用Nest 实现大文件分片上传,加速工作效率神器
文件上传是常见需求,只要指定 content-type 为 multipart/form-data,内容就会以这种格式被传递到服务端:
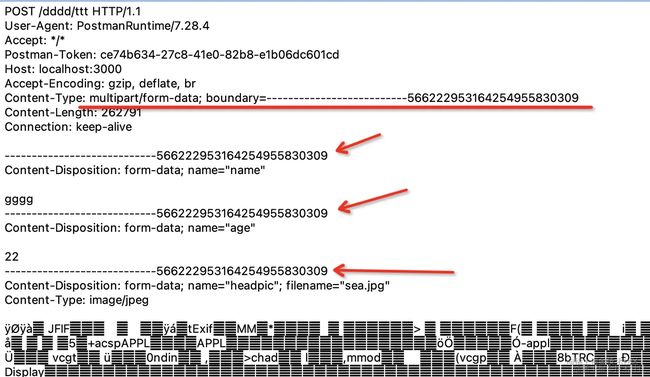
服务端再按照 multipart/form-data 的格式提取数据,就能拿到其中的文件。
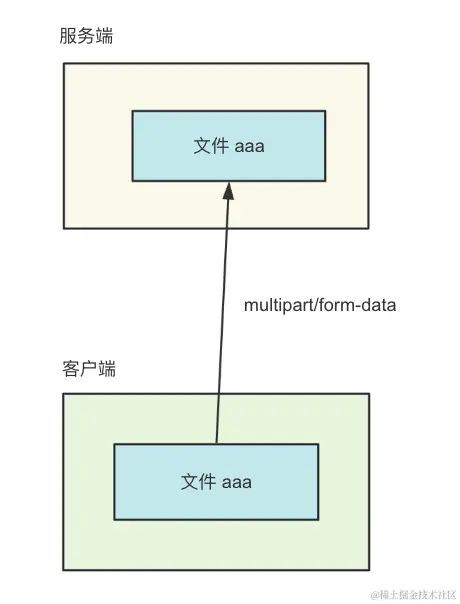
但当文件很大的时候,事情就变得不一样了。
假设传一个 100M 的文件需要 3 分钟,那传一个 1G 的文件就需要 30 分钟。
这样是能完成功能,但是产品的体验会很不好。
所以大文件上传的场景,需要做专门的优化。
把 1G 的大文件分割成 10 个 100M 的小文件,然后这些文件并行上传,不就快了?
然后等 10 个小文件都传完之后,再发一个请求把这 10 个小文件合并成原来的大文件。
这就是大文件分片上传的方案。
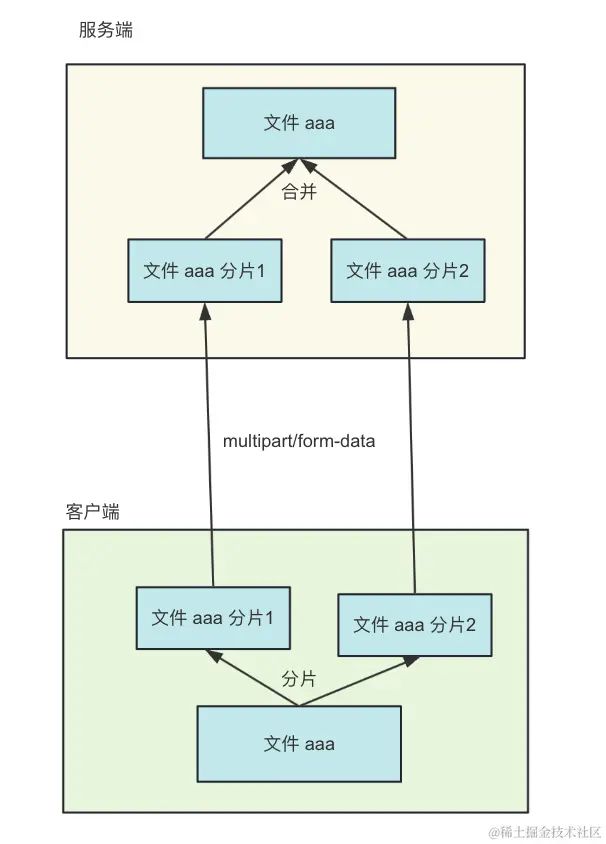
那如何拆分和合并呢?
浏览器里 Blob 有 slice 方法,可以截取某个范围的数据,而 File 就是一种 Blob:


所以可以在 input 里选择了 file 之后,通过 slice 对 File 分片。
那合并呢?
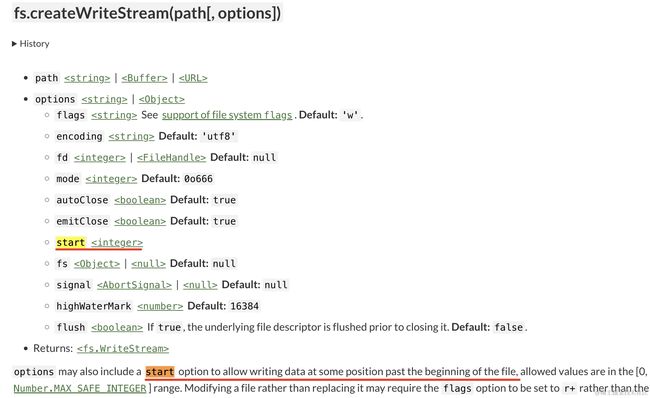
fs 的 createWriteStream 方法支持指定 start,也就是从什么位置开始写入。
这样把每个分片按照不同位置写入文件里,不就完成合并了么。
思路理清了,接下来我们实现一下。
创建个 Nest 项目:
npm install -g @nestjs/cli
nest new large-file-sharding-upload

在 AppController 添加一个路由:
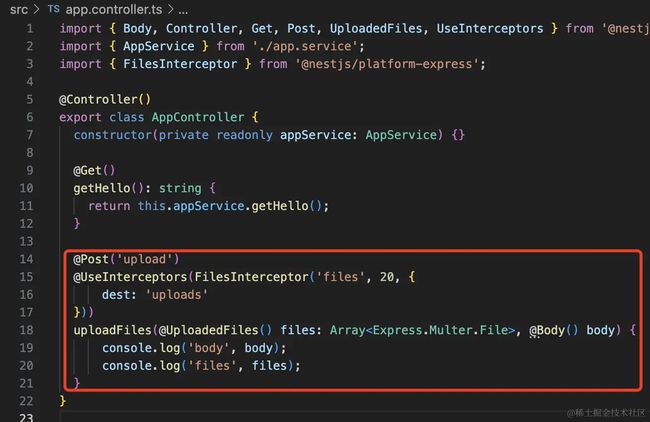
@Post('upload')
@UseInterceptors(FilesInterceptor('files', 20, {
dest: 'uploads'
}))
uploadFiles(@UploadedFiles() files: Array, @Body() body) {
console.log('body', body);
console.log('files', files);
}
这是一个 post 接口,会读取请求体里的 files 文件字段传入该方法。
这里还需要安装用到的 multer 包的类型:
npm install -D @types/multer
然后我们在网页里试一下:
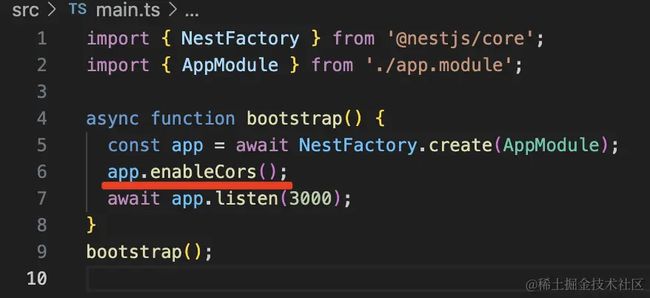
首先在 main.ts 里开启跨域支持:
然后添加一个 index.html:
Document
input 指定 multiple,可以选择多个文件。
选择文件之后,通过 post 请求 upload 接口,携带 FormData。FormData 里保存着 files 和其它字段。
起个静态服务:
npx http-server .
浏览器访问下:

选择几个文件:
这时候,Nest 服务端就接收到了上传的文件和其他字段:

当然,我们并不是想上传多个文件,而是一个大文件的多个分片。
所以是这样写:
Document
对拿到的文件进行分片,然后单独上传每个分片,分片名字为文件名 + index。
这里我们测试用的图片是 80k:
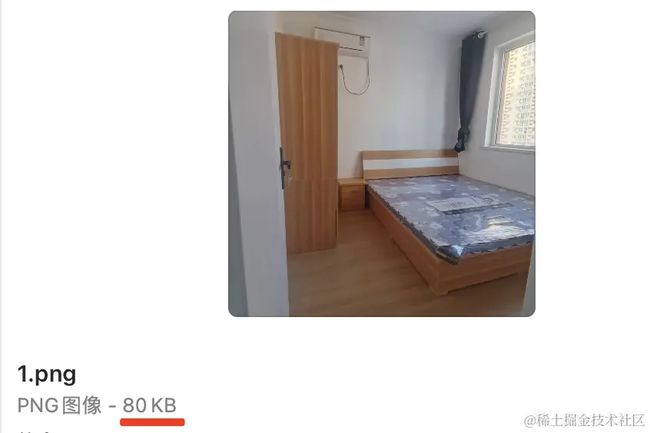
所以每 20k 一个分片,一共是 4 个分片。
测试下:
服务端接收到了这 4 个分片:
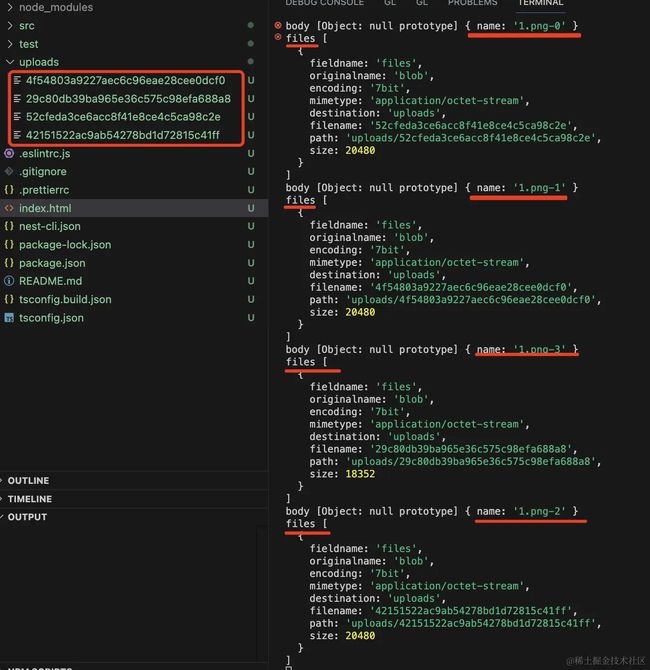
然后我们把它们移动到单独的目录:
@Post('upload')
@UseInterceptors(FilesInterceptor('files', 20, {
dest: 'uploads'
}))
uploadFiles(@UploadedFiles() files: Array, @Body() body: { name: string }) {
console.log('body', body);
console.log('files', files);
const fileName = body.name.match(/(.+)\-\d+$/)[1];
const chunkDir = 'uploads/chunks_'+ fileName;
if(!fs.existsSync(chunkDir)){
fs.mkdirSync(chunkDir);
}
fs.cpSync(files[0].path, chunkDir + '/' + body.name);
fs.rmSync(files[0].path);
}
用正则匹配出文件名:

在 uploads 下创建 chunks_文件名 的目录,把文件复制过去,然后删掉原始文件。
测试下:
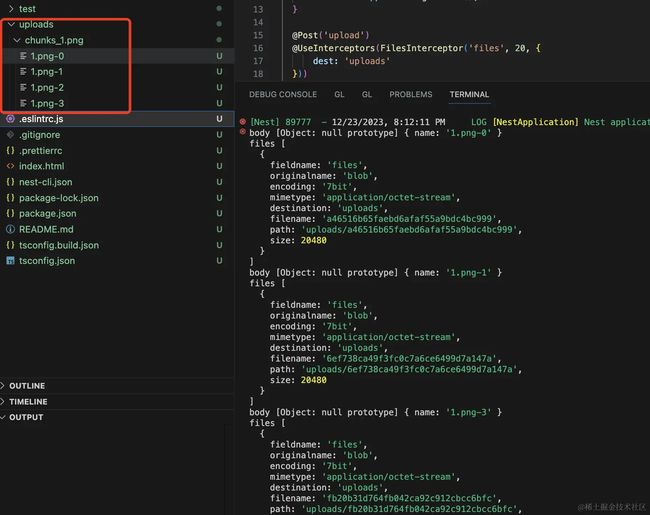
分片文件移动成功了。
不过直接以 chunks_文件名 做为目录名,太容易冲突了。
我们可以在上传文件的时候给文件名加一个随机的字符串。

这样就不会冲突了:

接下来,就是在全部分片上传完之后,发送合并分片的请求。
添加一个 merge 的接口:
@Get('merge')
merge(@Query('name') name: string) {
const chunkDir = 'uploads/chunks_'+ name;
const files = fs.readdirSync(chunkDir);
let startPos = 0;
files.map(file => {
const filePath = chunkDir + '/' + file;
const stream = fs.createReadStream(filePath);
stream.pipe(fs.createWriteStream('uploads/' + name, {
start: startPos
}))
startPos += fs.statSync(filePath).size;
})
}
接收文件名,然后查找对应的 chunks 目录,把下面的文件读取出来,按照不同的 start 位置写入到同一个文件里。
浏览器访问下这个接口:

可以看到,合并成功了:
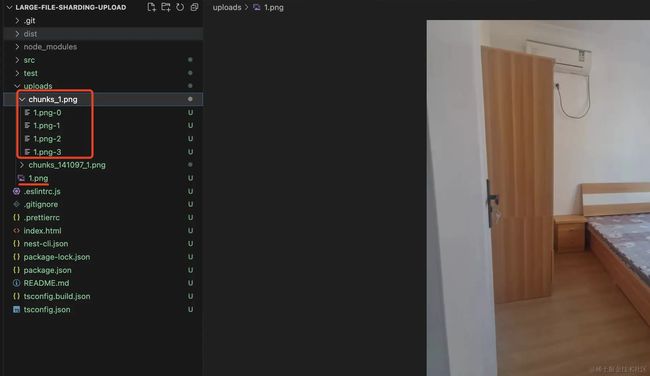
再测试一个:
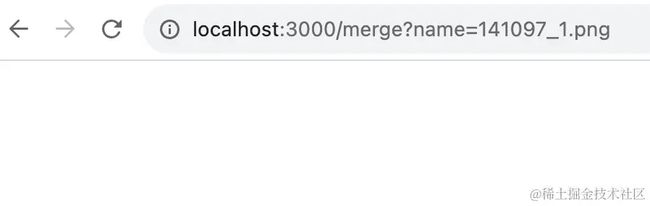
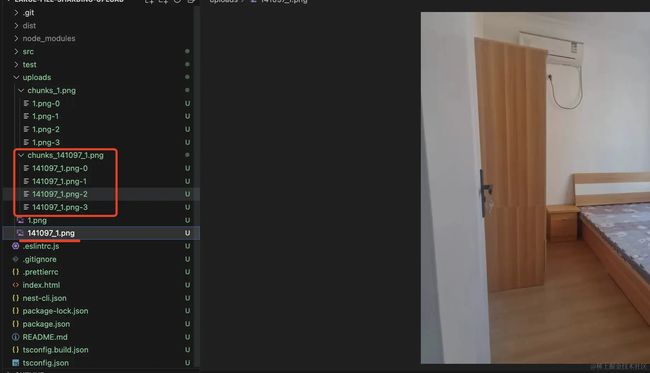
也没啥问题。
然后我们在合并完成之后把 chunks 目录删掉。

@Get('merge')
merge(@Query('name') name: string) {
const chunkDir = 'uploads/chunks_'+ name;
const files = fs.readdirSync(chunkDir);
let count = 0;
let startPos = 0;
files.map(file => {
const filePath = chunkDir + '/' + file;
const stream = fs.createReadStream(filePath);
stream.pipe(fs.createWriteStream('uploads/' + name, {
start: startPos
})).on('finish', () => {
count ++;
if(count === files.length) {
fs.rm(chunkDir, {
recursive: true
}, () =>{});
}
})
startPos += fs.statSync(filePath).size;
});
}
然后在前端代码里,当分片全部上传完之后,调用 merge 接口:
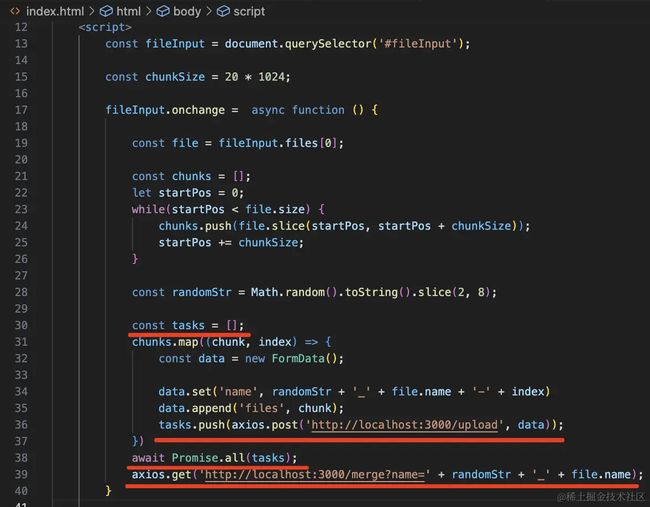
const tasks = [];
chunks.map((chunk, index) => {
const data = new FormData();
data.set('name', randomStr + '_' + file.name + '-' + index)
data.append('files', chunk);
tasks.push(axios.post('http://localhost:3000/upload', data));
})
await Promise.all(tasks);
axios.get('http://localhost:3000/merge?name=' + randomStr + '_' + file.name);
连起来测试下:
因为文件比较小,开启 network 的 slow 3g 网速来测。
可以看到,分片上传和最后的合并都没问题。
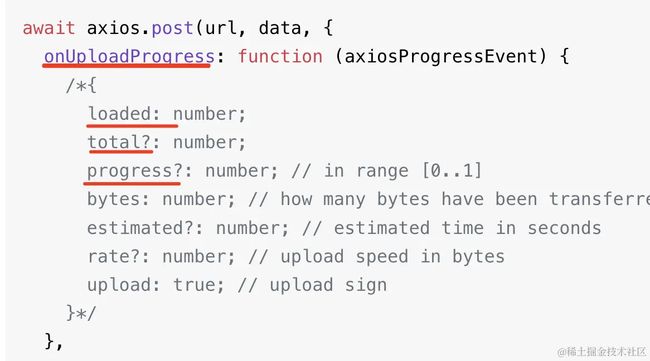
当然,你还可以加一个进度条,这个用 axios 很容易实现:
至此,大文件分片上传就完成了。
总结
当文件比较大的时候,文件上传会很慢,这时候一般我们会通过分片的方式来优化。
原理就是浏览器里通过 slice 来把文件分成多个分片,并发上传。
服务端把这些分片文件保存在一个目录下。
当所有分片传输完成时,发送一个合并请求,服务端通过 fs.createWriteStream 指定 start 位置,来把这些分片文件写入到同一个文件里,完成合并。
这样,我们就实现了大文件分片上传。
Nest 实现大文件分片上传
原文链接:https://juejin.cn/post/7315591545741197349