Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
命名实体识别 ( NER ) (也称为实体标识 , 实体分块和实体提取 )是信息提取的子任务,旨在将非结构化文本中提到的命名实体定位和分类为预定义类别,例如人员姓名,组织,位置,医疗代码,时间表达,数量,货币价值,百分比等。
In this project, we will work with a NER dataset provided by kaggle. The dataset can be accessed here. This dataset is the extract from GMB corpus which is tagged, annotated and built specifically to train the classifier to predict named entities such as name, location, etc. Dataset also includes one additional feature (POS) that can be used in classification. In this project, however we are working only with one feature sentence.
在此项目中,我们将使用kaggle提供的NER数据集。 数据集可在此处访问。 该数据集是GMB语料库的摘录,经过标记,注释和构建,专门用于训练分类器预测诸如名称,位置等命名实体。数据集还包括一个可用于分类的附加功能(POS)。 但是,在此项目中,我们仅使用一个功能语句。
1.加载数据集 (1. Load the dataset)
Lets begin by loading and visualising the dataset. To download ner_dataset.csv go to this link in kaggle.
让我们从加载和可视化数据集开始。 要下载ner_dataset.csv,请转至kaggle中的此链接 。
We will have to use encoding = ‘unicode_escape’ while loading the data. This function takes a parameter to toggle the addition of the wrapping quotes and escaping of that quote in a string.
加载数据时,我们将必须使用encoding ='unicode_escape'。 此函数使用一个参数来切换包装引号和字符串中引号的转义。
import pandas as pd
data = pd.read_csv('ner_dataset.csv', encoding= 'unicode_escape')
data.head()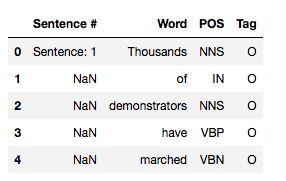
From the dataset we can see the sentences are already broken into tokens in the column ‘Word’ which will be our feature (X). The column ‘sentence #’ displays the sentence number once and then prints NaN till the next sentence begins. The ‘Tag’ column will be our label (y).
从数据集中,我们可以看到句子已在“单词”列中被分解为标记,这将成为我们的特征(X)。 “句子#”列一次显示句子编号,然后打印NaN直到下一个句子开始。 “标签”列将是我们的标签(y)。
2.提取神经网络所需的映射 (2. Extract mappings required for the neural network)
To train a neural network, we will use two mappings as given below. - {token} to {token id}: address the row in embeddings matrix for the current token.- {tag} to {tag id}: one-hot ground truth probability distribution vectors for computing the loss at the output of the network.
为了训练神经网络,我们将使用下面给出的两个映射。 -{ 令牌 }到{ 令牌ID }:在当前令牌的嵌入矩阵中寻址行。-{ 标记 }到{ 标记ID }:用于计算网络输出损耗的单点地面真理概率分布矢量。
This step is required, as any machine learning model including the neural network require integers as input.
这是必需的步骤,因为任何机器学习模型(包括神经网络)都需要整数作为输入。
data['Word_idx'] = data['Word'].map(token2idx)
data['Tag_idx'] = data['Tag'].map(tag2idx)
data.head()
We can see the function has added two new index columns for both our X (Word_idx) and y (Tag_idx) variables. Next lets collect tokens into arrays in respective sequence to make the best use of recurrent neural network.
我们可以看到该函数为X(Word_idx)和y(Tag_idx)变量添加了两个新的索引列。 接下来,让令牌以各自的顺序收集到数组中,以充分利用循环神经网络。
3.转换列以提取顺序数据 (3. Transform columns to extract sequential data)
To transform columns into sequential arrays, we will
要将列转换为顺序数组,我们将
- Fill NaN in ‘sentence #’ column using method ffill in fillna. 使用fillna中的方法fill在“句子编号”列中填写NaN。
- Thereafter groupby on the sentence column to get a list of tokens and tags for each sentence. 之后,在句子列上分组,以获取每个句子的标记和标签列表。
# Fill na
data_fillna = data.fillna(method='ffill', axis=0)# Groupby and collect columns
data_group = data_fillna.groupby(
['Sentence #'],as_index=False
)['Word', 'POS', 'Tag', 'Word_idx', 'Tag_idx'].agg(lambda x: list(x))# Visualise data
data_group.head()
4.将数据集拆分为训练,填充后进行测试 (4. Split the dataset into train, test after padding)
Padding: The LSTM layers accept sequences of same length only. Therefore every sentence that is represented as integers (‘Word_idx’) must be padded to have the same length. To acheive this we we will work with max length of the longest sequence and pad the sequences that are shorter than the longest sequence.
填充 :LSTM层仅接受相同长度的序列。 因此,必须填充每个以整数('Word_idx')表示的句子,使其具有相同的长度。 为了实现这一点,我们将使用最长序列的最大长度并填充比最长序列短的序列。
Please note we can use shorter padding lengths as well. In that case you will be padding the shorter sequences and truncating the longer sequences.
请注意,我们也可以使用较短的填充长度。 在这种情况下,您将填充较短的序列,并截断较长的序列 。
We will also be converting the y variable as one hot encoded vector using to_categorical function in keras. Lets import the required packages.
我们还将使用keras中的to_categorical函数将y变量转换为一个热编码向量。 让我们导入所需的软件包。
from sklearn.model_selection import train_test_split
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical5.建立模型架构 (5. Build the model architecture)
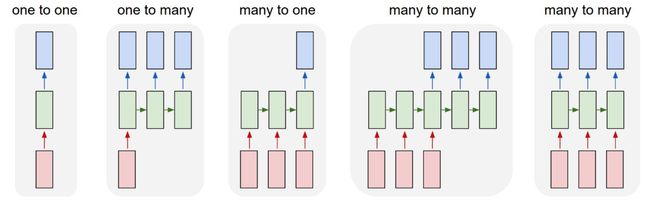
Neural network models work with graphical structure. Therefore we will first need to design the architecture and set input and out dimensions for every layer. RNNs are capable of handling different input and output combinations, In our task we will working with many to many architecture, please refer to the last architecture in the image given below. Our task is to output tag (y) for a token (X) ingested at each time step. Please refer to the below picture.
神经网络模型使用图形结构。 因此,我们首先需要设计架构,并为每一层设置输入和输出尺寸。 RNN能够处理不同的输入和输出组合,在我们的任务中,我们将使用多对多架构,请参考下图中的最后一个架构。 我们的任务是输出在每个时间步提取的令牌(X)的标签(y)。 请参考下图。
Lets begin by loading, the required packages.
让我们从加载所需的包开始。
import numpy as np
import tensorflow
from tensorflow.keras import Sequential, Model, Input
from tensorflow.keras.layers import LSTM, Embedding, Dense, TimeDistributed, Dropout, Bidirectional
from tensorflow.keras.utils import plot_modelIts always best to set seed for reproducibility.
始终最好为可重复性设置种子。
from numpy.random import seed
seed(1)
tensorflow.random.set_seed(2)To walk us through every step of the model architecture, I built a model and plotted it below. While I walk you through every step, please compare the layers in the model plot with the brief on each layer given below. This will help you get a better understanding of the input and output dimensions in the layers. In this architecture we are primarily working with 3 layers (embedding, bi-lstm, lstm layers) and the 4th layer which is TimeDistributed Dense layer to output the result. We will discuss the layers in detail :
为了引导我们完成模型体系结构的每个步骤,我建立了一个模型并将其绘制在下面。 当我逐步引导您完成所有步骤时,请比较模型图中的图层与下面给出的每个图层的摘要。 这将帮助您更好地了解图层中的输入和输出尺寸。 在此体系结构中,我们主要使用3层(嵌入,bi-lstm,lstm层)和第4层(即TimeDistributed Dense层)来输出结果。 我们将详细讨论各层:
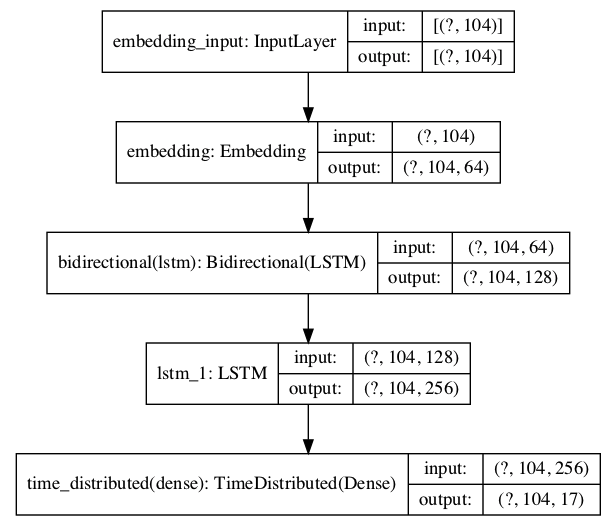
Layer 1 — Embedding layer : We will specify the maximum length (104) of the padded sequences. After the network is trained, the embedding layer will transform each token into a vector of n dimensions. We have chosen the n dimensions to be (64).
第1层-嵌入层:我们将指定填充序列的最大长度(104)。 训练完网络后,嵌入层会将每个令牌转换为n维向量。 我们选择n维为(64)。
The dimensions (?, 104, 64) that we see in the embedding layer in the given neural network plot comes from these specifications. Please note the 1st dimension shows ‘?’ or None in the plots. They represent the batch sizes, if its not given they show ‘?’ or None which means the model can take any batch size.
我们在给定神经网络图的嵌入层中看到的尺寸(?,104、64)来自这些规范。 请注意,第一个维度显示为“?” 或在图中没有。 它们代表批次大小,如果未给出,则显示“?” 或“无”表示该模型可以采用任何批处理大小。
Layer 2 — Bidirectional LSTM : Bidirectional lstm takes a recurrent layer (e.g. the first LSTM layer) as an argument. This layer takes the output from the previous embedding layer (104, 64).
第2层-双向LSTM:双向lstm将循环层(例如第一个LSTM层)作为参数。 该层获取前一嵌入层(104、64)的输出。
Since this is bidirectional lstm, we will have forward and backward outputs should be combined before being passed on to the next layer. This can be done by summing or taking average or concatenating or multiplying. All these functions are given in the merge mode argument in bi-lstm layer. The default mode is to concatenate, where the outputs are concatenated together, providing double the number of outputs to the next layer, in our case its 128(64 * 2).
由于这是双向的lstm,因此在传递给下一层之前,我们将要合并向前和向后的输出。 这可以通过求和或取平均值或串联或相乘来完成。 所有这些功能在bi-lstm层的合并模式参数中给出。 默认模式是串联,将输出串联在一起,从而为下一层(在本例中为128(64 * 2))提供两倍的输出。
Layer 3 — LSTM Layer : An LSTM network is a recurrent neural network that has LSTM cell blocks in place of our standard neural network layers. These cells have various components called the input gate, the forget gate and the output gate.
第3层-LSTM层: LSTM网络是一种递归神经网络,具有LSTM单元块来代替我们的标准神经网络层。 这些单元具有称为输入门,遗忘门和输出门的各种组件。
This layer takes the output dimension from the previous bidirectional lstm layer (?, 104, 128) and outputs (?, 104, 256)
该层采用前一个双向lstm层的输出尺寸(?,104,128)和输出(?,104,256)
Layer 4 — TimeDistributed Layer : We are dealing with Many to Many RNN Architecture where we expect output from every input sequence for example (a1 →b1, a2 →b2… an →bn) where a and b are inputs and outputs of every sequence. The TimeDistributeDense layers allow you to apply Dense(fully-connected) operation across every output over every time-step. If you don’t use this, you would only have one final output.
第四层-时间分布层:我们正在处理多对多RNN架构,我们期望从每个输入序列(例如,a1→b1,a2→b2…a→bn)输出,其中a和b是每个序列的输入和输出。 通过TimeDistributeDense层,您可以在每个时间步跨每个输出应用Dense(完全连接)操作。 如果您不使用它,则将只有一个最终输出。
This layer take the output dimension of the previous lstm layer (104, 256) and outputs the max sequence length (104) and max tags (17).
该层采用前一个lstm层的输出尺寸(104,256),并输出最大序列长度(104)和最大标签(17)。
input_dim = len(list(set(data['Word'].to_list())))+1
output_dim = 64
input_length = max([len(s) for s in data_group['Word_idx'].tolist()])
n_tags = len(tag2idx)print('input_dim: ', input_dim, '\noutput_dim: ', output_dim, '\ninput_length: ', input_length, '\nn_tags: ', n_tags)
Given below is the code used to build the model architecture we discussed above. Before fitting the model you can check the model graph by plotting the model using plot_model function or you can check the model summary by using the function model.summary().
下面给出的是用于构建我们上面讨论的模型架构的代码。 在拟合模型之前,您可以使用plot_model函数通过绘制模型来检查模型图,也可以通过使用model.summary()函数来检查模型摘要。
6.拟合模型 (6. Fit the model)
We will be fitting the model with a for loop to save and visualise the loss at every epoch.
我们将使用for循环对模型进行拟合,以保存和可视化每个时期的损失。
results = pd.DataFrame()model_bilstm_lstm = get_bilstm_lstm_model()
plot_model(model_bilstm_lstm)results['with_add_lstm'] = train_model(train_tokens, np.array(train_tags), model_bilstm_lstm)Model started with 0.9169 accuracy ended. After running 25 epochs with 1000 batch size, the final accuracy was 0.9687
型号以0.9169精度开始。 在以1000个批处理大小运行25个纪元后,最终精度为0.9687

Please experiment the model with different batch sizes, dropout value, optimisers, metrics and layers to get better result. The complete code for this project can be found in the Github Repository.
请使用不同的批处理大小,退出值,优化器,指标和层次来试验模型,以获得更好的结果。 该项目的完整代码可以在Github存储库中找到。
For anyone interested, I have left a piece of code that will highlight the entities in any given sentence using spaCy. Hope you enjoyed reading.
对于感兴趣的人,我留下了一段代码,将使用spaCy突出显示任何给定句子中的实体。 希望您喜欢阅读。
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')text = nlp('Jim bought 300 shares of Acme Corp. in 2006. And producing an annotated block of text that highlights the names of entities: [Jim]Person bought 300 shares of [Acme Corp.]Organization in [2006]Time. In this example, a person name consisting of one token, a two-token company name and a temporal expression have been detected and classified.State-of-the-art NER systems for English produce near-human performance. For example, the best system entering MUC-7 scored 93.39% of F-measure while human annotators scored 97.60% and 96.95%.[1][2]')displacy.render(text, style = 'ent', jupyter=True)
翻译自: https://towardsdatascience.com/named-entity-recognition-ner-using-keras-bidirectional-lstm-28cd3f301f54