这绝对是你见过的最全深度学习服务器管理配置手册,学不会你打我
这绝对是你见过的最全深度学习服务器管理/配置手册,学不会你打我
最近在配置服务器,遇到了不少问题,在此整理记录一下。主要是以下几个方面:多用户管理、服务器环境配置、Anaconda虚拟环境安装TensorFlow/PyTorch、远程访问。
目录
-
-
- 这绝对是你见过的最全深度学习服务器管理/配置手册,学不会你打我
-
- 一、多用户管理
-
- 1、新建/删除用户
- 2、更改用户权限
- 二、服务器环境配置
-
- 1、安装NVIDIA驱动
- 2、安装CUDA Toolkit
- 3、配置启动内核
- 4、挂载硬盘
- 三、Anaconda虚拟环境配置
-
- 1、安装Anaconda
- 2、配置TensorFlow虚拟环境
- 3、配置PyTorch虚拟环境
- 四、服务器远程访问配置
-
- 1、配置ssh
- 2、配置xrdp
- 3、配置frp内网穿透
- 4、配置frp开机自启
- 五、遇到的其他问题
-
一、多用户管理
1、新建/删除用户
参考:Linux下useradd命令与adduser命令的区别
linux新建用户命令有两个:useradd和adduser。这两个命令略有区别,总结如下:
1、adduser会自动创建用户组,useradd不会自动创建,需要加参数
2、adduser会自动创建用户目录,useradd不会自动创建,需要加参数
3、adduser会自动选择shell版本,useradd不会自动选择
4、adduser会提示添加用户密码,useradd不会
推荐使用adduser来创建新用户,设置完密码之后,一切默认即可:
sudo adduser test_user
参考:Linux的userdel和deluser命令
类似地,删除用户命令也有两个:userdel和deluser,区别如下:
1、deluser的选项要比userdel丰富,功能要更强大
2、deluser可以删除普通用户、从系统中删除用户组、将用户从一个组中删除
推荐使用usedel来删除用户,并使用-r选项删除用户目录:
sudo userdel -r test_user
2、更改用户权限
参考:Linux下添加用户并赋予root权限三种方法
对于新建的用户可能需要赋予root权限,推荐使用如下方法:
1、vim /etc/sudoers ,找到下面内容
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
2、在root后添加如下内容
test_user ALL=(ALL) ALL
3、修改后的文件内容如下,此时通过sudo命令,test_user即可获得root权限
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
test_user ALL=(ALL) ALL
二、服务器环境配置
1、安装NVIDIA驱动
对于深度学习服务器,可以使用nvidia-smi命令查看显卡使用情况,这就需要安装NVIDIA驱动。
1、去官网下载显卡对应的驱动版本,先选择显卡版本,然后点击搜索和下载即可


2、上传驱动程序至服务器,并赋予可执行权限
sudo chmod +x NVIDIA-Linux-x86_64-515.76.run
3、安装驱动程序,然后按照提示安装即可
sudo ./NVIDIA-Linux-x86_64-515.76.run
安装过程可能遇到如下问题,对应解决方案如下:
参考:安装 NVIDIA 显卡驱动时报错:An NVIDIA kernel module ‘nvidia-drm‘ appears to already be load
1、An NVIDIA kernel module ‘nvidia-drm‘ appears to already be load
原因:因为安装的是Ubuntu 图形化版本,之前也安装了 NVIDIA 驱动和 CUDA,系统加载图形化界面后,就会自动加载运行 NVIDIA 相关模块(如:nvidia-drm、nvidia-modeset 等)。
解决方法:启动 Ubuntu 系统时不让系统加载图形化界面 。在终端命令模式下卸载 NVIDIA 驱动,再重装新的驱动。
# 1. 获得超级用户权限
sudo -i
# 2. 关闭所有使用 GPU 的进程
sudo systemctl isolate multi-user.target
sudo modprobe -r nvidia-drm
# 3. 重装 NVIDIA 驱动
sudo ./NVIDIA-Linux-x86_64-XX.run
# 4. 打开使用GPU的进程
sudo systemctl set-default multi-user.target
# 5. 重新启动
sudo reboot
2、缺失gcc或make
sudo apt-get install gcc
sudo apt-get install make
3、x server或nouveau相关
sudo ./NVIDIA-Linux-x86_64-XX.run --no-x-check --no-nouveau-check
4、貌似安装驱动时加上 --no-opengl-files可以避免重启后nvidia-smi命令失效
5、如果出现ERROR: Unable to load the kernel module ‘nvidia.ko’. 安装输出的日志,可能是gcc原因,也可能是nouveau的原因。如果是nouveau的原因,可参考TITAN RTX安装驱动、cuda10 cudnn神报错: ERROR: Unable to load the kernel module ‘nvidiko‘
# 查看lightdm和dgm状态
sudo service lightdm status
service gdm status
# 如果正在运行,就stop;否则忽略即可
sudo service lightdm stop
service gdm stop
# 修改/etc/modprobe.d/blacklist.conf,末尾添加如下两行:
blacklist nouveau
options nouveau modeset=0
# update
sudo update-initramfs -u
# 重启
sudo reboot
# 查看nouveau状态,如果没有输出,则说明ok了
lsmod | grep nouveau
2、安装CUDA Toolkit
1、去官网选择要安装的版本
2、以cuda 11.1为例,选择系统配置

3、执行安装命令,由于前面已经安装了nvidia驱动,所以在安装选项里要取消Driver
wget https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run
sudo sh cuda_11.1.1_455.32.00_linux.run

4、将cuda写入环境变量,由于是多用户系统,推荐在/etc/profile文件(所有用户均生效)的末尾写入,也可以在~/.bashrc文件(仅当前用户生效)的末尾写入
#####################cuda11.1#######################
export PATH=$PATH:/usr/local/cuda-11.1/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.1/lib64
5、source刷新环境变量
source /etc/profile
安装过程可能遇到如下问题,对应解决方案如下:
1、gcc版本太高
推荐使用gcc 9.4.0,也可以根据提示no-check
参考:Ubuntu中gcc、 g++安装与卸载
# 1.卸载
sudo apt-get remove gcc gcc-xx #可能有多个版本,都要删掉
sudo apt-get remove g++
# 2.安装gcc、g++
sudo apt-get install gcc # 默认安装的是gcc 9.4.0
sudo apt-get install build-essential
3、配置启动内核
在安装好NVIDIA驱动后,如果重启服务器,可能出现一种奇怪的现象:nvidia-smi命令无法使用,NVIDIA-SMI has failed because it couldn‘t communicate with the NVIDIA driver。
这是由于系统内核版本过高,导致NVIDIA驱动失效,这时候就需要配置启动内核,步骤如下:
1、查看当前内核版本,默认是5.15.0
uname -a
2.安装旧的内核,亲测5.11.0-34-generic可用
参考:UBUNTU 18.04安装指定内核
apt-get install linux-image-5.11.0-34-generic linux-headers-5.11.0-34-generic linux-modules-extra-5.11.0-34-generic
如果安装成功,使用
dpkg --list | grep linux-image
就可以从列表中看到 linux-image-5.11.0-34-generic
3.修改系统默认启动内核
需要修改/etc/default/grub文件来设置系统启动的内核,该配置文件默认内容如下:
GRUB_DEFAULT=0 # 默认内核启动项
GRUB_TIMEOUT_STYLE=hidden # 系统启动时菜单是否显示
GRUB_TIMEOUT=0
GRUB_DISTRIBUTOR=`lsb_release -i -s 2> /dev/null || echo Debian`
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
GRUB_CMDLINE_LINUX=""
我们要修改的就是第一项,那么如何修改第一项使得我们的启动内核变为我们想要的版本呢?有三种方式:
-
在重启时,快速按
ESC进入GNU grub界面,通过启动菜单来观察我们需要的内核,可参考:Ubuntu指定默认Linux内核启动但是这种方法只适合于本地机器,对于服务器来说,我们通常不会到机房去直接连接机器进行操作。
-
直接在GRUB_DEFAULT中指定内核版本,可参考:Ubuntu设置开机时启动的系统内核版本 & 安装低版本内核
这种方法直接修改配置文件第一行为:
GRUB_DEFAULT="Advanced options for Ubuntu>Ubuntu, with Linux 5.11.0-34-generic"注意,如果按照这种方式修改更新并重启后,发现系统内核版本并未切换成功,可能是因为你的系统语言是中文。所以需将第一行修改为:
GRUB_DEFAULT="Ubuntu 高级选项>Ubuntu,Linux 5.11.0-34-generic" -
由于第一种方法需要连接机器来实现,那有没有办法不连接机器就可以知道启动菜单呢?当然是有的,这就是第三种方法。可参考:Ubuntu修改默认启动的内核版本(grub)
首先查看启动菜单的配置文件
cat /boot/grub/grub.cfg | grep menuentry # 结果如下: menuentry 'Ubuntu' submenu 'Advanced options for Ubuntu' menuentry 'Ubuntu, with Linux 5.15.0-50-generic' menuentry 'Ubuntu, with Linux 5.15.0-50-generic (recovery mode)' menuentry 'Ubuntu, with Linux 5.15.0-48-generic' menuentry 'Ubuntu, with Linux 5.15.0-48-generic (recovery mode)' menuentry 'Ubuntu, with Linux 5.11.0-34-generic' menuentry 'Ubuntu, with Linux 5.11.0-34-generic (recovery mode)' menuentry 'UEFI Firmware Settings'在上述显示信息的情况下,说明grub开机启动界面的菜单结构理应如下:
*Ubuntu # *表示一级菜单 *Advanced options for Ubuntu **Ubuntu, with Linux 5.15.0-50-generic # **表示二级菜单 **Ubuntu, with Linux 5.15.0-50-generic (recovery mode) **Ubuntu, with Linux 5.15.0-48-generic **Ubuntu, with Linux 5.15.0-48-generic (recovery mode) **Ubuntu, with Linux 5.11.0-34-generic **Ubuntu, with Linux 5.11.0-34-generic (recovery mode) *UEFI Firmware Settings所以我们需要将配置文件第一行修改为:
GRUB_DEFAULT="1>4" # 表示进入第1个一级菜单下的第4个二级菜单(菜单的起始索引为0,所以"Advanced options for Ubuntu"对应的就是0, "Ubuntu, with Linux 5.11.0-34-generic"对应的就是4)
4.更新配置文件并重启
sudo update-grub
sudo reboot
重启完成后,可使用
uname -a
再次查看内核版本是否正常切换
4、挂载硬盘
在配置深度学习服务器时,除了系统盘外,还会存在多个数据盘,为了方便访问,需要将这些数据盘挂载到指定目录。可参考:Ubuntu硬盘的挂载(临时、永久挂载)
1、临时挂载
sudo mkdir /data # 在根目录下新建目录data作为挂载目录
sudo mount /dev/sdb1 /data # 将硬盘/dev/sdb1挂载到/data目录,可通过sudo fdisk -l | grep /dev来查看磁盘情况
2、开机自动挂载
修改/etc/fstab文件,添加如下内容:
/dev/sdb1 /data auto defaults 0 0
命令格式为:
/dev/device mountpoint type rules dump order
设备名称 挂载点 分区类型 挂载选项 dump选项 fsck选项
各参数含义如下:
设备名称 挂载点 分区类型 挂载选项 dump选项 fsck选项
- 设备名称可以通过sudo fdisk -l | grep /dev来查看
- 挂载点即创建的挂载目录
- 分区类型指的是该磁盘的文件系统
- default的意义是在于按照大多数文件系统的缺省值设置挂载定义,即系统的默认定义(对于大多数文件系统的处理方式),其实除了default还有auto就是开机自动挂载,noauto就是开机不自动挂载,nouser就是只有超级用户才挂载,user,所有用户都挂载
- dump 就是从不备份
- fsck的检查顺序,0为不检查,分区为1,其他分区从2开始,这里指的是检查的优先级
三、Anaconda虚拟环境配置
1、安装Anaconda
在使用服务器时,可以使用Anaconda来创建和管理多个虚拟环境,非常好用。安装步骤如下:
1、去官网下载安装文件

2、上传至服务器并赋予执行权限
chmod +x Anaconda3-2022.05-Linux-x86_64.sh
3、安装
sh ./Anaconda3-2022.05-Linux-x86_64.sh
注意,安装路径默认是当前用户的home目录下的anaconda3,例如:/home/test_user/anaconda3。在询问是否执行conda initialization时,选择yes,这样就不需要自己配置环境变量了(默认写入~/.bashrc文件)。
2、配置TensorFlow虚拟环境
1、新建一个Python环境
conda create -n tf2.6 python=3.8 # 新建一个名为tf2.6的Python3.8环境
conda activate tf2.6 # 激活tf2.6环境
注:推荐Python环境为3.6-3.9,太高或太低都可能出现一些问题
2、下载TensforFow-GPU版本
pip install tensorflow-gpu==2.6.0 # 通过pip下载tensorflow-gpu的2.6.0版本
3、验证是否安装成功,执行如下Python代码即可:
import tensorflow as tf
tf.test.is_gpu_available()
4、tensorflow最近更新到2.12+版本了,有大坑。2.12+版本不再区分cpu和gpu,所以需要自己配置好cuda和cudnn环境。
如果想安装新版本,有点麻烦,可参考关于GPU版本tensorflow2.12.0版本安装问题。推荐的安装方式可参考:tensorflow gpu 快速安装与验证(自动装配,无需手动选择 cudnn,cudatoolkit),conda-forge通道很慢,尽量不要使用。
5,直接用pip安装tensorflow-gpu需要配置好cudnn,具体可参考Ubuntu 18.04安装CUDA和cuDNN
1, 从官网download与cuda版本对应的cudnn包
2,解压
3,将指定文件复制到cuda安装目录
4,赋予相关权限
3、配置PyTorch虚拟环境
1、新建一个Python环境
conda create -n py1.7 python=3.7 # 新建一个名为py1.7的python3.7环境
conda activate py1.7 # 激活py1.7环境
2、下载PyTorch-GPU版本
去官网查看对应版本的安装命令并执行
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
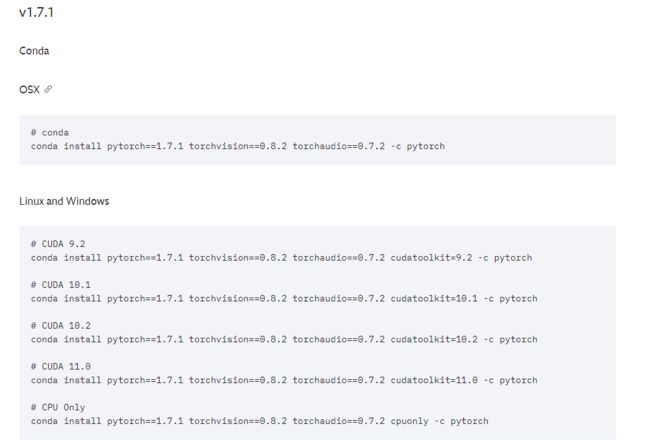
3、验证是否安装成功,执行如下Python代码即可:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
4、注意conda-forge这个通道会比较慢,所以安装pytorch的时候,最好选择不带conda-forge的命令,例如:
# CUDA 11.3, 推荐,速度很快
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
# CUDA 11.6,不推荐,速度很慢
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge
四、服务器远程访问配置
1、配置ssh
配置ssh是服务器配置的第一步,只有这样,才可以通过ssh命令远程访问服务器。
参考:使用Linux,从正确配置ssh开始
sudo apt update
sudo apt install openssh-server -y
sudo systemctl status ssh #查看状态
# 如果你的防火墙开启了,使用下面语句
sudo ufw allow ssh
配置好ssh之后,就可以使用ssh命令远程访问服务器了。
ssh username@server_ip -p ssh_port # 例如 ssh [email protected] -p 22
2、配置xrdp
当配置ssh之后,也只能使用终端来远程访问服务器,如果要使用图形界面,例如Windows的远程桌面来访问就需要配置xrdp。可参考:如何在Ubuntu 20.04 上安装 Xrdp 服务器(远程桌面)
sudo apt install xrdp # 安装xrdp
sudo systemctl status xrdp # 查看xrdp状态
sudo adduser xrdp ssl-cert # 将xrdp用户添加到"ssl-cert"用户组
sudo systemctl restart xrdp # 重启xrdp服务
3、配置frp内网穿透
由于服务器一般只限于局域网内访问,这就使得外地远程访问并不友好,可以通过frp配置内网穿透来实现外地访问服务器。可参考:ubuntu frp方式,实现内网穿透
1、准备
需要准备一台可以正常访问的具有公网ip的外网服务器,可以购买阿里云、腾讯云等云服务器。
外网服务器需要开启相应的访问端口,包括:连接端口和转发映射端口。
在准备好外网服务器之后,去GitHub下载对应的程序包。
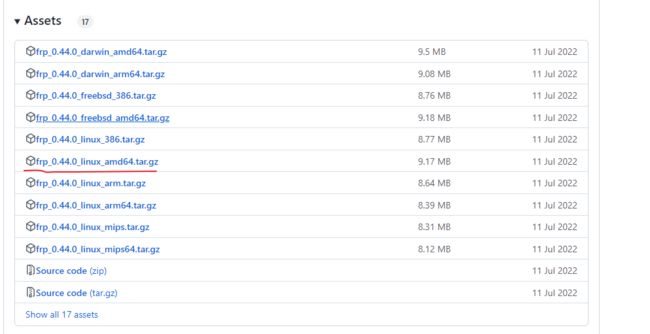
2、配置frps服务器端
-
将程序包上传至外网服务器,并解压
tar -xzvf frp_0.44.0_linux_amd64.tar.gz -
配置frps.ini文件
[common] bind_port = 7000 # 外网服务器和本地服务器连接的端口 -
启动frps服务器
nohup ./frps -c frps.ini >frps.log 2>&1 &
3、配置frpc客户端
-
将程序包上传至本地网服务器,并解压
tar -xzvf frp_0.44.0_linux_amd64.tar.gz -
配置frpc.ini文件
[common] server_addr = 外网服务器公网ip server_port = 7000 [ssh-22] # 转发映射22端口 type = tcp local_ip = 127.0.0.1 local_port = 22 # 本地服务器的22端口 remote_port = 2222 # 外网服务器的2222端口 [ssh-3389] # 转发映射3389端口 type = tcp local_ip = 127.0.0.1 local_port = 3389 # 本地服务器的3389端口 remote_port = 3390 # 外网服务器的3390端口 -
启动frpc客户端
nohup ./frpc -c frpc.ini >frpc.log 2>&1 &
4、配置frp开机自启
nohup启动只能保证frp服务会一直挂载在后台,如果服务器重启,frp服务也会中断。因此需要配置开机自启,以本地服务器配置frpc开机自启为例。可参考:frp设置开机自启的几种方法
1、安装Supervisor
sudo apt install supervisor
2、配置frpc服务
sudo vim /etc/supervisor/conf.d/frpc.conf
文件内容如下:
[program:frpc]
command = /your_frp_path/frpc -c /your_frp_path/frpc.ini
autostart = true
记得给frpc chmod +x 赋予可执行权限
3、重启Supervisor
# 重启supervisor
sudo systemctl restart supervisor
# 查看supervisor运行状态
sudo supervisorctl status
五、遇到的其他问题
1、ubuntu网络链接激活失败
参考:ubuntu网络链接激活失败,或者网络链接图标不显示的问题
sudo service network-manager restart # 重启网络
sudo service network-manager stop
sudo rm /var/lib/NetworkManager/NetworkManager.state
sudo service network-manager start
2、E:无法定位软件包
参考:解决 Ubuntu 无法定位软件包问题
把软件和更新里面的"下载自:主服务器"改为"下载自:中国的服务器"即可