理解JIT(读书之Java性能优化实践 第10章)
10.理解JIT
JIT Just-In-Time
10.1 认识JITWatch
10.1.1 JITWatch 介绍
• 是一款开源JavaFX工具
• 由 Chris Newland (也是本书作者之一)开发。
• 目前由 AdoptOpenJDK 托管
任何要分析的方法都必须在热路径中使用(Hot Path),并且有资格被编译,被解释的方法不适合作为被优化的目标。
JITWatch 通过解析HotSpot的详细编译日志,以在JavaFX上图形化上显示
日志开启方式
-XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+LogCompilation
其主界面如下:
提供了沙箱(sandbox)环境,用于实验JIT行为,功能包括:
1. 输出反汇编原生方法
2. 覆盖JVM默认的分层编译
3. 禁用压缩指针
4. 禁用栈上替换
5. 覆盖内联的默认限制
10.1.2 调试JVM和hdsdi
让虚拟机输出方法的汇编代码
-XX:+PrintAssembly
10.2 介绍 JIT
1. 系统会设置一些计数器,来保持热度,这些热度在剖析过程中衰减,当再次到编译头部时,如果有足够热度才会被编译;
2. 确定编译后,会为代码构建内部表示,并进一步确定使用哪个编译器(C1 or C2) 进行优化;
主要的优化技术:
• 内联
• 循环展开
• 逃逸分析
• 锁消除和锁合并
• 单态分发
• 内部函数
• 栈上替换
C1 和 C2 使用了其不同的子集。
C1 不会进行推测性优化(speculative optimization)
C2 会进行推测性优化,并有可能带来较大的性能提升。
推测性优化 使用对执行特性的未经证实的假设进行优化。
推测性优化采用健全性检查(sanity check)来保证假设的正确,即守卫
守卫来确保假设成立,如果守卫失效,HotSpot会停止优化(deoptimization),并将该方法降级回解释模式
10.3 内联(inline)
内联 也叫网关优化(gateway optimization),选择某个被调用方法(callee),将莫奈彩 内容复制到被调用处,即调用点中。
去掉的开销
1. 设置参数
2. 查找调用的精确方法
3. 为新的调用栈帧创建调用时运行结构
4. 将控制转移到新方法
5. 可能需要的结果返回
10.3.1 内联的限制
限制的方面:
1. JIT优化所需时间
2. 原生代码块的大小
决定内联的因素:
1. 内联方法的字节码大小
2. 内联方法在当前调用链的深度
3. 该方法编译版本在代码缓存中已占的空间量
内联子系统的调优参数
| JVM参数 | 默认值 (JDK 8, Linux x86_64) | Explanation |
| -XX:MaxInlineSize= |
35 字节码 | 内联方法大小上限 |
| -XX:FreqInlineSize= |
325 字节码 | Inline “hot” (frequently called) methods up to this size. 内联热方法的最大值 |
| -XX:InlineSmallCode= |
1,000 bytes of native code (non-tiered) 2,000 bytes of native code (tiered) 1000字节的原生代码(非分层) 2000字节的原生代码(分层编译) |
Do not inline methods where there is already a final-tier compilation that occupies more than this amount of space in the code cache. 如果最后一层的的分层编译代码量已经超过这个值,就不进行内联编译 |
| -XX:MaxInlineLevel= |
9 | Do not inline call frames deeper than this level. 调用层级比这个深的话就不进行内联。 |
对内联进行调优基本上会从FreqInlineSize和MaxInlineSize上入手。
拐言: 在框架中怎么计算调用深度?
10.4 循环展开(Loop Unrolling)
当循环体内的方法被内联以后,编译器可以了解每次循环迭代的大小和成本,以决定是否进行循环展开(unroolling the loop)
拐言: 循环展开的本质是拿空间换时间
是否进行循环展开的因素:
1. 计数器变量类型(int 或 long)
2. 循环步长(每次迭代时计数器如何改变)
3. 循环内出口点数量(return / break )
拐言:书上有一个对数组操作进行的性能测试,比较好理解,此处略去,毕竟阅读量和字数无关
HotSpot针对循环展开的优化:
1. 使用int/short/char类型作为循环计数器
2. 展开循环体,并移除安全点轮询
3. 可以减少向向后分支预测的数量,也就减少相关分支预测的成本
拐言: CPU,这里应该为JVM,在执行相关的指令块时,会跟据情况把之后指令块读进来,比如,现在执行代码块A,A的下一块是B,但是中间有跳转到C,那么B和C这两块代码都会预先读进来,这种预读的机制,可以简单理解为分支预测,那么循环展开后,因为向后跳转少了,所以说减少了分支预测的成本。
4. 移除安全点可以进一步减少每次循环要完成的工作。
安全点可以参考第7章的内容
10.5 逃逸分析(Escape Analysis)
逃逸分析技术用来确定方法内的对象在方法外是否可见。
当内联发生后,系统会尝试进行逃逸分析。
JVM中对可能逃逸的情况进行的分类
typedef enum {
NoEscape = 1, // An object does not escape method or thread and it is
// not passed to call. It could be replaced with scalar.
// 不会逃逸出方法和线程,也不会被传参,所以可以被标量替换
ArgEscape = 2, // An object does not escape method or thread but it is
// passed as argument to call or referenced by argument
// and it does not escape during call.
// 不会逃逸出方法和线程,但会作为调用传参,在调用期间不会逃逸
GlobalEscape = 3 // An object escapes the method or thread.
// 会逃逸出方法或线程
}逃逸分析的目的----可以让开发人员写出符合习惯的代码,而不须担心对象分配率。
10.5.1 消除堆分配
如果一个对象被判断了不会逃逸出方法和线程,也不会被传参,那么可以对其进行标量替换。
标量替换 对象中的字段会变成标量值,类似于局部变量,然后被寄存器分配器(register allocator)(HotSpot组件) 分配到CPU寄存器中。
如果没有足够的寄存器,会被分配到当前栈帧上,这种情况称为栈溢出(stack spill)
例
下面这段里,foo 为 NoEscape 可以进行标量替换
public long noEscape() {
long sum = 0;
for (int i = 0; i < 1_000_000; i++) {
MyObj foo = new MyObj(i); // foo does not escape the method (NoEscape)
sum += foo.bar();
}
return sum;
}而这段代码中,如果 extBar可以被内联,那么foo就会从ArgEscape变为NoEscape
public long argEscape() {
long sum = 0;
for (int i = 0; i < 1_000_000; i++) {
MyObj foo = new MyObj(i);
sum += extBar(foo); // foo is passed as an argument to extBar (ArgEscape)
}
return sum;
}因此,内联是循环展开和逃逸分析的一个基础工作
10.5.2 锁与逃逸分析
以下优化仅适用于内置锁,即synchronized,不适用于java.util.concurrent锁
可用的锁优化:
1. 移除不逃逸的对象上的锁(锁消除,lock elision)
2. 合并使用同一把锁的连续锁定区域(锁合并,lock coarsening)
3. 检测重复获取同一把锁但是没有解锁的地方(锁嵌套,nested lock)
拐言,谁TMD写程序会占上这三条啊???不如改行砍甘蔗算了
相关JVM参数
| JVM参数 | 作用 |
| -XX:-EliminateLocks | 关掉锁合并优化 |
| -XX:-EliminateNestedLocks | 关掉锁嵌套优化 |
10.5.3 逃逸分析的限制
• 超过64个元素的不会从逃逸分析中受益(占用栈帧空间)
配置开关
-XX:EliminateAllocationArraySizeLimit=
• HotSpot不支持部分逃逸分析
代码级的优化以利用逃逸分析
优化前:
for (int i = 0; i < 100_000_000; i++) {
Object mightEscape = new Object(i);
if (condition) {
result += inlineableMethod(mightEscape);
} else {
result += tooBigToInline(mightEscape);
}
}优化后:
for (int i = 0; i < 100_000_000; i++) {
if (condition) {
Object mightEscape = new Object(i);
result += inlineableMethod(mightEscape);
} else {
Object mightEscape = new Object(i);
result += tooBigToInline(mightEscape);
}
}10.6 单态分派(Monomorphic Dispatch)
依赖于一个观测事实:
在任何一个单独的调用点上通常只观察到一种运行时类型或是接收时对象的类型
即,当我们在对象上调用一个方法时,如果第一次检查该对象的运行时类型,那么很可能以后检查都是相同的结果.
在这个假设成立的情况下,可以用快速类型测试(守卫)代替invokevirtual指令,之后跳转到编译后的方法体
即 用klass指针和vtable进行的方法查找操作只进行一次,然后缓存结果以供再次调用。
双态分派(Bimorphic Dispatch)
即为一个调用点缓存两个klass
即不是单态也不是双态的状态称为复态(mergamorphic)
在极端情况下,可以通过剥离调用点来获得性能提升,即用instanceof从原始点进行剥离,最后剩下双态或单态的调用。
拐言: instanceof 的开销???
代码实现&&性能测试
package optjava.jmh;
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
interface Shape {
int getSides();
}
class Triangle implements Shape {
public int getSides() {
return 3;
}
}
class Square implements Shape {
public int getSides() {
return 4;
}
}
class Octagon implements Shape {
public int getSides() {
return 8;
}
}
@OutputTimeUnit(TimeUnit.SECONDS)
public class PeelMegamorphicCallsite {
private java.util.Random random = new java.util.Random();
private Shape triangle = new Triangle();
private Shape square = new Square();
private Shape octagon = new Octagon();
@Benchmark
public int runBimorphic() {
Shape currentShape = null;
switch (random.nextInt(2))
{
case 0:
currentShape = triangle;
break;
case 1:
currentShape = square;
break;
}
return currentShape.getSides();
}
@Benchmark
public int runMegamorphic() {
Shape currentShape = null;
switch (random.nextInt(3))
{
case 0:
currentShape = triangle;
break;
case 1:
currentShape = square;
break;
case 2:
currentShape = octagon;
break;
}
return currentShape.getSides();
}
@Benchmark
public int runPeeledMegamorphic() {
Shape currentShape = null;
switch (random.nextInt(3))
{
case 0:
currentShape = triangle;
break;
case 1:
currentShape = square;
break;
case 2:
currentShape = octagon;
break;
}
// 利用单态分配
if (currentShape instanceof Triangle) {
return ((Triangle) currentShape).getSides();
}
else {
return currentShape.getSides(); // 这种情况只有双态分配了
}
}
}输出结果如下:
Benchmark Mode Cnt Score Error Units
PeelMega...Callsite.runBimorphic thrpt 200 75844310 ± 43557 ops/s
PeelMega...Callsite.runMegamorphic thrpt 200 54650385 ± 91283 ops/s
PeelMega...Callsite.runPeeledMegamorphic thrpt 200 62021478 ± 150092 ops/s10.7 内部函数(intrinsic)
内部函数指的是一个高度优化的原生实现。
由JVM事先知道,而非JIT生成。
其功能用操作系统或CPU来提供支持。
例:一些内部函数
java.lang.System.arraycopy()
java.lang.System.currentTimeMillis()
java.lang.Math.min()内部函数可以在openJDK源码中看到,以
.ad为结尾的文件。
Java 9 引入了注解
@HotSpotIntrinsicCandidate用以说明一个函数在一些情况下可以为内部函数。
10.8 栈上替换(On-Stack Replacement)
一些情况下,会有函数本身调用很少,但是其自身包含了应该优化的热循环(HotLoop)
比如含有循环的main()方法。
在这种情况下,HotSpot会用一种叫栈上替换(On-Stack Replacement,OSR)的技术对其进行优化。
即会计算循环中向后跳转的次数,当其达到某个阈值时,这个循环会被编译,并将其执行切换到这个编译的版本。
编译器会要保证编译版本可以使用任何状态的更改,当编译的循环退出时,所有的状态更改必须在继续执行的位置可见。
向后分支,即为循环体执行到结尾后如果条件没有满足,分支会跑回到循环的起点。
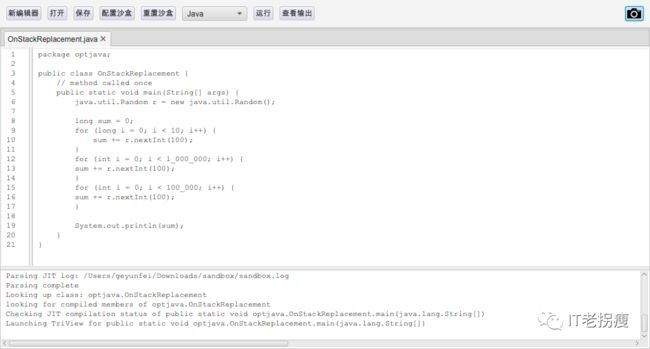
示范代码
public class OnStackReplacement {
// method called once
public static void main(String[] args) {
java.util.Random r = new java.util.Random();
long sum = 0;
for (int i = 0; i < 10; i++) {
sum += r.nextInt(100);
}
for (int i = 0; i < 1_000_000; i++) {
sum += r.nextInt(100);
}
for (int i = 0; i < 100_000; i++) {
sum += r.nextInt(100);
}
System.out.println(sum);
}
}运行效果

拐言,此处代码与书上的略有区别
可以看出JVM对第三个循环进行了栈上替换(红色部分),虽然并不是循环次数最多的一个。
同时,进行了几次实验,发现OSR似乎只会优化一个循环。
10.9 再谈安全点
除了GC STW事件以外,以下事件也处于安全点:
• 取消一个对方法的优化
• 创建堆转储
• 撤销偏向锁
• 重定义一个类
拐言: 其实了解了安全点定义和JVM执行后,这几个点为安全点都是显而易见的 :)
在编译后的代码中,JIT编译器负责生成安全点检查代码。
会在循环的向后分支及方法返回处,生成相应的安全点。
如果代码被JIT优化,如内联或循环展开,则可能需要相当长一段时间才能到达安全点。
安全点多了,轮询检查的成本就高,安全点少了,线程就要等待较长时间才能到达。
所以编译器会在二者之间达到一个平衡。
只要保证程序语义不变,JIT可以生成预测性和乱序的指令,当到达安全点时,编译代码的状态与程序在的状态应该是一致的。
安全点相关虚拟机开关
| 开关 | 作用 |
-XX:+PrintGCApplicationStoppedTime |
查看程序到达安全点的总时间 |
-XX:+PrintSafepointStatistics |
输出更多的关于安全点信息 |
10.10 核心库方法
10.10.1 内联方法的大小上限
• 内联决策根据字节码大小做出
• 可以通过对类文件进行静态分析来识别对内联讲是太大的方法
用JarScan可以识别大小超过给给定值的所有方法
JarScan也是JITWatch的一部分
./jarScan.sh --mode=maxMethodSize \
--limit=325 \
--packages=java.* \
/path/to/java/jre/lib/rt.jar• 一些与本地化有关的方法因为考虑的情况(不同地区)过多,因此其字节码比较大。比如
toUpperCase()和toLowerCase()• 极端情况下,可以自己重写这些方法,来达到使用内联优化的目的。
内联是否可能有多级嵌套的情况???
10.10.2 编译方法的大小上限
如果方法的字节码大小超过8000,则该方法不能内联。
在生产级JVM,这个值不可以改变
如果是调试版JVM,可以通过-XX:HugeMethodLimit=来调整。
参考
• JITWatch GitHub: https://github.com/AdoptOpenJDK/jitwatch
• JarScan.sh GitHub: https://github.com/AdoptOpenJDK/jitwatch/tree/master/scripts
• JIT的Profile神器JITWatch https://www.cnblogs.com/flydean/p/jvm-jit-jitwatch.html
关于老拐瘦
中年争取不油不丧积极向上的码农一名
咖啡,摄影,骑行,音乐
样样通,样样松
喜欢可以关注一下公众号 IT老拐瘦
IT老拐瘦目前个人博客长驻: yfge.github.io