re:Invent 2023技术上新|Amazon Bedrock已推出Amazon Titan图像生成器、多模态嵌入和文本模型...

亚马逊云科技推出两种新的 Amazon Titan 多模态基础模型(FM):Amazon Titan Image Generator(预览版)和 Amazon Titan Multimodal Embeddings。Amazon Bedrock 中也已推出 Amazon Titan Text Lite 和 Amazon Titan Text Express。现在,有三种可用的 Amazon Titan Text FM 供您选择,包括 Amazon Titan Text Embeddings。
Amazon Titan 模型融合了 Amazon 在 25 年间的人工智能(AI)和机器学习(ML)创新,通过完全托管的 API 提供一系列高性能图像、多模态和文本模型选项。亚马逊云科技基于大型数据集对这些模型进行了预训练,使它们成为强大的通用模型,旨在支持各种使用案例,同时还支持负责任地使用人工智能。
您可以按原样使用基础模型,也可以使用自己的数据私下对模型进行自定义。要启用对 Amazon Titan FM 的访问权限,请导航到 Amazon Bedrock 控制台,然后在左下角菜单上选择模型访问权限。在“模型访问权限概览”页面上,选择管理模型访问权限,启用对 Amazon Titan FM 的访问权限。
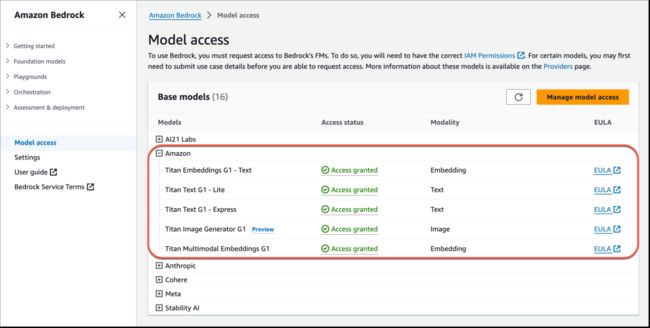
下面,我简要介绍一下新模型。
Amazon Titan Image Generator
(预览版)
作为内容创建者,您现在可以使用 Amazon Titan Image Generator,根据英语自然语言提示快速创建和优化图像。这样可以帮助广告、电子商务、媒体和娱乐领域的公司以低成本大量创建工作室质量的逼真图像。该模型可以根据文本描述生成多个图像选项,从而轻松迭代图像概念。该模型可以理解包含多个对象的复杂提示并生成相关的图像。它基于高质量、多样化的数据进行训练,以创建更准确的输出,例如具有包容属性和有限失真的逼真图像。
Titan Image Generator 的图像编辑功能包括使用内置细分模型根据文本提示自动编辑图像。该模型支持使用图像掩模进行修复和外部绘制,以扩展或更改图像的背景。您还可以配置图像尺寸并指定您希望模型生成的图像变体的数量。
此外,您可以使用专有数据自定义模型,生成与您的品牌指南一致的图像,也可以生成特定风格的图像,例如,使用之前营销活动中的图像对模型进行微调。Titan Image Generator 还可以减少有害内容的生成,以支持负责任地使用人工智能。默认情况下,Amazon Titan 生成的所有图像都包含不可见水印,旨在提供一种谨慎的机制来识别人工智能生成的图像,从而帮助减少错误信息的传播。
Amazon Titan Image Generator 的
实际运用
您可以提交英语自然语言提示以生成图像,或者上传图像供编辑,从而开始在 Amazon Bedrock 控制台中使用该模型。在以下示例中,我将向您展示如何使用适用于 Python Amazon SDK (Boto3) 通过Amazon Titan Image Generator 生成图像。
首先,我们来看看您可以在推理请求正文中指定的图像生成配置选项。对于任务类型,我选择 TEXT_IMAGE ,根据自然语言提示创建图像。
import boto3
import json
bedrock = boto3.client(service_name="bedrock")
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
# ImageGenerationConfig Options:
# numberOfImages: Number of images to be generated
# quality: Quality of generated images, can be standard or premium
# height: Height of output image(s)
# width: Width of output image(s)
# cfgScale: Scale for classifier-free guidance
# seed: The seed to use for reproducibility
body = json.dumps(
{
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": "green iguana", # Required
# "negativeText": "" # Optional
},
"imageGenerationConfig": {
"numberOfImages": 1, # Range: 1 to 5
"quality": "premium", # Options: standard or premium
"height": 768, # Supported height list in the docs
"width": 1280, # Supported width list in the docs
"cfgScale": 7.5, # Range: 1.0 (exclusive) to 10.0
"seed": 42 # Range: 0 to 214783647
}
}
) 接下来,指定 Amazon Titan Image Generator 的模型 ID,使用 InvokeModel API 发送推理请求。
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-image-generator-v1"
accept="application/json",
contentType="application/json"
)然后,解析响应并解码 base64 编码的图像。
import base64
from PIL import Image
from io import BytesIO
response_body = json.loads(response.get("body").read())
images = [Image.open(BytesIO(base64.b64decode(base64_image))) for base64_image in response_body.get("images")]
for img in images:
display(img)瞧,这是绿鬣蜥(实际上,这是我最喜欢的动物之一):
要详细了解所有 Amazon Titan Image Generator 功能,请访问 Amazon Titan 产品页面。(您会在该页面看到更多鬣蜥图像。)
接下来,我们将该图像与新的 Amazon Titan Multimodal Embeddings 结合使用。
Amazon Titan
Multimodal Embeddings
Amazon Titan Multimodal Embeddings 帮助您为最终用户打造更准确、上下文相关的多模态搜索和推荐体验。多模态是指系统能使用不同类型的数据(模式)处理和生成信息。借助 Titan Multimodal Embeddings,您可以提交文本、图像或两者的组合作为输入。
该模型会将图像和简短英语文本(最多 128 个令牌)转换为嵌入,从而捕获语义以及数据之间的关系。您还可以根据图像-说明组合微调模型。例如,您可以组合文本和图像来描述公司特定的制造部件,以便更有效地理解和识别部件。
默认情况下,Titan Multimodal Embeddings 会生成 1,024 个维度的向量,借此您可以打造较高准确度和速度的搜索体验。您还可以配置较小的向量维度,以便优化速度和性价比。该模型提供异步批处理 API,Amazon OpenSearch Service 将马上提供连接器,为神经搜索添加 Titan Multimodal Embeddings 支持。
Amazon Titan Multimodal Embeddings
的实际运用
在本演示中,我将创建图像和文本的组合嵌入。首先,我对图像进行 base64 编码,然后在推理请求的正文中指定 inputText 、 inputImage 或两者兼有。
# Maximum image size supported is 2048 x 2048 pixels
with open("iguana.png", "rb") as image_file:
input_image = base64.b64encode(image_file.read()).decode('utf8')
# You can specify either text or image or both
body = json.dumps(
{
"inputText": "Green iguana on tree branch",
"inputImage": input_image
}
)接下来,指定 Amazon Titan Multimodal Embeddings 的模型 ID,使用 InvokeModel API 发送推理请求。
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-embed-image-v1",
accept="application/json",
contentType="application/json"
)我们来看看响应。
response_body = json.loads(response.get("body").read())
print(response_body.get("embedding"))
[-0.015633494, -0.011953583, -0.022617092, -0.012395329, 0.03954641, 0.010079376, 0.08505301, -0.022064181, -0.0037248489, ...]为了简洁起见,我对输出进行了编辑。多模态嵌入向量之间的距离使用余弦相似度或欧几里得距离等指标测量,显示了不同模式之间所表示信息的相似或差异程度。距离越小意味着相似度越高,而距离越大意味着差异越大。
下一步,您可以在向量存储或向量数据库中存储和索引多模态嵌入,从而构建图像数据库。要实施文本转图像的搜索,请使用 inputText 查询数据库。要实施图像转图像的搜索,请使用 inputImage 查询数据库。要实施图像与文本转图像的搜索,请使用 inputImage 和 inputText 查询数据库。
Amazon Titan Text
Amazon Titan Text Lite 和Amazon Titan Text Express 是大型语言模型(LLM),支持各种与文本相关的任务,包括总结、翻译和对话式聊天机器人系统。它们还可以生成代码,优化到支持热门编程语言和文本格式(例如 JSON 和 CSV)。
Titan Text Express – Titan Text Express 的上下文长度上限为 8192 个令牌,非常适合广泛的任务(例如开放式文本生成和对话式聊天),并且在检索式增强生成(RAG)工作流内提供支持。
Titan Text Lite – Titan Text Lite 的上下文长度上限为 4096 个令牌,是非常适合英语任务的高性价比版本。该模型高度可定制,可以针对文章总结和文案撰写等任务进行微调。
Amazon Titan Text 的实际运用
在本演示中,我要求 Titan Text 给我的团队成员写一封电子邮件,建议他们组织直播:“以首席开发者宣传官 Antje 的名义写一封简短的电子邮件,鼓励开发者关系团队的同事组织直播,演示我们的新 Amazon Titan V1 模型。”
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"maxTokenCount":512,
"stopSequences":[],
"temperature":0,
"topP":0.9
}
})Titan Text FMs 支持 temperature 和 topP 推理参数以控制响应的随机性和多样化,并且支持 maxTokenCount 和 stopSequences 以控制响应的长度。
接下来,选择其中一个 Titan Text 模型的模型 ID,使用 InvokeModel API 发送推理请求。
response = bedrock_runtime.invoke_model(
body=body,
# 选择模型 ID
# Titan Text Express: "amazon.titan-text-express-v1"
# Titan Text Lite: "amazon.titan-text-lite-v1"
modelID="amazon.titan-text-express-v1"
accept="application/json",
contentType="application/json"
)我们来看看响应。
response_body = json.loads(response.get('body').read())
outputText = response_body.get('results')[0].get('outputText')
text = outputText[outputText.index('\n')+1:]
email = text.strip()
print(email)主题:直播演示我们新推的 Amazon Titan V1 模型!
亲爱的各位同仁:
见信安好!我很高兴宣布,我们最近推出了新的 Amazon Titan V1 模型。我相信,这将是我们向更广泛的开发者社区展示它们功能的好机会。
我建议,可以组织一次直播来演示这些模型,讨论它们的功能、优势以及它们如何帮助开发者构建创新型应用程序。该直播可以通过适合我们关注者的平台来举办。
我相信,通过展示我们的新模型,不仅可以提高知名度,还可以与开发者们建立更牢固的关系。我们还有机会接收反馈,并根据开发者的需求改进我们的产品。
如果您有兴趣参与这次直播,请告诉我。我很乐意提供您可能需要的任何支持或指导。我们一起让这次直播取得成功,向大家展示 Amazon Titan V1 模型的强大功能!
此致
Antje
首席开发者布道师
很好。我可以马上发送这封电子邮件!
可用性和定价
Amazon Titan Text FM 现已在以下亚马逊云科技区域推出:美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(新加坡、东京)和欧洲地区(法兰克福)。Amazon Titan Multimodal Embeddings 现已在以下区域推出:美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)。Amazon Titan Image Generator 在以下区域推出公开预览版:美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)。有关定价的详细信息,请参阅 Amazon Bedrock 定价页面。
了解详情
Amazon Bedrock 产品页面
https://aws.amazon.com/bedrock/
Amazon Titan 产品页面
https://aws.amazon.com/bedrock/titan/
Amazon Bedrock 用户指南。
https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html
立即转到亚马逊云科技管理控制台,开始在 Amazon Bedrock 上使用 Amazon Titan FM 构建生成式 AI!
了解所有 re:Invent 2023 热门发布产品,
请扫描下方二维码:


听说,点完下面4个按钮
就不会碰到bug了!
