PyTorch深度学习实战(27)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(27)——变分自编码器
-
- 0. 前言
- 1. 变分自编码器
-
- 1.1 自编码器的局限性
- 1.2 VAE 工作原理
- 1.3 VAE 构建策略
- 1.4 KL 散度
- 1.5 重参数化技巧
- 2. 构建 VAE
- 小结
- 系列链接
0. 前言
变分自编码器 (Variational Autoencoder, VAE) 是一种生成模型,结合了自编码器和概率模型的思想,通过学习输入数据的潜分布,能够生成新的样本。与传统的自编码器不同,变分自编码器引入了概率建模的思想,并通过编码器和解码器之间的随机性来实现生成过程。编码器将输入数据映射到潜空间中的概率分布,假设潜变量是从多元正态分布中采样得到的,解码器则将从潜空间采样得到的潜在变量映射回原始数据空间,并生成新的样本。本节中,将介绍变分自编码器的基本概念,并使用 PyTorch 实现变分自编码器生成新图像。
1. 变分自编码器
变分自编码器 (Variational Auto-Encoders, VAE) 是一种基于变分贝叶斯 (Variational Bayes, VB) 推断的生成式网络架构,与自编码器通过数值的方式描述潜空间不同,VAE 以概率分布的形式描述潜空间,使数据生成成为可能。
1.1 自编码器的局限性
相似的图像会被分组到同一集群中,使用自编码器可以重建(解码)属于给定集群的潜变量。但是,如果潜变量位于两个集群之间时,使用自编码器无法保证会生成逼真图像,在这种情况下,就需要使用变分自编码器。
在构建变分自编码器之前,首先通过采样潜变量生成图像,观察自编码器在重建位于不同集群中间的潜变量时的局限性。
(1) 使用训练的自编码器模型计算中验证图像的潜变量 (embeddings):
latent_vectors = []
classes = []
for im,clss in val_dl:
latent_vectors.append(model.encoder(im))
classes.extend(clss)
latent_vectors = torch.cat(latent_vectors).cpu().detach().numpy().reshape(10000, -1)
(2) 计算数据集中所有潜变量在每列上的均值均值 (mu) 和标准差 (sigma),并使用均值和标准创建随机潜变量,并将得到的随机潜变量保存在列表中 (rand_vectors):
rand_vectors = []
for col in latent_vectors.transpose(1,0):
mu, sigma = col.mean(), col.std()
rand_vectors.append(sigma*torch.randn(1,100) + mu)
(3) 绘制根据随机潜变量和训练后的自编码器模型重建的图像:
rand_vectors = torch.cat(rand_vectors).transpose(1,0).to(device)
ix = 1
for p in rand_vectors:
img = model.decoder(p.reshape(1,64,2,2)).view(28,28)
plt.subplot(10, 10, ix)
plt.imshow(img.detach().cpu(), cmap='gray')
ix += 1
plt.show()

从以上输出中可以看出,使用添加了噪声的潜变量生成图像时,得到的图像较为模糊。这是一个在实际场景中的常见问题,因为我们无法事先了解真实图片的潜变量范围。变分自编码器 (Variational Auto-Encoders, VAE) 通过生成均值为 0、标准差为 1 的向量来解决此问题。
本质上,在 VAE 中指定了瓶颈层应当遵循的分布。接下来,我们将介绍 VAE 的工作原理,并介绍 KL 散度 (Kullback–Leibler divergence) 损失用于获取遵循特定分布的潜变量。
1.2 VAE 工作原理
VAE 使用深度学习构建概率模型,将输入数据映射到一个低维度的潜空间中,并通过解码器将潜空间中的分布转换回数据空间中,以生成与原始数据相似的数据。与传统的自编码器相比,VAE 更加稳定,生成样本的质量更高。
VAE 的核心思想是利用概率模型来描述高维的输入数据,将输入数据采样于一个低维度的潜变量分布中,并通过解码器生成与原始数据相似的输出。具体来说,VAE 同样是由编码器和解码器组成:
- 编码器将数据 x x x 映射到一个潜在空间 z z z 中,该空间定义在低维正态分布中,即 z ∼ N ( 0 , I ) z∼N(0,I) z∼N(0,I),编码器由两个部分组成:一是将数据映射到均值和方差,即 z ∼ N ( μ , σ 2 ) z∼N(μ,σ^2) z∼N(μ,σ2);二是通过重参数化技巧,将均值和方差的采样过程分离出来,并引入随机变量 ϵ ∼ N ( 0 , I ) ϵ∼N(0,I) ϵ∼N(0,I),使得 z = μ + ϵ σ z=μ+ϵσ z=μ+ϵσ
- 解码器将潜在变量 z z z 映射回数据空间中,生成与原始数据 x x x 相似的数据 x ′ x′ x′,为了使生成的数据 x ′ x′ x′ 能够与原始数据 x x x 较高的相似度,
VAE在损失函数中使用重构误差和正则化项,重构误差表示生成数据与原始数据之间的差异,正则化项用于约束潜在变量的分布,使其满足高斯正态分布,使得VAE从潜空间中生成的样本质量更高
VAE 具有广泛的应用场景,如图像生成、语音、自然语言处理等领域,它能够通过有限的数据样本学习到输入数据背后的潜在规律,生成与原始数据类似的新数据,具有很强的潜数据的可解释性。
1.3 VAE 构建策略
在 VAE 中,基于预定义分布获得的随机向量生成逼真图像,而在传统自编码器中并未指定在网络中生成图像的数据分布。可以通过以下策略,实现 VAE:
- 编码器的输出包括两个向量:
- 输入图像平均值
- 输入图像标准差
- 根据以上两个向量,通过在均值和标准差之和中引入随机变量 ( ϵ ∼ N ( 0 , I ) ϵ∼N(0,I) ϵ∼N(0,I)) 获取随机向量 ( z = μ + ϵ σ z=μ+ϵσ z=μ+ϵσ)
- 将上一步得到的随机向量作为输入传递给解码器以重构图像
- 损失函数是均方误差和 KL 散度损失的组合:
KL散度损失衡量由均值向量 μ \mu μ 和标准差向量 σ \sigma σ 构建的分布与 N ( 0 , I ) N(0,I) N(0,I) 分布的偏差- 均方损失用于优化重建(解码)图像
通过训练网络,指定输入数据满足由均值向量 μ \mu μ 和标准差向量 σ \sigma σ 构建的 N ( 0 , 1 ) N(0,1) N(0,1) 分布,当我们生成均值为 0 且标准差为 1 的随机噪声时,解码器将能够生成逼真的图像。
需要注意的是,如果只最小化 KL 散度,编码器将预测均值向量为 0,标准差为 1。因此,需要同时最小化 KL 散度损失和均方损失。在下一节中,让我们介绍 KL 散度,以便将其纳入模型的损失值计算中。
1.4 KL 散度
KL 散度(也称相对熵)可以用于衡量两个概率分布之间的差异:
K L ( P ∣ ∣ Q ) = ∑ x ∈ X P ( x ) l n ( P ( i ) Q ( i ) ) KL(P||Q) = \sum_{x∈X} P(x) ln(\frac {P(i)}{Q(i)}) KL(P∣∣Q)=x∈X∑P(x)ln(Q(i)P(i))
其中, P P P 和 Q Q Q 为两个概率分布,KL 散度的值越小,两个分布的相似性就越高,当且仅当 P P P 和 Q Q Q 两个概率分布完全相同时,KL 散度等于 0。在 VAE 中,我们希望瓶颈特征值遵循平均值为 0 和标准差为 1 的正态分布。因此,我们可以使用 KL 散度衡量变分自编码器中编码器输出的分布与标准高斯分布 N ( 0 , 1 ) N(0,1) N(0,1) 之间的差异。
可以通过以下公式计算 KL 散度损失:
∑ i = 1 n σ i 2 + μ i 2 − l o g ∗ ( σ i ) − 1 \sum_{i=1}^n\sigma_i^2+\mu_i^2-log*(\sigma_i)-1 i=1∑nσi2+μi2−log∗(σi)−1
在上式中, σ σ σ 和 μ μ μ 表示每个输入图像的均值和标准差值:
- 确保均值向量分布在
0附近:- 最小化上式中的均方误差 ( μ i 2 \mu_i^2 μi2) 可确保 μ \mu μ 尽可能接近
0
- 最小化上式中的均方误差 ( μ i 2 \mu_i^2 μi2) 可确保 μ \mu μ 尽可能接近
- 确保标准差向量分布在
1附近:- 上式中其余部分(除了 μ i 2 \mu_i^2 μi2 )用于确保标准差 ( s i g m a sigma sigma) 分布在
1附近
- 上式中其余部分(除了 μ i 2 \mu_i^2 μi2 )用于确保标准差 ( s i g m a sigma sigma) 分布在
当均值 ( μ μ μ) 为 0 且标准差为 1 时,以上损失函数值达到最小,通过引入标准差的对数,确保 σ \sigma σ 值不为负。通过最小化以上损失可以确保编码器输出遵循预定义分布。
1.5 重参数化技巧
下图左侧显示了 VAE 网络。编码器获取输入 x x x,并估计潜矢量 z z z 的多元高斯分布的均值 μ μ μ 和标准差 σ σ σ,解码器从潜矢量 z z z 采样,以将输入重构为 x x x:

但是反向传播梯度不会通过随机采样块。虽然可以为神经网络提供随机输入,但梯度不可能穿过随机层。解决此问题的方法是将“采样”过程作为输入,如图右侧所示。 采样计算为:
S a m p l e = μ + ε σ Sample=\mu + εσ Sample=μ+εσ
如果 ε ε ε 和 σ σ σ 以矢量形式表示,则 ε σ εσ εσ 是逐元素乘法,使用上式,令采样好像直接来自于潜空间。 这种技术被称为重参数化技巧 (Reparameterization trick)。
2. 构建 VAE
在本节中,使用 PyTorch 实现 VAE 模型生成手写数字图像。
(1) 由于使用与训练自编码器模型相同的数据集,因此数据集的加载和构建方式与全连接自编码器完全相同:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import make_grid
import numpy as np
from matplotlib import pyplot as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'
train_dataset = datasets.MNIST(root='MNIST/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='MNIST/', train=False, transform=transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
(2) 定义神经网络类 VAE。
在 __init__ 方法中定义所需网络层:
class VAE(nn.Module):
def __init__(self, x_dim, h_dim1, h_dim2, z_dim):
super(VAE, self).__init__()
self.d1 = nn.Linear(x_dim, h_dim1)
self.d2 = nn.Linear(h_dim1, h_dim2)
self.d31 = nn.Linear(h_dim2, z_dim)
self.d32 = nn.Linear(h_dim2, z_dim)
self.d4 = nn.Linear(z_dim, h_dim2)
self.d5 = nn.Linear(h_dim2, h_dim1)
self.d6 = nn.Linear(h_dim1, x_dim)
d1 和 d2 层对应于编码器部分,d5 和 d6 层将对应于解码器部分,d31 和 d32 层分别用于获取均值和标准差向量,为了方便计算,使用 d32 层获取方差向量的对数表示。
定义编码器方法 encoder:
def encoder(self, x):
h = F.relu(self.d1(x))
h = F.relu(self.d2(h))
return self.d31(h), self.d32(h)
编码器返回两个向量:均值 self.d31(h) 和方差值的对数 self.d32(h)。
定义从编码器输出中采样 (sampling) 的方法:
def sampling(self, mean, log_var):
std = torch.exp(0.5*log_var)
eps = torch.randn_like(std)
return eps.mul(std).add_(mean)
计算 torch.exp(0.5*log_var)) 获取标准差 std,此外,通过添加随机噪声(标准差乘以满足正态分布的随机数)获取随机向量,确保即使编码器向量发生了微小变化,也可以生成高质量图像。
定义解码器方法 decoder:
def decoder(self, z):
h = F.relu(self.d4(z))
h = F.relu(self.d5(h))
return torch.sigmoid(self.d6(h))
定义前向计算方法 forward:
def forward(self, x):
mean, log_var = self.encoder(x.view(-1, 784))
z = self.sampling(mean, log_var)
return self.decoder(z), mean, log_var
在以上方法中,确保编码器返回均值和方差值的对数,对均值与 epsilon 乘以方差的对数之和进行采样,并在通过解码器后返回结果。
(3) 定义模型在批数据上进行训练和验证的函数:
def train_batch(data, model, optimizer, loss_function):
model.train()
data = data.to(device)
optimizer.zero_grad()
recon_batch, mean, log_var = model(data)
loss, mse, kld = loss_function(recon_batch, data, mean, log_var)
loss.backward()
optimizer.step()
return loss, mse, kld, log_var.mean(), mean.mean()
@torch.no_grad()
def validate_batch(data, model, loss_function):
model.eval()
data = data.to(device)
recon, mean, log_var = model(data)
loss, mse, kld = loss_function(recon, data, mean, log_var)
return loss, mse, kld, log_var.mean(), mean.mean()
(4) 定义损失函数:
def loss_function(recon_x, x, mean, log_var):
RECON = F.mse_loss(recon_x, x.view(-1, 784), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mean.pow(2) - log_var.exp())
return RECON + KLD, RECON, KLD
在以上代码中,获取原始图像 x 和重建图像 recon_x 之间的 MSE 损失 RECON,并计算了 KL 散度损失 KLD。
(5) 定义模型对象 vae 和优化器函数:
vae = VAE(x_dim=784, h_dim1=512, h_dim2=256, z_dim=50).to(device)
optimizer = optim.AdamW(vae.parameters(), lr=1e-3)
(6) 训练模型:
n_epochs = 20
train_loss_epochs = []
val_loss_epochs = []
for epoch in range(n_epochs):
N = len(train_loader)
trn_loss = []
val_loss = []
for batch_idx, (data, _) in enumerate(train_loader):
loss, recon, kld, log_var, mean = train_batch(data, vae, optimizer, loss_function)
pos = (epoch + (batch_idx+1)/N)
trn_loss.append(loss.item())
train_loss_epochs.append(np.average(trn_loss))
N = len(test_loader)
for batch_idx, (data, _) in enumerate(test_loader):
loss, recon, kld, log_var, mean = validate_batch(data, vae, loss_function)
pos = epoch + (1+batch_idx)/N
val_loss.append(loss.item())
val_loss_epochs.append(np.average(val_loss))
with torch.no_grad():
z = torch.randn(64, 50).to(device)
sample = vae.decoder(z).to(device)
images = make_grid(sample.view(64, 1, 28, 28)).permute(1,2,0)
plt.imshow(images.detach().cpu(), cmap='gray')
plt.show()
# show(images)
epochs = np.arange(n_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()
VAE 首先生成一个随机向量 z 并将其传递给解码器 vae.decoder 以获取图像样本,make_grid 函数用于绘制图像。损失值变化的情况和生成的图像样本如下所示:
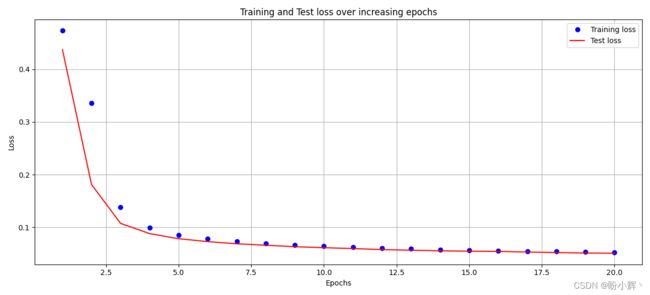

可以看到,VAE 模型能够生成原始图像中不存在的逼真的新图像。
小结
变分自编码器是一种结合了自编码器和概率建模的生成模型,通过编码器将输入数据映射到潜在空间中的概率分布,并通过解码器将从潜在空间采样得到的潜在变量映射回原始数据空间,实现了数据的生成和特征学习。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(25)——自编码器(Autoencoder)
PyTorch深度学习实战(26)——卷积自编码器(Convolutional Autoencoder)