软件体系结构
名词解释
- Zoo keeper:
是一个分布式的,开放源码的分布式应用程序协调服务,是Google的一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
- Giraph:
是一个迭代的图计算系统。Giraph计算的输入是由点和直连的边组成的图。图形(Graph)是大数据领域最热门的关键词。
- Hive:
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- Hbase:
HBase 是基于Hadoop 的面向列的 NoSQL 数据库,是 Google 的 BigTable 的开源实现。HBase 是一个针对半结构化数据的开源的、多版本的、可伸缩的、高可靠的、高性能的、分布式的和面向列的动态模式数据库。
- Pig:
是一种数据流语言和运行环境,用于检索非常大的数据集。为大型数据集的处理提供了一个更高层次的抽象。
- Hadoop:
Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算
- Mahout:
Mahout是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
- MapReduce:
MapReduce 是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由大规模通用服务器组成的大型集群上,并以一种可靠容错的方式并行处理 TB 级别的数据集。
- Redis:
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
- HDFS:
HDFS ( Hadoop Distributed File System)即 Hadoop 分布式文件系统,它的设计目标是把超大数据集存储到集群中的多台普通商用计算机上,并提供高可靠性和高吞吐量的服务。
- SGL:
Scatter/Gather List 将一份数据分布在物理内存碎片的基地址 ,记录在这样一份清单上,并把这份清单和清单的基地址告诉I/O控制器,以此加快I/O控制器取数据的速度。
- Libc:
是符合ANSI C标准的一个函数库。libc库提供C语言中所使用的宏,类型定义,字符串操作函数,数学计算函数以及输入输出函数等。
- SSL:
SSL(Secure Sockets Layer 安全套接字协议),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。
- Webkit:
WebKit是一个开源的浏览器网页排版引擎,包含WebCore排版引擎和JSCore引擎。
- SQLite:
是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。
简答题:
- 云平台体系架构7个组成
- 融合基础设施 2.服务编排(接入规范) 3.应用模板设计,自动部署
4.服务管理和质量保证 5.应用监控,服务保证
6.云服务目录 7.云门户
- Windows内核模式和用户模式4个组成
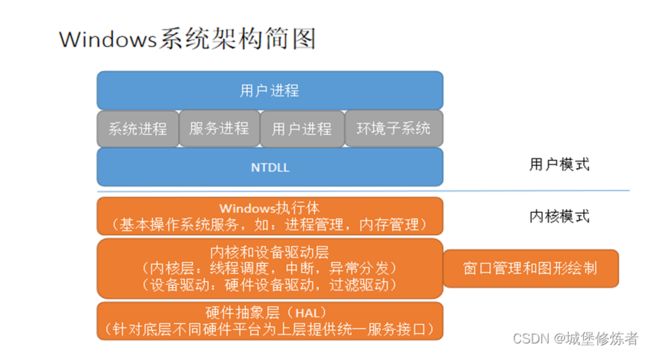
- 4个进程
系统进程(
Idle进程 System进程
会话管理器 本地会话管理器
会话初始化 登录进程
服务控制管理器 本地安全认证服务器),服务进程,用户进程,环境子系统
- 设备驱动的6个驱动程序
- 硬件设备驱动程序
- 文件系统驱动程序
- 文件系统过滤驱动程序
- 网络重定向器和服务器
- 协议驱动程序
- 内核流式驱动程序
- Windows执行体10个组件
1.配置管理器—注册
2.进程和线程管理器——创建和撤消
3.安全应用监视器——安全策略
4.I/O管理器——设备无关的I/O
5.即插即用(pnp)管理器——确定驱动,加载驱动。
6.电源管理器——降低电源电耗。
7.WDM Windows管理规范例程——接受来自用户的WMI服务命令。
8.高速缓存管理器——I/O操作的性能
9.内存管理器——虚拟内存
10.逻辑预取器——加速系统和进程启动过程
- 微信成功的10个设计原则
1. 创意
2. 有用
3. 优美
4. 容易使用
5. 含蓄不张扬
6. 诚实
7. 经久不衰
8. 不放过任何细节
9. 环保不浪费
10. 少即是多
- Oracle体系结构的6大文件
数据文件、数据控制文件、联机重做日志文件。
而归档日志文件、初始化参数文件和用户口令文件存放在数据库外。
- 四大缓存及作用
(一个缓存三个高速缓存)
①数据字典缓存:描述库中的表的信息、位置,提高命中率。
②库高速缓存:相同的SQL不再编译,LRU算法
③数据高速缓存:避免重复读取常用数据
④重做日志高速缓存:提升数据增删,减少读写
其中数据字典缓存和库高速缓存在共享池中。
大数据商业建模技术的三个大层和7个小层:

- 组件按作用分类5个
①负责系统运行管理的控制组件
②负责组件之间协作关系的协调组件
③为其它组件提供服务功能的服务组件
④负责安全检查和信息转接的信息控制组件
⑤负责组件连接和转换功能的连接组件
- 组件的五个特性
- 接口特性——与其它组件通信
- 运行特性——完成组件的功能
- 远程服务特性——多线程
- 关联特性——获取相关组件的地址信息
- 动态特性
- 连接器5个连接机制(5个连接特性)
1. 连接的方向性,如:发送、接收
2. 连接的角色,如发送者,接收者,客户端,服务器
3. 连接的触发,如电话提机,鼠标操作
4. 连接的响应,被叫方的响应时间、方式、处理的实时性、并发的能力等。
5. 连接的层次,连接是严格接层次进行的,如OSI模型
- 网站架构变迁的十个特点
- 初始阶段的网站架构
- 应用服务和数据服务分离
- 使用缓存改善网站性能
- 使用应用服务器集群改善网站的并发处理能力
- 数据库读写分离
- 使用反向代理和CDN加速网站响应
- 使用分布式文件系统和分布式数据库系统
- 使用NoSQL和搜索引擎
- 业务拆分
- 分布式服务
- 智慧城市6个层
行业应用层、应用服务层、支撑服务层、数据活化层、数据传输层、城市感知层
软件体系结构(SA)是一个三元组:
SA={ 组件,形式, 准则 }
组件是结构的实体,包括处理组件、数据组件和连接组件。
形式用于描述构成结构的实体,包括连接元素,是专有的特性和关系。
准则是组件组合的“生成”规则。
详细回答:
敏捷的四大法器:
1) 大系统小做:当设计庞大系统的时候,应该尽量分割成更小的颗粒,使得项目之间的影响是最小的。
2) 一切可扩展:在高稳定度、高性能的系统中间,为了稳定性能把它设计成不变化的系统,但为了支持敏捷需要让一切的东西都要变得可以扩展。
3) 必须建立基础组件:要解决复杂问题的时候,需要将已有的经验固化下来,固化下来的东西会成为系统中的一部分。
4) 轻松上线:当做了变化并把它从开发环境中部署到现有的运营环境中去,在这个过程中,“灰度”这个词非常关键,就是在黑和白之间的选择,必须要变成一种小规模尝试,再逐步扩展到海量过程中的一个问题。
- 微信架构四个要点
①协议: 移动终端跟后台服务器之间的交互协议,这个协议的设计是整个系统的骨架,在这一点做好设计可以使得系统的复杂度大大降低。
②容灾: 当系统出现了若干服务器或若干支架宕机的时候,仍然需要让系统尽可能的提供正常的服务。
③轻重: (前端轻、后端重,如何快呢?)如何在系统架构中分布功能,在哪一个点实现哪一个功能,代表系统中间的功能配置。把关键的点从终端移到后台实现,把功能点后移,来充分发挥后台快速变更的能力。
④监控: 智能处理和为系统提供一个智能仪表盘。
- 组件六大实现形式
1.最简单的组件是基本的位、字节数、整数、实数、数组、队列等等,这类组件没有行为能力,只是表达数据;
2.有行为能力的组件是各类的对象,因此,组件的实现形式就是对象,如用于界面设计的可视控件、输入/输出组件、OLE对象、DCOM/CORBA组件等;
3.组件软化的硬件层有:时钟、中断控制、存储器管理、堆栈管 理、I/O控制等;
4.在基础控制描述层有:数组、结构、树、文件、对象、状态、函数库/包,模块等;
5.在资源及管理调度层:注册表、DLL、ODBC、菜单、表单等;
6.在系统结构模式层有:生成规则、黑板、域名服务、路由服务、浏览器、解释器、设计模式、框架等。
- 连接的两个要素
连接机制——硬件是连接的物质基础
硬件层:中断、存储、栈、I/O、DMA等;
基础控制描述层:事件、流、文件等;
资源和管理层:进程、线程、同步、并发、消息、远程调用;
系统结构模式层:编译器、解释器、浏览器、中间件等。
连接协议——信息交换规则
什么是协议?
一种成文的公约集,相互通信系统间的信息交换格式、能被收/发双方接受的传送信息内容的一组定义 。
连接之所在,协议亦所在
- 连接器不匹配4个解决方案
①修改组件——全面改变组件A,使之符合B的要求;使A或B成为支持多实现机制的组件,其中一种机制能符合对方;将A中的数据转换成B能识别的,并从A中传送到B中;
②引入中间件——直接引入转换器;在外部建立信息交换表示;发布信息交换通用标准。
③采用握手技术——在经常变动的系统中,识别和确定对方
④进行包装——代理技术等。
- Spring架构的七个组成部分
1.核心容器
是Spring框架最基础的部分,它提供了依赖注入(Dependency Injection)特征来实现容器对Bean的管理。这里最基本的概念是BeanFactory,它是任何Spring应用的核心。BeanFactory是工厂模式的一个实现,它使用IoC将应用配置和依赖说明从实际的应用代码中分离出来。
2.应用上下文(Context)模块
核心模块的BeanFactory使Spring成为一个容器,而上下文模块使它成为一个框架。这个模块扩展了BeanFactory的概念,增加了对国际化(I18N)消息、事件传播以及验证的支持。
这个模块提供了许多企业服务,例如电子邮件、JNDI访问、EJB集成、远程以及时序调度(scheduling)服务。
3.Spring的AOP模块
- Spring在它的AOP模块中提供了对面向切面编程的丰富支持。这个模块是在Spring应用中实现切面编程的基础。
- 为了确保Spring与其它AOP框架的互用性,Spring的AOP支持基于AOP联盟定义的API。
- AOP联盟是一个开源项目,它的目标是通过定义一组共同的接口和组件来促进AOP的使用以及不同的AOP实现之间的互用性。
- Spring的AOP模块也将元数据编程引入了Spring。使用Spring的元数据支持,可以为源代码增加注释,指示Spring在何处以及如何应用切面函数。
4.JDBC抽象和DAO模块
- 使用JDBC经常导致大量的重复代码,取得连接、创建语句、处理结果集,然后关闭连接。
- Spring的JDBC和DAO模块抽取了这些重复代码,因此,可以保持你的数据库访问代码干净简洁,并且可以防止因关闭数据库资源失败而引起的问题。
- 这个模块还在几种数据库服务器给出的错误消息之上建立了一个有意义的异常层,使你不用再试图破译神秘的私有的SQL错误消息!
- 这个模块使用了Spring的AOP模块为Spring应用中的对象提供了事务管理服务。
5.对象/关系映射集成模块
Spring提供了ORM模块。Spring并不试图实现它自己的ORM解决方案,而是为几种流行的ORM框架提供了集成方案,包括Hibernate、JDO和iBATIS SQL映射。
Spring的事务管理支持这些ORM框架中的每一个,也包括JDBC。
6.Spring的Web模块
提供了一个适合于Web应用的上下文。
这个模块还提供了一些面向服务支持。例如:实现文件上传的multipart请求,它也提供了Spring和其它Web框架的集成,比如Struts、WebWork。
7.Spring的MVC框架
Spring为构建Web应用提供了一个功能全面的MVC框架。虽然Spring可以很容易地与其它MVC框架集成,例如Struts,但Spring的MVC框架使用IoC对控制逻辑和业务对象提供了完全的分离。
它也允许你声明性地将请求参数绑定到你的业务对象中,此外,Spring的MVC框架还可以利用Spring的任何其它服务,例如国际化信息与验证。