RNN_循环神经网络_总结学习(持续更新)
目录
-
- 1、什么是RNN
- 2、RNN架构
- 3、RNN工作流程
- 4、具体操作的栗子——NLP
-
- (0)、问题介绍
- (0)、导入包
- (1)、创建句子集合(数据集)
- (2)预处理
- (3)、创建神经网络模型并实例化模型
- (4)、训练
- (5)、测试
- 5、序列预测——bicton数据集(keras)
-
- (0)、问题描述
- (1)、导入包
- (2)、加载数据
- (3)、数据预处理
- (4)、创建MLP模型
- (5)、训练
- (6)、预测
-
- a、生成测试样本
- b、测试
- (7)、MLP预测结果
- (8)、RNN模型
1、什么是RNN
- 全连接神经网络: 输入输出相互独立
存在问题:在训练时,全连接神经网络假设输入彼此独立,这只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
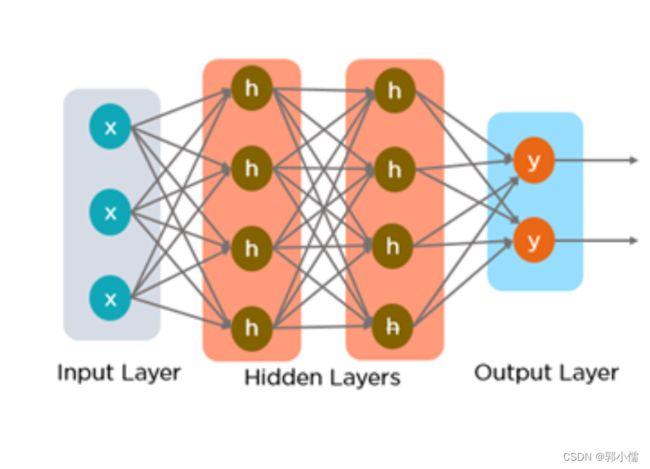
- 循环神经网络: 具有内部环状连接的人工神经网络,用于处理序列数据。其最大特点是网络中存在着环,使得信息能在网络中进行循环,实现对序列信息的存储和处理。

解决问题: RNN使用隐藏层来克服无法记住前面单词的问题
2、RNN架构

X X X:神经网络输入
U 、 V U、V U、V:权重矩阵
O O O:神经网络输出
W : W: W: 循环神经网络的隐藏层的值 S t S_{t} St不仅仅取决于当前这次的输入 X t X_{t} Xt,还取决于上一次隐藏层的值 S t − 1 S_{t-1} St−1。 W W W就是隐藏层上一次的值作为这一次的输入的权重。
循环神经网络的隐藏层的值 S t = f ( U ⋅ X t + W ⋅ S t − 1 ) S_{t}=f(U\cdot X_t+W \cdot S_{t-1}) St=f(U⋅Xt+W⋅St−1)

把上图展开:

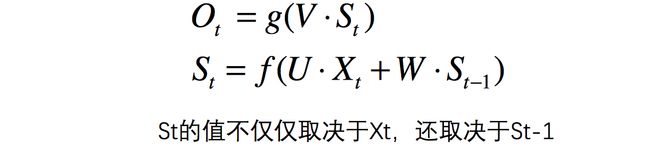
3、RNN工作流程

RNN单元在每个时间步进行计算时,都将前一个时间步的隐藏层状态和输出一起输入到单元中
4、具体操作的栗子——NLP
(0)、问题介绍
输入一个单词,预测下一个单词是什么,直到生成满足要求的句子
输入:“good”,生成有15个字符的句子
输出:“good i am fine ”
具体流程:

(0)、导入包
import torch
from torch import nn
import numpy as np
(1)、创建句子集合(数据集)
text = ['hi how are you','good i am fine','have a nice day']
chars = set(''.join(text)) # 连接所有的句子,提取其中的元素(字母,空格)
print(f'chars:{chars}')
int2char = dict(enumerate(chars)) # 创建一个字典,将每一个数字映射一个字母
print(f'int2char:{int2char}')
char2int = {char: ind for ind, char in int2char.items()} # 反过来,创建一个字典,将每一个字母映射一个数字
print(f'char2int:{char2int}')
输出:
chars:{'m', 'w', 'u', 'f', 'n', 'e', 'v', 'i', 'd', 'g', 'h', 'a', 'o', ' ', 'y', 'r', 'c'}
int2char:{0: 'm', 1: 'w', 2: 'u', 3: 'f', 4: 'n', 5: 'e', 6: 'v', 7: 'i', 8: 'd', 9: 'g', 10: 'h', 11: 'a', 12: 'o', 13: ' ', 14: 'y', 15: 'r', 16: 'c'}
char2int:{'m': 0, 'w': 1, 'u': 2, 'f': 3, 'n': 4, 'e': 5, 'v': 6, 'i': 7, 'd': 8, 'g': 9, 'h': 10, 'a': 11, 'o': 12, ' ': 13, 'y': 14, 'r': 15, 'c': 16}
(2)预处理
- **padding:**把所有句子填充成一样的长度
- splitting:把句子划分为input和label
- input:输入的句子应该不包括最后一个字母
- label:数入句子对应的正确答案(但要保证句子长度一致,所以省略第一个字母)
- one-hot encoding: 为句子中的每一个字符都赋予一个唯一的向量。
- 单词“GOOD”:有三个字符
- G: [ 1 , 0 , 0 ] [1,0,0] [1,0,0]
- O: [ 0 , 1 , 0 ] [0,1,0] [0,1,0]
- D: [ 0 , 0 , 1 ] [0,0,1] [0,0,1]
- 单词“GOOD”:有三个字符
# 2、预处理:把所有句子填充成一样的长度;将句子划分为input/label;热编码(把每个句子都变成一个独特的向量形式)
maxlen = len(max(text,key=len)) # 最长的句子的长度
## 填充 padding:让所有的句子一样长
for i in range(len(text)):
while len(text[i])<maxlen:
text[i] +=' '
## splitting into input/labels
input_seq = []
target_seq = []
for i in range(len(text)):
# 输入的句子应该不包括最后一个字母
input_seq.append(text[i][:-1])
# 输入句子对应的正确答案(但要保证句子长度一致,所以省略第一个字母)
target_seq.append(text[i][1:])
print(f"input_seq:{input_seq[i]}\ntarget_seq:{target_seq[i]}")
## 将文字序列转成数字序列
for i in range(len(text)):
input_seq[i] = [char2int[character] for character in input_seq[i]]
target_seq[i] = [char2int[character] for character in target_seq[i]]
print(f"将文字序列转成数字序列:input_seq:{input_seq[0]}\ntarget_seq:{target_seq[0]}")
## one-hot encoding
dict_size = len(char2int) # 字母的个数:决定one-hot向量的size
seq_len = maxlen - 1 # 句子的长度:-1是因为我们没有算最后一个字母(被移除了嘛)
batch_size = len(text) # 句子的数量
def one_hot_encode(sequence, dict_size, seq_len, batch_size):
# 创建具有所需输出形状的多维零数组
features = np.zeros((batch_size, seq_len, dict_size), dtype=np.float32)
# 将句子对应字母的位置替换为1
for i in range(batch_size):
for j in range(seq_len):
features[i, j, sequence[i][j]] = 1
return features
## 将输入的句子转成一个 one-hot vector
input_seq = one_hot_encode(input_seq, dict_size, seq_len, batch_size)
print(f"热编码后的输入序列:{input_seq[0]}")
## 将数据转成tensor类型
input_seq = torch.from_numpy(input_seq)
target_seq = torch.Tensor(target_seq)
输出:
input_seq:hi how are you
target_seq:i how are you
input_seq:good i am fine
target_seq:ood i am fine
input_seq:have a nice da
target_seq:ave a nice day
将文字序列转成数字序列:input_seq:[1, 11, 5, 1, 16, 0, 5, 13, 2, 8, 5, 12, 16, 7]
target_seq:[11, 5, 1, 16, 0, 5, 13, 2, 8, 5, 12, 16, 7, 5]
热编码后的输入序列:[[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
plus:检查GPU or CPU
is_cuda = torch.cuda.is_available()
if is_cuda: # GPU
device = torch.device("cuda")
print("使用GPU")
else:
device = torch.device("cpu")
print("使用CPU")
(3)、创建神经网络模型并实例化模型
class rnn_model(nn.Module):
def __init__(self, input_size, output_size, hidden_dim, n_layers):
super(rnn_model, self).__init__()
# 定义神经网络参数
self.hidden_dim = hidden_dim
self.n_layers = n_layers
# 定义层
## RNN层
self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True)
## 全连接层
self.fc = nn.Linear(hidden_dim, output_size)
def forward(self, x):
batch_size = x.size(0) # 句子的第0维是batch的数量
hidden = self.init_hidden(batch_size) # 初始化第一个隐藏层状态
out, hidden = self.rnn(x, hidden) # 将input和hidden输入到模型中得到下一时刻的输出和hidden
out = out.contiguous().view(-1, self.hidden_dim) # 将输出数据变化为可以作为全连接网络的输入的形状
out = self.fc(out)
return out, hidden
def init_hidden(self, batch_size):
# 生成第一个隐藏层状态,我们将在前向传递中使用它
hidden = torch.zeros(self.n_layers, batch_size, self.hidden_dim)
return hidden
model = rnn_model(input_size=dict_size, output_size=dict_size, hidden_dim=12,n_layers=1)
model.to(device)
(4)、训练
epochs = 100
lr = 0.01
criterion = nn.CrossEntropyLoss() # 定义随时函数
optimizer = torch.optim.Adam(model.parameters(),lr=lr) # 定义优化器
# 4、训练部分
for epoch in range(1,epochs+1):
optimizer.zero_grad() # 清除上一个epoch的梯度
input_seq.to(device)
output, hidden = model(input_seq)
loss = criterion(output, target_seq.view(-1).long())
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
if epoch%10 == 0:
print(f"Epoch:{epoch}/{epochs}\tloss:{round(loss.item(), 4)}")
Epoch:10/100 loss:2.3846
Epoch:20/100 loss:1.9993
Epoch:30/100 loss:1.6436
Epoch:40/100 loss:1.2811
Epoch:50/100 loss:0.9555
Epoch:60/100 loss:0.6969
Epoch:70/100 loss:0.4983
Epoch:80/100 loss:0.3656
Epoch:90/100 loss:0.277
Epoch:100/100 loss:0.2173
(5)、测试
def predict(model, character):
# 把输入的单词也转换成热编码向量
character = np.array([[char2int[c] for c in character]])
character = one_hot_encode(character, dict_size, character.shape[1], 1)
character = torch.from_numpy(character)
character.to(device)
# 将单词输入模型中
out, hidden = model(character)
# 按照列计算每一个字符的比重
prob = nn.functional.softmax(out[-1], dim=0).data
char_ind = torch.max(prob, dim=0)[1].item()
out_char = int2char[char_ind]
print(f"输出的字符中概率最大的字符:{out_char}")
return int2char[char_ind], hidden
# 输入模型和想要的句子的长度和起始的单词,返回生成的句子
def sample(model, out_len, start='hey'):
model.eval() # 评估模式
start = start.lower() # 小写
# 把输入的单词拆分成字母
chars = [ch for ch in start]
size = out_len - len(chars)
for i in range(size):
char, h =predict(model, chars)
chars.append(char)
return ''.join(chars)
predict_seq = sample(model, 15, 'good')
print(f"预测的句子:{predict_seq}")
输出的字符中概率最大的字符:
输出的字符中概率最大的字符:i
输出的字符中概率最大的字符:
输出的字符中概率最大的字符:a
输出的字符中概率最大的字符:m
输出的字符中概率最大的字符:
输出的字符中概率最大的字符:f
输出的字符中概率最大的字符:i
输出的字符中概率最大的字符:n
输出的字符中概率最大的字符:e
输出的字符中概率最大的字符:
预测的句子:good i am fine
over,
5、序列预测——bicton数据集(keras)
(0)、问题描述
使用Bicton数据集,对close数据进行预测,使用60个数据点预测第61个数据点。
下载数据集:Bitcoin Historical Data
csv文件中:

(1)、导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
from sklearn.metrics import mean_absolute_error
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout,Flatten
warnings.filterwarnings("ignore")
(2)、加载数据
bit_data = pd.read_csv("bitstampUSD_1-min_data_2012-01-01_to_2021-03-31.csv")
(3)、数据预处理
- 将时间戳转成日期形式
bit_data["date"]=pd.to_datetime(bit_data["Timestamp"],unit="s").dt.date
- 将数据按照日期分组(groupby)
group=bit_data.groupby("date")
data=group["Close"].mean() # 得到全部日期的close的平均值->shape:(3376,)
更多groupby知识在:Python学习
- 划分训练集和测试集(最后60行)
- data:(3376,)
- close_train:(3316,)
- close_test:(60,)
close_train=data.iloc[:len(data)-60]
close_test=data.iloc[len(close_train):]
close_train=np.array(close_train)
close_train=close_train.reshape(close_train.shape[0],1) # (3316, 1)
- 将close值归一化在0-1之间(避免出现较大的值)
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler(feature_range=(0,1))
close_scaled=scaler.fit_transform(close_train)
- 选择 60 个数据点作为 x-train,选择第 61 个数据点作为 y-train
timestep=60
x_train=[]
y_train=[]
for i in range(timestep,close_scaled.shape[0]):
x_train.append(close_scaled[i-timestep:i,0])
y_train.append(close_scaled[i,0])
print(np.array(x_train).shape) # (3256, 60)
print(np.array(y_train).shape) # (3256,)
- 形状转变
x_train,y_train=np.array(x_train),np.array(y_train)
x_train=x_train.reshape(x_train.shape[0],x_train.shape[1],1) #reshaped for RNN
print("x-train-shape= ",x_train.shape) # x-train-shape= (3256, 60, 1)
print("y-train-shape= ",y_train.shape) # y-train-shape= (3256,)
(4)、创建MLP模型
使用keras的sequential()创建神经网络模型
model = Sequential()
model.add(Dense(56, input_shape=(x_train.shape[1],1), activation='relu')) # (60,1)->(56,1)
model.add(Dense(32, activation='relu')) # (56,1)->(32,1)
model.add(Flatten()) # 数据从第0维展开:(32,)
model.add(Dense(1)) # (32,)->(1,)
model.compile(optimizer="adam",loss="mean_squared_error")
(5)、训练
model.fit(x_train,y_train,epochs=50,batch_size=64)

(6)、预测
a、生成测试样本

inputs=data[len(data)-len(close_test)-timestep:]
inputs=inputs.values.reshape(-1,1)
inputs=scaler.transform(inputs)
x_test=[]
for i in range(timestep,inputs.shape[0]):
x_test.append(inputs[i-timestep:i,0])
x_test=np.array(x_test)
x_test=x_test.reshape(x_test.shape[0],x_test.shape[1],1)
b、测试
predicted_data=model.predict(x_test) # 预测的第61个数据(60,1)
predicted_data=scaler.inverse_transform(predicted_data)
data_test=np.array(close_test) # 真实的第61个数据 (60,1)
data_test=data_test.reshape(len(data_test),1)
(7)、MLP预测结果
plt.figure(figsize=(8,4), dpi=80, facecolor='w', edgecolor='k')
plt.plot(data_test,color="r",label="true result")
plt.plot(predicted_data,color="b",label="predicted result")
plt.legend()
plt.xlabel("Time(60 days)")
plt.ylabel("Values")
plt.grid(True)
plt.show()

这是MLP的结果图,可以看到误差还是很大的,下面把模型改成RNN进行查看:
(8)、RNN模型
- 模型
reg=Sequential()
reg.add(SimpleRNN(128,activation="relu",return_sequences=True,input_shape=(x_train.shape[1],1)))
reg.add(Dropout(0.25))
reg.add(SimpleRNN(256,activation="relu",return_sequences=True))
reg.add(Dropout(0.25))
reg.add(SimpleRNN(512,activation="relu",return_sequences=True))
reg.add(Dropout(0.35))
reg.add(Flatten())
reg.add(Dense(1))
reg.compile(optimizer="adam",loss="mean_squared_error")
reg.fit(x_train,y_train,epochs=50,batch_size=64)
- 模型保存和加载
save_path = 'rnn.h5'
reg.save(save_path)
from keras.models import load_model
save_path = 'rnn.h5'
reg= load_model(save_path)
- 预测结果:

结果仍然不令人满意。这是由于信息的衰落(梯度消失),后续使用lstm、gru解决这个问题。
参考链接:
1、循环神经网络RNN完全解析:从基础理论到PyTorch实战
2、一文搞懂RNN(循环神经网络)基础篇
3、A Beginner’s Guide on Recurrent Neural Networks with PyTorch