Kafka
文章目录
- 一、什么是kafka?
- 二、消息队列的两种模式
-
- 2.1 点对点
- 2.2 发布/订阅模式
- 2.3 同步发送和异步发送
- 三、总体架构&概念
- 四、特性&设计原则
- 五、核心API
- 六、安装
-
- 6.1 安装jdk
- 6.2 安装zookeeper
- 6.3 安装[kafka](https://www.apache.org/dyn/closer.cgi?path=/kafka/3.1.0/kafka_2.13-3.1.0.tgz)
- 七、kafka测试消息生产和消费
-
- 7.1 创建生产者
- 7.2 查看当前的`topic`列表
- 7.3 查看当前主题的详细信息
- 7.4 创建消费者
- 八、Topic命令
- 九、kafka生产者原理
- 十、kafka异步发送数据
- 十一、同步发送
- 十二、生产者分区
-
- 12.1 分区的好处
- 12.2 分区的策略
- 12.3 代码层面
- 12.4 自定义分区
- 十三、提高生产者吞吐量
- 十四、数据可靠
-
- 14.1 应答策略 0
- 14.2 应答策略 1
- 14.3 应答策略 -1
- 14.4 数据完全可靠性
- 14.5 可靠性总结
- 14.6 数据重复分析
- 14.7 代码中设置acks
- 十五、数据去重
-
- 15.1 幂等性原理
- 15.2 kafka事务原理
- 十六、数据乱序
- 十七、kafka的Broker
-
- 17.1 zookeeper 存储的kafka信息
- 17.2 kafkaBroker整体工作流
- 17.2 服役新节点
- 17.3 退役旧节点 //TODO
- 17.4 Broker的副本
- 17.5 leader选举的流程
- 17.6 故障处理
- 17.7 分区副本分配
- 17.8 手动调整分区
- 十八、kafka的消费者
-
- 18.1 kafka的消费方式
- 18.2 kafka消费者原理
- 18.3 kafka消费者组的原理
- 18.4 kafka消费者组初始化原理
- 18.5 消费者组详细消费流程
- 18.6 消费者API
一、什么是kafka?
kafka是一个分布式的基于发布/订阅模式的消息队列。同时也是一个支持多分区、多副本,基于 Zookeeper 的分布式消息流平台。
二、消息队列的两种模式
2.1 点对点
一对一,消费者主动拉取消息,消息收到后消息清除
-
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。
-
消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。
-
Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。

2.2 发布/订阅模式
一对多,消费者消费数据后不会清除数据
-
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消
息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LHcV1Llw-1650767668633)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220407135602360.png)]
多对多

2.3 同步发送和异步发送
-
同步发送

-
异步发送

三、总体架构&概念

- 消息:Kafka 中的数据单元被称为消息,也被称为记录,可以把它看作数据库表中某一行的记录。
- 批次:为了提高效率, 消息会
分批次写入 Kafka,批次就代指的是一组消息。 - producer:消息生产者,就是向 kafka broker 发消息的客户端
- consumer:消息消费者,向 kafka broker 取消息的客户端
- Consumer group: 消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内的消费者消费,消费者组内互不影响,即消费者组是逻辑上的一个订阅者
- Broker:一台kafka服务器就是一个broker。一个集群就是多个broker组成,一个broker可以有多个topic。
- Topic:topic就是消息的分类,一个主题代表了一个分类。生产者和消费者面向的都是一个topic
- Partition:一个
Topic可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序。 - Replica:为了保证当集群中的某个节点发生故障时,**该节点上的partition数据不会丢失,且kafka还能正常工作,**所以提供了副本机制,一个Topic分区都有若干个副本,一个leader和若干个
follower.领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随。 - Rebalance:重平衡,消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
四、特性&设计原则
高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储。容错性: 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作高并发: 支持数千个客户端同时读写
五、核心API
-
Producer API,它允许应用程序向一个或多个 topics 上发送消息记录
-
Consumer API,允许应用程序订阅一个或多个 topics 并处理为其生成的记录流
-
Streams API,它允许应用程序作为流处理器,从一个或多个主题中消费输入流并为其生成输出流,有效的将输入流转换为输出流。
-
Connector API,它允许构建和运行将 Kafka 主题连接到现有应用程序或数据系统的可用生产者和消费者。例如,关系数据库的连接器可能会捕获对表的所有更改
六、安装
6.1 安装jdk
-
文件上传,并解压
tar -zxvf 文件名
-
修改环境变量
vi /etc/profileexport JAVA_HOME=/usr/local/jdk1.8.0_11 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=$PATH:${JAVA_PATH}
6.2 安装zookeeper
-
下载zookeeper并上传解压

-
在zookeeper的根目录下创建
data文件夹
-
修改数据存储的地址

-
zookeeper启动报错
Error: JAVA_HOME is not set and java could not be found in PATH.- 修改文件


-
启动
zookeeper,在bin目录下执行命令./zkServer.sh start
-
查看
zookeeper是否启动成功ps -ef | grep zookeeper
6.3 安装kafka
-
配置文件参数
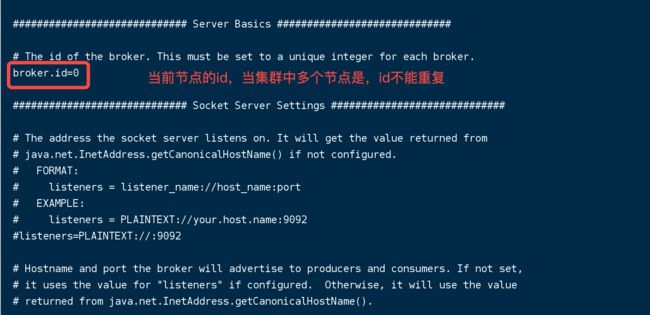
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O0GLaaje-1650767668635)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220408154845188.png)]
-
在跟目录下启动
bin/kafka-server-start.sh config/server.properties -
启动后用
jps查看进程
七、kafka测试消息生产和消费
7.1 创建生产者
-
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic tianzhuang --partitions 2 --replication-factor 1创建主题命令
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic tianzhuang --partitions 2 --replication-factor 1
Exception in thread "main" joptsimple.UnrecognizedOptionException: zookeeper is not a recognized option
at joptsimple.OptionException.unrecognizedOption(OptionException.java:108)
at joptsimple.OptionParser.handleLongOptionToken(OptionParser.java:510)
at joptsimple.OptionParserState$2.handleArgument(OptionParserState.java:56)
at joptsimple.OptionParser.parse(OptionParser.java:396)
at kafka.admin.TopicCommand$TopicCommandOptions.<init>(TopicCommand.scala:567)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:47)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic tianzhuang --partitions 2 --replication-factor 1
Created topic tianzhuang.
在较新版本(2.2 及更高版本)的 Kafka 不再需要 ZooKeeper 连接字符串,即- -zookeeper localhost:2181。使用 Kafka Broker的 --bootstrap-server localhost:9092来替代- -zookeeper localhost:2181
-
命令分析
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic tianzhuang --partitions 2 --replication-factor 1 ------------------------------------------------------------------------------------ bin/kafka-topics.sh 脚本 --bootstrap-server localhost:9092 之前是zookeeper的服务端口号 --create 动作指令 --topic tianzhuang 主题名称 --partitions 2 分区数量 2 --replication-factor 1 副本数量 一个
7.2 查看当前的topic列表
-
命令:
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PkshpSp6-1650767668636)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220408174226016.png)]
7.3 查看当前主题的详细信息
- 命令:
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic tianzhuang
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l8Bhq4ZS-1650767668636)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220408174429678.png)]
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic tianzhuang --partitions 2 --replication-factor 1
Created topic tianzhuang.
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
tianzhuang
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic tianzhuang
Topic: tianzhuang TopicId: ctDKcJF2R-ynOhlqr0MdNg PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: tianzhuang Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: tianzhuang Partition: 1 Leader: 0 Replicas: 0 Isr: 0
7.4 创建消费者
-
创建消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tianzhuang -
生产者者发送消息
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic tianzhuang
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic tianzhuang >m^H^H^H^H1^H^H^H^H^H >qwertyuiop[';lkjhgfdsa > -
此时消费端就能监听到消息
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tianzhuang qwertyuiop[';lkjhgfdsa PPPPPP
八、Topic命令
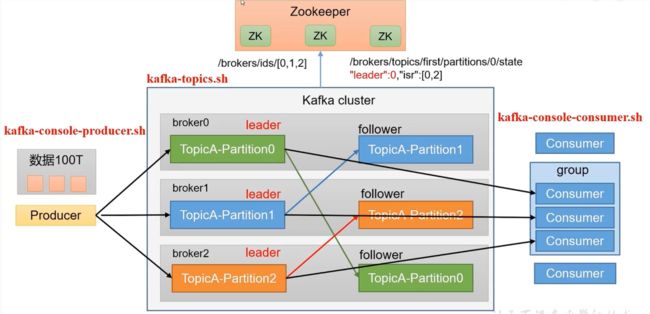
-
kafka-topic.sh:对应集群的脚本
-
kafka-console-producer: 生产者的脚本
-
kafka-console-consumer:消费者的脚本
-
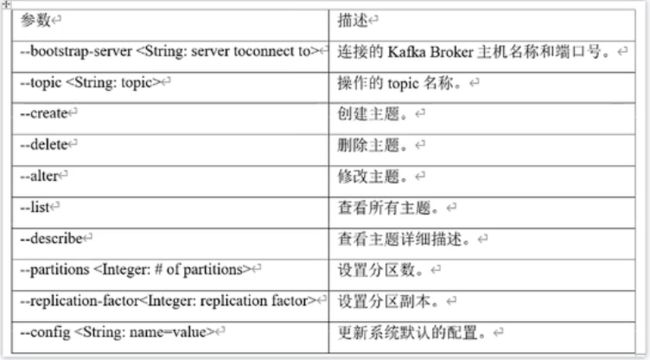
-
输入
bin/kafka-topics.sh,就可以看到对应的命令操作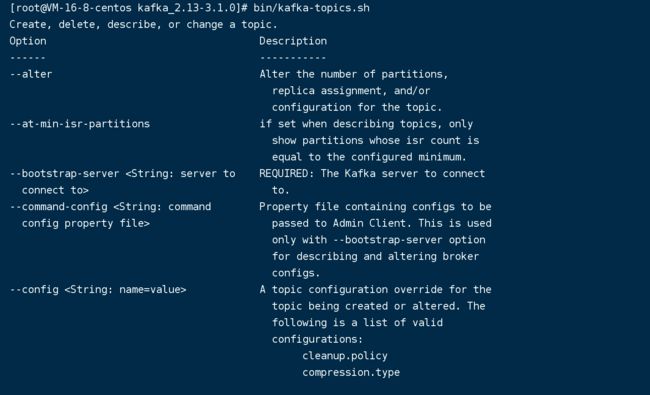
-
创建``topic
:bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic tianzhuang --partitions 2 --replication-factor 1` -
查看
topic的详细信息bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic tianzhuang -
修改分区**(分区数量只能增加不能减少)**
bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic tianzhuang --alter --partitions 3
-
不能通过命令行的方式去修改副本
-
开启生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic tianzhuang -
开启消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tianzhuang-
#生产者 [root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic tianzhuang >hello >hello #消费者 [root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tianzhuang hello当先开启生产者,发送消息时。此时如果没有消费者,则该条消息不会被后来开启的消费者消费到,消费者只能消费创建后生产者发来的数据
-
消费者消费topic的历史数据的命令,在末尾加上
--from-beginning的参数bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tianzhuang --from-beginning[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k0UGMXFa-1650767668636)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220411111001044.png)]
[root@VM-16-8-centos kafka_2.13-3.1.0]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tianzhuang --from-beginning qwertyuiop[';lkjhgfdsa hello PPPPPP aaa hello
-
九、kafka生产者原理
-
原理图

-
Sender从RecordAccumulator拉取数据的两种策略
batch.size:数据累计达到batch.size的大小(默认16k)后,Sender就会从RecordAccumulator开始拉取数据linger.ms如果数据迟迟没有达到batch.size的大小,Sender就会根据设置的``linger.ms从RecordAccumulator`开始拉取数据。单位ms,默认值是0ms,表示无延迟。
-
kafka集群应答Selector的三种策略- 0:生产者发送过来的数据,不需要等带数据落盘就应答
- 1:生产者发送过来的数据,leader收到数据后应答
- -1(ALL):leader和ISR队列的所有节点都收齐数据后应答
-
关于序列化器的对比
Java的序列化器处理的数据包中除了有效数据,还会有大量的信息数据。
kafka的数据包中序列化的信息数据就会比较少,数据大时,效率较高。

-
十、kafka异步发送数据
外部的数据发送到队列里面
-
异步发送
import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * @Auther: devin tian * @Date: 2022/4/11 14:38 * @Description: */ public class CustomProducer { public static void main(String[] args) { //创建配置文件 Properties properties=new Properties(); //连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"81.68.187.88:9092"); //指定对应的key和value的序列化器 //org.apache.kafka.common.serialization.StringSerializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //创建生产者 KafkaProducer<String,String> producer =new KafkaProducer<String, String>(properties); //发送消息 for (int i = 0; i < 5; i++) { producer.send(new ProducerRecord<>("tianzhuang","hello : "+i)); } //关闭资源 producer.close(); } } -
回调异步发送
import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * @Auther: devin tian * @Date: 2022/4/11 16:21 * @Description: */ public class MyProducer { /* public static void main(String[] args) { //创建配置文件 Properties properties=new Properties(); //连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"81.68.187.88:9092"); //指定对应的key和value的序列化器 //org.apache.kafka.common.serialization.StringSerializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //创建生产者 KafkaProducer
十一、同步发送
-
在异步发送的基础上调用get
public class SYCustomProducer { public static void main(String[] args) { //创建配置文件 Properties properties = new Properties(); //连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "81.68.187.88:9092"); //指定对应的key和value的序列化器 //org.apache.kafka.common.serialization.StringSerializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //创建生产者 KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties); //发送消息 try { for (int i = 0; i < 5; i++) { producer.send(new ProducerRecord<>("tianzhuang", "hello : " + i)).get(); } } catch (Exception e) { e.printStackTrace(); //关闭资源 producer.close(); } } }
十二、生产者分区
12.1 分区的好处
-
合理地使用存储资源,将海量数据分割成一小块一小块的存储在多台broker上。合理控制分区任务,实现负载均衡的效果
-
提高并行度,生产者可以以分区为单位将发送数据;消费者可以以分区为单位消费数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GV2cRLZ0-1650767668637)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220411181933233.png)]
12.2 分区的策略
ProducerRecord类有多个构造方法

-
在指明partition的情况下,直接将指明的值作为partition
-
没有指明partition的值,但是有
key值的情况下,将Key的hash值和topic的partition数进行取余得到``partition`值例如:key1的hash值是5,key2的hash值是6,topic的partition数是3.
那么key1对应的value就写入1号分区,key2对应的value写入0号分区
-
在既没有partition的值有没有
key值的情况下,Kafka采用了Sticky partition粘性分区器,随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已经完成,kafka会随机选择另外一个分区进行使用(和上一次选过的分区不同,之前选择过的分区这次不在选用)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到,kafka再随机选择一个分区进行使用(如果还是0会继续随机)
12.3 代码层面

- 对应的策略主要是在
send方法中去实现
12.4 自定义分区
-
package com.tz.kafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; /** * @Auther: devin tian * @Date: 2022/4/12 13:45 * @Description:自定义kafka的分区器 */ public class MyPartitioner implements Partitioner { /* * 自定义一个kafka分区器 * 需求: * 如果消息的value中含有"kafka"字段,就把消息放到1号分区,否则放到2号分区 * */ @Override public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) { //获取数据 String value = o1.toString(); int partition; //根据数据的参数来确定分区 if (value.contains("kafka")){ return partition=1; }else { return partition=2; } } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } }
步骤一:实现
Partitioner接口,然后重写partition方法步骤二:在
properties中将自己的partitioner关联到分区器上
十三、提高生产者吞吐量
可以根据情境来修改以下几个参数
一批只拉走一个数据
----------------------------------------> 通过调整批次的大小来提高吞吐量
batch.size:批次大小,默认16k
一批传送个多个数据
---------------------------------------->
-
linger.ms: 拉取数据的等待时间,修改为5-100ms(时间太长的话会导致前面的数据要等待其他数据,造成数据延迟) -
Compression.type:压缩snappy -
RecordAccumultor:缓冲区大小,修改为64M -
代码

//缓冲区的大小 //默认32M 达到缓存区指定大小后写到topic props.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); //批处理数据的大小,达到缓存区指定大小后,每次写入多少数据到topic //默认16KB props.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //可以延长多久发送数据 //默认为0 表示不等待 ,立即发送 等待时长指的是是否达到上面设置的16KB,即是否达到设置的批处理数据大小值 props.put(ProducerConfig.LINGER_MS_CONFIG,1); //压缩 props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
十四、数据可靠
数据可靠是靠ACK应答来保证的,三种ACK应答方式存在的漏洞
14.1 应答策略 0
0:生产者发送过来的数据,不需要等带数据落盘就应答。
因为leader不需要应答producer,此时如果leader挂掉了,那么producer并不知情,依然进行数据的发送,就会导致后续发出的数据丢失。
14.2 应答策略 1
1:生产者发送过来的数据,leader收到数据落盘后应答
假如说:leader把数据落盘后,给producer应答成功。
- 此时leade
- 成数据同步给
Follower,leader挂掉了 - 这时,会选出新的follower
- 但是此时新选出来的Leader中并没有之前的数据
- 造成了数据丢失
14.3 应答策略 -1
-1(ALL):leader和ISR队列的所有节点都收齐数据后应答
-
假设一种场景:
leader正在同步数据,此时一个follower挂掉了。但是leader要一直等待着follower的应答,系统就会一直卡着,leader不会给producer应答。
为了解决这个问题:
leader里面维护了一个动态的
in-sync replica set (ISR),意为和leader保持同步的Leader—Follower集合(leader:0, ISR:0,1,2)。
如果Follower长时间未向leader发送通信或者同步数据则该Follower将被踢出ISR。
时间的阈值由
replica.lag.time.max.ms参数设定,默认时间30s。例如2超时(leader:0, ISR:0,1)这样就不用等待长期联系不上或者已经故障的节点
-
数据可靠性分析:
如果分区副本设置为1,ISR里应答的最小副本数量设置为1,和ack=1的效果是一样的,仍然有丢失数据的危险。
-
14.4 数据完全可靠性
-
公式
数据完全可靠条件 = (ACK级别为-1) + (分区副本数大于等于2)+ (ISR里应答的最小副本数量大于等于2)
14.5 可靠性总结
- acks=0 生产者发送来消息就不管了,可靠性差,效率高
- acks=1 生产者发送数据leader应答,可靠性中等,效率中等
- acks=-1 生产者发送数据,leader和ISR队列里面所有的follower都应答,可靠性高,效率低
在生产环境中acks=0很少使用。
acks=1,一般用于传输普通日志,允许个别数据丢失。
acks=-1,一般用于传输和钱相关的数据,以及对可靠性要求高的场景。
14.6 数据重复分析
在acks=-1的时候,如果数据同步已经成功,leader正在应答时,leader挂掉了。
就会选出新的leader。由于Producer没有收到应答,会将之前的数据再发一份给leader,导致数据重复。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R7lOj3Lx-1650767668637)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220412165248355.png)]
14.7 代码中设置acks

props.put("acks","1");
//重试的次数 0不允许重试
props.put("retries",0);
```
十五、数据去重
在 14.6中提到的[数据重复](##14.6 数据重复分析)
-
数据传递语义:
-
至少一次(At Least Once)= (ACKS级别设置为-1)+ (分区副本大于等于2) + (ISR里应答的最小副本数量大于等于2)
生产者发送到kafka集群,集群这边至少能收到一次数据
-
最多一次(At Most Once)= Ack级别设置为0
-
-
At Least Once 可以保证数据不丢失,但是不能保证数据不重复
-
At Most Once 可以保证数据不重复,但是不能保证数据不丢失
-
精确一次(Exactly Once):对于一些比较重要的信息,比如和钱相关的数据,要求数据既不能重复,也不能丢失
kafka 0.11 版本后引入了幂等性和事务
15.1 幂等性原理
幂等性就是指:不论Producer向broker发送了多少次重复数据,broker只会持久化一条数据,保证了不重复。
精确一次(Exactly Once)=幂等性+至少一次(At Least Once)= (ACKS级别设置为-1)+ (分区副本大于等于2) + (ISR里应答的最小副本数量大于等于2)
重复数据的判断标准:具有**
- PID:kafka每次重新启动都会分配一个新的PID
- Partition:表示分区号
- Sequence Number:序列化号,是单调递增的
所以幂等性能保证的是在单个分区单会话内不重复
一旦kakfa挂掉之后再重启,还是有可能产生重复数据的。引入了事务
15.2 kafka事务原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c2lzcIcO-1650767668638)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220413110837170.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WYhoIcoW-1650767668638)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220413135201332.png)]
//指定事务的id,事务id可以随便指定,但是必须保证全局唯一
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transactionID");
//初始化事务
producer.initTransactions();
//启动事务
producer.beginTransaction();
try {
for (int i = 0; i < 100; i++) {
//这里需要三个参数,第一个:topic的名称,第二个参数:表示消息的key,第三个参数:消息具体内容
producer.send(new ProducerRecord<String, String>("tianzhuang", Integer.toString(i), "hello-kafka-" + i));
}
//提交事务
producer.commitTransaction();
} catch (Exception e) {
//中止事务
producer.abortTransaction();
}
finally {
producer.close();
}

十六、数据乱序
-
kafka在1.0版本前保证数据单分区有序
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)设置request缓存队列大小为一

-
在
kafka1.x及以后版本保证数据单分区有序条件如下
-
未开启幂等性
max.in.flight.requests.per.connection设置为1 -
开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5在kafka1.x版本后,启用幂等以后,kafka的服务器会缓存producer发来的5个request的元数据,所以无论如何都可以保证最近5个request的数据是有序的

-
十七、kafka的Broker
17.1 zookeeper 存储的kafka信息
- zookeeper中存储了哪些kafka的信息
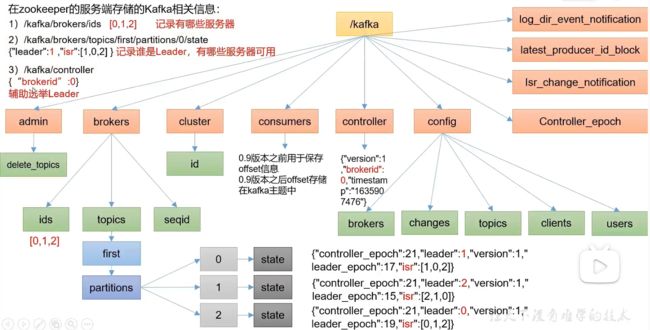
17.2 kafkaBroker整体工作流

17.2 服役新节点
-
创建新的服务器并配置环境(jdk,zookeeper,kafka)
-
配置kafka相关配置
vim server.properties[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dHSzhDYZ-1650767668638)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220413161531022.png)]
修改borker.id
- 重启集群的zookeeper服务以及kafka服务
- 执行负载均衡操作
17.3 退役旧节点 //TODO
17.4 Broker的副本
-
副本的基本信息
-
kafka副本的作用:提高数据的可靠性
-
kafka默认副本1个,生产环境为一般配置为两个,保证数据的可靠性,如果太多的副本会增加磁盘的空间,增加网络上的数据传输影响效率
-
kafka的副本分为
leader和follower,生产者只会向leader发送数据,follower向leader去同步数据。 -
kafka分区中所有的副本统称为AR
AR=ISR+OSR
OSR表示Follower与leader同步时延迟过多的副本
-
17.5 leader选举的流程
kafka集群中有一个broker的controller会被选举为Controller Leader,负责管理集群broker的上下线,所有topic分区副本的分配和leader的选举。controller的信息同步工作是依赖于zookeeper的

17.6 故障处理
-
follower故障处理细节
-
leader故障处理细节
17.7 分区副本分配
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UJzHN5hc-1650767668639)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220413190742275.png)]
17.8 手动调整分区
十八、kafka的消费者
18.1 kafka的消费方式
-
pull 拉模式
conumer采用从broker中主动拉取数据(因为不同的消费者消费速度是不一样的)
-
push 推模式
kafka没有采用这种方式,因为broker决定消息发送速率,很难适应所有消费者的消费速度
pull模式的不足之处在于如果kafka没有数据,消费者可能陷入循环中,一直拉返回数据
18.2 kafka消费者原理

18.3 kafka消费者组的原理
-
Consumer Group(CG): 由多个consumer组成。形成一个消费者组的条件,所有消费者的groupid相同- 消费者组内的每一个消费者负责消费不同分区的数据,一个分区的数据只能由一个组内消费者消费。
- 消费者组之间互不影响,所有的消费者都属于一个消费者组,在逻辑上来说,消费者组就是一个订阅者。
如果消费者组中的消费者数量超过了主题分区的数量,则有一部分消费者就会闲置,不会接受任何消息
- 消费者组之间互不影响,所有的消费者都属于某个消费者组,消费者组是逻辑上的一个订阅者。
18.4 kafka消费者组初始化原理
-
corrdinator:辅助实现消费者组的初始化和分区的分配corrdinator节点的选择=groupId的hashCode值%50(_consumer_offset的分区数量)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tUDEf68l-1650767668639)(https://gitee.com/tian-zhuang1219/pic_bed2/raw/master/pic/image-20220414140329422.png)]

18.5 消费者组详细消费流程

18.6 消费者API
-
消费一个主题
package com.tz.kafkatest.consumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.ArrayList; import java.util.Properties; /** * @Auther: devin tian * @Date: 2022/4/14 14:27 * @Description: */ public class MyConsumer { public static void main(String[] args) { //配置 Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "81.68.187.88:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName()); //配置消费者组id properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test"); //创建消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties); //订阅主题 ArrayList<String> topic = new ArrayList<>(); topic.add("tianzhuang"); kafkaConsumer.subscribe(topic); //消费数据 while (true){ ConsumerRecords<String, String> poll = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> stringStringConsumerRecord : poll) { System.out.println(stringStringConsumerRecord); } } } } -
消费一个分区(如何消费一个主题下的指定分区)
package com.tz.kafkatest.consumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.ArrayList; import java.util.Properties; /** * @Auther: devin tian * @Date: 2022/4/14 14:27 * @Description: */ public class MyConsumerForpartition { public static void main(String[] args) { //配置 Properties properties = new Properties(); //连接 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "81.68.187.88:9092"); //反序列化 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName()); //配置消费者组id properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test"); //创建消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties); //订阅主题的一个分区 ArrayList<TopicPartition> partitions = new ArrayList<>(); partitions.add(new TopicPartition("test",0)); kafkaConsumer.assign(partitions); //消费数据 while (true){ ConsumerRecords<String, String> poll = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> stringStringConsumerRecord : poll) { System.out.println(stringStringConsumerRecord); } } } }
-
18.7 offSet的默认维护位置
-
18.8 手动offSet
-
18.9 自动offSet
-
[ ]