让它的class样式为selected才对!
那么问题来了,我们该如何确定用户选择了哪一个?
规格属性的筛选
分析
规格参数的格式是这样的:

每一个规格项是数组中的一个元素,因此我们只要保存被选择的规格项的索引,就能判断哪个是用户选择的了!
我们需要一个对象来保存用户选择的索引,格式如下:
{
"4":0,
"12":0,
"13":0
}
但问题是,第一次进入页面时,用户并未选择任何参数。因此索引应该有一个默认值,我们将默认值设置为0。
我们在head的script标签中,对索引对象进行初始化:


页面改造
我们在页面中,通过判断indexes的值来判断当前规格是否被选中,并且给规格绑定点击事件,点击规格项后,修改indexes中的对应值:
<div id="specification" class="summary-wrap clearfix">
<dl v-for="(v,k) in specialSpec" :key="k">
<dt>
<div class="fl title">
<i>{{paramMap[k]}}i>
div>
dt>
<dd v-for="(str,j) in v" :key="j">
<a href="javascript:;" :class="{selected: j===indexes[k]}" @click="indexes[k]=j">
{{str}}<span v-if="j===indexes[k]" title="点击取消选择"> span>
a>
dd>
dl>
div>
效果:

确定SKU
在我们设计sku数据的时候,就已经添加了一个字段:indexes:

这其实就是规格参数的索引组合。
而我们在页面中,用户点击选择规格后,就会把对应的索引保存起来:

因此,我们可以根据这个indexes来确定用户要选择的sku
我们在vue中定义一个计算属性,来计算与索引匹配的sku:
computed:{
sku(){
const index = Object.values(this.indexes).join("_");
return this.skus.find(s => s.indexes == index);
}
}
在浏览器工具中查看:

渲染sku列表
既然已经拿到了用户选中的sku,接下来,就可以在页面渲染数据了
图片列表
商品图片是一个字符串,以,分割,页面展示比较麻烦,所以我们编写一个**计算属性:**images(),将图片字符串变成数组:
computed: {
sku(){
const index = Object.values(this.indexes).join("_");
return this.skus.find(s=>s.indexes==index);
},
images(){
return this.sku.images ? this.sku.images.split(",") : [''];
}
},
页面改造:
<div class="zoom">
<div id="preview" class="spec-preview">
<span class="jqzoom">
<img :jqimg="images[0]" :src="images[0]" width="400px" height="400px"/>
span>
div>
<div class="spec-scroll">
<a class="prev"><a>
<div class="items">
<ul>
<li v-for="(image, i) in images" :key="i">
<img :src="image" :bimg="image" onmousemove="preview(this)" />
li>
ul>
div>
<a class="next">>a>
div>
div>
效果:

标题和价格

完整效果

商品详情
商品详情页面如下图所示:

分成上下两部分:
- 上部:展示的是规格属性列表
- 下部:展示的是商品详情
商品详情是HTML代码,我们不能使用 th:text,应该使用th:utext
在页面的第444行左右:
<div class="intro-detail" th:utext="${spuDetail.description}">
div>
最终展示效果:
规格包装
规格包装分成两部分:
- 规格参数
- 包装列表
而且规格参数需要按照组来显示
规格参数
最终的效果:

们模型中有一个groups,跟这个数据结果很像:

分成8个组,组内都有params,里面是所有的参数。不过,这些参数都没有值!
规格参数的值分为两部分:
- 通用规格参数:保存在SpuDetail中的genericSpec中
- 特有规格参数:保存在sku的ownSpec中
我们需要把这两部分值取出来,放到groups中。
从spuDetail中取出genericSpec并取出groups:

把genericSpec引入到Vue实例:

因为sku是动态的,所以我们编写一个计算属性,来进行值的组合:
groups(){
groups.forEach(group => {
group.params.forEach(param => {
if(param.generic){
// 通用属性,去spu的genericSpec中获取
param.v = this.genericSpec[param.id] || '其它';
}else{
// 特有属性值,去SKU中获取
param.v = JSON.parse(this.sku.ownSpec)[param.id]
}
})
})
return groups;
}
然后在页面渲染:
<div class="Ptable">
<div class="Ptable-item" v-for="group in groups" :key="group.name">
<h3>{{group.name}}h3>
<dl>
<div v-for="p in group.params">
<dt>{{p.name}}dt><dd>{{p.v + (p.unit || '')}}dd>
div>
dl>
div>
div>
包装列表
包装列表在商品详情中,我们一开始并没有赋值到Vue实例中,但是可以通过Thymeleaf来渲染
<div class="package-list">
<h3>包装清单h3>
<p th:text="${spuDetail.packingList}">p>
div>
最终效果:

售后服务
售后服务也可以通过Thymeleaf进行渲染:
<div id="three" class="tab-pane">
<p>售后保障p>
<p th:text="${spuDetail.afterService}">p>
div>
页面静态化
简介
问题分析
现在,我们的页面是通过Thymeleaf模板引擎渲染后返回到客户端。在后台需要大量的数据查询,而后渲染得到HTML页面。会对数据库造成压力,并且请求的响应时间过长,并发能力不高。
大家能想到什么办法来解决这个问题?
首先我们能想到的就是缓存技术,比如之前学习过的Redis。不过Redis适合数据规模比较小的情况。假如数据量比较大,例如我们的商品详情页。每个页面如果10kb,100万商品,就是10GB空间,对内存占用比较大。此时就给缓存系统带来极大压力,如果缓存崩溃,接下来倒霉的就是数据库了。
所以缓存并不是万能的,某些场景需要其它技术来解决,比如静态化。
什么是静态化
静态化是指把动态生成的HTML页面变为静态内容保存,以后用户的请求到来,直接访问静态页面,不再经过服务的渲染。
而静态的HTML页面可以部署在nginx中,从而大大提高并发能力,减小tomcat压力。
如何实现静态化
目前,静态化页面都是通过模板引擎来生成,而后保存到nginx服务器来部署。常用的模板引擎比如:
- Freemarker
- Velocity
- Thymeleaf
我们之前就使用的Thymeleaf,来渲染html返回给用户。Thymeleaf除了可以把渲染结果写入Response,也可以写到本地文件,从而实现静态化。
实现静态化
概念
先说下Thymeleaf中的几个概念:
- Context:运行上下文
- TemplateResolver:模板解析器
- TemplateEngine:模板引擎
Context
上下文: 用来保存模型数据,当模板引擎渲染时,可以从Context上下文中获取数据用于渲染。
当与SpringBoot结合使用时,我们放入Model的数据就会被处理到Context,作为模板渲染的数据使用。
TemplateResolver
模板解析器:用来读取模板相关的配置,例如:模板存放的位置信息,模板文件名称,模板文件的类型等等。
当与SpringBoot结合时,TemplateResolver已经由其创建完成,并且各种配置也都有默认值,比如模板存放位置,其默认值就是:templates。比如模板文件类型,其默认值就是html。
TemplateEngine
模板引擎:用来解析模板的引擎,需要使用到上下文、模板解析器。分别从两者中获取模板中需要的数据,模板文件。然后利用内置的语法规则解析,从而输出解析后的文件。来看下模板引擎进行处理的函数:
templateEngine.process("模板名", context, writer);
三个参数:
- 模板名称
- 上下文:里面包含模型数据
- writer:输出目的地的流
在输出时,我们可以指定输出的目的地,如果目的地是Response的流,那就是网络响应。如果目的地是本地文件,那就实现静态化了。
而在SpringBoot中已经自动配置了模板引擎,因此我们不需要关心这个。现在我们做静态化,就是把输出的目的地改成本地文件即可!
具体实现

Service代码:
@Service
public class GoodsHtmlService {
@Autowired
private GoodsService goodsService;
@Autowired
private TemplateEngine templateEngine;
private static final Logger LOGGER = LoggerFactory.getLogger(GoodsHtmlService.class);
/**
* 创建html页面
*
* @param spuId
* @throws Exception
*/
public void createHtml(Long spuId) {
PrintWriter writer = null;
try {
// 获取页面数据
Map<String, Object> spuMap = this.goodsService.loadModel(spuId);
// 创建thymeleaf上下文对象
Context context = new Context();
// 把数据放入上下文对象
context.setVariables(spuMap);
// 创建输出流
File file = new File("C:\\project\\nginx-1.14.0\\html\\item\\" + spuId + ".html");
writer = new PrintWriter(file);
// 执行页面静态化方法
templateEngine.process("item", context, writer);
} catch (Exception e) {
LOGGER.error("页面静态化出错:{},"+ e, spuId);
} finally {
if (writer != null) {
writer.close();
}
}
}
/**
* 新建线程处理页面静态化
* @param spuId
*/
public void asyncExcute(Long spuId) {
ThreadUtils.execute(()->createHtml(spuId));
/*ThreadUtils.execute(new Runnable() {
@Override
public void run() {
createHtml(spuId);
}
});*/
}
}
线程工具类:
public class ThreadUtils {
private static final ExecutorService es = Executors.newFixedThreadPool(10);
public static void execute(Runnable runnable) {
es.submit(runnable);
}
}
什么时候创建静态文件
我们编写好了创建静态文件的service,那么问题来了:什么时候去调用它呢
想想这样的场景:
假如大部分的商品都有了静态页面。那么用户的请求都会被nginx拦截下来,根本不会到达我们的leyou-goods-web服务。只有那些还没有页面的请求,才可能会到达这里。
因此,如果请求到达了这里,我们除了返回页面视图外,还应该创建一个静态页面,那么下次就不会再来麻烦我们了。
所以,我们在GoodsController中添加逻辑,去生成静态html文件:
@GetMapping("{id}.html")
public String toItemPage(@PathVariable("id")Long id, Model model){
// 加载所需的数据
Map<String, Object> map = this.goodsService.loadModel(id);
// 把数据放入数据模型
model.addAllAttributes(map);
// 页面静态化
this.goodsHtmlService.asyncExcute(id);
return "item";
}
注意:生成html 的代码不能对用户请求产生影响,所以这里我们使用额外的线程进行异步创建。
重启测试
访问一个商品详情,然后查看nginx目录:

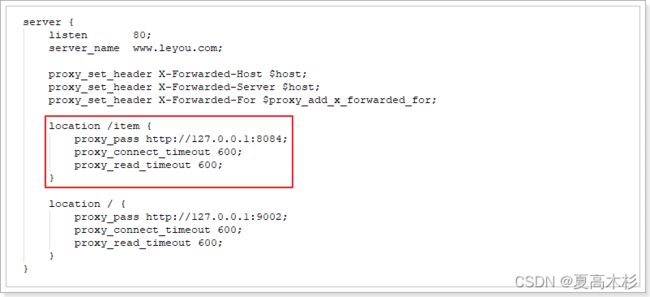
nginx代理静态页面
接下来,我们修改nginx,让它对商品请求进行监听,指向本地静态页面,如果本地没找到,才进行反向代理:
server {
listen 80;
server_name www.leyou.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location /item {
# 先找本地
root html;
if (!-f $request_filename) { #请求的文件不存在,就反向代理
proxy_pass http://127.0.0.1:8084;
break;
}
}
location / {
proxy_pass http://127.0.0.1:9002;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
重启测试:
发现请求速度得到了极大提升:
RabbitMQ 消息队列
RabbitMQ
搜索与商品服务的问题
目前我们已经完成了商品详情和搜索系统的开发。我们思考一下,是否存在问题?
- 商品的原始数据保存在数据库中,增删改查都在数据库中完成。
- 搜索服务数据来源是索引库,如果数据库商品发生变化,索引库数据不能及时更新。
- 商品详情做了页面静态化,静态页面数据也不会随着数据库商品发生变化。
如果我们在后台修改了商品的价格,搜索页面和商品详情页显示的依然是旧的价格,这样显然不对。该如何解决?
这里有两种解决方案:
- 方案1:每当后台对商品做增删改操作,同时要修改索引库数据及静态页面
- 方案2:搜索服务和商品页面服务对外提供操作接口,后台在商品增删改后,调用接口
以上两种方式都有同一个严重问题:就是代码耦合,后台服务中需要嵌入搜索和商品页面服务,违背了微服务的独立原则。
所以,我们会通过另外一种方式来解决这个问题:消息队列
消息队列(MQ)
什么是消息队列
消息队列,即MQ,Message Queue。
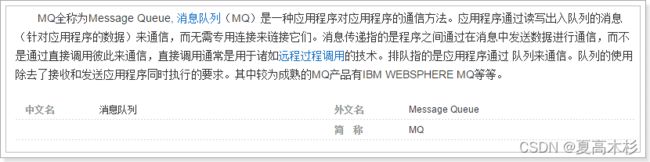
消息队列是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,这样就实现了生产者和消费者的解耦。
结合前面所说的问题:
- 商品服务对商品增删改以后,无需去操作索引库或静态页面,只是发送一条消息,也不关心消息被谁接收。
- 搜索服务和静态页面服务接收消息,分别去处理索引库和静态页面。
如果以后有其它系统也依赖商品服务的数据,同样监听消息即可,商品服务无需任何代码修改。
AMQP和JMS
MQ是消息通信的模型,并不是具体实现。现在实现MQ的有两种主流方式:AMQP、JMS。


两者间的区别和联系:
- JMS是定义了统一的接口,来对消息操作进行统一;AMQP是通过规定协议来统一数据交互的格式
- JMS限定了必须使用Java语言;AMQP只是协议,不规定实现方式,因此是跨语言的。
- JMS规定了两种消息模型;而AMQP的消息模型更加丰富
常见MQ产品

- ActiveMQ:基于JMS
- RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好
- RocketMQ:基于JMS,阿里巴巴产品,目前交由Apache基金会
- Kafka:分布式消息系统,高吞吐量
RabbitMQ
RabbitMQ是基于AMQP的一款消息管理系统
官网: http://www.rabbitmq.com/
官方教程:http://www.rabbitmq.com/getstarted.html


下载和安装
下载
官网下载地址:http://www.rabbitmq.com/download.html

目前最新版本是:3.7.5
我们的课程中使用的是:3.4.1版本
课前资料提供了安装包:
建议Linux虚拟机下载安装
cd /usr/local/leyou
mkdir rabbitmq
cd rabbitmq
安装Erlang
依次执行命令:
1)rpm -ivh esl-erlang-17.3-1.x86_64.rpm --force --nodeps
2)rpm -ivh esl-erlang_17.3-1centos6_amd64.rpm --force --nodeps
3)rpm -ivh esl-erlang-compat-R14B-1.el6.noarch.rpm --force --nodeps
安装RabbitMQ
rpm -ivh rabbitmq-server-3.4.1-1.noarch.rpm
设置配置文件
cp /usr/share/doc/rabbitmq-server-3.4.1/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
开启用户远程访问
vi /etc/rabbitmq/rabbitmq.config

注意要去掉后面的逗号。
启动、停止
service rabbitmq-server start
service rabbitmq-server stop
service rabbitmq-server restart
开启web界面管理工具
rabbitmq-plugins enable rabbitmq_management
service rabbitmq-server restart
设置开机启动
chkconfig rabbitmq-server on
防火墙开放15672端口
/sbin/iptables -I INPUT -p tcp --dport 15672 -j ACCEPT
/etc/rc.d/init.d/iptables save
管理界面

默认 账号密码都是 guest
connections:无论生产者还是消费者,都需要与RabbitMQ建立连接后才可以完成消息的生产和消费,在这里可以查看连接情况
channels:通道,建立连接后,会形成通道,消息的投递获取依赖通道。
Exchanges:交换机,用来实现消息的路由
Queues:队列,即消息队列,消息存放在队列中,等待消费,消费后被移除队列。
端口:
5672: rabbitMq的编程语言客户端连接端口
15672:rabbitMq管理界面端口
25672:rabbitMq集群的端口
添加用户
如果不使用guest,我们也可以自己创建一个用户:

1、 超级管理员(administrator)
可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作。
2、 监控者(monitoring)
可登陆管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
3、 策略制定者(policymaker)
可登陆管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)。
4、 普通管理者(management)
仅可登陆管理控制台,无法看到节点信息,也无法对策略进行管理。
5、 其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
设置权限

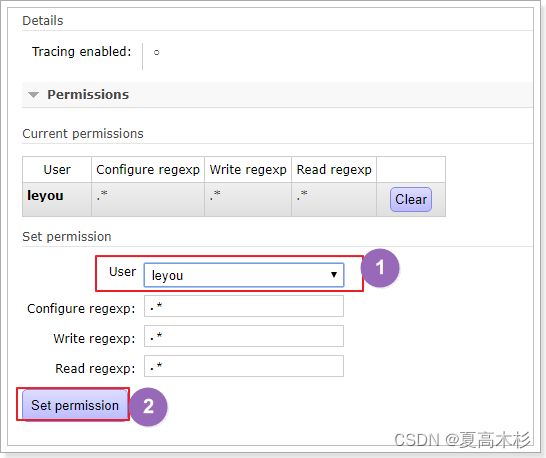

五种消息模型
RabbitMQ提供了6种消息模型,但是第6种其实是RPC,并不是MQ,因此不予学习。那么也就剩下5种。
但是其实3、4、5这三种都属于订阅模型,只不过进行路由的方式不同。

我们通过一个demo工程来了解下RabbitMQ的工作方式:
导入工程:


依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>cn.itcast.rabbitmqgroupId>
<artifactId>itcast-rabbitmqartifactId>
<version>0.0.1-SNAPSHOTversion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.0.2.RELEASEversion>
parent>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.3.2version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
dependencies>
project>
我们抽取一个建立RabbitMQ连接的工具类,方便其他程序获取连接:
public class ConnectionUtil {
/**
* 建立与RabbitMQ的连接
* @return
* @throws Exception
*/
public static Connection getConnection() throws Exception {
//定义连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置服务地址
factory.setHost("192.168.56.101");
//端口
factory.setPort(5672);
//设置账号信息,用户名、密码、vhost
factory.setVirtualHost("/leyou");
factory.setUsername("leyou");
factory.setPassword("leyou");
// 通过工程获取连接
Connection connection = factory.newConnection();
return connection;
}
}
基本消息模型
官方介绍:
RabbitMQ是一个消息代理:它接受和转发消息。 你可以把它想象成一个邮局:当你把邮件放在邮箱里时,你可以确定邮差先生最终会把邮件发送给你的收件人。 在这个比喻中,RabbitMQ是邮政信箱,邮局和邮递员。
RabbitMQ与邮局的主要区别是它不处理纸张,而是接受,存储和转发数据消息的二进制数据块。
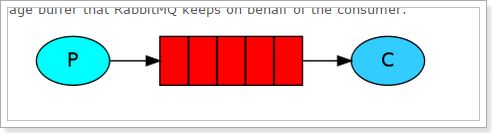
P(producer/ publisher):生产者,一个发送消息的用户应用程序。
C(consumer):消费者,消费和接收有类似的意思,消费者是一个主要用来等待接收消息的用户应用程序
队列(红色区域):rabbitmq内部类似于邮箱的一个概念。虽然消息流经rabbitmq和你的应用程序,但是它们只能存储在队列中。队列只受主机的内存和磁盘限制,实质上是一个大的消息缓冲区。许多生产者可以发送消息到一个队列,许多消费者可以尝试从一个队列接收数据。
总之:
生产者将消息发送到队列,消费者从队列中获取消息,队列是存储消息的缓冲区。
我们将用Java编写两个程序;发送单个消息的生产者,以及接收消息并将其打印出来的消费者。我们将详细介绍Java API中的一些细节,这是一个消息传递的“Hello World”。
我们将调用我们的消息发布者(发送者)Send和我们的消息消费者(接收者)Recv。发布者将连接到RabbitMQ,发送一条消息,然后退出。
生产者发送消息
public class Send {
private final static String QUEUE_NAME = "simple_queue";
public static void main(String[] argv) throws Exception {
// 获取到连接以及mq通道
Connection connection = ConnectionUtil.getConnection();
// 从连接中创建通道,这是完成大部分API的地方。
Channel channel = connection.createChannel();
// 声明(创建)队列,必须声明队列才能够发送消息,我们可以把消息发送到队列中。
// 声明一个队列是幂等的 - 只有当它不存在时才会被创建
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 消息内容
String message = "Hello World!";
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
//关闭通道和连接
channel.close();
connection.close();
}
}
管理工具中查看消息
进入队列页面,可以看到新建了一个队列:simple_queue

点击队列名称,进入详情页,可以查看消息:

在控制台查看消息并不会将消息消费,所以消息还在。
消费者获取消息
public class Recv {
private final static String QUEUE_NAME = "simple_queue";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 创建通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [x] received : " + msg + "!");
}
};
// 监听队列,第二个参数:是否自动进行消息确认。
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
这个时候,队列中的消息就没了:

我们发现,消费者已经获取了消息,但是程序没有停止,一直在监听队列中是否有新的消息。一旦有新的消息进入队列,就会立即打印.
消息确认机制(ACK)
通过刚才的案例可以看出,消息一旦被消费者接收,队列中的消息就会被删除。
那么问题来了:RabbitMQ怎么知道消息被接收了呢?
如果消费者领取消息后,还没执行操作就挂掉了呢?或者抛出了异常?消息消费失败,但是RabbitMQ无从得知,这样消息就丢失了!
因此,RabbitMQ有一个ACK机制。当消费者获取消息后,会向RabbitMQ发送回执ACK,告知消息已经被接收。不过这种回执ACK分两种情况:
- 自动ACK:消息一旦被接收,消费者自动发送ACK
- 手动ACK:消息接收后,不会发送ACK,需要手动调用
大家觉得哪种更好呢?
这需要看消息的重要性:
- 如果消息不太重要,丢失也没有影响,那么自动ACK会比较方便
- 如果消息非常重要,不容丢失。那么最好在消费完成后手动ACK,否则接收消息后就自动ACK,RabbitMQ就会把消息从队列中删除。如果此时消费者宕机,那么消息就丢失了。
我们之前的测试都是自动ACK的,如果要手动ACK,需要改动我们的代码:
public class Recv2 {
private final static String QUEUE_NAME = "simple_queue";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 创建通道
final Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [x] received : " + msg + "!");
// 手动进行ACK
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
// 监听队列,第二个参数false,手动进行ACK
channel.basicConsume(QUEUE_NAME, false, consumer);
}
}
注意到最后一行代码:
channel.basicConsume(QUEUE_NAME, false, consumer);
如果第二个参数为true,则会自动进行ACK;如果为false,则需要手动ACK。方法的声明:
自动ACK存在的问题
修改消费者,添加异常,如下:

生产者不做任何修改,直接运行,消息发送成功:

运行消费者,程序抛出异常。但是消息依然被消费:
这是因为虽然我们设置了手动ACK,但是代码中并没有进行消息确认!所以消息并未被真正消费掉。
当我们关掉这个消费者,消息的状态再次称为Ready

work消息模型
工作队列或者竞争消费者模式

在第一篇教程中,我们编写了一个程序,从一个命名队列中发送并接受消息。在这里,我们将创建一个工作队列,在多个工作者之间分配耗时任务。
工作队列,又称任务队列。主要思想就是避免执行资源密集型任务时,必须等待它执行完成。相反我们稍后完成任务,我们将任务封装为消息并将其发送到队列。 在后台运行的工作进程将获取任务并最终执行作业。当你运行许多消费者时,任务将在他们之间共享,但是一个消息只能被一个消费者获取。
这个概念在Web应用程序中特别有用,因为在短的HTTP请求窗口中无法处理复杂的任务。
接下来我们来模拟这个流程:
P:生产者:任务的发布者
C1:消费者,领取任务并且完成任务,假设完成速度较快
C2:消费者2:领取任务并完成任务,假设完成速度慢
面试题:避免消息堆积?
1)采用workqueue,多个消费者监听同一队列。
2)接收到消息以后,而是通过线程池,异步消费。
生产者
生产者与案例1中的几乎一样:
public class Send {
private final static String QUEUE_NAME = "test_work_queue";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 循环发布任务
for (int i = 0; i < 50; i++) {
// 消息内容
String message = "task .. " + i;
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
Thread.sleep(i * 2);
}
// 关闭通道和连接
channel.close();
connection.close();
}
}
不过这里我们是循环发送50条消息。
消费者
消费者1

消费者2

与消费者1基本类似,就是没有设置消费耗时时间。
这里是模拟有些消费者快,有些比较慢。
接下来,两个消费者一同启动,然后发送50条消息:

可以发现,两个消费者各自消费了25条消息,而且各不相同,这就实现了任务的分发。
能者多劳
刚才的实现有问题吗?
- 消费者1比消费者2的效率要低,一次任务的耗时较长
- 然而两人最终消费的消息数量是一样的
- 消费者2大量时间处于空闲状态,消费者1一直忙碌
现在的状态属于是把任务平均分配,正确的做法应该是消费越快的人,消费的越多。
怎么实现呢?
我们可以使用basicQos方法和prefetchCount = 1设置。 这告诉RabbitMQ一次不要向工作人员发送多于一条消息。 或者换句话说,不要向工作人员发送新消息,直到它处理并确认了前一个消息。 相反,它会将其分派给不是仍然忙碌的下一个工作人员。

订阅模型分类
在之前的模式中,我们创建了一个工作队列。 工作队列背后的假设是:每个任务只被传递给一个工作人员。 在这一部分,我们将做一些完全不同的事情 - 我们将会传递一个信息给多个消费者。 这种模式被称为“发布/订阅”。
订阅模型示意图:
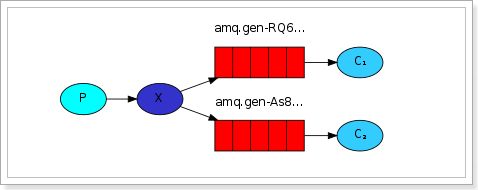
解读:
1、1个生产者,多个消费者
2、每一个消费者都有自己的一个队列
3、生产者没有将消息直接发送到队列,而是发送到了交换机
4、每个队列都要绑定到交换机
5、生产者发送的消息,经过交换机到达队列,实现一个消息被多个消费者获取的目的
X(Exchanges):交换机一方面:接收生产者发送的消息。另一方面:知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
Exchange类型有以下几种:
Fanout:广播,将消息交给所有绑定到交换机的队列
Direct:定向,把消息交给符合指定routing key 的队列
Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
我们这里先学习
Fanout:即广播模式
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
订阅模型-Fanout
Fanout,也称为广播。
流程图:

在广播模式下,消息发送流程是这样的:
- 1) 可以有多个消费者
- 2) 每个消费者有自己的queue(队列)
- 3) 每个队列都要绑定到Exchange(交换机)
- 4) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。
- 5) 交换机把消息发送给绑定过的所有队列
- 6) 队列的消费者都能拿到消息。实现一条消息被多个消费者消费
生产者
两个变化:
- 1) 声明Exchange,不再声明Queue
- 2) 发送消息到Exchange,不再发送到Queue
public class Send {
private final static String EXCHANGE_NAME = "fanout_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明exchange,指定类型为fanout
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
// 消息内容
String message = "Hello everyone";
// 发布消息到Exchange
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes());
System.out.println(" [生产者] Sent '" + message + "'");
channel.close();
connection.close();
}
}
消费者1
public class Recv {
private final static String QUEUE_NAME = "fanout_exchange_queue_1";
private final static String EXCHANGE_NAME = "fanout_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 绑定队列到交换机
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [消费者1] received : " + msg + "!");
}
};
// 监听队列,自动返回完成
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
要注意代码中:队列需要和交换机绑定
消费者2
public class Recv2 {
private final static String QUEUE_NAME = "fanout_exchange_queue_2";
private final static String EXCHANGE_NAME = "fanout_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 绑定队列到交换机
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [消费者2] received : " + msg + "!");
}
};
// 监听队列,手动返回完成
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
订阅模型-Direct
有选择性的接收消息
在订阅模式中,生产者发布消息,所有消费者都可以获取所有消息。
在路由模式中,我们将添加一个功能 - 我们将只能订阅一部分消息。 例如,我们只能将重要的错误消息引导到日志文件(以节省磁盘空间),同时仍然能够在控制台上打印所有日志消息。
但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
在Direct模型下,队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)
消息的发送方在向Exchange发送消息时,也必须指定消息的routing key。
P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。

X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
C1:消费者,其所在队列指定了需要routing key 为 error 的消息
C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
生产者
此处我们模拟商品的增删改,发送消息的RoutingKey分别是:insert、update、delete
public class Send {
private final static String EXCHANGE_NAME = "direct_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明exchange,指定类型为direct
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
// 消息内容
String message = "商品新增了, id = 1001";
// 发送消息,并且指定routing key 为:insert ,代表新增商品
channel.basicPublish(EXCHANGE_NAME, "insert", null, message.getBytes());
System.out.println(" [商品服务:] Sent '" + message + "'");
channel.close();
connection.close();
}
}
消费者1
我们此处假设消费者1只接收两种类型的消息:更新商品和删除商品。
public class Recv {
private final static String QUEUE_NAME = "direct_exchange_queue_1";
private final static String EXCHANGE_NAME = "direct_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 绑定队列到交换机,同时指定需要订阅的routing key。假设此处需要update和delete消息
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "update");
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "delete");
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [消费者1] received : " + msg + "!");
}
};
// 监听队列,自动ACK
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
消费者2
我们此处假设消费者2接收所有类型的消息:新增商品,更新商品和删除商品。
public class Recv2 {
private final static String QUEUE_NAME = "direct_exchange_queue_2";
private final static String EXCHANGE_NAME = "direct_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 绑定队列到交换机,同时指定需要订阅的routing key。订阅 insert、update、delete
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "insert");
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "update");
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "delete");
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [消费者2] received : " + msg + "!");
}
};
// 监听队列,自动ACK
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
订阅模型-Topic
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
通配符规则:
`#`:匹配一个或多个词
`*`:匹配不多不少恰好1个词
举例:
`audit.#`:能够匹配`audit.irs.corporate` 或者 `audit.irs`
`audit.*`:只能匹配`audit.irs`

在这个例子中,我们将发送所有描述动物的消息。消息将使用由三个字(两个点)组成的routing key发送。路由关键字中的第一个单词将描述速度,第二个颜色和第三个种类:“..”。
我们创建了三个绑定:Q1绑定了绑定键“* .orange.”,Q2绑定了“.*.rabbit”和“lazy.#”。
Q1匹配所有的橙色动物。
Q2匹配关于兔子以及懒惰动物的消息。
练习,生产者发送如下消息,会进入那个队列:
quick.orange.rabbit Q1 Q2
lazy.orange.elephant
quick.orange.fox
lazy.pink.rabbit
quick.brown.fox
quick.orange.male.rabbit
orange
生产者
使用topic类型的Exchange,发送消息的routing key有3种: item.isnert、item.update、item.delete:
public class Send {
private final static String EXCHANGE_NAME = "topic_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明exchange,指定类型为topic
channel.exchangeDeclare(EXCHANGE_NAME, "topic");
// 消息内容
String message = "新增商品 : id = 1001";
// 发送消息,并且指定routing key 为:insert ,代表新增商品
channel.basicPublish(EXCHANGE_NAME, "item.insert", null, message.getBytes());
System.out.println(" [商品服务:] Sent '" + message + "'");
channel.close();
connection.close();
}
}
消费者1
我们此处假设消费者1只接收两种类型的消息:更新商品和删除商品
public class Recv {
private final static String QUEUE_NAME = "topic_exchange_queue_1";
private final static String EXCHANGE_NAME = "topic_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 绑定队列到交换机,同时指定需要订阅的routing key。需要 update、delete
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "item.update");
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "item.delete");
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [消费者1] received : " + msg + "!");
}
};
// 监听队列,自动ACK
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
消费者2
我们此处假设消费者2接收所有类型的消息:新增商品,更新商品和删除商品。
/**
* 消费者2
*/
public class Recv2 {
private final static String QUEUE_NAME = "topic_exchange_queue_2";
private final static String EXCHANGE_NAME = "topic_exchange_test";
public static void main(String[] argv) throws Exception {
// 获取到连接
Connection connection = ConnectionUtil.getConnection();
// 获取通道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 绑定队列到交换机,同时指定需要订阅的routing key。订阅 insert、update、delete
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "item.*");
// 定义队列的消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
// 获取消息,并且处理,这个方法类似事件监听,如果有消息的时候,会被自动调用
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
// body 即消息体
String msg = new String(body);
System.out.println(" [消费者2] received : " + msg + "!");
}
};
// 监听队列,自动ACK
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
持久化
如何避免消息丢失?
1) 消费者的ACK机制。可以防止消费者丢失消息。
2) 但是,如果在消费者消费之前,MQ就宕机了,消息就没了。
是可以将消息进行持久化呢?
要将消息持久化,前提是:队列、Exchange都持久化



Spring AMQP
Sprin有很多不同的项目,其中就有对AMQP的支持:

Spring AMQP的页面:http://spring.io/projects/spring-amqp
Spring-amqp是对AMQP协议的抽象实现,而spring-rabbit 是对协议的具体实现,也是目前的唯一实现。底层使用的就是RabbitMQ。
依赖和配置
添加AMQP的启动器:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
在application.yml中添加RabbitMQ地址:
spring:
rabbitmq:
host: 192.168.56.101
username: leyou
password: leyou
virtual-host: /leyou
监听者
在SpringAmqp中,对消息的消费者进行了封装和抽象,一个普通的JavaBean中的普通方法,只要通过简单的注解,就可以成为一个消费者。
@Component
public class Listener {
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "spring.test.queue", durable = "true"),
exchange = @Exchange(
value = "spring.test.exchange",
ignoreDeclarationExceptions = "true",
type = ExchangeTypes.TOPIC
),
key = {"#.#"}))
public void listen(String msg){
System.out.println("接收到消息:" + msg);
}
}
@Componet:类上的注解,注册到Spring容器@RabbitListener:方法上的注解,声明这个方法是一个消费者方法,需要指定下面的属性:bindings:指定绑定关系,可以有多个。值是@QueueBinding的数组。@QueueBinding包含下面属性:value:这个消费者关联的队列。值是@Queue,代表一个队列exchange:队列所绑定的交换机,值是@Exchange类型key:队列和交换机绑定的RoutingKey
类似listen这样的方法在一个类中可以写多个,就代表多个消费者。
AmqpTemplate
Spring最擅长的事情就是封装,把他人的框架进行封装和整合。
Spring为AMQP提供了统一的消息处理模板:AmqpTemplate,非常方便的发送消息,其发送方法:

红框圈起来的是比较常用的3个方法,分别是:
- 指定交换机、RoutingKey和消息体
- 指定消息
- 指定RoutingKey和消息,会向默认的交换机发送消息
测试代码
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class MqDemo {
@Autowired
private AmqpTemplate amqpTemplate;
@Test
public void testSend() throws InterruptedException {
String msg = "hello, Spring boot amqp";
this.amqpTemplate.convertAndSend("spring.test.exchange","a.b", msg);
// 等待10秒后再结束
Thread.sleep(10000);
}
}
运行后查看日志:

项目改造
接下来,我们就改造项目,实现搜索服务、商品静态页的数据同步。
思路分析
发送方:商品微服务
-
什么时候发?
当商品服务对商品进行写操作:增、删、改的时候,需要发送一条消息,通知其它服务。
-
发送什么内容?
对商品的增删改时其它服务可能需要新的商品数据,但是如果消息内容中包含全部商品信息,数据量太大,而且并不是每个服务都需要全部的信息。因此我们只发送商品id,其它服务可以根据id查询自己需要的信息。
接收方:搜索微服务、静态页微服务
接收消息后如何处理?
- 搜索微服务:
- 增/改:添加新的数据到索引库
- 删:删除索引库数据
- 静态页微服务:
- 增/改:创建新的静态页
- 删:删除原来的静态页
商品服务发送消息
我们先在商品微服务leyou-item-service中实现发送消息。
引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
配置文件
我们在application.yml中添加一些有关RabbitMQ的配置:
spring:
rabbitmq:
host: 192.168.56.101
username: leyou
password: leyou
virtual-host: /leyou
template:
exchange: leyou.item.exchange
publisher-confirms: true
- template:有关
AmqpTemplate的配置- exchange:缺省的交换机名称,此处配置后,发送消息如果不指定交换机就会使用这个
- publisher-confirms:生产者确认机制,确保消息会正确发送,如果发送失败会有错误回执,从而触发重试
改造GoodsService
在GoodsService中封装一个发送消息到mq的方法:(需要注入AmqpTemplate模板)
private void sendMessage(Long id, String type){
// 发送消息
try {
this.amqpTemplate.convertAndSend("item." + type, id);
} catch (Exception e) {
logger.error("{}商品消息发送异常,商品id:{}", type, id, e);
}
}
这里没有指定交换机,因此默认发送到了配置中的:leyou.item.exchange
注意:这里要把所有异常都try起来,不能让消息的发送影响到正常的业务逻辑
然后在新增的时候调用:

修改的时候调用

搜索服务接收消息
搜索服务接收到消息后要做的事情:
- 增:添加新的数据到索引库
- 删:删除索引库数据
- 改:修改索引库数据
因为索引库的新增和修改方法是合二为一的,因此我们可以将这两类消息一同处理,删除另外处理。
引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
添加配置
spring:
rabbitmq:
host: 192.168.56.101
username: leyou
password: leyou
virtual-host: /leyou
这里只是接收消息而不发送,所以不用配置template相关内容。
编写监听器

代码:
@Component
public class GoodsListener {
@Autowired
private SearchService searchService;
/**
* 处理insert和update的消息
*
* @param id
* @throws Exception
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "leyou.create.index.queue", durable = "true"),
exchange = @Exchange(
value = "leyou.item.exchange",
ignoreDeclarationExceptions = "true",
type = ExchangeTypes.TOPIC),
key = {"item.insert", "item.update"}))
public void listenCreate(Long id) throws Exception {
if (id == null) {
return;
}
// 创建或更新索引
this.searchService.createIndex(id);
}
/**
* 处理delete的消息
*
* @param id
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "leyou.delete.index.queue", durable = "true"),
exchange = @Exchange(
value = "leyou.item.exchange",
ignoreDeclarationExceptions = "true",
type = ExchangeTypes.TOPIC),
key = "item.delete"))
public void listenDelete(Long id) {
if (id == null) {
return;
}
// 删除索引
this.searchService.deleteIndex(id);
}
}
编写创建和删除索引方法
这里因为要创建和删除索引,我们需要在SearchService中拓展两个方法,创建和删除索引:
public void createIndex(Long id) throws IOException {
Spu spu = this.goodsClient.querySpuById(id);
// 构建商品
Goods goods = this.buildGoods(spu);
// 保存数据到索引库
this.goodsRepository.save(goods);
}
public void deleteIndex(Long id) {
this.goodsRepository.deleteById(id);
}
创建索引的方法可以从之前导入数据的测试类中拷贝和改造。
静态页服务接收消息
商品静态页服务接收到消息后的处理:
- 增:创建新的静态页
- 删:删除原来的静态页
- 改:创建新的静态页并覆盖原来的
不过,我们编写的创建静态页的方法也具备覆盖以前页面的功能,因此:增和改的消息可以放在一个方法中处理,删除消息放在另一个方法处理。
引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
添加配置
spring:
rabbitmq:
host: 192.168.56.101
username: leyou
password: leyou
virtual-host: /leyou
这里只是接收消息而不发送,所以不用配置template相关内容。
编写监听器
代码:
@Component
public class GoodsListener {
@Autowired
private GoodsHtmlService goodsHtmlService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "leyou.create.web.queue", durable = "true"),
exchange = @Exchange(
value = "leyou.item.exchange",
ignoreDeclarationExceptions = "true",
type = ExchangeTypes.TOPIC),
key = {"item.insert", "item.update"}))
public void listenCreate(Long id) throws Exception {
if (id == null) {
return;
}
// 创建页面
goodsHtmlService.createHtml(id);
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "leyou.delete.web.queue", durable = "true"),
exchange = @Exchange(
value = "leyou.item.exchange",
ignoreDeclarationExceptions = "true",
type = ExchangeTypes.TOPIC),
key = "item.delete"))
public void listenDelete(Long id) {
if (id == null) {
return;
}
// 删除页面
goodsHtmlService.deleteHtml(id);
}
}
添加删除页面方法
public void deleteHtml(Long id) {
File file = new File("C:\\project\\nginx-1.14.0\\html\\item\\", id + ".html");
file.deleteOnExit();
}
测试
查看RabbitMQ控制台
重新启动项目,并且登录RabbitMQ管理界面:http://192.168.56.101:15672
可以看到,交换机已经创建出来了:

队列也已经创建完毕:

并且队列都已经绑定到交换机:
