【自然语言处理】用Python从文本中删除个人信息-第二部分
自我介绍
- 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师酒馆】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。微信小号【ca_cea】

Python中隐私过滤器的实现,该过滤器通过命名实体识别(NER)删除个人身份信息(PII)
这是我上一篇关于从文本中删除个人信息的文章的后续内容。
GDPR是欧盟制定的《通用数据保护条例》。其目的是保护所有欧洲居民的数据。保护数据也是开发人员的内在价值。通过控制对列和行的访问,保护行/列数据结构中的数据相对容易。但是免费文本呢?
在我上一篇文章中,我描述了一个基于正则表达式用法和禁止词列表的解决方案。在本文中,我们添加了一个基于命名实体识别(NER)的实现。完整的实现可以在github PrivacyFilter项目中找到。
什么是命名实体识别?
根据维基百科,NER是:
命名实体识别(NER)(也称为(命名)实体识别、实体分块和实体提取)是信息提取的一个子任务,旨在定位非结构化文本中提到的命名实体,并将其分类为预定义的类别,如人名、组织、位置、医疗代码、时间表达式、数量、货币值、百分比等。
因此,这一切都是关于寻找和识别文本中的实体。一个实体可以是一个单词或一系列连续的单词。实体被分类到预定义的类别中。例如,在下面的句子中,发现了三个实体:实体人“Sebastian Thrun”、实体组织“Google”和实体日期“2007”。

Example entity recognition (source: Spacy.io)
NER是自然语言处理(NLP)人工智能领域的一个子集。该领域包含处理和分析自然语言的算法。当NER能够用自然语言识别实体时,如果是个人、组织、日期或地点等与隐私相关的实体,则可以从文本中删除这些实体。
使用NER过滤PII
首先,我们需要一个NLP处理包。NLP包是按语言训练的,因为所有语言都有自己的语法。我们正在与达奇合作,所以我们需要一个了解这一点的人。我们将使用Spacy作为我们的隐私过滤器。
在Spacy网站上可以找到一个帮助安装Spacy的工具。在选择Python环境和语言后,它会给出相应的命令来安装Spacy:
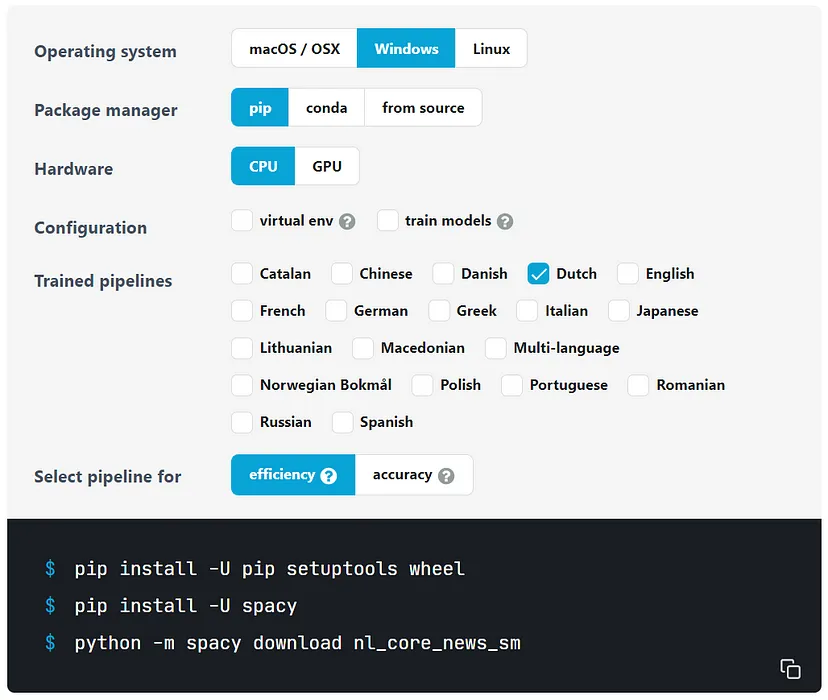
Spacy install tool (source: Spacy.io)
所选管道(效率或精度)决定了NER模型相对于尺寸和速度的精度。选择“效率”会产生更小、更快的模型,但与“精度”相比精度更低。这取决于您的用例哪个模型更合适。为了发展,我们选择使用效率模型。进行第一次净入学率分析:
import spacy
nlp = spacy.load("nl_core_news_sm")
doc = nlp("Geert werkt sinds 2010 voor HAL.")
for token in doc:
print(token.text, token.pos_, token.ent_type_)
'''
Output:
Geert PROPN PERSON
werkt VERB
sinds ADP
2010 NUM DATE
voor ADP
HAL PROPN ORG
. PUNCT
'''
在第2行导入Spacy包之后,将使用Spacy.load()方法加载模型。在这种情况下,加载了Dutch的有效模型。模型由其名称指定,该名称与上一步中用于下载模型的名称相同。要切换到准确的荷兰语模型,请将“nl_core_news_sm”替换为“nl_core _news_lg”。对于上面的示例,这将产生相同的输出。
快速、简单的性能测试表明,加载小型模型大约需要2.0秒,加载大型模型大约需要4.5秒。分析一个句子需要5.5毫秒,而不是6.0毫秒。大型号似乎需要大约500 MB的额外内存。
词性(POS)标签的含义可以在这个网站上找到。例如,它们是:
Geert PROPN PERSON Proper noun, person werkt VERB Verb sinds ADP Adposition, case marking 2010 NUM DATE Numeral, date voor ADB Adposition HAL PROPN ORG Proper noun, organisation . PUNCT Punctuation
对于过滤PII,我们对POS类型NUM和PROPN感兴趣。我们将用描述其实体类型的标签来替换POS文本元素。
import spacy
string = "Geert werkt sinds 2010 voor HAL."
print(string)
nlp = spacy.load("nl_core_news_sm")
doc = nlp(string)
filtered_string = ""
for token in doc:
if token.pos_ in ['PROPN', 'NOUN', 'NUM']:
new_token = " <{}>".format(token.ent_type_)
elif token.pos_ == "PUNCT":
new_token = token.text
else:
new_token = " {}".format(token.text)
filtered_string += new_token
filtered_string = filtered_string[1:]
print(filtered_string)
'''
Output:
Geert werkt sinds 2010 voor HAL.
werkt sinds voor .
'''
代码的第一部分加载语言模型,并将输入字符串解析为令牌列表(doc)。第8-16行中的循环通过迭代文档中的所有标记来构建过滤后的文本。如果令牌的类型为PROPN、NOUN或NUMBER,则会用标记<…>替换,其中标记等于Spacy识别的实体类型。所有令牌都通过前缀空间连接到新字符串。前缀是必需的,因为标记化字符串已经删除了这些前缀。如果是标点符号,则不添加前缀空格(第12-13行)。
在循环之后,由于第11行或第13行的原因,新字符串的第一个字符是一个空格,因此我们需要删除这个空格(第17行)。这导致字符串中没有隐私信息。
它有多好?
在上一篇文章中,我们已经建立了一个基于禁止词列表的隐私过滤器。与NER相比,该学徒需要更多的代码和精力。但它们的比较如何?
- NER要求语法正确的句子。在这种情况下,即使姓名拼写错误,也可以很好地替换隐私信息。NER优于禁言表。
- 无论上下文如何,禁词过滤器都会替换禁词。尤其是街道名称和城市名称的列表会导致大量不必要的删除词。例如,植物名称、动物或城堡等项目等单词作为街道名称很常见,将从文本中删除。这可能会删除许多不必要的单词,从而降低生成文本的可用性。NER的表现会更好。
- 如果文本在语法上不正确(例如,“你叫什么名字?”问题的答案“Peter”将不会被NER过滤为正确。这些句子在聊天信息和对话记录中很常见。在这些情况下,NER方法将失败,因为NER算法无法用一个或几个词来确定这些答案的性质。
因此,这完全取决于您的用例和所需的过滤级别。该组合确定最佳方法是使用禁止列表版本、NER版本还是甚至两者的组合。后者将结合这两种方法的优点(但也有部分缺点)。要找到最佳方法,请使用数据的子集来筛选和测试不同的算法和/或组合,以找到最适合的算法。
将NER与禁止词列表(FWL)进行比较的一些示例:
INPUT: Geert werkt sinds 2010 voor HAL. NER :werkt sinds voor . FWL : werkt sinds voor HAL. INPUT: Heert werkt sinds 2010 voor HAL. NER : werkt sinds voor . FWL : Heert werkt sinds voor HAL. INPUT: Wat is je naam? Geert. NER : Wat is je naam? Geert. FWL : Wat is je naam? FILTERED. INPUT: Geert kijkt naar de duiven op het dak. NER : kijkt naar de duiven op het dak. FWL : kijkt naar de op het dak.
(为了便于比较,所有标签(如<PERSON>)都替换为通用标签<FILTERED>)
- 第一个示例显示tat FWL无法删除公司名称,因为它没有公司名称列表。NER算法在句子上确定了“HAL”是一个名词,更具体地说是一个组织。
- 第二个例子表明,NER可以处理名称中的类型错误,因为它查看句子的结构,而FWL不将“Heert”识别为名称。名称列表只包含拼写正确的版本。
- 第三个例子表明,NER需要语法正确的句子来识别“Geert”这个名字。这可能是一次谈话的记录,也可能是聊天中的互动。它展示了NER如何在书面语言方面表现良好,但在理解口语方面存在困难。
- 在最后一个例子中,FWL删除了“duiven”一词,因为它不仅描述了动物(duiven在荷兰语中是鸽子的意思),而且还是一个城市的名字。
privacy filter code on Github 包含这两种方法,在初始化过程中可以选择NER方法或FWL方法。我们在本文中没有涉及正则表达式,但选择NER方法也会执行正则表达式(NER无法识别和替换URL等)。它还包含了一些使用和过滤的示例文本,以了解两种方法在现实生活中的美国案例中的差异。
最后一句话
本文和前一篇文章描述了删除文本中个人信息的两种方法。这两种方法都有其优点和缺点,不可能为所有用例选择一种方法。删除更多的隐私信息也会导致删除更多的非隐私信息,从而降低过滤文本的价值。NER在删除已识别的隐私信息方面更准确,但需要格式良好的句子才能操作。为了最大限度地提高安全性,甚至可以将这两种方法结合起来。请随意在Github上尝试实现。
我希望你喜欢这篇文章。想要获得更多灵感,请查看我的其他文章
本文:【自然语言处理】用Python从文本中删除个人信息-第二部分 | 开发者开聊
欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.