(2021|EMNLP,CLIP,CLIPScore,RefCLIPScore)CLIPScore:图像标题的无参考评估指标
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
公z号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2. 相关工作
3. CLIPScore
4. 标题评估基准
4.1 标题级别的 Likert 判断
4.2 Pascal-50S 上的成对排名
4.3 MSCOCO 的系统级相关性
4.4 CLIP-S 对“幻觉”敏感性
4.5 CLIP-S 对记忆的敏感性
4.6 我应该报告哪些度量标准?
5. 使用 CLIPScore 的案例研究
5.1 Twitter 的替代文本评分
5.2 Abstract-50S
5.3 个性化标题
5.4 新闻图像标题
6. 结论
S. 总结
S.1 主要贡献
S.2 架构和方法
0. 摘要
图像标题(captioning)传统上依赖于基于参考的自动评估,其中机器生成的标题与人类编写的标题进行比较。这与人类评估标题质量的无参考方式形成了对比。
在本文中,我们报告了一个令人惊讶的实证发现,CLIP(Radford等,2021),一个在来自网络的400M 图像-标题对上预训练的跨模态模型,可以用于对图像标题的强大自动评估,而无需参考。跨足几个语料库的实验证明,我们的新的无参考度量,CLIPScore,与人类判断的相关性最高,优于现有的基于参考的度量,如 CIDEr 和 SPICE。信息增益实验证明,CLIPScore 专注于图像-文本兼容性,与侧重于文本-文本相似性的现有基于参考的度量是互补的。因此,我们还提出了一个参考增强版本,RefCLIPScore,它实现了更高的相关性。除了文字描述任务,几个案例研究揭示了 CLIPScore 在表现良好的领域(剪贴画图像、替代文本评分),但也在相对较弱的领域(例如需要更丰富背景知识的新闻标题)与基于参考的度量相比。
1. 简介
对于大多数文本生成任务,基于参考的 n-gram 重叠方法仍然是自动评估的主要手段。对于图像标题生成,最近的基于参考的度量方法试图通过考虑更丰富的参考-候选相似性模型来超越重叠,例如近似场景图(Anderson等,2016),允许基于参考的方法整合图像(Jiang等,2019;Lee等,2020)。但是,收集参考可能很昂贵,并且即使每个图像有多个人编写的标题通常也是不足够的(见图 1)。因此,对于许多语料库,基于参考的评分与人类质量判断之间仍然存在显著差距。

我们是否需要为图像标题的评估准备参考?毕竟,当人们评估图像标题的适当性时,我们只需查看图像并阅读候选文本即可。
机器翻译中的一个最新趋势作为灵感:其中,无参考评估(有时称为质量估计)的一个关键难题是估计源-候选对之间的跨语言相似性(Blatz等,2004;Specia等,2010;Mehdad等,2012;Specia和Shah,2018)。但是最近的研究(Lo,2019;Yankovskaya等,2019;Zhao等,2020)通过利用大规模、预先训练的多语言模型(例如LASER(Artetxe和Schwenk,2019)或MBERT(Devlin等,2019))学到的跨语言表示,改善了与人类判断的相关性。
我们假设预训练的视觉-语言模型(例如 ALIGN(Jia等,2021)和 CLIP(Radford等,2021))学到的关系可能同样支持图像标题的无参考评估。事实上,它们可以:我们展示了将 CLIP 相对直接地应用于(图像,生成的标题)对,在一系列标准图像描述基准测试(例如 MSCOCO(Lin 等,2014))上,结果与人类判断呈现出令人惊讶的高相关性。我们将这个过程称为 CLIPScore(缩写为 CLIP-S)。除了与人类判断的直接相关性外,信息增益分析显示,CLIP-S 既对常报告的度量(如 BLEU-4、SPICE 和 CIDEr)具有补充性,也对新提出的基于参考的度量(例如ViLBERTScore-F(Lee等,2020))具有补充性。
此外,我们(1)提出了 CLIPScore 的一个参考增强版本,RefCLIPScore,它实现了更高的人类相关性,(2)验证了 CLIP-S 对于对抗性构建的图像标题的敏感性,其中一个名词短语已被替换为一个合理的(但不正确的)干扰项;和(3)构建了一个从未公开发布过的图像语料库,以验证CLIP-S 能够重建人类对以前从未见过的图像的判断。
最后,我们在与四个案例研究的背景下评估了 CLIP-S,这些案例研究不同于无上下文的文字照片描述。在两种情况下,CLIP-S 效果良好:它在 Twitter 上与替代文本(alt-text)质量评分高度相关,并展现出对剪贴画图像-标题进行推理的惊人能力。对于新闻标题生成,基于参考的方法与人类判断最相关。而对于受社交媒体语言启发的情感标题,即使基于参考的度量也无法完全满足。
2. 相关工作
仅基于参考的图像标题评估。通常,图像标题生成模型通过一套基于参考的 5 个度量标准进行评估:BLEU-4(Papineni等,2002)(衡量候选与参考之间的一种 precision 版本),ROUGE-L(Lin,2004)(衡量一种 recall 版本),METEOR(Banerjee和Lavie,2005)(计算单词级别的对齐),CIDEr(Vedantam等,2015)(结合 n-gram tf-idf 加权和词干处理),以及 SPICE(Anderson 等,2016)(对一组参考应用语义解析器,并使用预测的场景图计算相似性)。Yi 等人(2020)提出了一种特定调整到图像标题生成领域的 BERTScore(Zhang等,2020)的重新加权方法(我们将其称为 BERT-S++)。
参考+图像标题评估。最近的度量标准除了使用参考外,还包含图像-文本对齐特征:TIGEr(Jiang等,2019)使用预训练的 SCAN 模型(Lee等,2018),而 ViLBERTScore-F(Lee等,2020)使用预训练的 ViLBERT 模型(Lu等,2019),该模型还在 12 个下游视觉和语言任务上进行了微调(Lu 等,2020)。我们的工作提供了关于下一个逻辑扩展的视角:我们是否可以完全忽略参考,而不是在参考之外还加入视觉-文本交互。
图像标题的自检索。先前的工作已经提出了将自检索损失引入标题生成中的方法,其直觉是良好的标题应该能够以高准确度唯一地识别其图像(Dai和Lin,2017;Luo等,2018;Liu等,2018);监视这种类型的损失可以提供有关模型本身对标题的独特性有多强的见解。CLIP-S 在灵感上类似,但以其作为类似 BLEU-4 或 CIDEr 的外部评估度量的效用而独特。
无参考评估。除了引言中突出的机器翻译案例外,已经提出了其他生成任务的无参考评估,包括摘要(Louis和Nenkova,2013;Peyrard和Gurevych,2018;Sun和Nenkova,2019)和对话(Tao等,2018;Mehri和Eskenazi,2020)。这些度量标准可以是受监督的,依赖于人类判断进行质量评估,也可以是较少监督的,依赖于预训练模型表示。对于图像标题,提出了 VIFIDEL 的一个版本(Madhyastha等,2019)用于无参考评估;然而,基于固定目标词汇表中的图像中检测到的目标的列表计算的 VIFIDEL 通常与基于参考的度量相比,与人类评分的相关性较低。
3. CLIPScore
模型细节。CLIP(Radford等,2021)是一个跨模态检索模型,训练数据包括从网络中收集的 4 亿(图像,标题)对。在搜索引擎上执行了 50 万个搜索 query,,包括常见的单字/双字词、命名实体等。对于每个 query,收集了最多 2 万个(图像,标题)对。
我们使用的模型是 ViT-B/32 版本。它通过 Vision Transformer(Vaswani等,2017;Dosovitskiy等,2021)表示图像,该模型放弃了卷积滤波器,而是采用自注意力映射,在图像块的 7x7 网格之间计算,该网格均匀分割了 224x224 像素的输入图像。此模型有 12 个 Transformer 层和 8600 万个参数。文本同样由一个 12 层的 Transformer 表示,训练过程中使用了包含 49K BPE (Byte Pair Encoding)标记类型的词汇表(Sennrich等,2016)(更详细的描述请参见Radford等,2019)。文本和图像网络都输出单一向量;这些向量旨在分别表示输入标题或图像的内容。在 ViT-B/32 的情况下,这些向量是 512 维。模型的权重经过训练,通过 InfoNCE(Sohn,2016;Oord等,2018)最大化真正对应的图像/标题对的余弦相似性,同时通过最小化不匹配的图像/标题对的相似性。我们在实验中保持这组权重不变。
评估使用 CLIP 的标题生成。为了评估候选生成的质量,我们通过它们各自的特征提取器传递图像和候选标题。然后,我们计算结果嵌入的余弦相似性。我们发现,在候选前缀中加上提示:“A photo depicts” 稍微改善了相关性(这是我们推荐的/标准配置),尽管 “A photo of”,Radford等人(2021)的推荐提示,也效果良好。按照 Zhang 等人(2020)的做法,我们执行重新缩放操作。对于具有视觉 CLIP 嵌入 v 和具有文本 CLIP 嵌入 c 的候选标题,我们设置 w = 2.5,并计算 CLIP-S 如下:
![]()
计算语料库级别的 CLIP-S 时,我们简单地对(候选,图像)对取平均值。请注意,此评估不依赖于基础参考。使用 ViT-B/32 骨干的 CLIP-S 的运行时间很快:在我们的单个消费者 GPU 和硬盘上,大约可以每分钟处理 4K 个图像-候选对。
RefCLIPScore。如果有参考的话,CLIP-S 还可以扩展到与参考结合。我们通过将每个可用参考传递到 CLIP 的文本 transformer 中来提取它们的向量表示;结果是所有参考的向量表示集合 R。然后,RefCLIPScore 被计算为 CLIP-S 和最大参考余弦相似度的调和平均值,即,
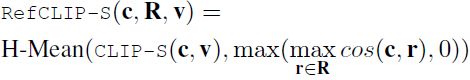
4. 标题评估基准
我们首先在一组文字描述语料库上进行评估。总体而言,这些语料库中的标题(caption)旨在识别和突出显示摄影图像中的文字、显著对象/动作,而不提供额外的上下文。
4.1 标题级别的 Likert 判断
我们首先研究了三个包含人类 Likert 判断的语料库,这些判断是在单个图像/标题对的级别上进行的。Flickr8K-Expert(Hodosh等人,2013)包含了 17K 个 “专家” 人类判断,涉及 5664 张图像:人类在 1 到 4 上对标题进行评分(4=“标题描述图像没有错误”;1=“标题与图像无关”)。Flickr8K-CF 是从 CrowdFlower 收集的包含 145K 个二元质量判断的数据集,覆盖了 48K个(图像,标题)对(1K 个唯一图像)。每对至少有 3 个二元判断,我们取 “yes” 的平均比例作为每对的分数来计算相关性。
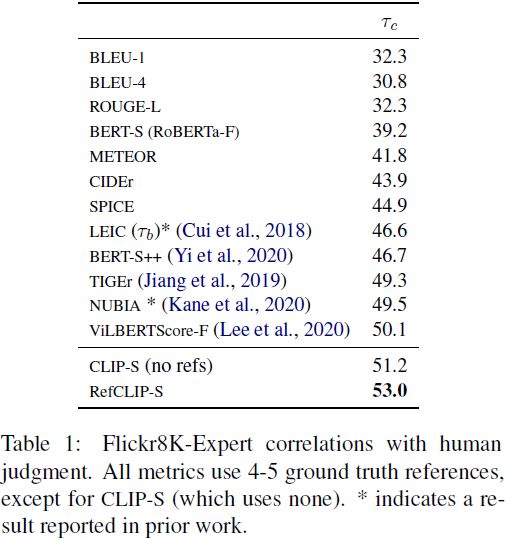

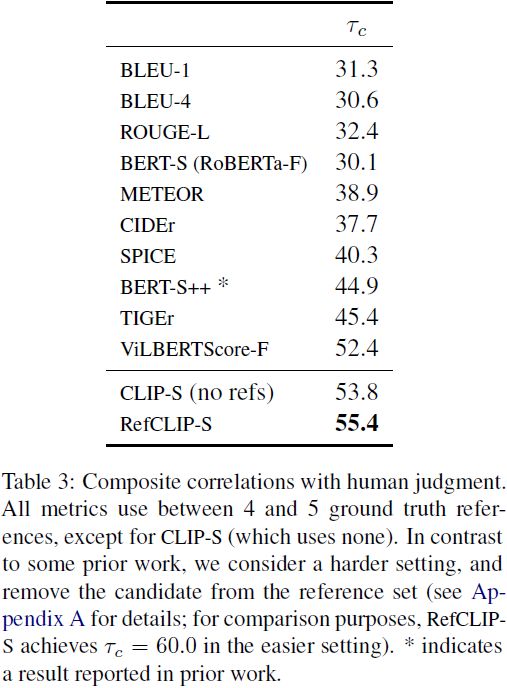
Composite(Aditya等人,2015)包含了来自 MSCOCO(2007 张图像)、Flickr8k(997 张图像)和 Flickr30k(Young等人,2014)(991 张图像)的图像之间的 12K 个人类判断。每个图像最初有五个参考文本,但其中一个被选定由人类在该集合中进行评分(因此在计算度量时我们将其从参考集中移除;这与一些之前的工作不同,请参见附录 A,了解我们为什么考虑更难的设置)。对于 Composite 和 Flickr8K 的判断,我们使用 Kendall 公式计算每个度量与人类评分之间的相关性。 结果 对于 Flickr8K-Expert 的结果见表 1,对于 Flickr8K-CF 的结果见表 2(在 b 中,参照 Cui 等人(2018)),对于 Composite 的结果见表 3。对于我们考虑的标题级别语料库,与以前提出的依赖于参考文献的度量相比,没有引用的 CLIP-S 在与人类判断的相关性上表现更好。此外,在所有情况下,RefCLIP-S 进一步提高了相关性。这为以下结论提供了有力的证据:在这些文字摄影图像描述任务的标题级别上,CLIP 的相对直接的应用可以作为一个强有力的自动评估度量。

4.2 Pascal-50S 上的成对排名
在 Pascal-50S(Vedantam等人,2015)中,评估者对句子对进行了成对偏好判断。总共有 4K 个句子对,均匀分布在四个类别中,例如,两个人类标题,两个机器标题等。对于每对,收集了 48 个人类成对判断。按照先前的工作,我们不计算相关系数,而是计算准确性,即,我们认为由大多数注释者偏好的标题是正确的,并测量评估度量多频繁地为该对的成员分配更高的分数。平局将随机打破。由于在 48 个候选人中随机选择了 5 个参考作为基于参考的度量的基本事实,结果可能与先前的工作略有不同(我们对 5 次参考的随机抽取取平均值)。结果见表 4。评估被分为标题对的四个类别(详细说明见表题)。在所有类别中,CLIP-S 和 RefCLIPS 通常表现出较高的性能。
4.3 MSCOCO 的系统级相关性
CLIP-S 在系统级别上也与人类判断达到了很高的相关性:我们评估了提交到 2015 年 MSCOCO 图像标题挑战赛(Vinyals等人,2016)的系统的输出。我们对这个语料库的标准评估设置有一些顾虑,主要与它只包含 12 个数据点有关(更多讨论请参见附录)。尽管如此,按照标准程序,我们将 CLIP-S 和 RefCLIP-S 与两个度量相关联:“被评价为优于或等于人类标题的百分比(M1)”和通过 “图灵测试” 的标题百分比(M2)。 使用这些系统级别度量,CLIP-S 实现了 Spearman ρ_M1 / ρ_M2 = .59 / .63,而 RefCLIP-S 实现了 ρ_M1 / ρ_M2 = .69 / .74(所有 p < .05)。
4.4 CLIP-S 对“幻觉”敏感性
先前的研究表明,在许多文字描述任务中,人类通常更喜欢标题的正确性而不是特异性(Rohrbach等人,2018,2017)。因此,了解评估度量如何处理包含不正确 “幻觉” 的图像标题,例如对未描绘的对象的引用,是很重要的。我们使用了来自 FOIL 数据集的图像标题样本,该数据集由 Shekhar等人(2017)构建,以测试 CLIP-S 对于检测可能含有不准确细节的描述的敏感性。该语料库由 MSCOCO 的修改后的参考标题组成,其中一个名词短语被对抗性地替换掉,使 FOIL标题变得不正确,例如,将 “摩托车” 换成 “自行车”。
为了适应我们的设置,对于 32K 个测试图像中的每一个,我们采样一个(FOIL,真实)对,并计算每个评估度量在将更高的分数分配给真实候选而不是 FOIL 的能力中的准确性。为了计算基于参考的度量,我们提供 MSCOCO 图像的参考标题(不包括用于评估 FOIL 的真实候选)。虽然我们考虑的成对设置并不完全相同,Shekhar 等人(2017)估计在任务的未成对版本中,相对于 50/50的随机猜测基线,大约有 92% 的人类一致性。
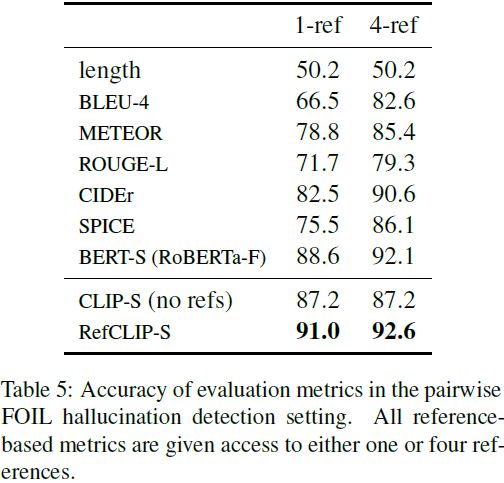
表 5 包含了结果。在这种设置下,对于基于参考的度量来说,访问更多的注释是非常有帮助的,例如,从一个到四个参考的转变会使 SPICE 和 BLEU-4 的准确性提高超过十个百分点。但在有限参考的情况下,没有任何参考的 CLIP-S 胜过除 BERT-S(RoBERTa-F)之外的所有度量。而 RefCLIP-S 在所有情况下都效果最好。总体而言,我们使用了Shekhar等人(2017)的语料库,特别是在有限的参考可用的情况下,证实了 Rohrbach 等人(2018)的发现,“对象幻觉不能总是基于传统的句子度量来预测”。然而,在成对设置中,CLIP-S 和 RefCLIP-S 提供了性能改进。
4.5 CLIP-S 对记忆的敏感性
关于基于模型的评分方法的一个担忧是记忆,即,如果一个模型的权重是使用大型语料库预训练的,存在一种风险,即在评估时使用的数据在预训练时已经被看到。尽管 Radford 等人 (2021) 进行了一项训练-测试重叠分析,并发现 CLIP 由于记忆而不太可能成功,但我们仍然进行了一项实验,使用了 CLIP 之前从未见过的图像。
本文的作者创建了一组 250 张从未发布到互联网上的图像,通过汇总个人照片而成。该集合包含各种类似于 Flickr 的情境,例如自然场景、动物、城市街道、物体等。对于每张图像,我们收集了两个自动生成的标题:一个来自商业 API,Microsoft Azure Cognitive Services (v 3.1)10,另一个来自 Luo 等人 (2018) 的预训练模型,该模型经过训练以最大化与自临界基线的 CIDEr 分数。然后,对于每张图像,本文的三位作者独立选择了哪个标题更准确地描述了图像内容。相对于 50% 的随机基线(和选择较短标题的 72% 长度基线),CLIP-S 在 86% 的情况下正确恢复了大多数人的首选。此语料库的人类一致性为 93%。
虽然这个设置不能明确反驳 CLIP 之所以工作良好是因为它已经记住了图像的观点,但我们希望这里的结果能为关于 Web 规模预训练模型泛化性质的讨论做出贡献。
4.6 我应该报告哪些度量标准?
大多数标题生成工作报告了多个度量标准,每个度量标准(据推测)与人类判断有不同程度的相关性。但并不总是清楚个别度量标准是否捕捉到人类判断的不同或冗余维度。例如,虽然 CLIP-S 和 ViLBERTScore-F 都产生了高度相关性,它们是冗余的还是互补的并不总是清楚。
我们寻求解释人类判断中最大方差的(最小)度量标准集。为了找到这个集合,我们对包括六个广泛报告的度量标准 13 和四个新度量标准 BERT-S(RoBERTa-F)、TIGEr、ViLBERTScore-F 和 CLIP-S 的十个候选度量标准进行了前向选择(我们还包括以 RefCLIP-S 而不是 CLIP-S 开始的实验)。从一个空集开始,我们通过选择最具信息的附加度量标准进行迭代贪婪选择添加。为了估计方差,我们使用语料库的 bootstrap 重采样版本重复进行前向选择过程 10 次。
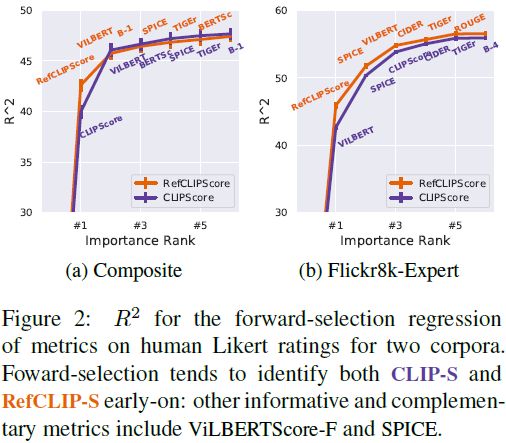
图 2 显示了在 Composite 和 Flickr8K-Expert 语料库上运行此实验所产生的信息增益;我们还显示了在每次迭代中最常选择的度量标准是哪一个(较早 = 更多信息增益)。对于 Composite,CLIP-S(或 RefCLIP-S)总是首先被选择,然后是 ViLBERTScore-F,然后(最常见的是) BERT-S(RoBERTa-F)。对于 Flickr8k-Expert,前三个选择总是 CLIP-S(或 RefCLIP-S)、ViLBERTScore-F 和 SPICE。虽然 CLIP-S 和 ViLBERTScore-F 倾向于是最具信息的度量标准,(1)尽管它们相关,它们并不纯粹是冗余的;(2)像 SPICE 这样的不考虑图像的基于参考的度量标准仍然可能是有用的。
总的来说,这些结果表明,像 CLIP-S 这样考虑视觉内容的评估度量标准确实捕捉到了目前由纯文本参考度量标准未涵盖的人类判断轴。对于我们考虑的文字图像描述评估设置,报告的度量标准的一个合理组合至少应包括一个图像感知度量标准(例如,CLIP-S)和一个强的仅参考度量标准(例如,SPICE)。

5. 使用 CLIPScore 的案例研究
迄今为止,我们的结果已经证明了 CLIP 编码了对评估文字图像描述任务有用的信息。但是,与 CLIP-S 相比,基于参考的度量标准可能在先验上似乎更具适应性。CLIP-S 是否与人类判断在 MSCOCO 和 Flickr8K 之类的情况之外的案例中存在相关性呢? 为了解决这个问题,我们考虑了四个案例研究,探讨了在 “不同” 图像描述数据集中 CLIP-S 与人类判断之间的相关性。这些语料库在质量上与第 4 节探讨的更受欢迎的领域不同,要么是因为图像不是来自 Flickr 的 “日常” 图像,要么是因为标题不是文字描述(图 3 说明)。
5.1 Twitter 的替代文本评分
在上传推文时,Twitter 用户有提供替代文本的选项:尽管很少有人使用这个功能(Gleason 等人 (2019) 发现少于 0.1% 的图像推文有替代文本),但它的广泛采用可能在某一天使社交媒体对低视力和盲用户更具可访问性。我们衡量了 CLIP-S 重建了一组 2.8K 人类对替代文本质量的判断的能力。这个语料库由 Gleason 等人 (2019, 2020) 的作者收集和评分。每个替代文本都根据其作为替代文本的可能效用在 0 到 3 的尺度上评分。虽然评分人员本身是有视力而不能直接评估给定替代文本(alt-text)对低视力或盲评用户的效用,但他们是设计和评估替代文本系统的专家。推文是从 Twitter FireHose API 和站点的低视力和盲评用户的时间轴中混合抽样的。在质量上,这些图像与 Flickr 等领域相比更广泛,例如截图、表情包等。替代文本的候选项是用户上传和机器生成的混合。该语料库不包含参考,但为了与基于参考的度量标准进行比较,我们(通过编程方式)将推文的任何文本上下文都视为参考。
CLIP-S 在与人类判断的相关性方面达到了48.4%。相比之下,由于推文文本不够可靠作为可行的替代文本,基于参考的方法表现不佳:最佳的纯基于参考的度量标准 BERT-S(RoBERTa-F)(达到15%)相对于长度基线(达到25%)表现较差。虽然收集高质量的上下文参考替代文本是未来工作的一个有希望的方向,但在这个领域,CLIP-S 提供了一个有希望的评估度量标准候选。
5.2 Abstract-50S
我们评估 CLIP-S 在抽象的非摄影剪贴画图像上的泛化能力,使用 Abstract-50S(Vedantam 等人,2015)。该数据集将剪贴画图像(最初由 Zitnick 和 Parikh(2013)构建)与 48 个人工编写的参考标题配对。这些图像描绘了两个卡通角色,Mike 和 Jenny,在各种户外情境中,例如进行体育运动、野餐等。对于 400 个人工编写的候选标题对(其中 200 对来自同一图像,200 对来自不同图像),收集了人类判断:标注者被指示选择哪个配对的标题更类似于每个参考标题,因此为每个候选对收集了 48 个判断(总共 19200 个)。 当给定对五个参考标题的随机样本访问时,我们将 CLIP-S 与几个基于参考的度量标准进行比较。按照我们对 Pascal-50S 的程序,我们随机重新采样了 5 次,并报告了平均成对准确性。两个基线(BL)都达到了 53:仅长度(即,说较长的标题更好)和将图像随机洗牌作为输入提供给 CLIP-S(以便它不能依赖有意义的视觉-文本交互)。

总体而言,虽然相对于基于参考的度量标准,CLIP-S 的性能较差,但相对于基线来说,它的表现要好得多。这个结果表明,即使在非摄影图像中,CLIP-S 也能够推理关于视觉-文本交互的信息。
5.3 个性化标题
受社交媒体上的语言使用启发,Shuster 等人(2019)通过提示标注者以 “个性”(例如,戏剧性的、富有同情心的、悲伤的等)收集了图像标题,并要求他们 “在给定个性特征的情境下,写一个别人会觉得有趣的图像评论”。为了评估他们的模型,作者收集了成对的人类判断,评估者被指示“选择哪个评论最引人入胜”。我们评估 CLIP-S 的两个能力: (1) 它是偏好文字描述,还是较不文字的、更引人入胜的个性化标题?; (2) 如果给定两个个性化标题,它能否预测人类判断哪个更引人入胜?
对于(1):在一组 2.4K 的 “传统” 与个性化标题成对评分中,人类评价个性化标题更引人入胜的比例为 65%,而 CLIP-S 更喜欢传统的描述的比例是 80% 。我们的结论是:当给定一个直接的描述和一个更引人入胜的非文字标题时,CLIP-S 通常会更喜欢文字描述。
对于(2):CLIP-S 的性能略优于随机,例如,在比较两个神经生成模型(TransResNet(ResNeXt-IG-3.5B)与 TransResNet(ResNet-152))的 2.5K 人类成对判断时,为 57%,但不比仅长度的基线更好(也是 57%)。值得注意的是,即使是基于参考的度量标准也未能与该语料库上关于引人入胜的成对人类判断提供相关性:例如,当提供一个个性化的参考时,BLEU-4、CIDEr 和 SPICE 分别在 52%/53%/51% 的情况下与人类判断一致。我们的结论是:当给定两个引人入胜的非文字描述时,无论是 CLIP-S 还是传统的基于参考的度量标准都未能预测人类会判断哪个更引人入胜。
5.4 新闻图像标题
Biten 等人(2019)考虑了纽约时报文章中的图像标题生成;他们的任务与 MSCOCO 不同,因为 1) 95% 的标题至少包含一个命名实体,例如政治家、名人或地方;2) 标题通常 “不描述场景对象,而是提供场景的情境化解释”。他们在 106 张图像上收集了 2.1K 对人类判断,比较了两个新闻图像标题生成模型的性能。对于每张图像,有 20 个标注者被指示选择两个模型生成中哪个更接近地面真实标题(他们还看到了图像本身)。我们比较了度量标准在匹配两个候选之间的人类判断方面的准确性。
基于参考的度量标准占主导地位:METEOR 和 BLEU-4 的准确性分别达到了 93 和 91,而 CLIP-S 的准确性仅略高于随机的 65。从质量上来看,CLIP-S 在存在可以通过视觉验证的内容时成功,例如,将黑白照片与较早的日期进行匹配(例如,在一个案例中选择 1933 年 vs. 1977 年),以及匹配特别有代表性的名人(例如,它自信地识别出穆罕默德·阿里拳击)。但它最常见的失败案例是仅通过图像内容可能无法验证的标题。例如:对于一个房间的图像,CLIP-S 选择了 “Elle Decor 的餐厅”,但标注者更喜欢提到 “纽约青年联盟” 的标题;地面真实标题揭示了为什么图像被拍摄的原因:“纽约青年联盟于 5 月 7 日进行的曼哈顿家庭之旅。”
总体而言,在这种情况下,我们不提倡无参考的评估,特别是因为我们的结果表明(至少对于这个特定的注释集),基于参考的 n-gram 重叠度量与人类判断存在高度相关性。
6. 结论
对于文字图像描述任务,CLIPScore 在不使用参考时以现成的方式实现了与人类对标题质量的判断的高度相关性。对于不同领域的附加实验表明,CLIP 还可以推理非摄影剪贴画,并且在替代文本(alt-text)情况下作为无参考评估的合理选择。有希望的未来工作包括探索:1) 将 CLIP-S 作为文字标题生成器的强化学习奖励;和 2) 少量标记的人类评分数据是否可以帮助 CLIP-S 适应其困难的领域,例如引人入胜的预测。我们希望我们的工作能够为有关预训练模型在生成评估中的作用的持续讨论做出贡献。
无参考评估存在一些风险。与 BERTScore 一样,基于模型的度量标准如 CLIP-S 反映了预训练数据的偏见。虽然我们认为将 CLIP-S 用作文字标题质量的离线评估指标符合 CLIP 模型卡(Mitchell 等人,2019)的建议,Agarwal 等人(2021)的研究表明 CLIP 可能对人们进行不成比例的错误分类,例如,“男性图像被误分类为与犯罪相关的类别。” 探讨候选生成的潜在社会偏见(例如,参见 Hendricks 等人(2018))仍然至关重要,特别是如果要部署系统。
同期工作。在提交过程中,引入了两个替代的无参考评估度量,用于图像标题生成:FAIEr(Wang 等人,2021)(基于预训练的目标检测器,并在 MSCOCO 上进行微调)和 UMIC(Lee 等人,2021)(基于 UNITER(Chen 等人,2020))。特别是 UMIC 在直接图像描述任务(§4)上与 CLIP-S 相比产生了类似的与人类判断的相关性,但采用了在合成负面标题上进行微调的补充方法。未来的工作可以探索 Lee 等人(2021)提出的文本数据增强是否会产生一种与未微调的 CLIP-S(第 4.6 节)相补充或相重叠的度量标准;以及(2)是否可以扩展到非文字描述的情况(第 5 节)。
S. 总结
S.1 主要贡献
预训练的跨模态模型 CLIP 是用于图像标题的强大自动评估,且无需参考。本文提出无参考度量,CLIPScore,与人类判断的相关性最高,优于现有的基于参考的度量,如 CIDEr 和 SPICE。信息增益实验证明,CLIPScore 专注于图像-文本兼容性,与侧重于文本-文本相似性的现有基于参考的度量是互补的。因此,还提出了一个参考增强版本,RefCLIPScore,它实现了与人类判断更高的相关性。
S.2 架构和方法
CLIP。本文使用的模型是 ViT-B/32。
- 它通过使用自注意力映射的 Vision Transformer 表示图像。此模型有 12 个 Transformer 层和 8600 万个参数。
- 文本同样由一个 12 层的 Transformer 表示,训练过程中使用了包含 49K BPE (Byte Pair Encoding)标记类型的词汇表。
- 文本和图像网络都输出单一向量;这些向量旨在分别表示输入标题或图像的内容。
- 模型的权重经过训练,通过 InfoNCE 最大化真正对应的图像/标题对的余弦相似性,同时通过最小化不匹配的图像/标题对的相似性。在实验中保持这组权重不变。
CLIPScore 的计算如下所示:
![]()
其中,v 是视觉 CLIP 嵌入,候选标题 c 的文本 CLIP 嵌入,设置 w = 2.5。
RefCLIPScore。将每个可用参考标题传递到 CLIP 的文本 transformer 中来提取它们的向量表示。然后,RefCLIPScore 被计算为 CLIP-S 与最大参考余弦相似度的调和平均值,即,