技术探秘:在RISC Zero中验证FHE——RISC Zero应用的DevOps(2)
1. 引言
前序博客:
- 技术探秘:在RISC Zero中验证FHE——由隐藏到证明:FHE验证的ZK路径(1)
技术探秘:在RISC Zero中验证FHE——由隐藏到证明:FHE验证的ZK路径(1) 中,深入研究了RISC Zero中Fully Homomorphic Encryption(FHE)的bootstrapping步骤。基于此,本文专注于性能优化。
人们在对RISC Zero中应用做优化时,最重要的一点就是:
- 专注于解决主要性能瓶颈问题
为此,首先需知道主要性能瓶颈在哪,因此:
- 需profile 应用程序 每一部分 所贡献的 “ZK-proving”开销。
本文致力于通过RISC Zero上的理论和实验相结合来计算这种证明开销。
2. ZK proving开销贡献因子
从理论角度来说,RISC Zero中的“ZK-proving”开销,是以“cycles”来计量的——与CPU的cycles类似。与常规RISC-V CPU类似,RISC Zero中的cycles有2大来源:
- 1)compute
- 2)paging
2.1 compute开销
根据RISC Zero zkVM guest程序优化技巧 及其 与物理CPU的关键差异,当执行每个RISC-V指令时,都将引起RISC Zero内的某些CPU compute cycles:
- one cycle指令有:LUI, AUIPC, JAL, JALR, BEQ, BNE, BLT, BGE, BLTU, BGEU, LB, LH, LW, LBU, LHU, SB, SH, SW, ADDI, SLTI, SLTIU, SLLI, ADD, SUB, SLL, SLTU, MUL, MULH, MULHSU, MULHU。
- two cycles指令有:XORI, ORI, ANDI, SRLI, SRAI, XOR, SRL, SRA, OR, AND, DIV, DIVU, REM, REMU。
- 76 cycles per 64 bytes指令有:syscall for SHA-256。
- 10 cycles指令有:syscall for 256-bit modular multiplication
大多数常规指令,如32位数字加法和乘法,均引发一个cycle。某些bitwise运算和触发运算,需要2个cycles。调用密码学accelerator的syscalls,需要更多cycles。这在本质上类似于现代CPU的SHA扩展,它添加了专门用于SHA256的指令,这些指令只需要几个cycles即可执行。
需注意,RISC Zero的cycle counts,是专门针对RISC Zero的。真实的RISC-V CPU芯片,大概率有不同的cycle count,因计算开销通常高于验证开销。未来的RISC Zero版本,每个指令也可能会有不同的cycle counts。
2.2 paging开销
由于paging,指令也可能引发non-compute cycles。paging也是ZK-proving开销的重要来源。
为理解RISC Zero中的paging开销,首先需了解现代CPU的数据访问原理,具体取决于待访问的数据在哪:
- 1)待访问的数据在L1/L2 caches:可 以few cycles来访问该数据。
- 2)待访问的数据在main memory:该数据访问具有数百cycles延迟。
- 3)待访问的数据在external storage:
- 首先需将该数据加载进main memory,该过程称为“paged-in”。在此期间,CPU需等待,“paged-in”需消耗数万个cycles,即使external storage是高端SSD。
- 数据可能还需要从main memory “paged-out” 回该external storage。
称为“paged-in”和“paged-out”的原因在于,现代操作系统管理内存为,使得程序可访问“pages”。不同的操作系统,page size各不相同:
- M2芯片的Mac Studio操作系统:每个page为16KB
- RISC-V标准:每个page为4KB
- RISC Zero:每个page更小,为1KB
RISC Zero中,程序可使用约192MB的空间,寻址范围从0x0400到0x0c000000。该空间切分为pages,每个page 1KB。这些pages由page tables索引,这些page tables需要约6.7MB的空间,page tables空间的起始地址为0x0d000000。与现代操作系统类似,RISC Zero的这些page tables是multi-level的,具体如下图所示,展示了RIS Zero中guest程序内存空间的Multi-level page tables:
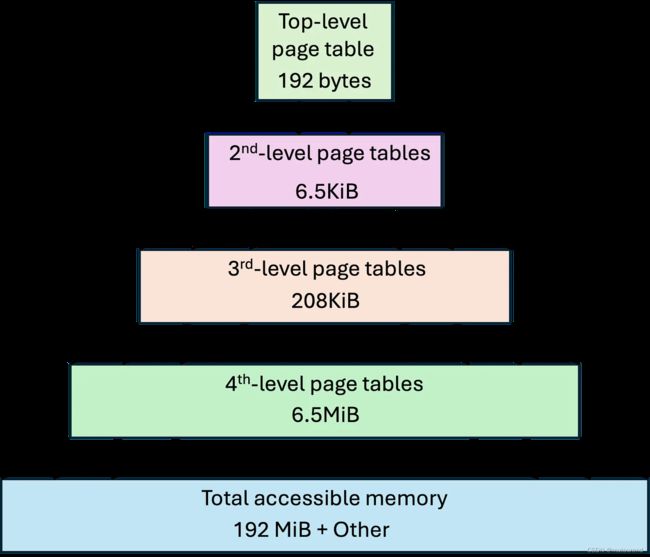
在RISC Zero guest程序中,当某page被首次访问时,RISC Zero需要“zk-load”该page,使得其数据被置入ZK电路可使用的authenticated format。执行结束时,RISC Zero将“zk-unload”该page——会验证该page以 与ZK电路执行一致的方式被修改。
注意,为load或unload某page,RISC Zero需load或unload其page table。换句话说,整个程序的首个指令,将load 5个page:
- 1)Page A:该指令所位于的page。
- 2)Page B:对A的4-th level page table。
- 3)Page C:对B的3-rd level page table。
- 4)Page D:对C的2-nd level page table。
- 5)Page E:top-level page table。
load或unload 每个page,将贡献约1094个cycles,除外情况为,top-level page table需要的更少——为754个cycles。可通过一个即将开放的工具来站看——整个执行过程中,load或unload的page数是如何变化的。如 Standalone VM and GDB stub for RISC Zero guest programs
——https://github.com/l2iterative/gdb0 中展示了相应的cycles输出:

对于运行在RISC Zero内的RISC-V程序,所需page cycles数量,取决于其执行过程中,需访问或修改的memory pages数量——也称为“memory footprint”。因此,优化时,有必要,避免在特定时间使用太多的内存。即,降低RISC Zero的peak memory。
3. From cycles to ZK proof
接下来,将解释cycles为何与ZK proving开销直接相关。这与RISC Zero的ZKP原理有关。RISC Zero的ZK电路文档不多,但代码是开源的。为理解其ZK proving 开销,首先理解RISC Zero的ZK。
简单来说,RISC Zero的证明系统可总结为:
- 1)UltraPlonk(或Halo2):算术化中包含了定制gates、高degree多项式relations、很多witness wires,以及lookup arguments。
- 2)FRI:使用FRI(fast Reed-Solomon interactive proof of proximity)来做polynomial evaluation和commitment。
- 3)BabyBear:其计算基于BabyBear域(模 15 ∗ 2 27 + 1 15*2^{27}+1 15∗227+1)定义。在algebraic holographic证明时,使用了BabyBear的degree-four extension 域。每个BabyBear元素存储了一个字节的数据。换句话说,对于32位整数,其使用4个BabyBear域。
- 4)Memory checking:尽管使用Merkle tree来authenticate pages,但main memory使用algebraic memory checking技术,使得每次对main memory的访问,仅引起一个常量的开销。
- 5)SHARK from Groth16:STARK proof可进一步,在不泄露信息和trustless的方式下,通过Groth16压缩为very succinct SNARK proofs。预计RISC Zero将通过Privacy Scaling Exploration(PSE)的public ceremony平台——P0tion为其SNARK电路举行setup ceremony。
当前,有RISC Zero的完整电路——但是编译器(Zirgen)将其高级描述编译的电路,目前Zirgen编译器暂未公开。Zirgen相关视频资料有:
- 2022年11月 cirgen: MLIR based compiler for zk-STARK circuit generation - Frank Laub (RISC Zero)
- 2023年12月 (Almost) effortless formal verification of ZK-circuits by Julian Sutherland (Nethermind Security)
通过这些Zirgen相关视频,有助于理解:
- 电路从何而来
- 为何需要Cirgen编译器,来实现效率、硬件不可知以及形式化验证
同时需注意,以上RISC Zero证明系统仅为当前情况,未来可能会很不相同。随着递归的开发(之前称为continuations),RISC Zero将更像某种“Plonk”,人们可定制其特定应用的RISC Zero变种。
想像一下未来,RISC Zero将成为不同ZK协议的hub,像Minecraft有多达15万+ 社区项目的大量改装/插件生态系统。此时,RISC Zero提供通用支持和公共特性——以RISC-V和SHA256/BigInt syscalls形式,以及作为电路生成(Zirgen)、远程proof委托和压缩(Bonsai)、派生自Zirgen的不同高效后端实现(包括CPU、Metal和CUDA)的基础设施。
其它目标平台的可执行文件——如WASM,可通过just-in-time编译器(JIT)转换为RISC-V。所谓just-in-time编译器(JIT),与Solana的JIT for VM——rbpf类似。
如下图所示,展示了基于RISC Zero 的proof系统潜在未来:

之前,人们“Rolling Your Own Crypto”的2大挑战在于:
- 1)挑战一:创建证明系统的技术和知识壁垒
- 2)挑战二:安全性方面信息不足
Zirgen可解决挑战一,(Almost) effortless formal verification of ZK-circuits by Julian Sutherland (Nethermind Security) 中Nethermind已讨论了其如何利用形式化验证。外行人可以创建一个特定于应用程序的、经过正式验证的、社区构建的证明系统——可能在GPT的帮助下——并不遥远,这可能是ZK证明系统的真正去中心化,它消除了ZK的“精英主义”风险。
RISC Zero中,约有6个ZK电路,其编码了RISC-V程序执行的约束,每个ZK电路具有不同size:
- 1)电路一:验证最多 32768 ( = 2 15 ) 32768 (=2^{15}) 32768(=215)个execution cycles。
- 2)电路二:验证最多 65536 ( = 2 16 ) 65536 (=2^{16}) 65536(=216)个execution cycles。
- 3)电路三:验证最多 131072 ( = 2 17 ) 131072 (=2^{17}) 131072(=217)个execution cycles。
- 4)电路四:验证最多 262144 ( = 2 18 ) 262144 (=2^{18}) 262144(=218)个execution cycles。
- 5)电路五:验证最多 524288 ( = 2 19 ) 524288 (=2^{19}) 524288(=219)个execution cycles。
- 6)电路六:验证最多 1048576 ( = 2 20 ) 1048576 (=2^{20}) 1048576(=220)个execution cycles。
为给指定RISC-V程序选择电路,RISC Zero:
- 首先运行该程序,并找出其完成需要多少个cycles。
- 然后,选择可处理该cycle数量的最小电路。
- 若程序执行需要多于 2 20 2^{20} 220个cycles,则整个执行将切分为segments,每个segment最多有 2 20 2^{20} 220个cycles。
- segment proof会通过递归证明进行合并。
所有这些电路都遵循很简单的结构:
- 1)Pre-loading sub-circuit:验证执行环境的初始化:【Pre-loading sub-circuit占用的空间,约为电路中的 N p r e = ∼ 1592 N_{pre}=\sim 1592 Npre=∼1592个cycles。】
- 1.1)对byte formality checking和RAM的lookup tables做初始化。
- 1.2)加载初始数据到RAM。
- 1.3)最后且最重要的是,禁用pre-loading特权。这类似于x86-64的"real mode"——booters以特权模式运行,然后,移除特权,切换到实际操作系统的“protected mode”。
- 2)Boby sub-circuit:对于后续的 ∼ 2 k − N p r e − N p o s t \sim 2^k-N_{pre} - N_{post} ∼2k−Npre−Npost cycles,验证每个cycle符合RISC-V CPU行为。
- 为高度重复电路,每个cycle都相互等价。
- page loading和page unloading均是在body sub-circuit中完成的。类似于操作系统需注意虚拟内存和分页管理。
- 3)Post-loading sub-circuit:
- 验证计算合理关闭
- 关闭对byte formality checking和RAM的lookup tables。
- Post-loading sub-circuit位于整个电路的末尾,其所需空间约为电路中的 N p o s t = ∼ 6 N_{post}=\sim 6 Npost=∼6 cycles。
- 可将其想象为是机器关机。
RISC Zero代码库中,body sub-circuit的定义见:【展示了RISC Zero zkVM的body阶段的约束系统构建】

可以看出,body sub-circuit非常简单,其重复向底层ZK电路的body wire写 1 1 1,直到post-loading。
与其它FRI证明系统类似,由于FRI不关心电路的稀疏,证明生成开销完全取决于电路size,或更准确来说,取决于使用以上6种电路中的哪一个。
换句话说,cycles数,是影响FRI证明系统的唯一因素。
需注意的是,最近也有利用稀疏性的证明系统,如:
- 1)a16z crypto的 Lasso+Jolt:其依赖于对,结构化的同态承诺方案的multilinear扩展,进行承诺
- 2)Ulvetanna的 Binius:为硬件友好编码的binary证明系统。
二者都与RISC Zero相关。个人认为Lasso+Jolt和Binius是两棵独立的樱桃树,它们包含非常不同的互补技术,未来版本的RISC Zero或其社区变体可以进行樱桃采摘。
由于周期是cycles需要考虑的全部,现在将注意力转向可以帮助研究特定程序的cycles的工具。
4. 深入RISC Zero cycles的profiler
深入RISC Zero cycles的profiler,开源代码见:
- https://github.com/l2iterative/profiler0
牢记,代码优化,首先应识别主要瓶颈。profile0工具可在代码中添加一些定时器:如“start_timer!”、 “stop_start_timer!” 和 “stop_timer!”,来验证RISC Zero中的FHE。
start_timer!("Total");
start_timer!("Load the bootstrapping key");
let bsk = black_box(unsafe {
std::mem::transmute::<&u8, &[GgswCiphertext; 16]>(&BSK_BYTES[0])
});
stop_start_timer!("Load the ciphertext to be bootstrapped");
let c = black_box(unsafe {
std::mem::transmute::<&u8, &LweCiphertext>(&C_BYTES[0])
});
stop_start_timer!("Perform trivial encryption and rotation");
let lut = black_box(GlweCiphertext::trivial_encrypt_lut_poly());
let mut c_prime = lut.clone();
c_prime.rotate_trivial((2 * N as u64) - c.body);
stop_start_timer!("Perform one step of the bootstrapping");
// set to one step
for i in 0..1 {
start_timer!("Rotate");
let rotated = c_prime.rotate(c.mask[i]);
stop_start_timer!("Cmux");
c_prime = cmux(&bsk[i], &c_prime, &rotated);
stop_timer!();
}
stop_timer!();
stop_timer!();
从而可看出不同的代码片段所贡献的cycles数。该profiler会跟随guest程序的执行,并统计相应cycles。具体cycles统计结果见:
- https://gist.github.com/weikengchen/59aabee17de6803927e594d9b56681ca
根据该profiler结果,总结如下:
- 1)加载bootstrapping key:15条指令,3297个cycles。
- 2)加载待bootstrapped密文:11条指令,11个cycles。
- 3)执行trivial encryption和rotation:66096条指令,123982个cycles。
- 4)执行bootstrapping 1024个步骤中的一步:151619979条指令,159597740个cycles:
- rotate:55930条指令,75670个cycles。
- cmux:151564031条指令,159520958个cycles。
总共有151686471条指令和159726565个cycles。
由此可看出,cmux占用了约99%的指令和约99%的cycles。注意,这仅是整个bootstrapping流程中的一个步骤,整个TFHE bootstrapping例子中有1024个类似的步骤。
接下来,自然是对cmux函数内部进行profile,并在TFHE库中添加如下profiling代码:
pub fn cmux(ctb: &GgswCiphertext, ct1: &GlweCiphertext, ct2: &GlweCiphertext) -> GlweCiphertext {
start_timer!("subtract the ciphertext");
let mut res = ct2.sub(ct1);
stop_start_timer!("external product");
res = ctb.external_product(&res);
stop_start_timer!("add the result");
res = res.add(ct1);
stop_timer!();
res
}
同时在external_product函数内添加profiling代码,external_product函数为性能关键所在。profiler0支持静态消息,也支持运行时生成的动态消息:
impl GgswCiphertext {
/// Performs a product (GGSW x GLWE) -> GLWE.
pub fn external_product(&self, ct: &GlweCiphertext) -> GlweCiphertext {
start_timer!("apply g inverse");
let g_inverse_ct = apply_g_inverse(ct);
stop_start_timer!("multiply");
let mut res = GlweCiphertext::default();
for i in 0..(k + 1) * ELL {
start_timer!(format!("i = {}", i));
for j in 0..k {
res.mask[j].add_assign(&g_inverse_ct[i].mul(&self.z_m_gt[i].mask[j]));
}
res.body
.add_assign(&g_inverse_ct[i].mul(&self.z_m_gt[i].body));
stop_timer!();
}
stop_timer!();
res
}
}
从而,cmux内部profile的数据信息为:【注意,添加profiler会注入少量指令,因此cmux cycle数会小幅增加。】
- 1)subtract the ciphertext:38495条指令,46163个cycles。
- 2)apply g inverse:79991条指令,167498个cycles。
- 3)multiply with i = 0:37840587条指令,39875485个cycles。
- 4)multiply with i = 1:37840584条指令,39759520个cycles。
- 5)multiply with i = 2:37840584条指令,39802186个cycles。
- 6)add the result:50816条指令,70525个cycles。
cmux中,总共有151565973条指令,159619414个cycles。
具体的profilier输出见:
- https://gist.github.com/weikengchen/aca15c4c9243299824ed3c7635d9ce1e
其中会给出触发大量cycles的指令位置,如下位置出现额外频繁:
0x200d18, 0x200d20, 0x200d74, 0x200d78, 0x200d7c
即表示这些位置在loop内。这些地址相互很近,提示其可能是单个函数的汇编代码,且该函数被重复调用,贡献了大多数cycles。尽管该profiler未显示具体的指令,如额外频繁的0x200d74,对应指令“lw s10, t5, 0”,但需要具体上下文来理解指令行为。
拥有上下文的最佳方式为:
- 返回具体场景
5. 使用GDB来做动态代码分析
之前提到,理解指令行为,需要具体的上下文,而拥有上下文的最佳方式为:
- 返回具体场景
因此,需要工具来返回具体场景,并查看代码情况,为此引入了GDB工具gdb0来匹配RISC Zero:
- https://github.com/l2iterative/gdb0
首先,以debug信息来编译程序,具体实现方式为:
- 1)在“guest”目录下的Cargo.toml中,添加如下信息:【若不添加,Rust程序可能会慢得莫名其妙。添加后,即使在debug模式下,也可对程序做必要的优化。】
[profile.dev]
opt-level = 3
[profile.dev.build-override]
opt-level = 3
- 2)以环境变量来编译guest,以启用RISC Zero debug模式:
RISC0_BUILD_DEBUG=1 cargo run
- 3)编译后的guest程序,为对RISC-V代码的标准的ELF文件,将其复制拷贝到gdb0目录。注意,一定拷贝“debug”目录下的已编译程序,而不是“release”目录下的。
cp ../vfhe0/target/riscv-guest/riscv32im-risc0-zkvm-elf/debug/method code
- 4)再次运行profiler,因该函数可能在不同的位置。该profiler的新结果见:【可看出地址0x200db0, 0x200db4, 0x200db8, 0x200dbc处的指令经常会(因读/写)引起大量cycles。】
- https://gist.github.com/weikengchen/b6ed8b2db86f555e45731ce3c92c4974
- 5)启动GDB,基于以上profiler输出,在0x200db0设置软件断点,然后请求GDB继续执行,结果输出如下界面:【运行至贡献大量开销的loop】

从而可看出: - 为何0x200db0被频繁调用
- 以及0x200db0属于哪里:在多项式乘法函数的inner loop中。
在设置断点时,GDB已尝试告知其对应src/ttfhe/poly.rs文件的Line 42。
接下来,看Rust源码是如何转换为RISC-V指令的。如,该inner loop中是做64位整数乘法和累加的,其看起来像:

此处,“bne”通常是指loop结束。
RISC Zero使用32位RISC-V,通过32位整数运算来模拟64位整数乘法。具体的32位整数运算由mul、mulhu、add等。这由Rust在编译过程完成,也可通过Godbolt来检查一致性。
6. 代码诊断
首先,正如VFHE库所否认的那样,当前执行negacyclic卷积的算法很native的,需要时间为 O ( n 2 ) O(n^2) O(n2)。换句话说,当对大小为1024的两个向量执行此操作时,代码将需要执行1048576个64位整数乘法,以及同时中间还有加载/保存数据的开销。
其他算法:
- 首先,排除了NTT,因为模是2^64,l2ivresearch不想改变它(为了与Zama兼容),所以整数NTT没有太大希望。然而,可像Zama一样,在复数上使用浮点NTT。Zama之所以采用这种看起来很重的方法——使用浮点——原因很简单:浮点在现代CPU上一点也不贵,因为它(像整数乘法那样)只需要几个周期,比整数除法便宜得多。
然而,RISC-V或RISC Zero的情况并非如此。官方文件提到,“浮点运算可能需要60-140个周期才能完成加法、减法、乘法和除法等基本运算。”在RISC Zero中,浮点运算的成本要高得多。基于与Zama Rand Hindi的对话,l2ivresearch得出结论,具有浮点的复数NTT可能不是ZK的解。 - 剩下的选项是non-NTT efficient的多项式乘法(或者,更具体和准确地说,negacyclic卷积)。l2ivresearch计划使用Karatsuba算法,该算法使用分治方式来执行计算,从而产生subquadratic开销。
这应该已经带来了两个数量级的加速。
另一个优化空间是找到特定于应用程序的优化机会。在TFHE中,当进行自举时,将GGSW密文乘以GLWE密文,关于这种乘法,一个非常有趣的事情是,GLWE将被分解为所有数字都很小的格式(即,应用逆G变换)。
这意味着实际上不必进行64位整数计算。在l2ivresearch的配置中,逆G变换的输出仅为8位。Karatsuba算法可以在这里和那里添加数字,因此只要Karatsubb的深度不太大,16位表示就应该是舒适的,以适应由于Karatsubo引起的中间结果。在32位数字中,可对其中两个数字进行编码,这将节省内存空间和加载/保存,并且可根据需要对其进行解码。
最后再回顾下64位整数乘法和累加 inner loop及其汇编代码:

inner loop中每次迭代具有约20条指令。若采用上面的压缩表示,可节约少量指令。然后剩余的指令有:
- 0x200da4 - 0x200dac:为sanity check,用于探测代码是否正在访问超过slice边界的位置。为rust safety相关指令。可能不能移除这些指令。
- 0x200db4 - 0x200dc4:t4用于存储rhs.coefs[N-j+1]的地址。其看起来非常可能可简化计算,如,使用“slli”来左移3位以实现乘以8的操作。有2个指针交叠移动,一个加8,另一个减8。所实现代码在 0x200df0 - 0x200df4。
- 若使用上面提及的压缩表示,有助于在一次迭代中做2个steps。
平均每个乘法贡献 36 ( = 37840587 / 1024 / 1024 ) 36(=37840587/1024/1024) 36(=37840587/1024/1024)个cycles。可通过以上优化进一步降低该值,且,由于Karatsuba可降低乘法次数,可降低总的乘法开销。
一个有趣的思想在于:
- 若可使用RISC Zero bigint syscall来模拟3个16位乘以64位乘法运算,但不确定其效率是否更优,因这有pack和unpack开销。
最后,若想在合理时间内,构建整个proof(共1024个steps),需要加速:
- 硬件加速
- 软件加速
l2ivresearch将测试RISC Zero的Metal GPU优化,其看起来似乎很强大,同时将了解RISC Zero continuation,以及如何并行为整个计算生成proof,从而可线性扩展以降低延迟。
l2ivresearch对RISC Zero的Zirgen工具很感兴趣,将开启定制化证明系统的新可能,尤其是添加有助于negacyclic卷积的向量化指令。
同时,还对RISC Zero Jeremy Bruestle在Discord中提及的具有 O ( n ) O(n) O(n)复杂度的probabilistic checking protocol感兴趣,不过这还在内部开发中。
参考资料
[1] l2ivresearch 2023年12月博客 Tech Deep Dive: Verifying FHE in RISC Zero, Part II
FHE系列博客
- 技术探秘:在RISC Zero中验证FHE——由隐藏到证明:FHE验证的ZK路径(1)
- 基于[Discretized] Torus的全同态加密指引(1)
- 基于[Discretized] Torus的全同态加密指引(2)
- TFHE——基于[Discretized] Torus的全同态加密 代码解析
RISC Zero系列博客
- RISC0:Towards a Unified Compilation Framework for Zero Knowledge
- Risc Zero ZKVM:zk-STARKs + RISC-V
- 2023年 ZK Hack以及ZK Summit 9 亮点记
- RISC Zero zkVM 白皮书
- Risc0:使用Continunations来证明任意EVM交易
- Zeth:首个Type 0 zkEVM
- RISC Zero项目简介
- RISC Zero zkVM性能指标
- Continuations:扩展RISC Zero zkVM支持(无限)大计算
- A summary on the FRI low degree test前2页导读
- Reed-Solomon Codes及其与RISC Zero zkVM的关系
- RISC Zero zkVM架构
- RISC-V与RISC Zero zkVM的关系
- 有限域的Fast Multiplication和Modular Reduction算法实现
- RISC Zero的Bonsai证明服务
- RISC Zero ZKP协议中的商多项式
- FRI的Commit、Query以及FRI Batching内部机制
- RISC Zero的手撕STARK
- RISC Zero zkVM guest程序优化技巧 及其 与物理CPU的关键差异
- ZK*FM:RISC Zero zkVM的形式化验证
- Zirgen MLIR:RISC-Zero的ZK-circuits形式化验证
- 以RISC Zero ZK Fraud Proof赋能Optimistic Rollups
- zkSummit10 亮点记
- 技术探秘:在RISC Zero中验证FHE——由隐藏到证明:FHE验证的ZK路径(1)