RocketMQ学习笔记
使用场景:
解耦、流量削峰、数据分发.
部署架构:

producer 生产者
与nameserver去连接建立连接,生产消息时是与broker连接,但只会向master发送消息
consumer 消费者
与nameserver去连接,消费消息时与broker去消费信息.根据偏移量来决定去master还是slave1拉取消息
broker 暂存和传输组件
通过broker Name来形成集群,并通过brokerid区分,broker id为0的为master,1和master为读写使用,其余都为备份broker,提供故障转移高可用
nameServer 管理broker的架构,无状态的组件,去中心化的吗?
与redis sentinel一样.在rocker mq中相当于注册中心.
topic 主题
MessageQueue 主题的分区 与partition一样
启动流程:
1启动 NameServer
2启动 broker
3创建 Topic
4向topic发送消息,可分配存在哪个broker上
5消费topic的消息.
RocketMQ特性:
订阅和发布;
有序的消息,多分区的话也没法保证有序性....,但针对某一分区,消费是有序的.
消息过滤,可以针对消费者的需求设置过滤器,在broker端进行处理,匹配的话再发送,否则就发了.省去网络压力
消息可靠性:
宕机是可以保证消息可靠性的.
但硬件损坏是完蛋了.
同步双写机制,最大保证可靠性,但会影响性能.
至少一次:
ack机制保证可重发
回溯消费:
可消费之前已消费的数据,通过时间点来进行回退.
事务消息:
批次消息发送到全局事务里,提供幂等性.全局事务哦
X/Opne XA分布式事务支持很好.
定时消息:
可做延迟队列,那也就可以做死信队列.
broker设置messageDealyLevel 默认18级别, 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h,你设置多少级,就多少时间,超了就按18来.
针对不同的延迟时间,将不同的时间暂存到SCHEDULE_TOPIC_XXXX的topic中,根据延迟级别存到不同的queue中,queueId就是延迟级别-1,保证了不同的延迟时间的有序发送.等到到期了就发送到broker的topic里.
消息重试:
消息本身问题出错那种就抛弃吧或者设置定时,要不一直重试失败
下游服务宕机,就设置的时间也稍微长点;
消息重投:
同步消息失败重投
异步消息有重试
oneway就不管了.速度快,不用ack
retryTimesWhenSendFailed:同步失败重试次数 默认为2 ,会尝试发送到其他broker. 客出现RemotingExeption
、MQClientException和部分MQBrokerException异常时会重投
异步发送失败重投:retryTimesWhenSendAsyncFailed:异步发送失败次数,不会选择其他broker,一直在一个broker上重试.
retryAnotherBrokerWhenNotStoreOK:消息刷盘超时了或者slave不可用,是否尝试向其他broker发送,默认为false,消息如果非常重要,就开启;
流量控制:
阻断生产者生产消息和停止给消费者推送消息.
生产者方面:
commitLog被锁时间超过设置时间(osPageCacheBusyTimeOutMills,默认1000ms),就流控了
transientStorePoolEnable = true,而且broker为异步刷盘的主机,还有transientStorePool中资源不足,拒绝当前send请求,发生流控.
broker每隔10ms检查send请求队列头部请求的等待时间,如果超过了waitTimeMillsinSendQueue,默认200ms,拒绝当前send请求,发生流控. 就看第一条等了多长时间了
broker通过拒绝send 请求方式实现流量控制,就手动了
消费者:
本地缓存消息超过pullThresholdForQueue设置的数量,默认1000
本地缓存消息大小超过pullThresholdSizeForQueue设置的大小,默认是100MB.
本地缓存信息跨度超过consumeConcurrentlyMaxSpan时,默认2000. 就是和最新发出的消息差距已经达到2000了就不给你再推了,你先处理会,我再发.
流控的结果是降低拉取频率.可以手动设置一些手段.
死信队列:
一定时间内没被消费的消息的队列称之为死信队列.与rabbit一样
消费模式:
推和拉其实都是主动拉取的方式,一个是手动,一个自动拉取.
push:
咔咔推给消费者
通过监听器来一直拉取消息.取到消息后缓刑consumeMessage()方法来消费.消费者的感知是被推送来的.
pull:
消费者自己去拉取.
不能一直拉啊,设置点时间长轮询拉取吧
相关术语:
消息模型:
pushConsumer:推送的消费者对象
pullConsumer:拉取的消费者对象
ProducerGroup:生产组,提供生产高可用
ConsumerGroup:消费组,只能消费相同的主题,不可消费其他主题.
广播消费:所有消费者都可收到
集群消费:消费组的每个实例均匀的消费主题里的消息
顺序消息:
按照生产顺序来消费.会有稍微乱
严格顺序消息:
牺牲了分布式的可用性,来严格保证消息顺序性,但是双写主从模式就可以保证一些稳定性
Message Queue
队列topic也有offset的概念,long设置的,循环用之不尽.
tag:
主题下的再次分组.消费者根据标签来消费,类似于rabbit的rk
rocket mq环境搭建
需要环境jdk 11
下载rocket mq 并解压,是zip的 unzip解压
JDK 8以上的环境,8就没问题,11需要修改一下脚本... 阿里这适配性犹如国产车啊,好用就是有小毛病...
配置环境变量:
配置jdk的
配置rocket的
需要删除runserver.sh的一些东西
UseCMSCompactAtFullCollection
UseParNewGC
UseConcMarkSweepGC
修改内存:(记得看原配置是什么样的)
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=64mm -XX:MaxMetaspaceSize=160mm"
-Xloggc修改为-Xlog:gc
*修改后启动:mqnamesrv
runbroker.sh也要修改:
删除:
PrintGCDateStamps
PrintGCApplicationStoppedTime
PrintAdaptiveSizePolicy
UseGCLogFileRotation
NumberOfGCLogFiles=5
GCLogFileSize=30m
有可能会出现的情况:
$JAVA ${JAVA_OPT} --add-exports=java.base/jdk.internal.ref=ALL-UNNAMED $@ 这块在JDK9默认不对外使用了,所以需要导出插件
*修改后启动mqbroker -n localhost:9876 去连接nameSever
使用工具需要修改tools.sh
删除 JAVA_OPT="${JAVA_OPT} -Djava.ext.dirs=${BASE_DIR}/lib:${JAVA_HOME}/jre/lib/ext"
但要把这条中的环境变量写到上面的CLASSPATH中:
${BASE_DIR}/lib/*:${JAVA_HOME}/jre/lib/ext
停止时先停止broker再停止nameServer
RocketMQ环境测试:
发送消息:
设置环境变量来指定NAMESRV_ADDR的地址
export NAMESRV_ADDR=localhost:9876
./tools.sh org.apache.rocketmq.example.quickstart.Producer 启动了就示例给你发一堆消息.
消费消息:
设置一次环境变量就行
./tools.sh org.apache.rocketmq.example.quickstart.Consumer
API的使用:
对象涉及:
DefaultMQProducer
DefaultMQPullConsumer
DefaultMQPushConsumer
导入依赖:
rocketmq-client
生产者代码:
DefaultMQProducer实例化,指定一下生产组.
producer.setNamesrvAddr(nameserver的地址)
producer.start()启动producer对象
实例化Message,标记消息和主体,如果没有默认创建,主题创建默认4个分区
producer.send(message)
SendResult接收send的返回,里面有发送的反馈以及消息的元数据
异步发送消息的代码:
send重载方法中有实现SendCallback回调函数的方法.使用该方法
消费者代码:
拉取:
DefaultMQPullConsumer实例化,指定消费组名称
consumer.setNamesrvAddr(namesever地址)
consumer.start()启动消费者
consumer.fetchSubsrcibeMessageQueues("topic_name")获取主题的消费队列集合
循环pull(messageQueue,"*tag过滤",开始的offset,拉取消息的条数)拉取队列集合内的消息
result.getMsgFoundList()每个队列拉取到的消息集合.
循环获取到集合的信息,消息体用的是字节数组,需要String反序列化一下;
推送:
DefaultMQPushConsumer实例化,指定消费组名称.
consumer.setNamesrvAddr(namesever地址)
consumer.subcribe("topic")订阅主题
consumer.setMessageListener(里面有多种机制,按需选择,通常是使用orderly)创建监听来接收消息的处理方法,在需要实现的方法中参数集合是消息的集合,需要返回消费结果.
consumer.start()启动消费者
Spring boot整合rocket MQ:
导入依赖:rocketmq-spring-boot-starter
生产者:
配置文件:
nameserver=nameServer地址
producer.group=生产组
其余属性可以按需配置,一般都有默认值;
rocketMQTemplate.convertSend()
消费者:
配置文件:
nameserver=nameServer地址
与消费者的配置没有,需要去实际代码去配置
创建监听器实现RocketMQListenet接口;
添加@RocketMQMessageListener注解
RocketMQ高级特性:
消息发送:
生产者代码的额外属性:
设置InstanceName,一个JVM需要启动多个producer的话,设置不同的instanceName来区分,默认是default
设置发送失败重试次数:
setRetryTimesWhenSendFailed()同步
setRetryTimeWhenSendAsyncFailed()异步
异步发送的回调函数中发送失败的方法是重试完失败的回调,不是重试就回调.
异常的情况说明:
1. FLUSH_DISK_TIMEOUT:表示没有在规定时间内完成刷盘(需要Broker的刷盘策略被设置成SYNC_FLUSH才会报这个错误)。
2. FLUSH_SLAVE_TIMEOUT:表示在主备方式下,并且Broker被设置成SYNC_MASTER方式,没有在设定时间内完成主从同步。
3. SLAVE_NOT_AVAILABLE:这个状态产生的场景和FLUSH_SLAVE_TIMEOUT类似,表示在主备方式下,并且Broker被设置成SYNC_MASTER,但是没有找到被配置成Slave的Broker。
提升写入性能:
snedOneway将消息放到socket缓冲区就返回,不会等待broker响应,可能会丢消息.
多个producer来发送消息,提高并发发送能力.
调优linux参数来提高写盘速度
消息消费:
代码的额外属性:
consuler.setMessageModel(MessageModel.CLUSTER(集群)|BROADCASTING(广播)) 消费模式
设置消费的最小和最大的线程数:
setConsumerThreadMin()
setConsumerThreadMax()
设置消息过滤tag:
subscribe(主题,"tag,可用*")
消费性能提升:
提高消费并行度,创建一消费组.组内的消费再设置多线程.
批次消费消息:
setConsumerMessageBatchMaxSize()
检测消息情况,进行跳跃消费.
消息存储:
存储到DB.但受到DB性能限制;
存储到文件,硬盘的写入速度,超过网卡的传输速度.存储的核心是CommitLog文件,是分段存储的,采用顺序存储.速度更快,默认1个G,文件名长度20位,特点都与kafka相同
ConsumeQueue(逻辑消费队列)是存储持久化的消息的前置文件.负责提供快速查询,每个条目里面含有:
指定主题的commitlog偏移量8字节、4字节的消息长度,8字节的hash,单个queue文件可存储30万条目.文件大小约为5.72Mb,可根据该文件进行定位到commitLog中指定索引的位置.
index是索引文件,提供快速的消息查询,可以时间查可以key查;单个文件约为400Mb,最大可存储2000万个索引.初始化先征用空间,然后再写,保证顺序读写磁盘.
消息过滤:
tag标签形式:
过滤器写在consumer,但broker负责去执行.在消费者上设置固定的tag,消息中如果不符合条件,那么就不处理了.
broker先通过过滤器进行过滤,然后找到过滤的消息进行发送,客消费者再进行比对,比对成功,消费消息,不成功,直接放弃消息.不会被重投吧?
tag标签型代码设置:
在拉取subcribe方法中添加tag的参数
SQL92过滤方式:
通过SQL语句来进行过滤,在broker中利用布隆过滤器进行过滤.筛选中的才进行发送,消费者只能通过push模式来获取消息.
代码设置:
在broker.config中设置enablePropertyFilter=true来开启SQL92过滤模式.
在启动broker时需要带上配置文件启动了
启动方法:mqbroker -n namesev地址 -c broker.conf的目录
在生产者中设置生产者属性:setUserProperty(key,value)
在拉取方法subcribe方法中使用messageSelector参数来设置sql,这里的就可以对生产者设置的属性进行过滤.
SQL支持一些常用的语法
零拷贝原理:
读cache:
APP读取内核缓存,内核缓存去读取磁盘文件.如果已经在缓存中,那么就直接从缓存返回,更高效.
写cache:
异步写入,APP写到cache,cache中数据被标记脏数据,内核周期性对脏数据的列表遍历去刷盘.内核决定什么时候去遍历.
cache回收:
对不使用超过一定时间的缓存,进行释放,但脏数据的话需要先刷盘再释放.
cache缓存,高速读取,buffer是缓冲,对读取速度不对等时,进行缓冲,让快的一方可以等待时做其他事.
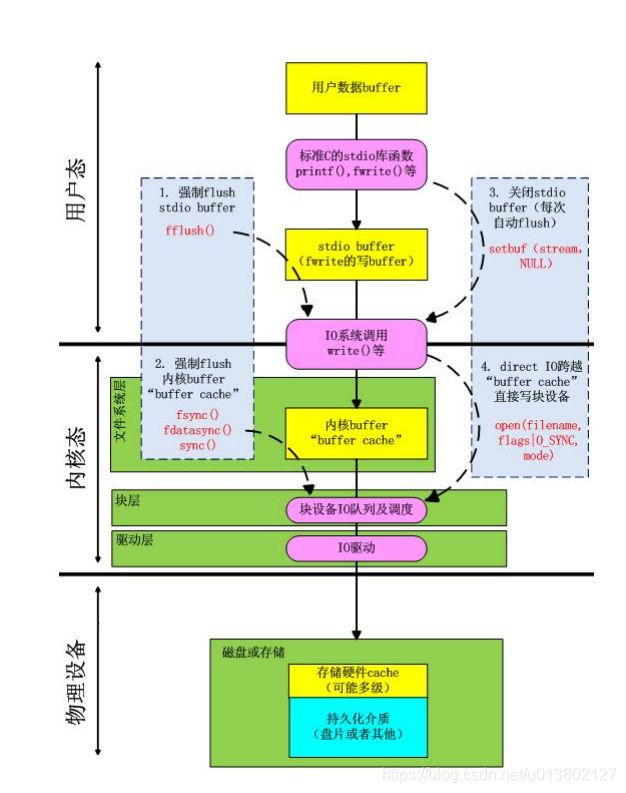
缓冲IO和直接IO:
缓冲IO是磁盘读到缓存,然后再复制到应用程序的地址空间.
写缓存时APP先写入到缓存,缓存在复制到硬盘中,但什么时候写是OS决定的,除非设置sync同步.
隔离系统和OS空间.安全
减少读盘次数.提高性能
需要在缓存中过一手的话,就会给CPU和内存增加压力.
直接IO是APP直接访问磁盘,不通过缓存.提升速度.
但是如果APP缓存没有,就会去读盘,这时APP是阻塞的.影响性能.而缓存IO不会阻塞.
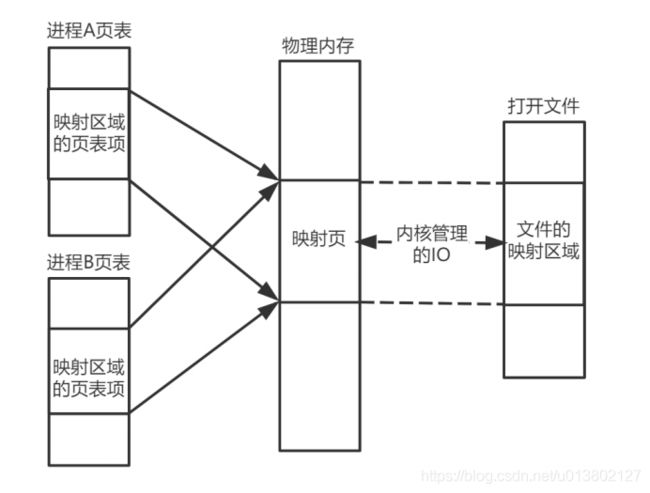
内存映射文件:
用mmap创建的虚拟内存空间,创建与物理内存的映射空间.这个虚拟内存直接映射到磁盘的文件;APP不需要自己单独开辟一片内存空间,直接读取映射内存,通过内核管理IO直接找到文件的映射区域
文件映射:
把文件映射成物理内存
匿名映射:
初始化全为0的内存空间
私有映射:
多进程里数据共享,修改不反馈给磁盘文件,是写时复制的映射方式.
共享映射:
多进程数据共享,修改将会影响到磁盘文件
2*2=4种交织的映射模式,私有文件映射、私有匿名映射、共享文件映射、共享匿名映射
mmap只是在虚拟内存分配了空间,在实际使用那块才会分配物理内存.没用到的那块空间叫缺页.
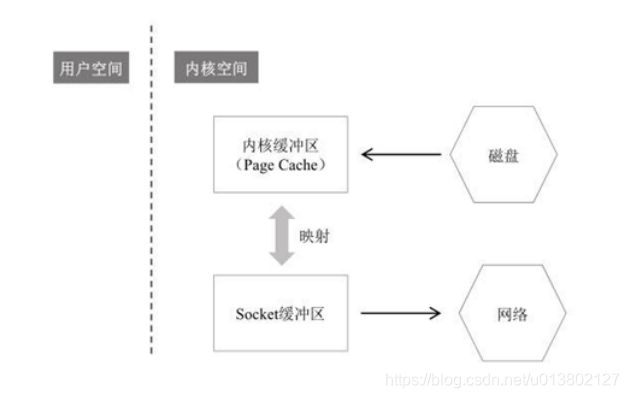
普通写入方式是磁盘拷贝到内核缓冲区,内核再复制到APP缓存,APP再发给socket缓冲,然后发送到网络

mmap是省略了内核缓冲区与app缓存的复制,直接APP缓存映射为内核缓冲区,然后直接从内核缓存区拷贝到socket发送到网络

sendfile零拷贝就是socket缓冲区和内核缓冲区进行映射.这样用户操作内核缓冲区的数据直接被socket知晓并发送到网络
同步复制和异步复制:
在集群内的主从,生产者写入主节点,从节点可以设置用什么方式去同步主节点数据.
同步复制:
主收到写入后,同步到从节点,slave同步完成后,反馈给生产者发送成功.会增加延迟
异步复制:
master收到写入后反馈发送成功,然后slave再去异步同步master的消息.消息可能会丢失哦.
配置:
broker.conf:
brokerRole:
SYNC_MASTER:同步master节点
ASYNC_MASTER:异步master节点
SLAVE:我是个slave,不管
brokerName:主从一致
brokerId:区分集群节点
listenePort:监听端口
namesvr:nameServer地址.
复制模式再配合刷盘模式,来寻求一个最佳方案
高可用机制(集群):
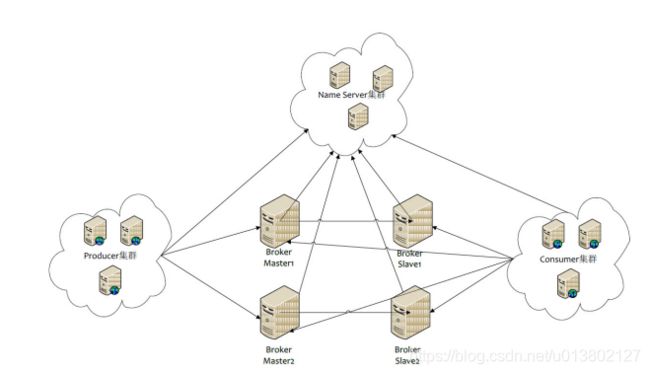
brokerId区分集群节点
brokerName:相同表一个集群
brokerRole角色设置一下.slave是能被读,不能被写入.等着跟master同步
读master还是slave是自动切换的,不用生产者手动配置
发送消息高可用,将一个topic设置路由来分配到多个broker集群中,发送消息发送给这个topic中不同的broker集群的master里的messagequeue中,如果其中broker集群宕机,那么会去尝试其他broker集群的messagequeue,5分钟后再尝试向宕机的broker集群去发送消息.这么做提高了消息的可用性,但无法保证消息严格的顺序性.
也就是说这种机制没有故障转移.master宕机slave不能升主.
Dledger机制:
zookeeper的通信机制与选举机制
主从半数以上都接收到消息才会成功;
master挂机会重新选举master,从slave中选择版本最新的几个进行选举;
综合这两点,即可保证了消息的严格一致性,也能保证高可用了.
原来这个机制一开始竟然没有....不能自动故障转移
但是也有问题:
选举时不能提供服务,半数以上机制注定会让服务器数量增多提高成本.而且半数以上确认机制会让性能降低一些些;
刷盘机制:
同步刷盘:
消息收后,必须从缓存更新到磁盘后才反馈消息发送成功.有效保证消息不会丢失
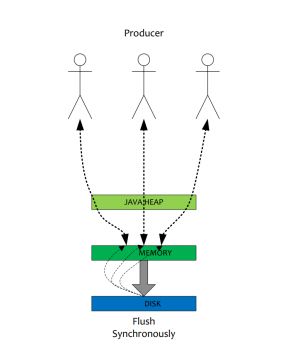
异步刷盘:
发送消息,缓存收到后即反馈发送成功,再由内核决定什么时候从内核缓存去更新到磁盘.脏页那个.
为了防止刷盘速度慢,导致内核缓存的堆积而压爆内存,rocket的机制会将缓存未修改的数据进行丢弃来存储新进入的脏数据,如果还是满载状态,那么将会进行刷盘操作.就是LRU淘汰策略,冷数据淘汰;

负载均衡:
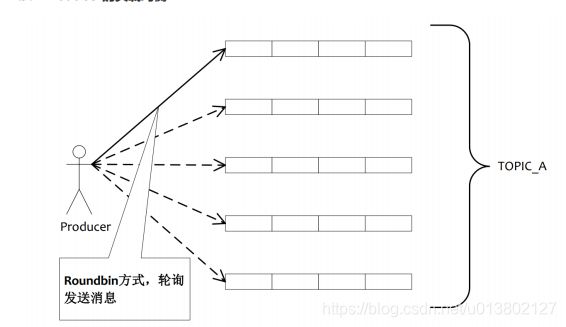
所有角色都有负载均衡;生产者负载发送消息,消费者负载消费消息,broker负载到不同queue上.
producer负载均衡:
默认是自动负载均衡的,但我们可以手动设置发送到哪个broker的哪个queue.
mqadmin的操作:
通过./mqadmin 可以查看具体的命令
创建队列mqadmin updateTopic -n namesver地址 -b broker或集群地址:10911 -t topicName -w 6
-w为设置可写queue为多少个,topic在一个broker上建立默认4个queue,两个broker为8个,那么设置为6个是可以的,另外两个只能读
代码手动设置负载:
send方法中使用MessageQueue对象,对象参数为(topicname,brokername,mqNumId)
消费者在拉取时同样使用MessageQueue对象.
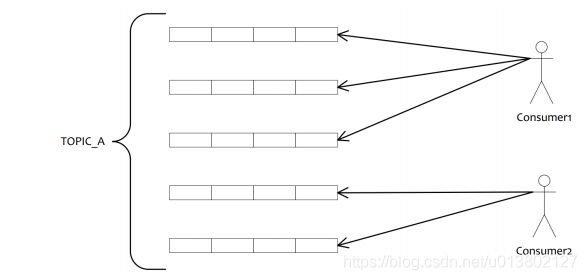
consumer负载均衡:
集群消费模式下,consumer就需要将队列分配到不同的consumer,但一个queue只能由一个consumer消费.在分配queue规则中与kafka分区的range分配规则一致.queueNUM/consumerNUM得到每个consumer的数量.然后queueNUM%consumerNUM查看是否有多余部分,多余部分就再顺序的分配给consumer.
分配流程:
向集群中broker发送心跳包,broker知晓消费组中consumer的数量和信息;
consumer核心组件拉取所有broker的queue数量,获取所有consumer信息,进行排序,根据负载的实现对象,拿取到当前consumer需要消费的队列.
通过consumer.setAllocateMessageQueueStrategy()来指定自动的负载算法
推送模式下的consumer手动负载:
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumer_push_grp_01");
consumer.setNamesrvAddr("node1:9876"); // 设置负载均衡算法
consumer.setAllocateMessageQueueStrategy(new AllocateMessageQueueAveragely());
consumer.setMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
// todo 处理接收到的消息 return null;
}
});
consumer.start();
消息重试:
顺序消息的重试:
再前一个消息没有被成功消费之前不会接收到下一条消息,重试每隔1s试一次.这种机制就会阻塞队列.
代码实现:
批处理设置为1,最大一次只接受1条消息,但注意的是,每个messagequeue都会发送1条.实际就是4条了
consumer.setMessageListener方法中使用实现MessageListenerOrderly接口的参数,会一直重试啊...
无序消息重试:
重试级别对应时间:贴图
重试机制为16个级别重试机制,对应16次重试,针对不同时间的等待重试,与MQ的重投机制等级类似.大于
代码实现
consumer.setMaxReconsumeTimes(重试级别)设置充实级别
通过message对象的.getReconsumeTimes()方法可以获取当前消息重试到第几次了
可视化工具:
rocketmq-console下载地址:
https://github.com/apache/rocketmq-externals/archive/rocketmq-console-1.0.0.zip
# 编译打包
mvn clean package -DskipTests
# 运行工具
java -jar target/rocketmq-console-ng-1.0.0.jar
页面设置NameSrv地址即可。如果不生效,就直接修改项目的application.properties中的namesrv地址选项的值。
死信队列:
消息重试次数达到设置的重试级别后,就被放入到死信队列,死信队列自动创建;
默认命名规则是
%RETRY%消费组名称(重试Topic)
%DLQ%消费组名称(死信队列)
rocketMQweb监控程序:
rocketMq-console-ng,一个java程序,源码编译一下就可以使用了.
不会再被消费者正常消费
死信队列的消息默认3天删除.
死信队列对应的是消费组,不对应单个的consumer
消费组如果没有产生出死信消息,那么该消费组的死信队列不会创建.
消费组的死信队列包含该消费组订阅的所有主题中的死信,注意哦,多个topic的消息就混在一块了.

延迟消息:
消息发送到broker后,不会立即被消费,等待特定时间投递给真正的topic。
broker有配置项messageDelayLevel,默认值为 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m8m 9m 10m 20m 30m 1h 2h
18个level。可以配置自定义messageDelayLevel
设置为broker级,不针对哪个topic.
因为暂存在临时队列倒了一次手,所以tps和发送量会变多.
延迟队列那个临时队列是看不到了,叫为SCHEDULE_TOPIC_XXXX的,总共18个级别对应18队列
顺序消息:
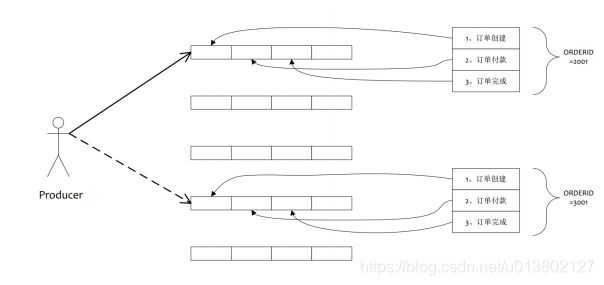
需要保证顺序的消息,进行严格的顺序消费,分为全局有序和部分有序,全局是所有消息都得有序,部分是每几个消息按照顺序发送和消费.
大量的消息要是有序那就会影响性能了啊.注意注意.而且全局有序要同时发到一个队列.consumer和producer的并发也只能为1了
部分有序的话 把需要严格顺序的消息发送同意queue里即可,但也要保证消费者不可并发处理,(每个分区不只能被一个消费者消费吗,这里指的是消费者自身的并发处理)通过MessageListenerOrderly类来处理消费消息时的并发处理.使用该模式时,下列参数依旧可用:
setConsumerThreadMin 最小并发
setConsumerThreadMax 最大并发
setPullBatchSize 设置每次拉取数量.设成1默认32
setConsumerMessageBatchMaxSize 最大消费批次数量
创建队列 额外的参数:
mqadmin updateTopic -b node1:10911 -n localhost:9876 -r 8只读的队列数 -t tp_demo_1 -w 8可写如的queue数
删除队列
mqadmin deleteTopic -c DefaultCluster deleteTopic -n localhost:9876 -t tp_demo_1
查看主题
mqadmin topicStatus -n localhost:9876 -t tp_demo_1
代码中实现部分有序:
在生产者生产消息时,指定发送到哪一个队列中,producer.fetchPublishMessageQueues获取主题所有队列后,再通过队列集合获取指定某一队列,将部分有序的消息都发送到该队列中,达到部分有序的效果,设置消费着并发和批次的属性都设置为1保证顺序消费.
代码实现全局有序:
控制台创建主题时 -w -r 都设置为1只有一个队列.这样就保证生产消息只在一个队列中,消费者也同样设置并发和批次属性为1
控制台在创建主题时设置了-w 和 -r属性,这两个属性影响该topic的messageQueue的数量,目前来看,messageQueue的最大数量取决于这两个属性中最大的那个,如 -w 5 -r 2,那么该topic为5个messageQueue但只有2个是可读的.
事务消息:
本地事务:
本地处理的事务.
rocketMQ使用了2pc机制来保证整体的事务.
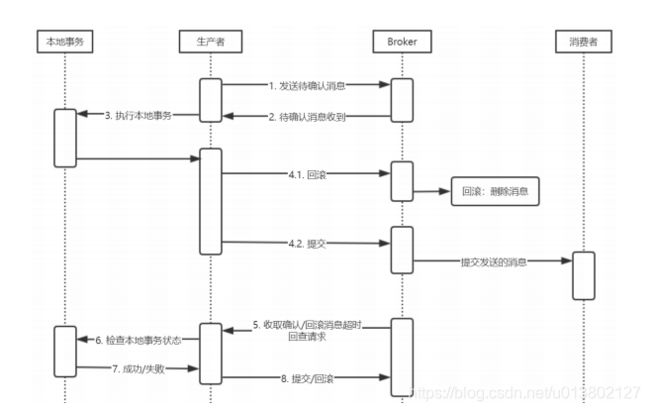
事务处理流程
生产者开始事务前向队列发送一条事务消息,然后开始处理事务,事务消息发送到一个事务的RMQ_SYS_TRANS_HALF_TOPIC临时队列,如果事务回滚,那么"删除"消息.如果提交,那么消息转发到正式的队列中,消费者消费消息.这是正常事务的状况.
意外情况的处理:
1:生产没有发送消息到临时队列RMQ_SYS_TRANS_HALF_TOPIC,这个无所谓了,相当于事务没转到broker处理.
2:生产者开启事务发送消息到临时事务队列,但是没有提交或回滚,那么broker会进行回查请求,生产者检查事务状态成功或失败,提交给broker;
broker会一直回查,最多15次;超过了就不再处理,丢掉该条消息
底层机制:
在生产发送消息时,消息发送的主题和队列,被修改为事务主题和队列,真实的被放入到消息属性中,当producer二次提交后也会生成了一条OP消息,无论是commit还是rollback都会发送,记录该事务消息的最终状态,OP消息存储在mq全局的内部topic中,如果二次为commit消息内容为事务发送的half消息的偏移量.给临时事务队列查找消息进行转发使用.
代码实现事务消息:
创建一个TransacationListener监听器,实现两个方法,一个是发送half消息后执行本地事务,通过返回LocalTransactionState状态来决定提交还是回滚,一个是发送事务消息,还有一个是回查方法;
生产者使用的是TransactionMQProducer对象
producer.sendMessageInTransaction();发送事务消息.
消息查询:
先尝后买,通过查询messageId再去消费消息,messageId由16位组成,前8为broker地址,后8为commit log offset;
在RocketMQ中具体做法是:Client端从MessageId中解析出Broker的地址(IP地址和端口)
和CommitLo的偏移地址后封装成一个RPC请求后,通过Remoting通信层发送(业务请求码VIEW_MESSAGE_BY_ID)。
Broker使用QueryMessageProcessor,
使用请求中的 commitLog offset和 size 去 commitLog 中找到真正的记录并解析成一个完整的消息返回
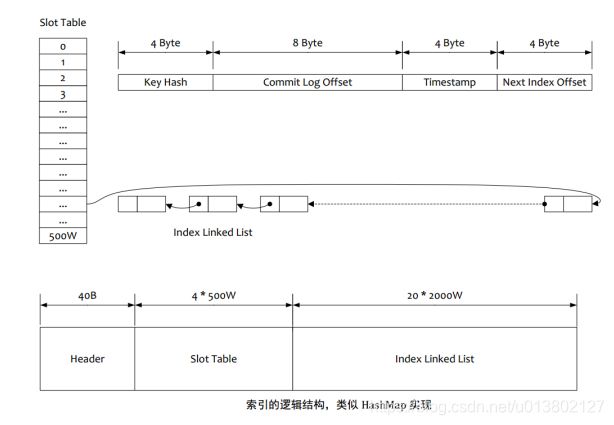
按照Message Key查询消息,主要是基于RocketMQ的IndexFile索引文件来实现的。RocketMQ的索引文件逻辑结构,类似JDK中HashMap的实现
1.根据查询的 key 的 hashcode%slotNum 得到具体的槽的位置(slotNum 是一个索引文件里面包含的最大槽的数目, 例如图中所示 slotNum=5000000)。
2.根据 slotValue(slot 位置对应的值)查找到索引项列表的最后一项(倒序排列,slotValue 总是指向最新的一个索引项)。
3.遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的 32 条记录)
4.Hash 冲突:
第一种,key 的 hash 值不同但模数相同,此时查询的时候会再比较一次 key 的 hash 值(每个索引项保存了 key 的 hash 值),过滤掉 hash 值不相等的项。
第二种,hash 值相等但 key 不等, 出于性能的考虑冲突的检测放到客户端处理(key 的原始值是存储在消息文件中的,避免对数据文件的解析), 客户端比较一次消息体的 key 是否相同。
5.存储;为了节省空间索引项中存储的时间是时间差值(存储时间-开始时间,开始时间存储在索引文件头中), 整个索引文件是定长的,结构也是固定的。
代码实现:
package com.lagou.rocket.demo.query;
import org.apache.rocketmq.client.consumer.DefaultMQPullConsumer;
import org.apache.rocketmq.client.exception.MQBrokerException;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.remoting.exception.RemotingException;
public class QueryingMessageDemo {
public static void main(String[] args) throws
InterruptedException,
RemotingException,
MQClientException,
MQBrokerException {
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("consumer_test1");
consumer.setNamesrvAddr("localhost:9876");
consumer.start();
MessageExt message = consumer.viewMessage("demo_topic1", "123456");
System.out.println(message);
System.out.println(message.getMsgId());
consumer.shutdown();
}
}
消息优先级:
topic和消息级别都不支持.如果想用,如下方法:
1:消息分队列,不同队列处理不同消息
2:单个topic设置多messageQueue,消费者均匀消费,多生产者,
保证哪个队列的消息暴增也不会产生其他队列的阻塞,但要注意消息处理的并发和批次数量控制一下;
3:强制优先级,通过代码业务设置来控制
底层通信:
采用netty框架,高性能.
remoting模块是rocket的通信模块,每次请求带上请求码来匹配对应处理办法.处理器继承nettyRequestProcessor,需要注册才可使用.
协议设计与编解码:
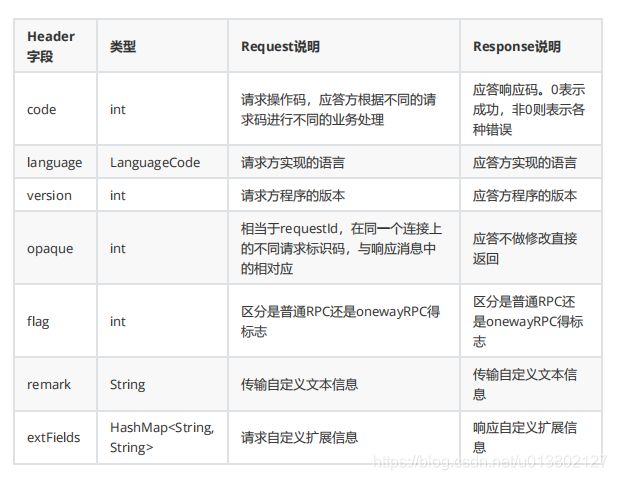
传输内容分4个部分:
1:消息长度:总长度,int类型
2:序列化类型&消息头长度:int类型,第1字节表序列化类型,后3表消息头程度
3:消息头数据:序列化后的消息头数据
4:消息主题:消息的二进制字节数据
消息的通信流程:
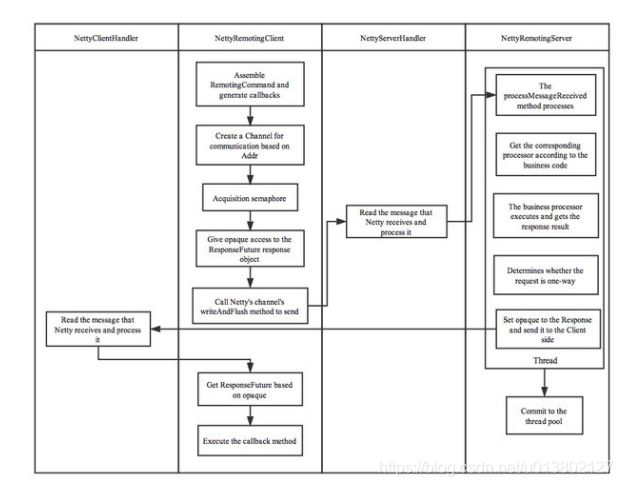
通信方式有同步、异步、单向,其中单向最省事,不关心回.
Reactor多线程模型:
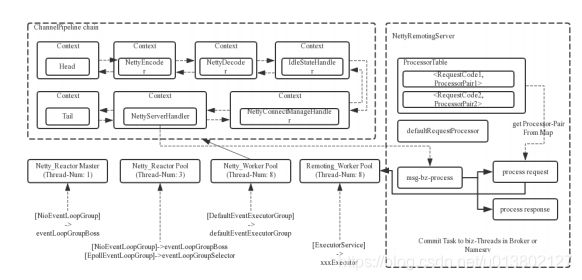
主线程监听TCP请求,建立连接,创建通道,注册到selector中;
MQ会根据OS类型选择NIO还是epoll,也可参数设置,开始监听数据传输;
拿到网络数据丢给woker线程池,子线程负责去检查一系列的网络状态.交给defaultEventExecutorGroup做;
处理具体业务时是丢给业务线程池中处理,根据业务请求的code去processorTable里找对应的processor,封装为task任务交给对应业务processor处理线程池来执行;
Rocket的限流:
限流前的优化选项:设置最大线程和批次拉取消息数量
削峰填谷:每个MQ的必备能力.
使用sentinel流控组件来对MQ进行流控.
将暂时消费不了的消息存放到临时队列.
代码:
FlowRule对象
setResource(groupName:topicNamne)
setCount(消费数量)
setGrade(流控规则)
setLimitApp()
setControlBehavior(设置固定间隔)
setMaxQueueingTimeMs(等待队列超时时间)
FlowRuleManager.loadRules()
消费消息:
pullBlockIfNotFound(对列,null,偏移量位置,最大拉取数量)没有收到消息则阻塞.
pullResult.getNextBeginOffset()获取下一个消息的偏移量
consumer.updateConsumerOffset(mq,offset)更新队列的偏移量
处理消息时使用
Entry加载流控规则
ContextUtil.enter(流控设置的KEY)
SphU.entry(KEY,enryType.OUT) 执行流控
Rokect高级实战:
生产者:
Tag:producer生产消息设置tag过滤消息
Key:通过设置消息的key来保证消息的完整性,broker会为每个消息创建hash索引,app通过topic、key可以查询该条消息,以及属性,但要避免key的hash冲突
代码:
在生产消息时,给消息setKey(key) 设置一个key
生产者发送消息返回状态:
SEND_OK:
发送成功
FLUSH_DISK_TIMEOUT:
刷盘时间超过了一段时间(默认5S),返回异常刷盘超时
FLUSH_SLAVE_TIMEOUT:
同步到slave时 超过了默认5s的时间,返回异常同步slave超时
SLAVE_NOT_AVAILABLE:
当同步模式为sync master时,slave没有或者没被发现,返回slave没找到异常
重投机制默认同步模式重投2次,异步没有,如果发送失败则轮转到下一个broker.发放总耗时不抄过sendMsgTimeout
特殊的发送模式:oneway
只负责将消息写入到socket缓冲区,不关心是否发送或发送成功.
消费者:
消费幂等:
无法避免消息重复,如果想避免这个问题,就需要自行在用用处理,例如添加唯一的ID,来保证消息重投的问题,但业务型重发需要更多判断
提供消费并行度:
增加并发和消费者集群数量,但也要配合messageQueue的数量.也可丢弃一些不重要的消息
批量方式消费:
批次属性设置,设置每批次消费消息的数量.
跳过非重要消息:
消费消息时,看当前偏移量与最大的偏移量差值,根据差值可以做一些处理,比如相差10000条了就可以直接抛弃返回consume_success状态
针对单条消息优化:
对业务本身进行优化设计,减少IO操作
打印消费日志:
根据日志发现问题
其他建议:
消费者订阅时注意设计
有序消息 一定会锁定队列下降性能
并发消费 适当开启
消费状态尽量返回 reconsume_later
消费位移:
consumer.setConsumeFromWhere();设置消费位置
ConsumerFromWhere.ENUM:
CONSUME_FROM_FIRST_OFFSET第一个
CONSUME_FROM_LAST_OFFSET最新的
CONSUME_FROM_TIMESTAMP
其中使用timestamp时要同时setConsumeTimestamp()设置时间戳
Broker:
broker rule 角色:
sync_master 同步主
async_master 异步主
slave 从
broker Id:集群节点标记
flushDiskType:
sync_flush同步刷盘是消息发送完等待刷盘完后才返回发送成功
async_flush异步刷盘broker接收到消息就返回发送成功,刷盘时机由broker决定处理
broker的设置:
listenPort 客户端直连的监听端口,一般咱们都是去连nameServer
nameServer: 注册中心地址
brokerIp1:客户端连接交互
brokerip2:主从连接交互
brokername:
brokerClusterName
brokerId
storePathCommitLog log存储路径
storePathConsumerQueue 消费队列的路径
mappedFileSizeCommitLog log映射文件的大小
deleteWhen 每日何时删除超过保留期限的log文件
fileReservedTime log文件的保留期限,小时为单位
brokerRole broker角色
flushDiskType: 刷盘模式
NameServer:
rocketMq的注册中心的作用:负责broker集群的调度,监控和选举.对外的代理,提供高可用方案.
设计特点:
1相互独立,没有通信;
2不主动推消息
3:所有broker向namseServer发送心跳定时注册30s每次,每10snameserver去检测这写心跳包,超过2分就认为broker死掉
4:consumer随机与一个namesev建立长连接,如果该namesev挂掉,那么再去namesev列表找下一个,consumer是去nameserv中获取当前broker集群的topic、broker地址等信息,查到后缓存到本地,每30s会向namesev拉取broker集群的地址信息,处理挂掉的broker,如果某个broker集群master挂掉,那就去slave上消费.consumer将broker集群的master和salve都建立连接的,应对不同的消费场景.
5:producer随机与一个nameserver建立长连接,每30S(可配置)从nameserver获取topic的最新队列情况,某个master挂了,producer最多30m才可感知,这期间消息发送都会失败,producer与提供topic服务建立连接,定时发送心跳,生产者不能与slave连接进行写入;
在rocket中的作用就是检测每个broker的健康状态,存储topic和队列,存储broker的过滤器列表,向consumer和producer提供最新的路由信息
为什么不用zookeeper作为注册中心:
zk是强一致性,而服务发现类的组件,都是趋于AP的,保证高可用,及时发现,扩容等,达到最终一致性即可.
zk的强一致性,在出现网络分区时,为了保证C,它会做出一些阻断,或者为了一致性做出数据的同步性,而这就违背了服务发现的宗旨,做为注册中心是不应该影响到服务之间的调用关系的.
zk的性能,使的它在大量服务注册,与客户端高频交互时显得吃力,如健康检查,状态获取,数据获取以及大量长连接.zk并不能很好的应付.
服务发现中的注册中心其实并不需要对历史的情况做记录,而且服务方也不关心那些,他们只关心当前的服务列表,但也会需要存储一些配置,服务的版本、权重、策略等一些元数据,而注册中心对这些数据应该相应的有些检索的功能;
zk在健康监测上仅仅是针对于他与客户端的那条长连接和session健康状态,但并不代表服务的真实健康状态.
服务是弱依赖注册中心,仅仅在发布、上下线、扩容缩容时才依赖注册中心.服务自身为了降低依赖,都会在本地缓存注册中心的数据.注册中心本身应该对自己的挂机或不可用状态做相应的处理.这点zk就并不具备;
zk的复杂处理机制,client/session状态机,复杂的异常处理.
但阿里并不是放弃zookeeper,它在做分布式锁,分布式一致性等功能上还是很优秀的,针对一些其他组件的主从情况,主从切换等发挥很大作用.因为这些都不要大量的TPS操作.zk最大的优势就是多服务集群协同,而不是服务发现.阿里的项目,在申请使用zookeeper时,都会经过严格的指标评估.还有大数据zookeeper也支持的较好.
客户端配置:
公共类:ClientConfig,消费者生产者的类都是继承他
寻址方式:setNameServer(多个逗号隔开)
JVM启动添加参数来设置namesrv:
-D rocketmq.namesrv.addr=
设置环境变量:
NAMESRV_ADDR也可以让mq启动时找到namesrv地址.
HTTP静态服务器寻址:
rocketMQ的客户端实例启动时,会去向一个URL访问来测试该URL是否为可行的rocket broker,初始为10s,以后都是每2s一次,这是内部一个测试功能,但我们可以加以利用,如URL是http://jmenv.tbsite.net:8080/rocketmq/nsaddr,我们可以修改host文件将该域名指向我们实际的broker地址,也可修改改URL
客户端公共配置:
namesrvAddr:nameserver的地址
clientIP:默认为本机IP,应对特殊情况强制设定
instanceName:客户端的实例总称,多个producer和consumer都使用这个实例;默认为"default"
clientCallbackExecutorThreads:通信层异步回调线程数,默认4个
pollNameServerInteval:向nameServer拉取信息的间隔时间,默认30s
heartbeatBrokerInterval:向broker发送心跳包的间隔时间,默认30s
persistConsumerOffsetInterval:持久化Consumer消费进度间隔时间,单位毫秒,默认5s
Producer配置:
producerGroup:生产组名称
createTopicKey:自动创建主题,指定一个key,是topic的默认路由.
defaultTopicQueueNums:自动创建topic时默认的messageQueue数量,默认4个
sendMsgTimeout发送消息的超时时间,默认10s
compressMsgBodyOverHowmuch:消息容量超过多少进行压缩,单位字节,默认4KB,consumer消费时会自动解压
retryAnotherBrokerWhenNotStoreOK:发送状态返回不为send_ok时,是否重试发送,默认false
retryTimesWhenSendFailed:发送失败时最大重试次数,这里不包括正常发送那一次,默认为2,只针对同步模式.
masMessageSize:消息的最大空间,默认4MB,与consumer的消息大小配合使用.
transactionCheckListener:事务消息回查的监听器,这个必须设置,没有默认.就是broker回查发送者事务处理状态的方法;
checkThreadPoolMinSize:回查事务状态时,线程池中最小线程数,默认1
checkThreadPoolMaxSize:回查事务线程池最大线程数,默认1
checkRequestHoldMax:回查时,producer本地缓冲请求队列的大小,默认2000
RPCHook:producer创建,包含客户端调用的两个接口
Consumer配置:
consumerGroup:消费组,默认DEFAULT_CONSUMER
messageModel:消息模式,集群消费和广播,默认cluster集群
consumeFromWhere:从队列的什么位置开始消费,默认是最新的offset,也可指定位置或从第一个.
consumeTimeStamp:当消费位置设置为时间时,设置该值表示从哪个时间节点开始消费,默认是30m前
allocateMessageQueueStraregy:消费者与队列的分配策略默认是AllocateMessageQueueAveragely
subscription:订阅关系,必须要订阅一个topic
messageListener:推送模式下的监听器,用于接收消息
offsetStore:队列消费信息的位置存储,代表当前消费进度
consumeThreadMin:消费者线程池最小线程数,最小并发数的意思,默认10
consumerThreadMax:消费者线程池最大线程数,最大并发数的意思,默认20
consumerConcurrentlyMaxSpan:单个队列中并发消费允许的最大跨度,就是一个线程消费的与最后一个线程消费的消息offset差距不能大于某个值.默认2000
pullThresholdForQueue:拉取消息缓存到本地的最大数量,默认1000
pullInterval:拉取消息的间隔,默认为0,一直拉取不停歇,当需要流控时,将设置该值
consumerMessageBatchMaxSize:批量消费.一次拉取多少条消息,默认1条,单个线程的拉取数量
pullBatchSize:批次拉取消息,最大拉取多少条,默认32,所有线程下拉取的总数.
PullConsumer的专属配置:
brokerSuspendMaxTimeMillis:消费者等待消息的最长时间,默认20s
consumerTimeoutMillisWhenSuspend:消费者等待的时间超过了一定时间,认为超时,消费者重新发起连接,默认30s
consumerPullTimeoutMillis:手动拉取时的超时时间,默认10s
messageModel:消息模式,这个默认是广播
registerTopics:注册Topic的集合
rokcet系统配置优化:
jvm:
-Xms8g最大栈容量 -Xmx8g最小容量
-Xmn4g新生代的容量,设置大点,就会影响gc的处理频率.
-XX:+MaxFirectMemorySize=15g堆外内存大小,当超过这个值会触发JVM的 fullGC全局回收处理.
-XX:+AlwaysPreTouch启动则将容量全部提前划分好;
-XX:-UseBiasedLocking 偏向锁,检查是否有锁的步骤,在高并发下,大家就直接去申请锁就行,不需要检查一下是否有锁.
推荐使用G1垃圾回收器:
-XX:+UseG1GC
设置单个region区的大小:
-XX:G1HeapRegionSize:16m (最大可设置32m)
设置预留内存:G1ReservePercent 使G1内存达到峰值时使用该块内存.
更早的开始标记周期,设置InitiatingHeapOccupancyPercent,更早的标记周期
增加并发收集的线程数:ConcGCThreads
-XX:MaxGCPauseMillis设置过小的话会加快GC垃圾回收的频率.如果标记的时间超过了这个频率时间,那么G1为了满足这个回收频率将会减小年轻代区域大小,这样会降低并发性能
使用GC log文件的配置:
+UseGCLogFileRotation
NumberOfGCLogFiles = 5
GCLogFileSize=30m
也可将GCLog写入到内存文件系统:
Xloggc:/dev/shm/mq_gc_%p.log123
Linux内核参数:
os.sh文件中设置:
sudo sysctl -w来设置
vm.extra_free_kbytes
VM后台回收的阈值和直接回收的阈值之间保留歪歪的可用内存,MQ使用此参数来避免内存分配的长延迟
vm.min_free_kbytes
如果低越1024,将会巧妙的破坏系统,高负载下容易出现死锁
vm.max_map_count
限制一个进程最大内存映射区域数,MQ的零拷贝机制将会用到大量的映射区域,所以要将这个值相对设大一些;
vm.swappiness
内核与内存交换数据的积极程度.较高的值将会影响性能,设置低点有好处
File descriptor limits
设置文件和网络连接描述符,建议设置成655350
echo '* hard nofile 655350 ' >> /etc/security/limits.conf 这个配置最多只可打开655350个文件
echo 'deadline' 使用IO截止时间调度器,属兔为请求提供有保证的延迟.
动态扩缩容:
动态增减nameserver:
新增与删除只需要修改cli而已,不会进行再平衡.
新增nameserver无需多个参数,只需直接添加即可,但broker启动时,填写多个nameserver地址时需要注意是分号; 隔开,而shell会识别为一个命令结束,所以需要拿引号引上
动态增减broker:
新增broker也是直接启动,只是在主题新增分区时,需要一些格外的动作,或者topic再平衡
新增topic的分区在broker上:
mqadmin updateTopic -b ip:port -t topicName -n nameServer:port -w -r
减少broker时需要搞点命令了:
得先停producer再能停broker,要不消息就丢失了对不,但是同步发送的情况就没事,会重发到其他broker上,但是异步或者oneway的就不行了,就会丢失消息了
主从情况下 producer关闭 master关闭,consumer会从slave进行读取消息,不会影响可用性.
也可kill 函数shutdown会被执行. 但别-9 啊 不太优雅
故障对消息的影响:
broker正常关闭、启动
producer会重试其他broker,消费者也会向其他broker进行消费.
broker异常,启动
系统异常重启
服务器断电 重新供电
如果采用同步刷新的情况,不会导致消息丢失,没同步完成崩溃了,至少主还在.同步完成了,崩溃,slave也有.
磁盘损坏
主要硬件损坏
数据会导致丢失,但是同步情况下依旧不会导致丢失,接收到消息立即落盘 就没问题
针对这些情况,我们做出的配置建议:
多个master/slave架构, master之间与slave同步:SYNC_MASTER;
producer同步写入,保证每条消息得到确认成功发送
刷盘策略设置SYNC_FLUSH,
这些都会影响性能,但可以避免单节点的极端故障.
rocketMQ集群搭建:
启动顺序还是不要搞错了,先搞nameserver,再搞broker.复杂的是broker集群之间的关系.
单master模式:
单个broker,没有slave.风险很大,数据会丢失;
多master模式:
多个主节点,topic设置多个分区queue,提高可用性,但也会造成消息无法访问或丢失;
多主多从模式:
(异步)master与slave之间采用异步同步,效率很高,但是有可能因为没同步完成master宕机而导致消息丢失;
(同步)master与slave之间采用同步复制,最大保证消息可靠性不会丢失,但会影响MQ的整体效率,单个消息的延迟会变长,而且也没有故障转移这个功能;
搭建流程:
根据JDK的版本修改一下相应的.sh文件,前面有说过.
单主模式搭建:
启动nameserver:
nohup ./mqnamesrv &
启动broker:
nohup ./mqbroker -n nameserver:port &
管理命令:
mqadmin
关闭:
mqshutdown namesev/broker
多主模式:
优点:配置简单、不会对整体主题有太大影响、性能优秀、设置RAID10磁盘机制不会丢失数据(异步会掉一小部分)
缺点:节点挂机将导致一部分消息无法被消费.
搭建流程:
1:启动nameserver
2:启动broker时指定配置文件 -c 配置文件,而且不同的broker配置文件也不能使用一样的.注意一下;
多主多从模式(异步复制):
优点:少量消息丢失但不会影响实时性、可持续消费消息、性能与多主差不多
缺点:会丢一点点消息哦.因为不能故障转移;
搭建流程:
启动nameserver
配置broker的配置文件,在2m-2s-async文件夹:
主从下brokerClusterName要一致
brokerId需要设置唯一,master要设置为0号,slave要大于0
每个主的brokerName也不能一样;
*主和从的配置文件名不一样,要注意一下,主是-m,从是-s;
启动broker时同样 将配置文件用-c 加上;
多主多从模式(同步复制):
优点:没有单点故障、master挂掉不会导致消息延迟或丢失.消费服务高可用;
缺点:性能要低于异步复制10%、发送消息时延迟会高,因为要等待m和s的同步、不能故障转移,手动修改会出些问题,会导致老的m出现偏移量问题;
搭建流程:
启动nameserver
配置broker的配置文件,在2m-2s-sync文件夹中
主从下brokerClusterName要一致
brokerId需要设置唯一,master要设置为0号,slave要大于0
*主和从的配置文件名不一样,要注意一下,主是-m,从是-s;
启动broker时同样 将配置文件用-c 加上;
mqadmin管理工具:
mqadmin命令 加参数,必须指定nameserver地址,就是-n 必备;
通过-h可以查看有哪些命令和用法;
如果设置了-b 和 -c,那么会以-b优先,如果没写-b 写了-c 那么该集群下的所有节点broker都将生效.
有很多命令,但不是全部可用,只在MQAdminStartup中初始化的命令才是可用的.这个类可以修改,进行添加命令;
因为版本的问题,有些命令没有及时更新,会导致出错,具体看看源码;
Topic相关的命令:
updateTopic: 更新/新建主题
-b:broker地址
-c:集群名称
-h:打印帮助说明
-n:nameserver地址
-p:topic新权限
-r:可读的队列数(分区数)
-w:可写的队列数(分区数)
*推荐-r -w相同,如果不同,具体对列数以大的那个为准.如果填写-c,那么集群下所有broker都会按照这个配置创建一定数量的队列
-t:topic名称
deleteTopic:删除主题
-b:broker地址
-c:集群名称
-h:打印帮助说明
-n:nameserver地址
-t:topic名称
topicList:主题列表
-n:nameserver地址
-c:集群名称 可不填,具体的集群
topicRoute: 主题的路由
topicStatus:主题状态
-n:nameserver地址
-t:topic名称
topicClusterList:主题所在集群的名称
-n:nameserver地址
-t:topic名称
updateTopicPerm:更新主题权限
updateOrderOf:更新主题顺序消费
allocateMQ:消费者负载算法分配
-t:topic名称
-n:nameserver地址
-h:打印帮助说明
-i:ip列表,计算这些ip并负载到topic的哪些队列
statsAll:打印监控信息
-h:打印帮助说明
-n:nameserver地址
-a是否只打印活跃的topic
-t:topic名称 可不写,就打印所有
集群相关操作:
clusterList: 集群信息查看
-m 打印更多信息,消息的统计
-h 帮助
-n nameserver
-i 时间间隔
clusterRT: 计算集群之间的延迟
-a amount 测试消息的总数
-s 消息大小 B单位
-c 集群名称
-p 是否打印格式化日志 日志格式更清晰
-h 帮助信息
-m 机房
-i 间隔
-n nameserver
broker相关:
updateBroker: 更新broker的配置文件,就那个2m-2s-sync/async那个文件夹下的配置文件
-b broker地址
-c cluster名称
-k 属性名 key
-v 属性值 value
-h 帮助
-n nameserver
brokerStatus: 查看broker的状态
-b broker地址
-h 帮助
-n nameserver
brokerConsumeStats: broker在各个消费者的消费情况,按queue维度返回偏移量等信息
-b broker地址
-t 请求超时时间
-l 偏移量间隔的阈值,超过这个阈值的消费者信息才被打印
-o 是否为顺序topic 一般为false
-h 帮助
-n nameserver
getBrokerConfig: 获取broker配置
-b broker地址
-n nameserver
wipeWirtePerm:在nameserver上清除broker的写权限
-b broker地址
-n nameserver
-h 帮助
cleanExpiredCQ: 清理过期的消费者queue,就是重置了topic的队列数,可能变少了,多余的queue就需要这个命令清除
-b broker地址
-n nameserver
-h 帮助
-c cluster名称
cleanUnusedTopic:清除不使用的主题,从内存中释放主题的queue,就是deleteTopic后执行一下,要不会占用你的磁盘空间
-b broker地址
-n nameserver
-h 帮助
-c cluster名称
sendMsgStatus:向broker发送消息,返回发送的状态和RT的信息
-b broker名称,注意不是地址了.其实就是向那个broker名称的主题发送消息.
-n nameserver
-h 帮助
-c 发送次数
-s 消息大小,单位为B
消息相关的命令:
queryMsgById:根据offsetMsgId查询msg,如果是开源控制台就得用这个命令,更多参数查看QueryMsgByIdSubCommand
-i msgId
-n nameserver
-h 帮助
queryMsgByKey:根据消息的Key查询消息
-k msgKey
-t 主题名称
-n nameserver
-h 帮助
queryMsgByOffset:根据偏移量查询消息
-b broker的名称,注意不是地址.
-i 队列ID
-o 偏移量
-t 主题名称
-n nameserver
-h 帮助
queryMsgByUniqueKey:根据msgId查询,与offsetMsgId不同,区别去看常见运维问题,-g和-d配合使用,查到消息让特定的消费者去消费该消息并返回结果
-n nameserver
-h 帮助
-i 唯一的msgid
-g 消费组名称
-d 客户端ID
-t 主题名称
checkMsgSendRT:向topic发送消息返回RT消息.类似clusterRT
-n nameserver
-h 帮助
-t 主题名称
-a 发送次数
-s 消息大小
sendMessage:发送消息
-h 帮助
-n nameserver
-t 主题名称
-p 消息体
-k keys
-c tags
-b broker的名称,注意不是地址.
-i 队列ID
consumeMessage:消费消息
-h 帮助
-o 开始偏移量
-g 消费组
-s 开始时间戳
-d 结束时间戳
-c 消费条数
printMsg:从broker消费消息并打印,可选时间段
-h 帮助
-c 字符集
-s subExpress过滤表达式
-b 开始时间戳
-e 结束时间戳
-d 是否打印消息体
printMsgByQueue:指定队列打印消息,类似printMsg
-i 消息ID
-p 是否打印消息
-f 是否统计tag数量并打印
resetOffsetByTime:按时间戳重置偏移量,broker和consumer都会重置
-s重置此时间戳对应的偏移量
-f是否强制重置,false只回溯偏移量,true就不管时间戳与偏移量的关系
-c 是否重置c++客户端偏移量
消费者、消费组相关:
consumerProgress:查看订阅消费组状态,查看具体的client IP的消息积累量
-g 消费组
-s 是否打印client IP
consumerStatus: 查看消费者状态,包括分组内是否都是相同的订阅,分析process queue是否堆积,返回消费者jstack结果,详细内容查看ConsumerStatusSubCommand.
-g 消费组
-i clientId
-s 是否执行jstack
updateSubGroup:更新或创建订阅关系
-n地址、-h、-b、-c集群名称、-g消费组
-s 分组是否允许消费
-m 是否从最小偏移量开始消费
-d 是否广播模式
-q 重试队列数量
-r 最大重试次数
-i slaveReadEnable开启有效,而且未进行建议备机消费时有效,可设置备机ID,主动从该slave消费.设置brokerID
-w 与上面区别为当进行建议从机消费时,设置从哪个salve消费,设置brokerID
-a 消费者数量发生变化是否通知其他消费者负载均衡
deleteSubGroup:从Broker中删除订阅关系
-n -h -b -c 集群名称 -g
cloneGroupOffset:克隆源群组的偏移量,在源消费群组中使用
-n -h -s源消费者群组 -d 目的消费者组 -t -o暂未使用
连接相关:
consumerConnection:查看消费者的网络连接
-g 消费组 -n -h
producerConnection:查看生产者的网络连接
-g 生产组 -n -h -t
nameserver:
getNamesrvConfig:获取nameserver的配置信息
-n -h
updateNamesrvConfig 更新nameserver的配置
-n -h -k 属性key -v 属性值
运维常见问题:
1.mqadmin报错:connect to failed 找不到nameserver 要不命令指定, 要不设置环境变量
2.MQ生产端和消费端版本不一致导致的不能正常消费:
异常消息:Not found the consumer group consume stats, because return offset table is empty, maybe the consumer not consume any message
以生产者的版本为准,消费者配合使用相同的版本
3.新增一个topic的消费组,无法消费历史消息:
默认是最后偏移量消费,所以历史消息消费不到了
ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET
可设置成从first偏移量开始消费
ConsumeFromWhere.CONSUME.FROM.FIRST_OFFSET
也可设置成从指定时间戳开始消费
ConsumeFromWhere.CONSUME.FROM.TIMESTAMP
4.如何开启从Slave读消息功能:
消费者需要消费很多的历史消息,这样会导致master压力较大,所以需要开启slaveReadEnable来开启读取slave节点消息的功能,当消费历史数据偏移量与最新的差值容量超过master机器的内存百分比设置(accessMessageInMemoryMaxRatio=40%)时,(超出的部分?)就会推荐consumer从slave的节点中读取历史消息,给master留出IO写入消息
5.性能调优问题:
异步刷盘是自选所,同步刷盘是用重入锁
调整Broker配置:
useReentrantLockWhenPutMessage,默认是false
异步刷盘开启TransientStorePoolEnable,关闭transferMsgByHeap,提高拉消息的效率;
同步刷盘增大sendMessageThreadPoolNums,提高效率,但也要结合测试调出最佳数字
6.msgId和offsetMsgId:
msgId是客户端生成的