使用自监督对比学习模型SimCLR完成图像分类任务:pytorch代码详解
文章目录
- 一、定义有监督和无监督部分网络结构和损失函数
-
- 1. 1 任务分解
- 1.2 代码
- 1.3 代码详解
-
- 1.3.1 SimCLRStage1
- 1.3.2 SimCLRStage2
- 1.3.3 loss function
- 二、配置文件config.py
-
- 2.1 代码
- 2.2 解释
- 三、无监督学习数据加载loaddataset.py
-
- 3.1 代码
- 3.2 代码详解
-
- 3.2.1 重写__getitem__方法
- 3.2.2 main方法
- 四、无监督训练:trainstage1.py
-
- 4.1 代码
- 4.2 代码详解
-
- 4.2.1 设置可用GPU
- 4.2.2 加载数据集
- 4.2.3 创建训练模型损失函数和优化器
- 4.2.4 保存训练过程文件
- 4.2.5 使用for循环加载每个batch的训练过程
- 4.2.6 设置命令行参数
- 五、有监督训练阶段:trainstage2.py
-
- 5.1 代码
- 5.2 代码详解
-
- 5.2.1 加载数据集
- 5.2.2 创建有监督模块
- 5.2.3 训练和验证的主要循环
- ps:什么是top-k评估标准?
- 六、训练并查看过程
-
- 6.1 代码
- 6.2 代码详解
- 七、验证集评估:eval.py
-
- 7.1 代码
- 7.2 代码详解
-
- 7.2.1 加载评估数据集
- 7.2.2 创建分类器模型
- 7.2.3 验证
- 7.2.4 main
- 八、自定义图片测试
-
- 8.1 代码
- 8.2 代码详解
-
- 8.2.1 创建测试集并且获取图像
- 8.2.2 对图像进行预处理
- 8.2.3 创建分类模型
- 8.2.4 main
代码来自:SimCLR图像分类——pytorch复现
SimCLR框架: SimCLR框架解析
一、定义有监督和无监督部分网络结构和损失函数
1. 1 任务分解
无监督部分: 网络特征提取采用resnet50,将输入层进行更改,并去掉池化层及全连接层。之后将特征图平坦化,并依次进行全连接、批次标准化、relu激活、全连接,得到输出特征。
有监督部分: 下游分类任务,使用无监督学习网络的特征提取层及参数,之后由一个全连接层得到分类输出。
损失函数: 最小化正样本之间的相似性与负样本之间的相似性之间的差异,从而使得正样本更接近,负样本更远离。
下游任务就是把经过无监督部分encoder提取到的特征拿出来,再加一个全连接层进行分类的输出
论文用ResNet-50结构作为卷积网络encoder,得到一个1*2048的表示
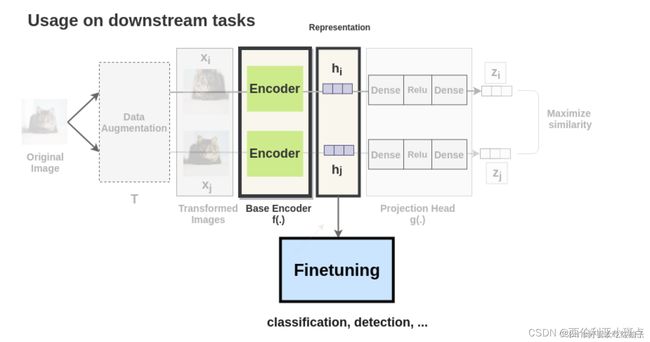
1.2 代码
# net.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models.resnet import resnet50
# stage one ,unsupervised learning
class SimCLRStage1(nn.Module):
def __init__(self, feature_dim=128):
super(SimCLRStage1, self).__init__()
self.f = []
for name, module in resnet50().named_children():
if name == 'conv1':
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
self.f.append(module)
# encoder
self.f = nn.Sequential(*self.f)
# projection head
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Linear(512, feature_dim, bias=True))
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
# stage two ,supervised learning
class SimCLRStage2(torch.nn.Module):
def __init__(self, num_class):
super(SimCLRStage2, self).__init__()
# encoder
self.f = SimCLRStage1().f
# classifier
self.fc = nn.Linear(2048, num_class, bias=True)
for param in self.f.parameters():
param.requires_grad = False
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.fc(feature)
return out
class Loss(torch.nn.Module):
def __init__(self):
super(Loss,self).__init__()
def forward(self,out_1,out_2,batch_size,temperature=0.5):
# [2*B, D]
out = torch.cat([out_1, out_2], dim=0)
# [2*B, 2*B]
sim_matrix = torch.exp(torch.mm(out, out.t().contiguous()) / temperature)
mask = (torch.ones_like(sim_matrix) - torch.eye(2 * batch_size, device=sim_matrix.device)).bool()
# [2*B, 2*B-1]
sim_matrix = sim_matrix.masked_select(mask).view(2 * batch_size, -1)
# 分子: *为对应位置相乘,也是点积
# compute loss
pos_sim = torch.exp(torch.sum(out_1 * out_2, dim=-1) / temperature)
# [2*B]
pos_sim = torch.cat([pos_sim, pos_sim], dim=0)
return (- torch.log(pos_sim / sim_matrix.sum(dim=-1))).mean()
if __name__=="__main__":
for name, module in resnet50().named_children():
print(name,module)
1.3 代码详解
1.3.1 SimCLRStage1
- class SimCLRStage1
定义了一个名为SimCLRStage1的类,继承自nn.Module。该类用于实现自监督学习的第一阶段。
class SimCLRStage1(nn.Module):
def __init__(self, feature_dim=128):
super(SimCLRStage1, self).__init__()
self.f = []
for name, module in resnet50().named_children():
if name == 'conv1':
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
self.f.append(module)
# encoder
self.f = nn.Sequential(*self.f)
# projection head
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Linear(512, feature_dim, bias=True))
在构造函数__init__中,首先通过resnet50().named_children()迭代遍历resnet50模型的所有子模块。如果当前子模块的名称为’conv1’,则将其替换为一个新的nn.Conv2d模块,用于处理输入图像的通道数调整。然后,将除了nn.Linear和nn.MaxPool2d之外的所有子模块存储在列表self.f中,作为编码器的一部分。接下来,通过nn.Sequential将列表中的子模块连接成一个序列,并将其存储在self.f中。然后,定义了一个投影头(projection head),用于将编码器输出的特征映射到一个更低维度的空间。投影头由两个线性层和一个ReLU激活函数组成,最后输出的特征维度为feature_dim。
- 前向传播forward函数
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
这个方法定义了前向传播的过程。输入x首先经过编码器self.f的处理,然后通过torch.flatten将特征张量展平为二维形状。接着,将展平后的特征张量输入至投影头self.g,得到投影后的特征表示out。最后,使用F.normalize对特征进行标准化,并返回编码器输出的标准化特征feature和投影头输出的标准化特征out。
1.3.2 SimCLRStage2
- class SimCLRStage2
这段代码定义了一个名为SimCLRStage2的类,继承自nn.Module。该类用于实现自监督学习的第二阶段,即在第一阶段得到的特征基础上进行有监督学习。
class SimCLRStage2(torch.nn.Module):
def __init__(self, num_class):
super(SimCLRStage2, self).__init__()
# encoder
self.f = SimCLRStage1().f
# classifier
self.fc = nn.Linear(2048, num_class, bias=True)
for param in self.f.parameters():
param.requires_grad = False
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.fc(feature)
return out
在构造函数__init______中,首先通过SimCLRStage1().f获取第一阶段的编码器self.f,然后定义了一个线性分类器self.fc,用于将编码器输出的特征映射到类别空间中。在构造函数的最后,将编码器的参数设置为不可训练,即requires_grad = False。
- 前向传播forward函数
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.fc(feature)
return out
这个方法定义了前向传播的过程。输入x首先经过编码器self.f的处理,然后通过torch.flatten将特征张量展平为二维形状。接着,将展平后的特征张量输入至线性分类器self.fc,得到分类结果out。最后,返回分类结果out。
1.3.3 loss function
SimCLR使用了一种叫做 NT-Xent loss 的损失函数,全称 Normalised Temperature-Scaled Entropy Loss。
def forward(self, out_1, out_2, batch_size, temperature=0.5):
# 拼接特征表示
out = torch.cat([out_1, out_2], dim=0)
# 计算相似性矩阵
sim_matrix = torch.exp(torch.mm(out, out.t().contiguous()) / temperature)
# 创建掩码矩阵
mask = (torch.ones_like(sim_matrix) - torch.eye(2 * batch_size, device=sim_matrix.device)).bool()
# 提取相似性矩阵中的有效元素
sim_matrix = sim_matrix.masked_select(mask).view(2 * batch_size, -1)
# 计算分子部分的相似性
pos_sim = torch.exp(torch.sum(out_1 * out_2, dim=-1) / temperature)
pos_sim = torch.cat([pos_sim, pos_sim], dim=0)
# 计算损失函数
loss = (-torch.log(pos_sim / sim_matrix.sum(dim=-1))).mean()
return loss
- out_1和out_2是来自模型的两个特征表示,其形状为[batch_size, feature_dim]。
- out通过将out_1和out_2在第0维度进行拼接而得到,形状为[2 * batch_size, feature_dim]。
- torch.mm(out, out.t().contiguous())计算out与其转置矩阵的乘积,得到一个相似性矩阵。为了保证计算的正确性,需要调用.contiguous()方法来确保out在内存中是连续存储的。
- 相似性矩阵中的元素通过除以温度参数temperature进行归一化,并使用torch.exp进行指数运算,得到归一化后的相似性矩阵sim_matrix。
- 接下来,创建一个掩码矩阵mask,其形状与相似性矩阵相同。掩码矩阵的对角线元素为0,其他元素为1,用于排除相似性矩阵中每个特征与自身的相似性。
- 使用mask对相似性矩阵进行掩码操作,提取出有效的相似性值,并将其形状调整为[2 * batch_size, 2 * batch_size - 1],其中每一行表示一个特征与其他特征的相似性。
- 使用torch.sum(out_1 * out_2, dim=-1)计算out_1和out_2之间的点积相似性,然后通过除以温度参数temperature进行归一化,并使用torch.exp进行指数运算,得到pos_sim。
- pos_sim通过在第0维度进行拼接而得到一个大小为[2 * batch_size]的张量,用于与相似性矩阵中的相似性进行比较。
- 计算损失函数的公式为:-torch.log(pos_sim / sim_matrix.sum(dim=-1)).mean()。其中,分子部分为pos_sim,分母部分为相似性矩阵中所有相似性的和,并进行取负对数和平均操作。
- 最后,返回计算得到的损失值。
二、配置文件config.py
配置项定义了训练和测试过程中的一些参数和数据预处理操作,使得代码更加灵活和可配置。可以在其他代码中导入这些配置项,并根据需要进行调整和使用。
2.1 代码
# config.py
import os
from torchvision import transforms
# use_gpu是一个布尔值,表示是否使用GPU进行训练。
# gpu_name是一个整数,表示使用的GPU设备的编号。
use_gpu=True
gpu_name=1
# pre_model是一个字符串,表示预训练模型的路径。
# os.path.join('pth','model.pth')用于将两个路径部分拼接成完整的路径。在这个例子中,预训练模型的路径为pth/model.pth。
pre_model=os.path.join('pth','model.pth')
# save_path是一个字符串,表示保存模型文件的路径。
# 在这个例子中,模型文件将保存在pth文件夹中
save_path="pth"
train_transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
2.2 解释
train_transform是一个torchvision.transforms.Compose对象,用于定义训练数据的预处理操作。
在这个例子中,预处理操作按顺序包括:随机裁剪到32x32大小、随机水平翻转(概率为0.5)、随机应用颜色抖动(概率为0.8)、随机将图像转为灰度图像(概率为0.2)、将图像转为张量、以及图像归一化操作。
test_transform与train_transform类似,但只包含将图像转为张量和图像归一化操作,用于对测试数据进行预处理。
三、无监督学习数据加载loaddataset.py
使用CIFAR-10数据集,一共包含10个类别的RGB彩色图片, 图片的尺寸为32×32,数据集中一共有50000张训练图片片和10000张测试图片。
3.1 代码
loaddataset.py : 自定义的数据集类PreDataset,继承自torchvision.datasets.CIFAR10。
# loaddataset.py
from torchvision.datasets import CIFAR10
from PIL import Image
class PreDataset(CIFAR10):
def __getitem__(self, item):
img,target=self.data[item],self.targets[item]
img = Image.fromarray(img)
if self.transform is not None:
imgL = self.transform(img)
imgR = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return imgL, imgR, target
if __name__=="__main__":
import config
train_data = PreDataset(root='dataset', train=True, transform=config.train_transform, download=True)
print(train_data[0])
3.2 代码详解
3.2.1 重写__getitem__方法
class PreDataset(CIFAR10):
def __getitem__(self, item):
img,target=self.data[item],self.targets[item]
img = Image.fromarray(img)
if self.transform is not None:
imgL = self.transform(img)
imgR = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return imgL, imgR, target
在PreDataset中,重写了__getitem__方法。该方法在通过下标索引获取样本时被调用。在这里,它首先获取原始图像数据self.data[item]和对应的标签self.targets[item]。
然后,使用PIL.Image.fromarray将原始图像数据转换为PIL图像对象img。
接下来,如果self.transform不为None,表示在创建数据集对象时传入了数据预处理操作,那么将对图像进行预处理操作。这里的预处理操作应用于两个相同的图像,分别存储在imgL和imgR中。这样设计的目的是为了后续的对比学习任务,使用两个相同的图像进行训练。
最后,如果self.target_transform不为None,表示在创建数据集对象时传入了目标标签的预处理操作,那么将对标签进行预处理。
最后,返回imgL、imgR和target作为样本的内容。
3.2.2 main方法
if __name__=="__main__":
import config
train_data = PreDataset(root='dataset', train=True, transform=config.train_transform, download=True)
print(train_data[0])
在if name==“main”:的条件下,导入了之前定义的config.py配置文件。然后,创建了一个PreDataset对象train_data,传入了相关参数,包括数据集的根目录root、是否是训练集train、以及数据预处理操作transform等。最后,打印了第一个样本的内容。
这段代码的作用是定义了一个自定义的数据集类PreDataset,并在主函数中示例化该类对象,用于加载和处理数据集。通过重写__getitem__方法,可以实现对图像和标签的预处理操作,并返回预处理后的样本。
四、无监督训练:trainstage1.py
通过使用自监督学习方法(SimCLR)来训练一个模型。它加载训练数据集,定义模型、损失函数和优化器,然后通过循环迭代训练数据批次来更新模型参数。训练过程中的损失值被记录并保存到文件中。
4.1 代码
# trainstage1.py
import torch,argparse,os
import net,config,loaddataset
# train stage one
def train(args):
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
# 每次训练计算图改动较小使用,在开始前选取较优的基础算法(比如选择一种当前高效的卷积算法)
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
print("current deveice:", DEVICE)
train_dataset=loaddataset.PreDataset(root='dataset', train=True, transform=config.train_transform, download=True)
train_data=torch.utils.data.DataLoader(train_dataset,batch_size=args.batch_size, shuffle=True, num_workers=16 , drop_last=True)
model =net.SimCLRStage1().to(DEVICE)
lossLR=net.Loss().to(DEVICE)
optimizer=torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-6)
os.makedirs(config.save_path, exist_ok=True)
for epoch in range(1,args.max_epoch+1):
model.train()
total_loss = 0
for batch,(imgL,imgR,labels) in enumerate(train_data):
imgL,imgR,labels=imgL.to(DEVICE),imgR.to(DEVICE),labels.to(DEVICE)
_, pre_L=model(imgL)
_, pre_R=model(imgR)
loss=lossLR(pre_L,pre_R,args.batch_size)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("epoch", epoch, "batch", batch, "loss:", loss.detach().item())
total_loss += loss.detach().item()
print("epoch loss:",total_loss/len(train_dataset)*args.batch_size)
with open(os.path.join(config.save_path, "stage1_loss.txt"), "a") as f:
f.write(str(total_loss/len(train_dataset)*args.batch_size) + " ")
if epoch % 5==0:
torch.save(model.state_dict(), os.path.join(config.save_path, 'model_stage1_epoch' + str(epoch) + '.pth'))
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Train SimCLR')
parser.add_argument('--batch_size', default=200, type=int, help='')
parser.add_argument('--max_epoch', default=1000, type=int, help='')
args = parser.parse_args()
train(args)
4.2 代码详解
4.2.1 设置可用GPU
def train(args):
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
print("current deveice:", DEVICE)
这是定义了一个名为train的函数。它接受一个参数args,该参数是通过命令行解析得到的训练参数。
在函数内部,首先检查是否可用GPU并且配置文件中设置了使用GPU(config.use_gpu)。如果满足条件,则将DEVICE设备设置为可用的GPU设备。同时,通过torch.backends.cudnn.benchmark = True设置启用CuDNN自动寻找最适合当前硬件的卷积算法来提高性能。如果不满足条件,将DEVICE设备设置为CPU设备。
4.2.2 加载数据集
train_dataset=loaddataset.PreDataset(root='dataset', train=True, transform=config.train_transform, download=True)
train_data=torch.utils.data.DataLoader(train_dataset,batch_size=args.batch_size, shuffle=True, num_workers=16 , drop_last=True)
这里创建了一个训练数据集对象train_dataset,通过调用loaddataset.PreDataset类来加载数据集。 传入的参数包括数据集的根目录root、是否是训练集train、数据预处理操作transform等。
然后,使用torch.utils.data.DataLoader将训练数据集封装成一个可迭代的数据加载器train_data。 设置了批次大小batch_size、是否打乱数据shuffle、使用的线程数num_workers等参数。
4.2.3 创建训练模型损失函数和优化器
model = net.SimCLRStage1().to(DEVICE)
lossLR = net.Loss().to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-6)
创建无监督SimCLR模型model, 通过调用net.SimCLRStage1类来实例化。模型被移动到之前确定的设备DEVICE上进行训练。
另外,创建损失函数lossLR, 通过调用net.Loss类来实例化。损失函数也被移动到设备DEVICE上。
最后,定义优化器optimizer,使用Adam优化器来优化模型的参数。 将模型参数传递给优化器,并设置学习率lr和权重衰减weight_decay等参数。
4.2.4 保存训练过程文件
os.makedirs(config.save_path, exist_ok=True)
这行代码用于创建保存模型和训练过程中的结果的文件夹。
config.save_path是在config模块中定义的保存路径。
4.2.5 使用for循环加载每个batch的训练过程
for epoch in range(1,args.max_epoch+1):
model.train()
total_loss = 0
for batch,(imgL,imgR,labels) in enumerate(train_data):
imgL,imgR,labels=imgL.to(DEVICE),imgR.to(DEVICE),labels.to(DEVICE)
_, pre_L=model(imgL)
_, pre_R=model(imgR)
loss=lossLR(pre_L,pre_R,args.batch_size)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("epoch", epoch, "batch", batch, "loss:", loss.detach().item())
total_loss += loss.detach().item()
print("epoch loss:",total_loss/len(train_dataset)*args.batch_size)
# 把过程数据写入日志文件stage1_loss.txt中
with open(os.path.join(config.save_path, "stage1_loss.txt"), "a") as f:
f.write(str(total_loss/len(train_dataset)*args.batch_size) + " ")
if epoch % 5==0:
torch.save(model.state_dict(), os.path.join(config.save_path, 'model_stage1_epoch' + str(epoch) + '.pth'))
这是训练的主循环。对于每个训练周期(epoch),模型被设置为训练模式(model.train())。然后,使用enumerate(train_data)迭代训练数据加载器中的批次。
在每个批次中,将数据移动到设备DEVICE上。通过模型model对左右图像进行前向传播, 得到预测结果pre_L和pre_R。然后,计算损失值loss,通过调用lossLR损失函数,传递预测结果和批次大小args.batch_size作为参数。
接下来,执行优化步骤。首先,将优化器的梯度缓冲区清零(optimizer.zero_grad())。然后,计算损失值相对于模型参数的梯度(loss.backward())。最后,调用优化器的step()方法来更新模型的参数。
在每个批次结束后,打印出当前训练周期、批次和损失值。累计总损失值,以便计算每个训练周期的平均损失值。
完成一个训练周期后,打印出该周期的平均损失值。然后,将平均损失值写入保存路径下的stage1_loss.txt文件中。
如果当前周期是5的倍数,将模型的状态字典保存到文件中,文件名包含训练周期的信息。
4.2.6 设置命令行参数
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Train SimCLR')
parser.add_argument('--batch_size', default=200, type=int, help='')
parser.add_argument('--max_epoch', default=1000, type=int, help='')
args = parser.parse_args()
train(args)
在这个代码块中,首先创建了一个argparse.ArgumentParser对象,用于解析命令行参数。description参数是一个描述性的字符串,用于生成帮助文档。然后,通过add_argument方法添加了两个命令行参数:–batch_size和–max_epoch。default参数指定了参数的默认值,type参数指定了参数的类型,help参数是一个可选的帮助文本,用于描述参数的作用。这样就定义了两个可通过命令行指定的参数。
接下来,调用parser.parse_args()方法解析命令行参数,并将解析结果赋值给变量args。这样就可以通过args.batch_size和args.max_epoch访问命令行指定的参数值。
最后,调用train(args)函数,传递解析后的参数进行训练。这样就将训练过程包装在了一个可执行的脚本中,可以通过命令行指定参数来运行训练过程。
五、有监督训练阶段:trainstage2.py
5.1 代码
# trainstage2.py
import torch,argparse,os
import net,config
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
# train stage two
def train(args):
# 检查是否可用GPU,并根据配置文件中的use_gpu参数和GPU的可用性确定设备类型。如果可用,还会对CUDA加速进行一些配置。
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(2)) #config.gpu_name
# 每次训练计算图改动较小使用,在开始前选取较优的基础算法(比如选择一种当前高效的卷积算法)
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
print("current deveice:", DEVICE)
# load dataset for train and eval
train_dataset = CIFAR10(root='dataset', train=True, transform=config.train_transform, download=True)
train_data = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=16, pin_memory=True)
eval_dataset = CIFAR10(root='dataset', train=False, transform=config.test_transform, download=True)
eval_data = DataLoader(eval_dataset, batch_size=args.batch_size, shuffle=False, num_workers=16, pin_memory=True)
model =net.SimCLRStage2(num_class=len(train_dataset.classes)).to(DEVICE)
# 加载预训练模型的参数到模型中,使用torch.load函数加载参数文件,并通过model.load_state_dict方法将参数加载到模型中。
# args.pre_model是命令行参数--pre_model指定的预训练模型的路径。
model.load_state_dict(torch.load(args.pre_model, map_location='cpu'),strict=False)
# 损失函数定义,使用交叉熵损失
loss_criterion = torch.nn.CrossEntropyLoss()
# 优化器定义
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-3, weight_decay=1e-6)
# 创建一个用于保存模型和结果的文件夹
os.makedirs(config.save_path, exist_ok=True)
for epoch in range(1,args.max_epoch+1):
model.train()
total_loss=0
for batch, (data, target) in enumerate(train_data):
data, target = data.to(DEVICE), target.to(DEVICE)
pred = model(data)
loss = loss_criterion(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print("epoch",epoch,"loss:", total_loss / len(train_dataset)*args.batch_size)
with open(os.path.join(config.save_path, "stage2_loss.txt"), "a") as f:
f.write(str(total_loss / len(train_dataset)*args.batch_size) + " ")
if epoch % 5==0:
torch.save(model.state_dict(), os.path.join(config.save_path, 'model_stage2_epoch' + str(epoch) + '.pth'))
model.eval()
with torch.no_grad():
print("batch", " " * 1, "top1 acc", " " * 1, "top5 acc")
total_loss, total_correct_1, total_correct_5, total_num = 0.0, 0.0, 0.0, 0
for batch, (data, target) in enumerate(train_data):
data, target = data.to(DEVICE), target.to(DEVICE)
pred = model(data)
total_num += data.size(0)
prediction = torch.argsort(pred, dim=-1, descending=True)
top1_acc = torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
top5_acc = torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
total_correct_1 += top1_acc
total_correct_5 += top5_acc
print(" {:02} ".format(batch + 1), " {:02.3f}% ".format(top1_acc / data.size(0) * 100),
"{:02.3f}% ".format(top5_acc / data.size(0) * 100))
print("all eval dataset:", "top1 acc: {:02.3f}%".format(total_correct_1 / total_num * 100),
"top5 acc:{:02.3f}%".format(total_correct_5 / total_num * 100))
with open(os.path.join(config.save_path, "stage2_top1_acc.txt"), "a") as f:
f.write(str(total_correct_1 / total_num * 100) + " ")
with open(os.path.join(config.save_path, "stage2_top5_acc.txt"), "a") as f:
f.write(str(total_correct_5 / total_num * 100) + " ")
# 判断当前脚本是否作为主程序直接运行。如果是,则解析命令行参数,并调用train函数进行训练。
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Train SimCLR')
parser.add_argument('--batch_size', default=200, type=int, help='')
parser.add_argument('--max_epoch', default=200, type=int, help='')
parser.add_argument('--pre_model', default=config.pre_model, type=str, help='')
args = parser.parse_args()
train(args)
5.2 代码详解
5.2.1 加载数据集
train_dataset = CIFAR10(root='dataset', train=True, transform=config.train_transform, download=True)
train_data = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=16, pin_memory=True)
eval_dataset = CIFAR10(root='dataset', train=False, transform=config.test_transform, download=True)
eval_data = DataLoader(eval_dataset, batch_size=args.batch_size, shuffle=False, num_workers=16, pin_memory=True)
这段代码用于加载训练集和验证集的数据。CIFAR10是一个图像分类数据集,通过指定root参数设置数据集的路径。train=True表示加载训练集,train=False表示加载验证集。transform参数指定了数据的预处理操作。download=True表示如果数据集不存在,则下载数据集。
DataLoader用于将数据封装成可迭代的数据加载器。batch_size参数指定了每个批次的样本数量,shuffle参数表示是否在每个epoch之前对数据进行洗牌,num_workers参数表示用于数据加载的线程数,pin_memory参数表示是否将数据存储于页锁定内存中,以加速数据传输。
5.2.2 创建有监督模块
model =net.SimCLRStage2(num_class=len(train_dataset.classes)).to(DEVICE)
model.load_state_dict(torch.load(args.pre_model, map_location='cpu'),strict=False)
loss_criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-3, weight_decay=1e-6)
这段代码用于创建模型、加载预训练模型的参数,并定义损失函数和优化器。
net.SimCLRStage2是一个自定义的模型类,用于第二阶段的训练。通过len(train_dataset.classes)获取训练集中的类别数量,并传递给模型作为输出类别数。
torch.load函数用于加载预训练模型的参数。args.pre_model是命令行参数–pre_model指定的预训练模型的路径。map_location='cpu’表示将模型加载到CPU上。
torch.nn.CrossEntropyLoss是交叉熵损失函数,用于多分类问题。
torch.optim.Adam是Adam优化器,用于优化模型的参数。model.fc.parameters()指定了要优化的参数,lr=1e-3表示学习率为0.001,weight_decay=1e-6表示权重衰减参数。
5.2.3 训练和验证的主要循环
for epoch in range(1,args.max_epoch+1):
model.train()
total_loss=0
for batch, (data, target) in enumerate(train_data):
data, target = data.to(DEVICE), target.to(DEVICE)
pred = model(data)
loss = loss_criterion(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print("epoch",epoch,"loss:", total_loss / len(train_dataset)*args.batch_size)
with open(os.path.join(config.save_path, "stage2_loss.txt"), "a") as f:
f.write(str(total_loss / len(train_dataset)*args.batch_size) + " ")
if epoch % 5==0:
torch.save(model.state_dict(), os.path.join(config.save_path, 'model_stage2_epoch' + str(epoch) + '.pth'))
model.eval()
with torch.no_grad():
print("batch", " " * 1, "top1 acc", " " * 1, "top5 acc")
total_loss, total_correct_1, total_correct_5, total_num = 0.0, 0.0, 0.0, 0
for batch, (data, target) in enumerate(train_data):
data, target = data.to(DEVICE), target.to(DEVICE)
pred = model(data)
total_num += data.size(0)
prediction = torch.argsort(pred, dim=-1, descending=True)
top1_acc = torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
top5_acc = torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
total_correct_1 += top1_acc
total_correct_5 += top5_acc
print(" {:02} ".format(batch + 1), " {:02.3f}% ".format(top1_acc / data.size(0) * 100),
"{:02.3f}% ".format(top5_acc / data.size(0) * 100))
print("all eval dataset:", "top1 acc: {:02.3f}%".format(total_correct_1 / total_num * 100),
"top5 acc:{:02.3f}%".format(total_correct_5 / total_num * 100))
with open(os.path.join(config.save_path, "stage2_top1_acc.txt"), "a") as f:
f.write(str(total_correct_1 / total_num * 100) + " ")
with open(os.path.join(config.save_path, "stage2_top5_acc.txt"), "a") as f:
f.write(str(total_correct_5 / total_num * 100) + " ")
在每个epoch中,模型被设置为训练模式model.train(), 并迭代训练数据集。
在每个batch中,数据和标签被移到指定的设备上,通过模型计算预测值。然后计算损失并进行反向传播和参数更新。通过模型计算预测值(pred),然后使用损失函数(loss_criterion)计算预测值与真实标签之间的损失。优化器(optimizer)的zero_grad()方法用于梯度清零,backward()方法用于计算梯度,step()方法用于更新模型参数。
在每个epoch结束时,打印平均损失,并将损失值写入文件(stage2_loss.txt),以便后续分析和可视化。
如果当前epoch是5的倍数,将模型的参数保存到文件(model_stage2_epoch{epoch}.pth),以便后续使用。
在每个epoch结束时,模型被设置为评估模式model.eval(),并使用torch.no_grad()关闭梯度计算,迭代验证数据集。在每个batch中,计算top-1和top-5准确率,并累计正确的样本数和总样本数。在所有数据集上完成评估后,打印总体的top-1和top-5准确率,并将它们写入文件(stage2_top1_acc.txt和stage2_top5_acc.txt),以便后续分析和可视化。
ps:什么是top-k评估标准?
在计算机视觉任务中,常用的评估指标之一是top-k准确率,其中k表示预测结果的排名。在这种情况下,top-1准确率表示模型的预测结果中最高概率的类别与真实标签匹配的比例,即只考虑排名最高的预测结果。而top-5准确率表示模型的预测结果中排名前五的类别中是否包含真实标签的比例。
具体来说,在代码中的评估部分,对于每个样本,模型会生成一个预测结果向量,其中包含每个类别的概率得分。然后,根据这些概率得分,将类别按照得分从高到低排序。top-1准确率计算的是预测结果中排名最高的类别是否与真实标签匹配,而top-5准确率计算的是预测结果中排名前五的类别中是否包含真实标签。
例如,对于一个图像分类任务,如果模型的预测结果中排名最高的类别与真实标签匹配,那么它的top-1准确率就是1。如果模型的预测结果中排名前五的类别中至少有一个与真实标签匹配,那么它的top-5准确率就是1。
这些准确率指标可以帮助我们了解模型在分类任务中的性能,尤其是在多类别分类问题中。top-1准确率通常被视为主要的评估指标,而top-5准确率则可以提供更宽松的评估,允许模型在预测结果中有一定的模糊性或不确定性。
六、训练并查看过程
将训练过程中的损失和准确率数据可视化的辅助脚本。使用了Visdom库来创建交互式的图表。visdom库可以使用pip install安装
6.1 代码
# showbyvisdom.py
import numpy as np
import visdom
def show_loss(path, name, step=1):
with open(path, "r") as f:
data = f.read()
data = data.split(" ")[:-1]
x = np.linspace(1, len(data) + 1, len(data)) * step
y = []
for i in range(len(data)):
y.append(float(data[i]))
vis = visdom.Visdom(env='loss')
vis.line(X=x, Y=y, win=name, opts={'title': name, "xlabel": "epoch", "ylabel": name})
def compare2(path_1, path_2, title="xxx", legends=["a", "b"], x="epoch", step=20):
with open(path_1, "r") as f:
data_1 = f.read()
data_1 = data_1.split(" ")[:-1]
with open(path_2, "r") as f:
data_2 = f.read()
data_2 = data_2.split(" ")[:-1]
x = np.linspace(1, len(data_1) + 1, len(data_1)) * step
y = []
for i in range(len(data_1)):
y.append([float(data_1[i]), float(data_2[i])])
vis = visdom.Visdom(env='loss')
vis.line(X=x, Y=y, win="compare",
opts={"title": "compare " + title, "legend": legends, "xlabel": "epoch", "ylabel": title})
if __name__ == "__main__":
show_loss("stage1_loss.txt", "loss1")
show_loss("stage2_loss.txt", "loss2")
show_loss("stage2_top1_acc.txt", "acc1")
show_loss("stage2_top5_acc.txt", "acc1")
# compare2("precision1.txt", "precision2.txt", title="precision", step=20)
6.2 代码详解
def show_loss(path, name, step=1):
with open(path, "r") as f:
data = f.read()
data = data.split(" ")[:-1]
x = np.linspace(1, len(data) + 1, len(data)) * step
y = []
for i in range(len(data)):
y.append(float(data[i]))
vis = visdom.Visdom(env='loss')
vis.line(X=x, Y=y, win=name, opts={'title': name, "xlabel": "epoch", "ylabel": name})
show_loss函数用于展示损失函数的变化情况。它接受三个参数:path表示存储数据的文件路径,name表示展示图像的窗口名称,step表示横坐标步长,默认为1。
函数内部首先使用open函数打开指定路径的文件,并读取文件内容。然后使用split函数将读取到的内容按空格分割,并去除最后一个空元素([:-1])。这样可以将文件中的数据转换为一个字符串列表。
接下来,通过np.linspace函数生成与数据长度相同的横坐标数组x,并乘以步长step。然后创建一个空的列表y。
接着使用一个循环遍历数据列表,将每个字符串元素转换为浮点数,并添加到y列表中。
然后,创建一个visdom.Visdom对象,并指定环境为’loss’。然后使用vis.line函数绘制折线图,其中X参数为横坐标数组x,Y参数为纵坐标数组y,win参数为窗口名称name,opts参数为图像的标题、横坐标标签和纵坐标标签等选项。
七、验证集评估:eval.py
7.1 代码
# eval.py
import torch,argparse
from torchvision.datasets import CIFAR10
import net,config
def eval(args):
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
eval_dataset=CIFAR10(root='dataset', train=False, transform=config.test_transform, download=True)
eval_data=torch.utils.data.DataLoader(eval_dataset,batch_size=args.batch_size, shuffle=False, num_workers=16, )
model=net.SimCLRStage2(num_class=len(eval_dataset.classes)).to(DEVICE)
model.load_state_dict(torch.load(config.pre_model, map_location='cpu'), strict=False)
# total_correct_1, total_correct_5, total_num, data_bar = 0.0, 0.0, 0.0, 0, tqdm(eval_data)
total_correct_1, total_correct_5, total_num = 0.0, 0.0, 0.0
model.eval()
with torch.no_grad():
print("batch", " "*1, "top1 acc", " "*1,"top5 acc" )
for batch, (data, target) in enumerate(eval_data):
data, target = data.to(DEVICE) ,target.to(DEVICE)
pred=model(data)
total_num += data.size(0)
prediction = torch.argsort(pred, dim=-1, descending=True)
top1_acc = torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
top5_acc = torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
total_correct_1 += top1_acc
total_correct_5 += top5_acc
print(" {:02} ".format(batch+1)," {:02.3f}% ".format(top1_acc / data.size(0) * 100),"{:02.3f}% ".format(top5_acc / data.size(0) * 100))
print("all eval dataset:","top1 acc: {:02.3f}%".format(total_correct_1 / total_num * 100), "top5 acc:{:02.3f}%".format(total_correct_5 / total_num * 100))
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='test SimCLR')
parser.add_argument('--batch_size', default=512, type=int, help='')
args = parser.parse_args()
eval(args)
7.2 代码详解
7.2.1 加载评估数据集
eval_dataset=CIFAR10(root='dataset', train=False, transform=config.test_transform, download=True)
eval_data=torch.utils.data.DataLoader(eval_dataset,batch_size=args.batch_size, shuffle=False, num_workers=16, )
加载CIFAR10数据集的测试集。其中root参数指定数据集的根目录,train=False表示加载测试集,transform=config.test_transform表示使用配置文件中定义的测试集数据转换函数,download=True表示如果数据集不存在则进行下载。
然后使用torch.utils.data.DataLoader创建一个数据加载器eval_data,用于批量加载测试数据。其中batch_size参数指定批大小,shuffle=False表示不对数据进行洗牌,num_workers参数指定用于数据加载的线程数。
7.2.2 创建分类器模型
model=net.SimCLRStage2(num_class=len(eval_dataset.classes)).to(DEVICE)
model.load_state_dict(torch.load(config.pre_model, map_location='cpu'), strict=False)
创建一个net.SimCLRStage2模型对象model,用于评估。SimCLRStage2是自定义的模型类,用于进行图像分类。num_class参数设置为评估数据集的类别数量。
然后,使用torch.load函数加载预训练模型的参数,并将其加载到model中。config.pre_model指定了预训练模型的路径,map_location='cpu’表示在没有GPU时将模型参数加载到CPU上,strict=False表示允许加载不严格匹配的参数。
7.2.3 验证
total_correct_1, total_correct_5, total_num = 0.0, 0.0, 0.0
model.eval()
with torch.no_grad():
print("batch", " "*1, "top1 acc", " "*1,"top5 acc" )
for batch, (data, target) in enumerate(eval_data):
data, target = data.to(DEVICE) ,target.to(DEVICE)
pred=model(data)
total_num += data.size(0)
prediction = torch.argsort(pred, dim=-1, descending=True)
top1_acc = torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
top5_acc = torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
total_correct_1 += top1_acc
total_correct_5 += top5_acc
print(" {:02} ".format(batch+1)," {:02.3f}% ".format(top1_acc / data.size(0) * 100),"{:02.3f}% ".format(top5_acc / data.size(0) * 100))
print("all eval dataset:","top1 acc: {:02.3f}%".format(total_correct_1 / total_num * 100), "top5 acc:{:02.3f}%".format(total_correct_5 / total_num * 100))
初始化变量total_correct_1、total_correct_5和total_num为0。
然后,将模型设置为评估模式,禁用梯度计算,使用torch.nograd();
在一个循环中,遍历评估数据加载器中的每个批次。将批次的输入数据和目标标签移动到设备上。
通过模型前向传播,得到预测结果pred。 使用torch.argsort函数对预测结果进行排序,以获得按概率从高到低的类别索引。
计算每个样本的Top-1和Top-5准确率。首先将预测结果与目标标签进行比较,得到每个样本是否在Top-1或Top-5中的布尔值。然后将布尔值进行求和,并转换为浮点数,最后通过item()方法获取准确率的数值。
累加每个批次中的正确预测数量和样本总数。在每个批次中打印当前批次号、Top-1准确率和Top-5准确率。循环结束后,打印整个评估数据集的Top-1准确率和Top-5准确率。
7.2.4 main
创建一个参数解析器argparse.ArgumentParser,用于从命令行中解析参数。其中–batch_size是一个可选参数,默认值为512,用于指定评估时的批次大小。
解析命令行参数,并将参数传递给eval函数进行评估。
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='test SimCLR')
parser.add_argument('--batch_size', default=512, type=int, help='')
args = parser.parse_args()
eval(args)
八、自定义图片测试
用于使用训练好的模型对一张图像进行分类。
8.1 代码
# test.py
import torch,argparse
import net,config
from torchvision.datasets import CIFAR10
import cv2
def show_CIFAR10(index):
eval_dataset=CIFAR10(root='dataset', train=False, download=False)
print(eval_dataset.__len__())
print(eval_dataset.class_to_idx,eval_dataset.classes)
img, target=eval_dataset[index][0], eval_dataset[index][1]
import matplotlib.pyplot as plt
plt.figure(str(target))
plt.imshow(img)
plt.show()
def test(args):
classes={'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
index2class=[x for x in classes.keys()]
print("calss:",index2class)
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
transform = config.test_transform
ori_img=cv2.imread(args.img_path,1)
img=cv2.resize(ori_img,(32,32)) # evry important,influence the result
img=transform(img).unsqueeze(dim=0).to(DEVICE)
model=net.SimCLRStage2(num_class=10).to(DEVICE)
model.load_state_dict(torch.load(args.pre_model, map_location='cpu'), strict=False)
pred = model(img)
prediction = torch.argsort(pred, dim=-1, descending=True)
label=index2class[prediction[:, 0:1].item()]
cv2.putText(ori_img,"this is "+label,(30,30),cv2.FONT_HERSHEY_DUPLEX,1, (0,255,0), 1)
cv2.imshow(label,ori_img)
cv2.waitKey(0)
if __name__ == '__main__':
# show_CIFAR10(2)
parser = argparse.ArgumentParser(description='test SimCLR')
parser.add_argument('--pre_model', default=config.pre_model, type=str, help='')
parser.add_argument('--img_path', default="bird.jpg", type=str, help='')
args = parser.parse_args()
test(args)
8.2 代码详解
8.2.1 创建测试集并且获取图像
def show_CIFAR10(index):
eval_dataset=CIFAR10(root='dataset', train=False, download=False)
print(eval_dataset.__len__())
print(eval_dataset.class_to_idx,eval_dataset.classes)
img, target=eval_dataset[index][0], eval_dataset[index][1]
import matplotlib.pyplot as plt
plt.figure(str(target))
plt.imshow(img)
plt.show()
show_CIFAR10函数用于显示CIFAR10数据集中指定索引的图像。首先创建一个CIFAR10数据集对象eval_dataset,其中root参数指定数据集的根目录,train=False表示使用测试集,download=False表示不下载数据集。
然后,通过索引index获取指定索引处的图像和目标标签。使用matplotlib.pyplot库创建一个图像窗口,显示图像。
8.2.2 对图像进行预处理
test函数用于对图像进行分类。
def test(args):
classes={'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
index2class=[x for x in classes.keys()]
print("calss:",index2class)
if torch.cuda.is_available() and config.use_gpu:
DEVICE = torch.device("cuda:" + str(config.gpu_name))
torch.backends.cudnn.benchmark = True
else:
DEVICE = torch.device("cpu")
model=net.SimCLRStage2(num_class=10).to(DEVICE)
model.load_state_dict(torch.load(args.pre_model, map_location='cpu'), strict=False)
pred = model(img)
prediction = torch.argsort(pred, dim=-1, descending=True)
label=index2class[prediction[:, 0:1].item()]
cv2.putText(ori_img,"this is "+label,(30,30),cv2.FONT_HERSHEY_DUPLEX,1, (0,255,0), 1)
cv2.imshow(label,ori_img)
cv2.waitKey(0)
首先定义一个字典classes,将类别名称映射到类别索引。然后通过字典的键获取类别名称列表index2class。
获取配置文件中的测试数据预处理的转换函数transform。
使用cv2.imread函数读取指定路径args.img_path的图像,并指定参数1表示以彩色图像格式读取。将原始图像ori_img调整大小为(32,32),并保存到变量img中,这一步非常重要,因为模型训练时使用的图像大小为32x32像素。
应用测试数据预处理的转换函数transform对图像进行预处理,并在第0维度上添加一个维度,以匹配模型输入的形状。将处理后的图像移动到设备上。
8.2.3 创建分类模型
model=net.SimCLRStage2(num_class=10).to(DEVICE)
model.load_state_dict(torch.load(args.pre_model, map_location='cpu'), strict=False)
pred = model(img)
prediction = torch.argsort(pred, dim=-1, descending=True)
label=index2class[prediction[:, 0:1].item()]
cv2.putText(ori_img,"this is "+label,(30,30),cv2.FONT_HERSHEY_DUPLEX,1, (0,255,0), 1)
cv2.imshow(label,ori_img)
cv2.waitKey(0)
创建一个net.SimCLRStage2模型对象model,用于分类。SimCLRStage2是自定义的模型类,用于进行图像分类。num_class参数设置为10,对应CIFAR10数据集中的类别数目。
加载预训练的模型参数,使用torch.load函数加载参数文件args.pre_model,并传入map_location='cpu’参数以确保在没有GPU的情况下也能加载模型。strict=False表示允许加载模型参数时出现不匹配的情况。
将图像img输入模型,得到预测结果pred。
使用torch.argsort函数对预测结果pred按照概率从高到低进行排序,得到排序后的索引。
根据排序后的索引,获取概率最高的类别索引,并通过index2class字典映射得到类别标签label。
使用cv2.putText函数在原始图像上添加文本标签,显示预测结果。
最后使用cv2.imshow函数显示带有预测结果的图像,并通过cv2.waitKey(0)等待用户按下任意键关闭图像窗口。
8.2.4 main
在脚本的主程序中,创建一个argparse.ArgumentParser对象,用于解析命令行参数。定义了两个命令行参数–pre_model和–img_path,分别表示预训练模型参数文件和输入图像路径。
解析命令行参数,并将解析结果传递给test函数进行图像分类。
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='test SimCLR')
parser.add_argument('--pre_model', default=config.pre_model, type=str, help='')
parser.add_argument('--img_path', default="bird.jpg", type=str, help='')
args = parser.parse_args()
test(args)