大语言模型入门要点
引言
作为一名见证了大语言模型 (LLM) 兴起的机器学习工程师,我发现理解 LLM 相关的生态系统如何发展是令人生畏的。每周,我都会在 社交媒体上看到与 LLM 相关的新工具和技术。跟上LLM生态系统的发展其实是相当困难的。如果你刚刚开始使用LLM,大概率你会觉得潮流进展得太快而很难加入!
好消息是,我们现在已经有了可靠且易于使用的工具来切入LLM。虽然未来可能会出现更先进的工具,但目前微调模型或直接进行预测的效果令人印象深刻,使你能够创建一些真正强大的应用程序。
在这篇文章中,我将深入探讨LLM的核心原则以及开始学习LLM所需的工具和技术。
什么是LLM?
顾名思义,大语言模型是指在大型数据集上训练以理解和生成内容的模型。本质上,它是一个大规模的Transformer模型。Transformer 模型本身是一个神经网络,旨在通过分析顺序数据内的关系来掌握上下文和含义。
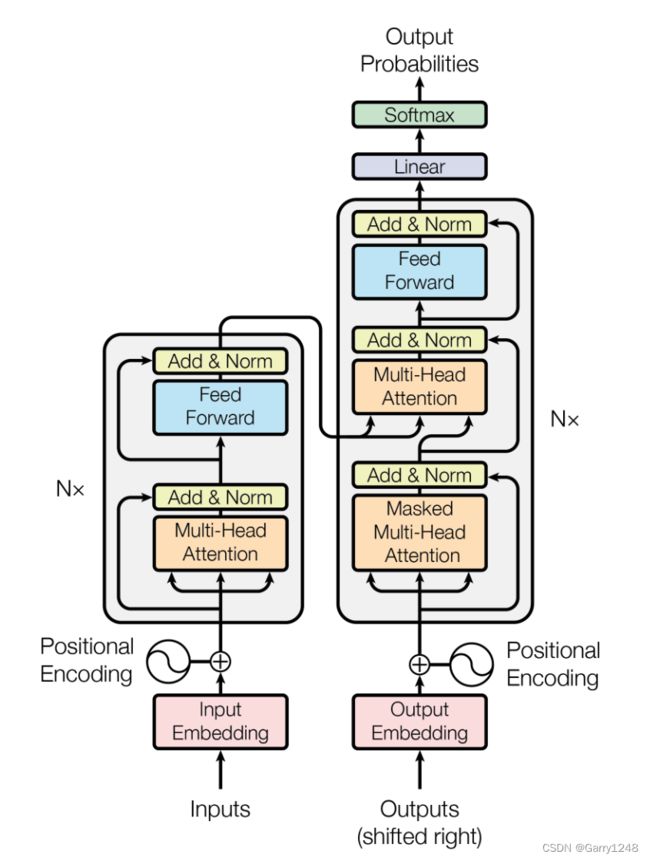
Transformer 非常适合大语言模型,因为它们有两个重要特征:位置编码和自注意力。
- 位置编码帮助模型理解序列中单词的顺序,并将此信息包含在单词嵌入中。以下是 Brandon Rohrer 的文章“ Transformers from Scratch ”中的更多信息:
“可以通过多种方式将位置信息引入到我们嵌入的单词表示中,但在原始Transformer中完成的方式是添加圆形摆动。”
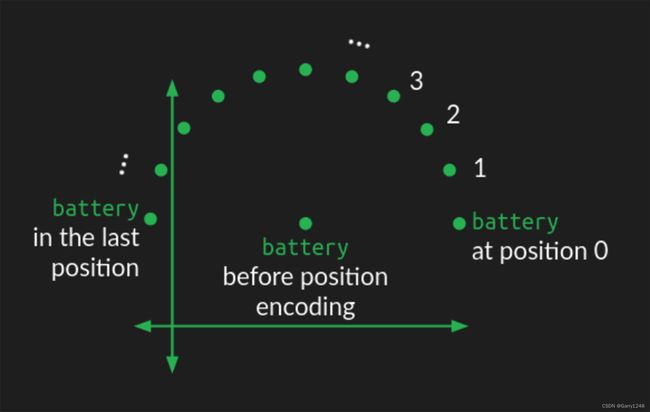
“单词在嵌入空间中的位置充当圆的中心。根据它在单词序列中的顺序,对其添加扰动。对于每个位置,单词都会移动相同的距离但以不同的角度,从而在您在序列中移动时形成圆形图案。序列中彼此接近的单词具有相似的扰动,但相距较远的单词会在不同的方向上受到扰动。”
自注意力允许序列中的单词相互交互,并找出它们应该更加关注谁。为了帮助您更好地理解这个概念,我借用了 Jay Alammar 的“The Illustrated Transformer” 文章中的一个例子:
“假设以下句子是我们要翻译的输入句子:”
“The animal didn’t cross the street because it was too tired”
“这句话中的‘it’指的是什么?它指的是街道还是动物?这对人类来说是一个简单的问题,但对算法来说就不那么简单了。”
“当模型处理‘it’这个词时,自注意力让它能够将‘it’与‘animal’联系起来。”
Transformer 利用了一种强大的注意力机制,称为多头注意力。将其视为多个自关注的结合。通过这种方式,我们可以捕获语言的各个方面,并更好地理解不同实体如何在序列中相互关联。
LLM 可以做什么?
LLM的可能性是巨大的——从创建人工智能助手和聊天机器人到与数据进行对话并增强搜索能力。
人工智能助手
LLM的发展带动了许多人工智能助手的发展,每个助手都是为特定任务而设计的,例如pair programming、日程安排和预订。正在进行的研究旨在创造一个能够协助完成广泛任务的通用助手。此类助手的示例包括Pi和 ChatGPT。
聊天机器人
您可以创建针对特定任务量身定制的聊天机器人,例如通过根据自定义数据进行微调来回答用户或客户的问题。此外,您可以灵活地开发模仿各种角色(例如游戏角色或名人)的语音模式的聊天机器人。Character.ai是一个有趣的例子。
生成
LLM经过训练,可以在给定一些输入文本的情况下生成下一段文本。你可以使用它们来编写故事、创建营销内容甚至生成代码。他们非常擅长理解文本中接下来的内容,使他们可以轻松完成各种写作任务。
翻译
LLM擅长翻译任务,这对他们来说相对简单。他们还可以处理更复杂的任务,例如将文本翻译成代码。如果你提供用户指令以任何编程语言生成代码片段,LLM应该能够为你生成代码。这种模型的一个流行例子是Code Llama。
摘要
借助LLM,您可以创建自动总结长文档、研究论文以及会议记录和文章的应用程序,使信息更易于访问。
搜索
LLM 非常擅长掌握自然语言查询。与简单的基于关键字的搜索不同,LLM 支持的搜索引擎(例如Google 的生成式 AI 搜索和Perplexity AI)可提供更相关和上下文感知的结果。这些进步彻底改变了实时搜索功能。
这些用例仅代表冰山一角;LLM提供了更多的可能性,包括个性化、推荐系统、互动小说、游戏等等。
测试LLM
ChatGPT是测试 LLM 的首选。但是,如果你像我们一样是开源解决方案的粉丝,您可能想探索HuggingChat。此外,Hugging Face 空间上还提供Google Bard和其他开源LLM。这些可以用作托管应用程序或通过 API 以编程方式访问。
您可以在 Hugging Face 的Open LLM 排行榜中找到开源 LLM 列表。这些模型使用Eleuther AI 语言模型评估工具框架进行评估,该框架可评估各种任务中的生成语言模型。
值得注意的是,并非所有聊天机器人或应用程序都使用相同的LLM。ChatGPT 采用 GPT 系列模型,HuggingChat目前采用OpenAssistant LLaMa 30B SFT 6模型,Google Bard目前由PaLM 2模型提供支持。值得注意的是,随着更新、更高效的模型不断在更大的数据集和改进的模型架构上进行训练,这些模型可能会随着时间的推移而发生变化。
LLM 有何不同?
我们需要解决的一个重要问题是:拥有多种语言模型的目的是什么?值得注意的是,LLM仍然是一个活跃的研究领域,我们还没有达到可以依赖单一模型来完成所有任务的程度。我们是否会达到那个阶段仍然不确定。然而,社区正在积极努力为我们打算构建和使用的各种应用程序发现最佳模型。
以下是造成LLM士之间差异的一些关键因素:
-
模型架构
LLM 可以根据其目标、计算资源和培训任务拥有不同的架构。 -
数据
训练数据的质量和数量因模型而异。例如,PaLM 2 使用的数据是其前身的五倍。 -
参数个数
参数数量越高表示模型越强大。例如,GPT-3有1750亿个参数。Meta 的Llama 2包括 70 亿到 700 亿个参数的模型。 -
训练目标
虽然一些LLM擅长文本补全任务,但其他LLM则针对特定用例而设计。例如,MosaicML 引入了StoryWriter模型,该模型旨在读取和编写具有扩展上下文长度(65K 标记)的虚构故事。在推理时,它可以超过 65K 个tokens。 -
计算资源
一些LLM被设计为资源密集型以获得更好的性能,而另一些LLM则优先考虑效率以加快推理速度或在资源有限时。例如,Llama 2 可以在你的 Mac 上运行。 -
什么是提示?
提示是用户给出的输入,模型根据该输入做出响应。提示可以是问题、命令或任何类型的输入,具体取决于特定用例的需要。
Classify the text into positive, negative or neutral.
Text: The movie isn’t that great.
Sentiment:
这是一个可以提供给LLM来指导的提示。LLM通常会回答“积极”、“消极”或“中性”。
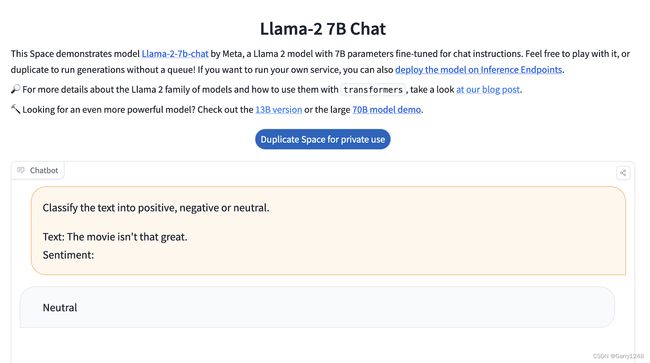

从上面的例子中,您可以看到不同的LLM会产生不同的结果。发生这种情况是因为他们的训练方式,类似于我们每个人对确切的文本所传达的情感有不同的看法。
提示格式
与LLM互动的一种直接方法是提供一个不完整的句子并让模型来完成它。这种方法符合预训练LLM的本质,其擅长文本完成。
Flamingos are
当出现此提示时,LLM会提供有关Flamingos是什么的信息。

LLM可以做的不仅仅是文本补全;他们可以总结、生成代码、解决数学问题等等。
<Q>: Two missiles speed directly toward each other, one at 9,000 miles per hour and the other at 21,000 miles per hour. They start 1,317 miles apart. Without using pencil and paper, calculate how far apart they are one minute before they collide.
<A>:

在本例中,提示的格式为< Q >其次是< A >。但是,格式可能会有所不同,具体取决于您使用的特定 LLM 以及您的目标响应。创建清晰有效的提示对于实现您想要的结果至关重要,这一过程称为提示工程。
提示工程
提示工程就是通过操纵输入提示将模型引入其潜在空间的区域,以便它预测的下一个token的概率分布符合您的意图。简单来说,它意味着指导模型生成所需的输出。
有很多方法可以做到这一点,例如提供您想要的输出类型的示例,指示模型以某些作者的“风格”编写,使用思想链推理,使模型能够使用外部工具,和更多。
零样本提示
不提供模型应如何响应的具体示例的提示称为“零样本提示”。flamingos提示和分类提示都是零样本提示的示例。在模型理解指令的情况下,零样本提示是有效的。
小样本提示
LLM擅长零样本提示,但可能难以完成复杂的任务。小样本提示(其中包含提示中的示例)可以实现上下文学习。在这种方法中,模型从指令和提供的示例中学习以理解其任务。

思想链(CoT)提示
CoT 提示鼓励LLM为其推理提供解释。将其与几次提示相结合可以为更复杂的任务带来更好的结果,这些任务需要在生成响应之前进行事先推理。

CoT 背后的核心概念是,通过提供包含推理的 LLM 少量示例,随后在解决提示时将推理过程纳入其响应中。
让我们逐步思考
你无需在提示中包含带有推理的示例,只需在问题末尾添加“Let’s consider step by step”即可通过使用零样本提示来获得准确的答案。这种方法已在大语言模型零样本推理论文中得到证明,可以产生可靠的结果。

上下文学习(ICL)
上下文学习(In-context learning,ICL)需要在提示中提供上下文,可以是示例(小样本提示)或附加信息的形式。这种方法使经过预先训练的LLM能够吸收新知识。

这个例子中的分类很容易理解——甚至一眼就能理解——因为它代表了两轮车和四轮车之间的区别。LLM 根据提示中提供的上下文进行准确分类,显示出其推理能力。这种方法可以扩展到更复杂的场景。例如,与数据交互并合并所提供文档中的上下文的聊天机器人将受到上下文窗口大小的限制,因为它限制了您可以在提示中包含的信息。幸运的是,您可以通过使用矢量数据库来克服此限制。
向量数据库
向量数据库存储上下文向量或嵌入。如果你想将文档输入到你的LLM中,你必须首先将文本转换为向量并将它们存储在向量数据库中。稍后,这些向量可用于在提示中向LLM提供“相关”上下文。相关性称为语义搜索,涉及查找输入查询和文档之间的相似性,两者都表示为向量。这使我们能够有选择地从向量数据库中获取并向LLM提供相关文档,而不会压倒提示上下文窗口。
向量数据库的示例包括Pinecone、ChromaDB和Weaviate。
语义搜索和模型提示的通用pipeline如下:
- 用户输入他们的查询。
- 使用与文档向量相同的嵌入来嵌入查询。
- 语义搜索从向量数据库中检索 k 个最相似的文档。
- 语义搜索的输出与用户查询一起发送到模型以生成一致的响应。
LangChain是一种流行的工具,用于在LLM之上构建上下文感知应用程序。
什么是检索增强生成 (Retrieval Augmented Generation,RAG)?
向量数据库中存储的文档可能无法为你的LLM提供准确回答的最新信息。出现这种限制是因为模型的知识仅限于它所训练的数据,并且有一个截止日期。如果您向模型询问其知识中未包含的最近发生的事件,它可能会产生不准确的答案,这种现象通常称为幻觉。
检索增强生成 (RAG) 通过从外部数据库检索当前上下文特定信息来解决此问题。然后,更新后的信息将被输入LLM以生成准确的答复。RAG 还使LLM能够在生成回复时引用资源。
RAG 与常规上下文学习有何不同?
RAG 可以被概念化为一种在线的上下文学习方法。生成向量、将它们存储在向量数据库中以及更新索引的过程是实时发生的。这有效地解决了 LLM 申请中常见的新近度问题。例如,您可以编写代码以确保每当有数据更新时,索引模块都会更新插入向量数据库中的数据。
RAG可以通过LangChain、HuggingFace、OpenAI等实现。
LLM参数
当提供提示时,LLM可以生成一长串潜在的回应。它的运作就像一个预测引擎。然而,在实践中,LLM通常会提供一个代表根据模型最可能的响应的输出。该模型计算响应中出现不同单词的概率,并仅返回满足设置参数的单词。
模型
预训练的 LLM 的性能取决于其规模:较大的模型往往会产生更高质量的响应。然而,更大的模型会增加成本并需要更多的计算资源。
温度
温度影响模型的创造力。较低的温度会产生一致且可预测的结果,而较高的温度会引入随机性,从而产生更具创意的输出。在温度为 0 时,模型始终产生相同的输出。然而,随着温度升高,模型输出与不同概率相关的单词。
Top-p 和 Top-k
Top-p 选择涉及从最高概率的选项中选择token;它们的概率之和决定了选择。例如,如果p设置为 0.15 时,模型将选择“United”和“'Netherlands”等标记,因为它们的组合概率总计为 14.7%。
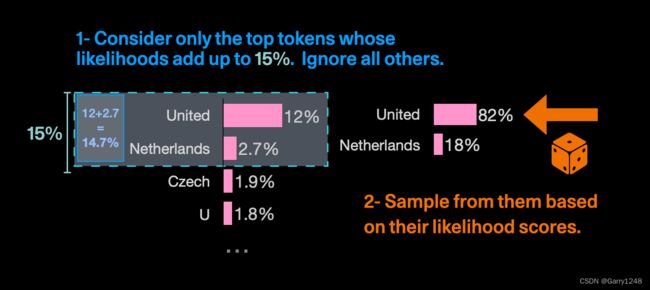
p的值越低,模型生成的响应的确定性越高。一般建议是改变温度或 top-p,但不能同时改变两者。
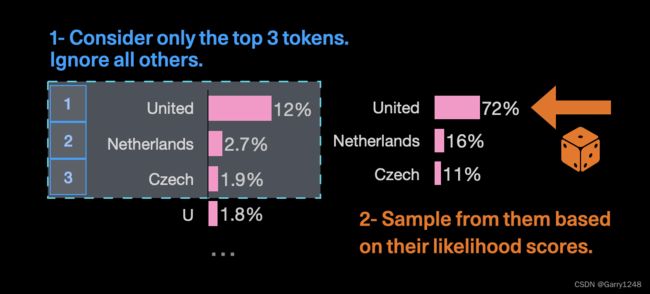
Top-k 选择涉及从最高的k 个token列表中选择下一个token,按概率排序。例如,如果k设置为 3,模型将从前 3 个选项中进行选择。
Token数量
token是LLM中文本的基本单位。一个 token 并不总是代表一个单词;它还可以包含一组字符。根据一般经验,一个token大致相当于英文文本的四个字符。

模型中的token数量对应于模型可以接受的输入token的最大数量以及它可以产生的输出token的最大数量。通常,此数字设置为 1,024、2,048 或 4,096,但对于某些型号,它可能更大。
停止序列
停止序列可用于指示模型在特定点(例如句子或列表的末尾)停止其token生成。当您打算在遇到停止序列时立即停止token生成时,它被证明是有用的。这种方法可以根据特定的用例进行定制,或者用来降低token生成的成本。
重复惩罚
重复惩罚会阻止最近在生成的文本中出现的token的重复。它通过降低选择得分较高的token的可能性来鼓励模型产生更多样化的tokens。
当重复惩罚设置为 1.0 时,不应用惩罚。如本文所述,值 1.2 在保持生成准确性和最小化重复之间取得了良好的平衡。
什么时候进行微调?
当模型需要数据输入时,无论是否有少量提示和上下文学习,提示工程都适用。然而,对于需要特定风格、模式、专业技能或内部模型改进的场景,微调是更好的选择。微调涉及通过对选定数据进行训练来更新模型参数,从内部增强模型,同时提示工程从外部增强模型。微调是一种更先进的技术,通常需要LLM的大量专业知识。
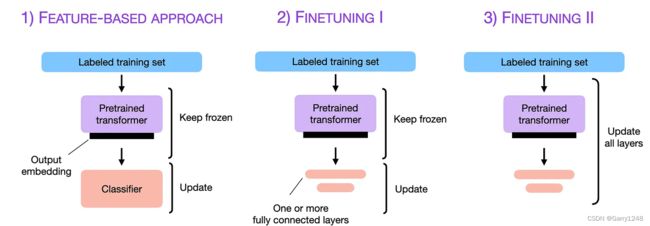
在基于特征的方法中,我们加载预训练的 LLM,为训练集生成输出嵌入,并将它们用作输入特征来训练分类器。在微调 I 中,输出层经过预训练,保持 LLM 冻结。在微调 II 中,所有模型层都会更新——这很昂贵并且需要更多的计算能力。下图展示了在 IMDB 电影评论数据集上微调的预训练 DistilBERT 模型的性能。

更新所有层(微调 II)比仅更新输出层(微调 I)产生更好的性能。这可以从博客文章作者 Sebastian Raschka 进行的实验的性能图中看出。该图显示了训练最后两层和Transformer块时的性能平台,最后阶段之间的准确性没有提高。换句话说,执行完整的参数微调在计算资源和时间方面变得低效。
参数高效微调 (PEFT)
参数高效微调(PEFT,Parameter-efficient fine-tuning)重复使用预先训练的模型来减少计算和资源需求。PEFT 包含在保持准确性的同时微调有限数量的模型参数的技术。PEFT 技术的示例包括提示调整和低秩自适应 (LoRA)。
提示调整
快速调整介于提示工程和微调之间。与微调不同,它不会修改模型参数。相反,它涉及将提示嵌入与发送到模型的每个提示一起传递。本质上,模型更新提示本身,创建我们所说的软提示。这些软提示包括嵌入、源自更大模型知识的数字表示。与使用离散输入token手动制作的硬提示相比,软提示不能直接作为文本查看或编辑。
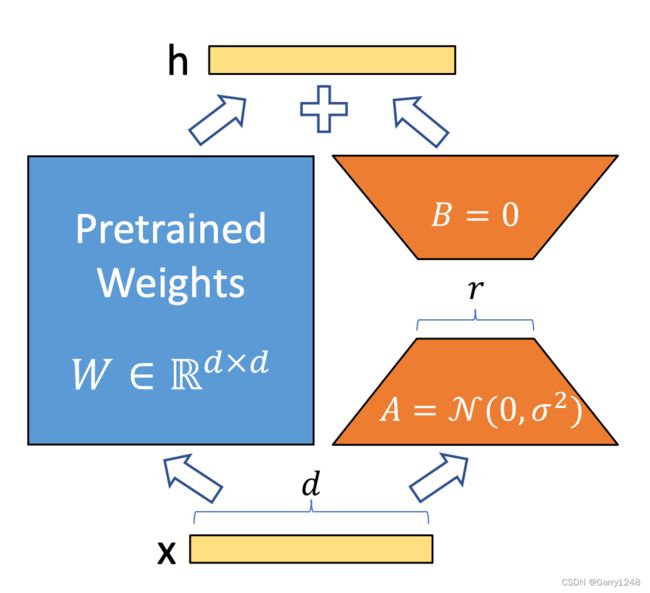
低秩适应(LoRA)
另一种流行的 PEFT 技术是 LoRA,它有助于微调加载到模型中的特定适配器。LoRA 通过将权重转换为低维空间来实现这一点,有效减少计算和存储需求。
带人类反馈的强化学习 (RLHF)
在 RLHF 中,预训练模型通过监督学习和强化学习的结合进行微调。通过对各种模型输出进行排名或评级来收集人类反馈,从而创建奖励信号。这些奖励标签训练奖励模型,反过来又指导LLM适应人类偏好。

奖励模型可以从监督微调模型(SFT)初始化,其中模型通过监督学习进行微调。然后,奖励模型计算损失并使用一种称为近端策略优化 (PPO) 的强化学习形式更新预训练的 LLM。
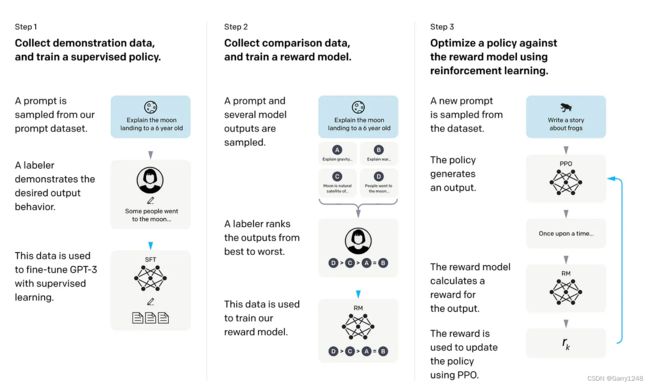
Transformer强化学习 (TRL) 库可用于训练 Transformer 语言模型和稳定扩散模型,从 SFT、奖励建模到 PPO。它构建在Transformers库之上。
用于微调的优化技术
为了提高微调效率,可以考虑采用量化和零冗余优化。
注:本节摘自 Niels Bantilan 在 Union.ai 上题为“微调与提示工程大型语言模型”的博客文章。
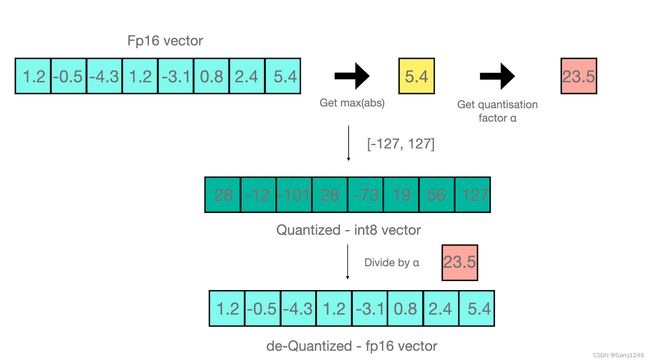
量化降低内存利用率
量化是降低数值数据精度的过程,因此消耗更少的内存并提高处理速度。然而,较低的精度会导致较低的准确度,因为每层中存储的信息较少。这不仅适用于神经网络,也适用于神经网络。如果您是使用过 Numpy、Pandas 或任何其他数值库的数据科学家或 ML 工程师,您可能遇到过浮动64,浮动32和浮动16数据类型。数字 64、32 和 16 分别表示使用多少位来表示(在本例中)浮点数。
PyTorch、TensorFlow和Jax等深度学习框架通常提供进行混合精度训练的实用程序;这使得框架在适当的时候自动将权重、偏差、激活和梯度转换为较低的浮点精度(例如 float16),然后在数值稳定性很重要时(例如在梯度累积或损失缩放)。微调器可能感兴趣的一个库是BitsandBytes库,它使用 8 位优化器来显着减少模型训练期间的内存占用。
零冗余优化分片和卸载模型状态
几年前,唯一可以轻松利用深度学习库的数据并行性会消耗大量 GPU 内存。如果您有一台具有四个 GPU 的机器,则可以将模型复制四次,并且如果您可以在每个 GPU 上训练批量大小为 8 的机器,则您将获得有效批量大小为 32。

ZeRO论文可通过DeepSpeed和 Pytorch 的FSDP实现获取,使您能够在训练系统中的可用 GPU 和 CPU 上分割优化器状态、梯度和参数。这是以分层方式完成的,因此只有特定本地前向/后向传递所需的模型状态才会跨 GPU 复制。例如,如果您正在训练具有三层的神经网络,ZeRO 协议会复制第一层前向传递所需的模型状态,并在获得激活后释放内存。这在第二层和第三层的前向传递中重复。最后,该过程应用于向后传递,从而更新模型的参数。

ZeRO 框架还允许在适当的情况下将模型状态卸载到 CPU 或NVMe,这进一步减少了 GPU 内存消耗并提高了训练速度。
LLM 中的幻觉是什么?
当模型生成看似合理但实际上不正确或无意义的文本时,LLM中的幻觉就会发生。虽然Google Bard、Perplexity AI 和Bing Chat显示了引用,但它们可能会在一定程度上减少幻觉,但并不能完全消除它们。

为什么 LLM 会产生幻觉?
当LLM对提示的上下文没有完全理解时,他们往往会产生幻觉。在这种情况下,他们可能会根据学到的模式做出有根据的猜测。幻觉也可能是由于训练数据不完整或不正确造成的。由于LLM依赖于他们的训练数据而不是现实世界的信息,因此他们的输出有时可能是无关紧要的。然而,可以采用检索增强生成 (RAG) 等技术来合并实时信息并缓解此问题。
如何减少幻觉?
在某些情况下,例如当需要创造性反应时(例如在故事写作或营销内容创建中),幻觉可能是可取的。然而,当需要准确性和事实信息时,幻觉就变得不可取。
以下是减轻幻觉的方法:
- 提示工程:通过在提示中包含更多上下文信息,语言模型可以更好地理解上下文,并可以生成更合适的响应。
- 上下文学习:当模型收到上下文信息作为提示的一部分时,它可以访问有助于生成准确响应的附加数据。缺乏背景是产生幻觉的常见原因。
- 受控生成:在提示中施加足够的约束可以限制模型产生幻觉内容的自由。
然而,值得注意的是,幻觉并不总是能完全消除。模型仍然可能产生难以检测的错误。
在本地计算机上运行 LLM
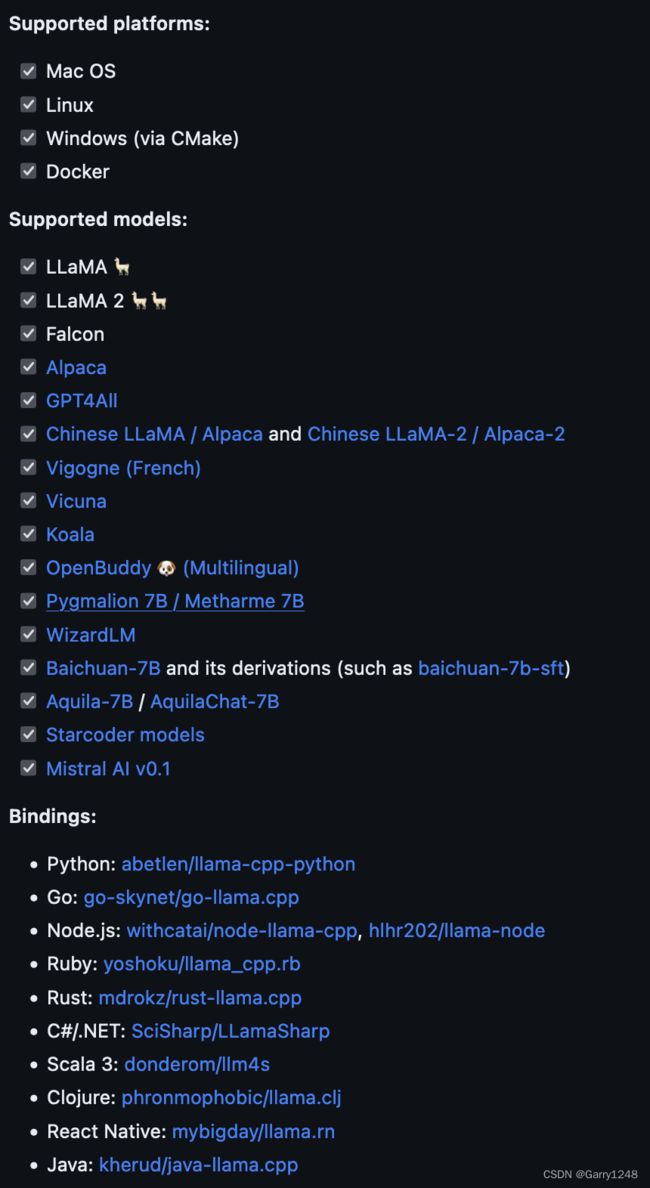
确实,你没听错!您可以在本地计算机上运行 LLM 来生成预测。您可以利用机器学习编译 (MLC)进行 LLM 或使用llama.cpp达到相同目的。
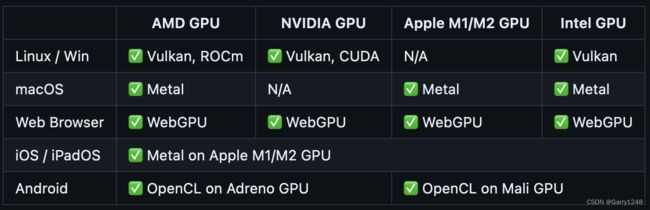
MLC
MLC 可通过具有编译器加速功能的本机 API 实现任何 LLM 的本机部署。它提供对以下平台和硬件的支持:
llama.cpp
llama.cpp 使您能够在 MacBook 上使用 4 位整数量化执行 Llama 模型。它用纯C/C++进行Llama模型的推理。
在生产中微调和运行LLM
对于那些渴望进一步探索的人,您可能想知道如何通过精心编排的管道来微调LLM并执行低延迟、高吞吐量的推理。
成功的微调通常需要大量的 GPU、RAM 和内存资源,但值得注意的是,某些模型可以在本地计算机上进行微调。例如,您可以在此处找到有关在本地计算机上微调 Llama 2 的指南。具体的资源要求根据您使用的模型的大小而有所不同。
Flyte能够将 PyTorch Elastic Trainer、PEFT、量化和各种优化技术无缝集成到您的 LLM pipeline中进行微调。此外,它还提供了实施缓存、恢复、检查点和现场实例运行等策略的灵活性。这些功能是编排工具包的一部分,在优化资源分配以降低成本和更有效地管理作业时,它被证明是非常宝贵的。
对于推理,可以使用vLLM、CTranslate2、Rayserve和文本生成推理等各种工具来满足您的特定需求。下图是LLM推理框架比较:
结论
这篇博文介绍了LLM并讨论了我们与他们互动的各种方式。首先概述了LLM的开发方式及其应用。接下来,我们深入研究了LLM的测试方式以及为什么需要不同类型的LLM,并强调了它们的差异。
然后我们探索了提示的概念,它与模型交互并鼓励它通过各种操作生成准确的响应。随后,我们探索了 LLM 参数,并研究了微调 LLM 的一些原因,以及降低计算和存储成本的优化策略。
最后,我们解决了LLM中的幻觉问题,并提供了在本地计算机上运行LLM的见解。