2023年12月2日~12月8日周报(OpenFWI代码细节理解之warm-up策略、Tensorboard的使用、loss的理解等,以及OpenFWI论文初读)
目录
一、前言
二、学习情况
2.1 torch.optim.AdamW的理解
2.2 warm-up策略
2.3 Tensorboard的使用
2.4 Loss的理解
2.5 OpenFWI论文初读
三、遇到的部分问题及解决
四、总结
4.1 存在的疑惑
4.2 下周安排
一、前言
上周对OpenFWI代码中的训练与测试部分进行了抄写与理解,存在一部分疑惑尚未解决。
因此,本周的任务是完成相关细节的理解,包括warm-up策略、Tensorboard的使用、Loss的理解等,最后完成OpenFWI论文的正文部分阅读。
二、学习情况
2.1 torch.optim.AdamW的理解
Adam自2014年提出就受到广泛关注,但是很多研究者发现Adam算法的收敛性得不到保证。AdamW是在Adam的基础上加入了weight decay正则化,实现了带权重衰减的Adam优化算法。正则化是用来防止模型过拟合(泛化能力差,训练样本集准确率高,测试样本集准确率低)而采取的手段,但是Adam的代码中已经有正则化。AdamW的优点包括收敛速度快、适应性强、对于超参数的选择不敏感等。在训练深度学习模型时常常使用AdamW优化器来加速模型的收敛。
其中,lr、betas和eps与Adam优化器的参数相同,weight_ decay则是AdamW的特有参数。
class AdamW(Optimizer):
"""
Implements Adam algorithm with weight decay fix as introduced in
`Decoupled Weight Decay Regularization `__.
Parameters:
params (:obj:`Iterable[torch.nn.parameter.Parameter]`):
Iterable of parameters to optimize or dictionaries defining parameter groups.
lr (:obj:`float`, `optional`, defaults to 1e-3):
The learning rate to use.
betas (:obj:`Tuple[float,float]`, `optional`, defaults to (0.9, 0.999)):
Adam's betas parameters (b1, b2).
eps (:obj:`float`, `optional`, defaults to 1e-6):
Adam's epsilon for numerical stability.
weight_decay (:obj:`float`, `optional`, defaults to 0):
Decoupled weight decay to apply.
correct_bias (:obj:`bool`, `optional`, defaults to `True`):
Whether ot not to correct bias in Adam (for instance, in Bert TF repository they use :obj:`False`).
"""
def __init__(
self,
params: Iterable[torch.nn.parameter.Parameter],
lr: float = 1e-3, # 学习率
betas: Tuple[float, float] = (0.9, 0.999), # AdamW优化器中的两个指数衰减率,分别用于计算梯度的一阶矩估计和二阶矩估计,默认值为(0.9,0.999)
eps: float = 1e-6, # AdamW优化器中一个小常数,用于防止除以零的情况,用于控制L2正则化的强度,通常建议设置为一个小于1的值。默认值为1e-8
weight_decay: float = 0.0, # L2正则化(权重衰减)的系数,用于控制模型参数的大小。默认值为0
correct_bias: bool = True,
):
参考:当前训练神经网络最快的方式:AdamW优化算法+超级收敛 - 知乎 (zhihu.com)
2.2 warm-up策略
学习率是神经网络训练中最重要的超参数之一,Warm-up是众多学习率优化方式中的一种。
warm-up是一种学习率预热的方法,在训练开始的时候先使用一个较小的学习率训练一些epoches或者steps,使网络熟悉数据,随着训练的进行学习率慢慢变大,等到了一定程度,再修改为预先设置的学习率来进行训练,接着过了一些inter后,学习率再慢慢变小。
学习率变化:上升——平稳——下降;
选择原因:开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小。在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
具体步骤:
- 启用warm-up,设置warm up setp(一般等于epoch*inter_per_epoch)
lr = args.lr * args.world_size
# 定义优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, betas=(0.9, 0.999), weight_decay=args.weight_decay)
warmup_iters = args.lr_warmup_epochs * len(dataloader_train)
lr_milestones = [len(dataloader_train) * m for m in args.lr_milestones]
# 确定学习率调整策略
lr_scheduler = WarmupMultiStepLR(
optimizer, milestones=lr_milestones, gamma=args.lr_gamma,
warmup_iters=warmup_iters, warmup_factor=1e-5)- 当step小于warm_iters时,学习率等于基础学习率×(当前step/warm up inters),由于后者是一个小于1的数值,因此在整个warm up的过程中,学习率是一个递增的过程
- 当warm up结束后,学习率以基础学习率进行训练,再学习率开始递减
# Scheduler adopted from the original repo
# 自定义调整学习率的方式
class WarmupMultiStepLR(torch.optim.lr_scheduler._LRScheduler):
def __init__(
self,
optimizer, # 优化器
milestones, # 一个list,每一个元素代表何时调整学习率,list元素必须是递增的,如milestones=[30,80,120]
gamma=0.1, # 学习率调整倍数(更新lr的乘法因子),默认为0.1倍,即下降10倍
warmup_factor=1.0 / 3, # 初始学习率
warmup_iters=5, # 更新epoch数
warmup_method="linear", # warmup的其中一种方式
last_epoch=-1, # 上一个epoch数,该变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整。当为-1时,学习率设置为初始值。
):
# sorted()函数对所有可迭代的对象进行排序操作
if not milestones == sorted(milestones):
raise ValueError(
"Milestones should be a list of" " increasing integers. Got {}",
milestones,
)
if warmup_method not in ("constant", "linear"):
raise ValueError(
"Only 'constant' or 'linear' warmup_method accepted"
"got {}".format(warmup_method)
)
self.milestones = milestones
self.gamma = gamma
self.warmup_factor = warmup_factor
self.warmup_iters = warmup_iters
self.warmup_method = warmup_method
super(WarmupMultiStepLR, self).__init__(optimizer, last_epoch)
# 获取学习率
def get_lr(self):
warmup_factor = 1
# 根据不同的策略设置相应的warm-up学习率
if self.last_epoch < self.warmup_iters:
# constant从一个很小的学习率一下变为比较大的学习率,会导致训练误差突然增大
if self.warmup_method == "constant":
warmup_factor = self.warmup_factor
# linear避免constant的不足,线性增长
elif self.warmup_method == "linear":
alpha = float(self.last_epoch) / self.warmup_iters
warmup_factor = self.warmup_factor * (1 - alpha) + alpha
return [
base_lr *
warmup_factor *
self.gamma ** bisect_right(self.milestones, self.last_epoch)
for base_lr in self.base_lrs
]常见的warm-up方式:constant,linear和exponent
参考:
- 一文看懂学习率warmup及各主流框架实现差异 - 知乎 (zhihu.com)
- torch.optim.lr_scheduler:调整学习率-CSDN博客
- pytorch之warm-up预热学习策略_pytorch warmup_还能坚持的博客-CSDN博客
2.3 Tensorboard的使用
Tensorboard是一组可用于数据可视化的工具,包含在流行的开源机器学习库TensorFlow中,其主要功能包括:
- 可视化模型的网络架构
- 跟踪模型指标,如损失、准确性变化等
- 检查机器学习工作流程中权重、偏差和其他组件的直方图
- 显示非表格数据,包括图像、文本和音频
- 将高维嵌入投影到低维空间
使用步骤:
(1)安装Tensorboard:
本次Tensorboard在pycharm终端中下载,先激活Pytorch环境,接着输入pip install tensorboard;下载完成后,还需要安装另一个它所依赖的库pip install future。
pip install tensorboard
pip install future
下载完成后,可以通过pip list查看是否安装成功:
(2)启动Tensorboard:
- 打开Pycharm终端,输入dir查看项目当前文件夹中的文件:

- 设置路径,输入tensorboard --logdir=./runs,./runs为想要可视化数据所在的文件夹路径,接着点击网址,打开tensorboard页面
有的时候,可能主机很多人在使用,为防止端口号冲突,可以设定特别的主机端口,方法是多加一个参数:--port=,例如:
tensorboard --logdir=XXX --port=6666

Tensorboard中涉及的类:SummaryWriter(在给定目录中创建事件文件,并向其中添加摘要和事件。 该类异步更新文件内容,这允许训练程序调用方法以直接从训练循环将数据添加到文件中,而不会减慢训练速度。)
# Set up tensorboard summary writer 设置 tensorboard 摘要编写器
train_writer, val_writer = None, None
if args.tensorboard:
utils.mkdir(args.log_path) # create folder to store tensorboard logs
if not args.distributed or (args.rank == 0) and (args.local_rank == 0):
# SummaryWriter:在给定目录中创建事件文件,并向其中添加摘要和事件。
# 该类异步更新文件内容,允许训练程序调用方法以直接从训练循环将数据添加到文件中,而不会减慢训练速度。
train_writer = SummaryWriter(os.path.join(args.output_path, 'logs', 'train'))
val_writer = SummaryWriter(os.path.join(args.output_path, 'logs', 'val'))writer.add_scalar():目的是添加一个标量数据(scalar data)到summary中,用于在tensorboard中加入loss,其中常用参数有:
- tag:标签,用于描述该标量数据图的标题
- scalar_value:标签的值
- global_step:标签的x轴坐标
if writer:
writer.add_scalar('loss', loss_val, step)
writer.add_scalar('loss_g1v', loss_g1v_val, step)
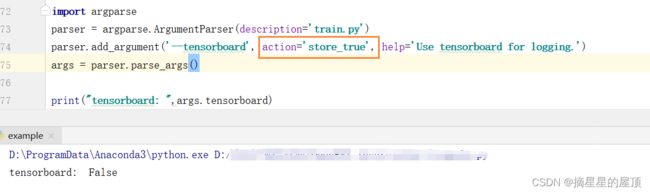
writer.add_scalar('loss_g2v', loss_g2v_val, step)store_true 是指带触发action时为真,不触发则为假。
有default值的时候,running时不声明就为默认值;没有的话,如果是store_false,则默认值是True,如果是store_true,则默认值是False。
参考:
- TensorBoard最全使用教程:看这篇就够了 - 知乎 (zhihu.com)
- 【pytorch】使用tensorboard进行可视化训练-CSDN博客
- Tensorboard的使用 ---- SummaryWriter类(pytorch版)-CSDN博客
2.4 Loss的理解
2.4.1 L1损失函数
L1损失函数也叫平均绝对值误差(MAE-mean abs error),是指预测值和真实值之间差值的绝对值。
yi是指目标值,f(xi)是指估计值。
- 缺点:梯度恒定;导数不连续;
- 优点:收敛速度必L2损失函数更快,L1可以提供更大且稳定的梯度;

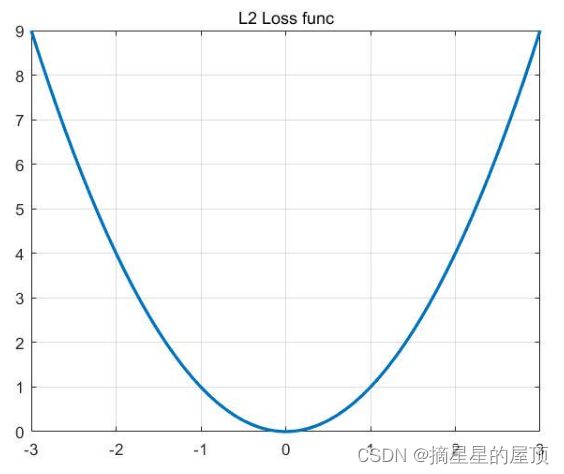
2.4.2 L2损失函数
L2损失函数也叫平均平方误差(MSE-mean square error),是指预测值和真实值之间的差值(会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和)。均方误差公式如下:
- 缺点:收敛速度比L1慢,梯度会随着预测值接近真实值而不断减小;对异常数据比L1更加敏感,这是由平方项引起的,异常数据会引起很大的损失;
- 优点:训练更容易,鲁棒性(指模型在陌生环境或者噪声干扰下依旧能够完成预期任务的能力)更好,梯度随着预测值接近真实值而不断减小,不会轻易错过极点值,但是容易陷入局部最优;导数具有封闭解,更容易进行优化和编程。
2.5 OpenFWI论文初读
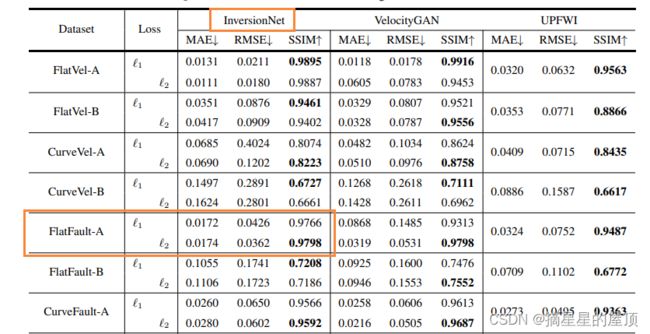
在本周完成了OpenFWI论文的初读任务,见:论文学习记录之OpenFWI(Large-scale Multi-structuralBenchmark Datasets for Full Waveform Inversion)-CSDN博客。
三、遇到的部分问题及解决
运行test.py文件遇到了如下问题:f'{funcname}() argument must be str, bytes, or ‘‘, f'os.PathLike object, not {s.__class__.__name__!
检查代码:通常是字符串两端的引号未正确匹配、成对造成的,是否有单引号、双引号或三引号没有闭合(只有开头无结尾)
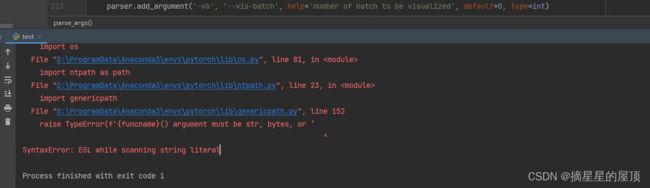
解决方式:
- ①查看genericpath.py发现存在错误:

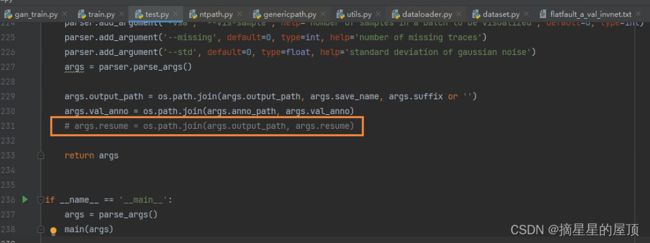
- ②注释代码:
运行成功:


四、总结
4.1 存在的疑惑
- 项目所涉及的知识点太多,感觉对很多概念一知半解,该如何解决?
- 实验室师兄师姐的项目一般会用到预热学习率吗?如果使用的话,一般采用什么策略?
- 对loss损失函数、优化器等概念需要掌握到什么程度呢?了解他们之间的区别并熟悉用法吗?
- 哪种损失函数的使用更多?根据个人项目决定吗?
4.2 下周安排
- 阅读剩下OpenFWI论文中的细节,并尝试修改部分参数,运行后对比效果;
- 打开Tensorboard,进行可视化;
- 运行完代码,查看结果;