《中小银行运维架构:解密与实战》李丙洋_2021
目录
- 传统IT基础架构
-
- IT基础设施
- 网络架构
- 灾备架构
- 运维日常
-
- 系统监控
-
- 基础设施层监控
- 系统层监控
- 应用层监控
- 业务层监控
- 用户体验层监控
- 事件管理
-
- 事件管理流程
- 事件应急处理
- 事件管理制度及分级
- 事件管理优化
- 运维标准化
-
- 域名化
- 安全基线
- 基础运行环境标准化
-
- 操作系统
- 中间件运行规范
- 中间件编码规范
- 网络标准化
- 数据库标准化
- 立体化监控体系
-
- 监控体系
-
- 流行监控系统
-
- Nagios
- Ganglia
- Zabbix
- Open-Falcon
- Prometheus
- Elastic Stack组合
- 规划监控体系
- 监控指标模型
- 事件响应与监控告警
- 全链路监控
- 再谈监控
看了一部分章节,主要是监控体系这一块,另外也稍微了解了银行的IT基础架构是怎么样的
说实话这本书对实战也没什么帮助,对我来说看这本书也是扫盲性质的
传统IT基础架构
IT基础设施
网络架构
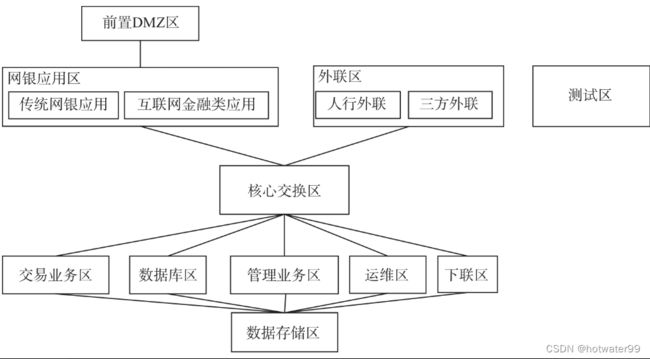
网络划分和隔离
灾备架构
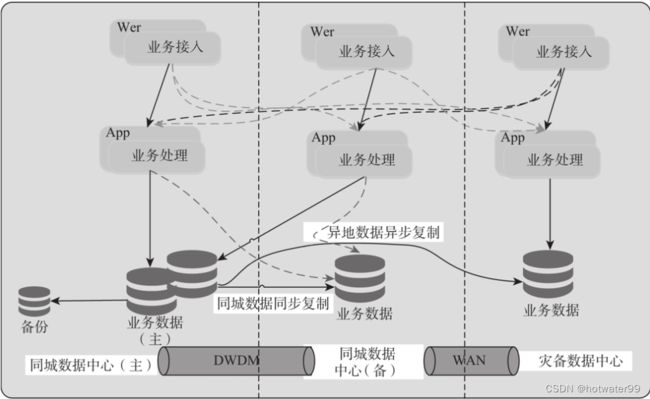
- 灾备网络层
- 全局负载均衡设计
- 跨中心链路设计
- 灾备服务器层
- 灾备数据库层
- 数据库层灾备架构的总体思路是当出现数据级灾难时,可以将读写切换至灾备机房
- 由于数据均已通过复制技术同步,因此数据并不会丢失
- 切换完成后可以使用灾备机房的数据库系统,继续对外提供服务
- 灾备存储层
运维日常
系统监控

基础设施层监控
- 从监控类型角度来看,基础设施层的监控要考虑状态监控(例如机房供电、硬件设备状态)、性能监控以及设备运行情况的监控(包括电流、电压、温度、湿度、资源使用率、端口流量、设备负载等)
系统层监控
- 物理服务器及网络设备监控
- 网络可用性监控
- 互联网出入口流量及可用性
- 机房间专线流量及可用性
- 网络设备各端口流量及可用性
- 虚拟化资源监控
- 存储及备份设备监控
- 安全设备监控
- IDS/IPS、WAF、日志审计、数据库审计、威胁检测等设备或系统的监控
- 这类设备有一个特点,就是误报率比较高,但每一次告警都不能轻视,因为安全无小事
应用层监控
- 从用户发起访问请求开始,包括在DNS解析、CDN响应速度及性能、负载均衡能力、应用软件/中间件/数据库的可用性及性能监控,以及访问安全等层面进行监控
- 对于多机房场景,还需要考虑机房间的交叉监控
- 分布式任务调度服务、分布式缓存、消息队列、分布式数据库、分布式存储等中间件,围绕中间件集群的健康状态、运行情况及性能展开监控
- 数据库,除了常规的数据库自身健康检查以外,日常最主要的关注点是缓存使用、连接统计、慢查询、锁数量、SQL读写性能、主从同步、集群状态等指标
业务层监控
- 关注关键业务功能是否正常,通过具体的业务功能模块,如发起注册、登录、交易、支付等服务,通过返回请求来判断业务能否正常运行
- 关注业务交易的整体情况和服务性能,如交易量、成功率、失败笔数、响应时间等具体指标,以及服务状态、日志刷新、端口监控、网络连通性等综合因素,每个业务系统都要根据自身的业务特点设计对应的监控项
用户体验层监控
页面响应时间、页面渲染时间、重要接口响应时间等
事件管理
- ITIL(Information Technology Infrastructure Library,信息技术基础架构库),由服务台、事件管理、问题管理、变更管理、配置管理、发布管理、服务级别管理组成
- 提升事件管理的时效性,让事件管理回归本质
- 事件处理要以尽快恢复生产运行为宗旨,控制影响范围,减少对生产业务运营的影响,保障服务的稳定性
事件管理流程

- 事件的接收和记录:事件统一由服务台负责接收(来源可以是用户、业务人员、IT部门人员或系统自动检测发现等),接收后服务台会对事件进行唯一编号,并记录事件基本信息(包括时间、症状、受影响服务、影响范围、影响用户等)。在实际处理过程中,还需要预判事件的严重程度,如果严重,则需要先向管理层报告再处理,如果严重级别不高,则直接进入“分类及初步支持”步骤
- 分类及初步支持:根据事件的类型、现象、影响度、紧急度、优先级等对事件进行初步处理。事件的分类和初步判断主要是通过事件知识库匹配,确定是否是曾经出现过的事件,若是出现过的事件,则可根据过往经验解决,若是从未出现过的事件,则需要转交给事件支持组排查做进一步调查和诊断
- 事件升级:在事件解决过程中,服务台需要跟进处理进度及情况,如遇到困难或事件影响范围较大,并且在事件管理制度约定的时间内仍然无法解决时,应将事件升级,增加事件处理技术人员,投入更多资源积极响应排查。事件升级渠道即从一线到二线、三线、四线支持,一线支持通常由服务台提供,二线支持通常由管理部门提供,可以是业务运维团队或信息系统管理人员,三线支持多由软件开发及系统架构人员提供,四线支持则由供应商提供
- 事件分析:在事件处理终止后,需要对事件进行复盘分析,排查事件发生原因,以及复盘整个处理过程可能存在的问题
- 事件复盘:在事件解决后,需要召集相关业务人员、运维人员、研发人员进行事件处理过程的回顾,同时也需要关注事件根本原因,以及是否有改进措施
- 事件报告:根据事件复盘情况,需要出具整个事件的分析报告,报告内容需要体现事件原因、发生时间、影响范围、处理过程、整改措施等
- 事件整改:在事件复盘后,为避免同类型事件重复发生,可能会提出一些整改措施,需要持续跟进,推动相关整改措施完成改进
- 事件库管理:在事件处理分析均完成后,需要将事件录入事件知识库,这样在下次遇到相同或类似问题时,可以提供处理参考意见,提高初步判断阶段的处理效率
事件应急处理
- 不管出现什么问题,对于IT运维团队来说最根本的追求就是保障系统可用,先恢复业务是第一位的,因此应急恢复的时效性是事件应急的关键指标
- 1 系统变更关联:大部分线上故障都与变更有关,确定故障现象后,如果事前有过变更操作,可以先分析故障是否由变更引起,进而快速定位故障并准备回滚等应急方案
- 2 避免全面性排查:在对系统进行排查时,应尽可能缩小范围,再协调关联团队排查,以避免各关联团队同时无头绪地排查,浪费资源
- 3 分析应用日志:运维人员要知道业务功能对应哪个服务进程,知道这些服务进程对应哪些应用日志,更要具备根据应用日志分析异常的能力
- 4 保护故障现场
- 为了避免手忙脚乱,要重视针对常见场景的应急方案,并且文档内容要注重实用性,明确当前应用系统在整个交易中的角色,明确这个服务影响什么业务以及服务涉及的日志、程序、配置文件在哪里,能用数据说明交易影响的情况,能定位到交易报错的信息
- 有了应急方案,如何持续更新也是难点,因此定期的应急演练非常有必要
事件管理制度及分级
- 为了能让生产事件得到充分的重视,在发生后得到快速处理,以降低事件带来的影响,相应的事件管理办法、制度流程必不可少
- 制度可以规范生产事件报告、响应、处置、上报、总结、问责等流程处理,明确生产事件的分级

事件管理优化
- 建立事件处理优先级
- 服务台接收到事件后,首先该做的是根据事件对用户和正常业务带来的影响严重程度来评估优先级。通过判断优先级,明确事件处理的先后顺序以及IT资源的投入,以此保障事件解决的时效性
- 最好能得到一个及时更新的配置管理数据库(CMDB)的支持,用以帮助评估事件的影响度和紧急度,最终确定事件的优先级
- 事件发生后,需要明确跟进责任人,对事件进行全程监控和跟踪处理
- 建立事件管理知识库
- 事件管理知识库可用于服务台接收事件后的查询,通过长期的积累和丰富,可以有效提升同类事件处理效率,也避免了不必要的事件处理流转
- 提供事件管理平台化工具
- 通过可视化界面支持,统一IT服务事件受理渠道,记录事件信息、处理流转情况及结果反馈,使事件得以快速推进并处理,变被动为主动
- 结合事件的优先级,设置不同优先级的事件在平台中的受理时长限制、资源配置等,通过平台化支持使资源分配得以落地
- 避免事件管理问题化
- 通常会有一个误区,就是把事件当成问题处理,在事件处理过程中过分关注事件如何解决,而不是把恢复服务放在首位
- 问题管理的主要目标当然是查明事件发生的潜在原因并找到解决方法以防止再次发生
- 事件管理过程中可能会采取一些临时解决方案,但永远强调把恢复中断业务作为首要目标
- 问题管理重质量,事件管理重时效,不能将两者混淆处理,以免降低事件处理时效性
- 规范事件管理流程
- 完善的制度可以明确约束事件管理的时效性、处理节点、各岗位职责等,以此规范事件管理的流程,并建立事件管理的重要性和时效性意识,从而更好地开展事件管理工作
运维标准化
- 不管是为了避免不必要的维护和改造工作量,还是为了更轻松地完成日常运维工作,又或是为了生产系统的安全稳定运行,都需要制定一套运维标准,让所有运维技术人员可以参照相同的规范去执行运维操作
域名化
安全基线
- 不管什么类型的设备,其初始化后的默认配置通常都不适合企业内的实际情况,某些配置方面的缺陷甚至可能导致安全问题,因此通过基线配置对各类设备设施进行加固就非常必要
- 银行业的重要信息系统会要求进行信息系统安全等级保护测评(简称“等保测评”),该测评的其中一项工作就是检查各类设备设施的安全基线是否合理配置
- 基线配置也可以算标准化的一部分,是运维标准化管理的一项日常工作
- 1 操作系统基线:对操作系统的设备账号认证、日志、协议、补丁升级、文件系统管理等方面的安全配置,对系统的安全配置审计、加固操作
- 2 网络设备基线:包括SNMP安全管理、其他设备安全管理、用户账号配置、日志审计配置、IP协议管理等
- 3 数据库基线:包括账号管理、认证授权、日志配置、通信协议、其他设备安全要求等基线配置
- 4 中间件基线:包括文件权限配置、用户账号配置、其他设备安全管理、日志审计配置等基线配置
- 对于不同版本、不同型号的设备,应该分别制定安全基线标准化文档
- 设立一个安全基线标准化的文档库,以不断维护、更新安全基线的执行标准
基础运行环境标准化
操作系统
- 内部yum源
- rsyslog配置
- 时区配置
- 统一的NTP时间同步服务器
- 开机启动项
- 参数优化
- 必要软件安装
中间件运行规范
- 排除版本差异运行异常
- 统一参数优化
- 降低安全风险
中间件编码规范
- 消息队列中间件规范化
- 命名规范
- 幂等性
- 缓存中间件规范化
- 键值设计
- 控制key的长度,避免过多占用内存
- 设计key时使用合适的数据类型,平衡资源和性能
- 拒绝bigkey,string类型控制在10KB以内
- hash、list、set、zset元素个数不要超过5000
- 冷热数据分离
- 按业务系统划分集群实例
- 安全设置
- 键值设计
网络标准化
- 网络区域规划
- 垂直分层、水平分区的网络架构,可以在不同网络层次及不同区域之间实现必要安全防范措施,形成水平和垂直两个方向的多层次的保护,使网络架构合理,边界区分明确,数据流向清晰,便于网络运维配置管理,同时也进一步提升了银行网络安全
- 网络设备命名
- A数据中心运维区的H3C5560型号的第1台交换机,其设备命名为:DCA-YW-SW-H3C5560-01。可以快速识别设备所在数据中心、区域、型号等信息,可谓清晰又直观,当发生网络告警时也有助于快速识别故障设备
- 网络地址规划
数据库标准化
- 参数配置
- 字符集。对于MySQL可选择utf8mb4
- 数据库隔离级别。数据库事务的隔离级别有4个,由低到高依次为Read Uncommitted、Read Committed、Repeatable Read、Serializable,这4个级别可以逐个解决脏读、不可重复读、幻读这几类问题
- 内存及连接数。这部分参数与数据库性能息息相关,参数的默认值是万万满足不了需求的,这类参数的配置除了基于经验,还需要考虑通过全面性能压测验证
- 日志参数。包括慢查询、二进制日志、重做日志等,要注意日常文件大小、输出路径
- 数据复制。根据场景需求,配置源和目标、同步模式等
-用户管理 - 用户命名
- 通过用户名即可识别用户分类
- 对数据库有读写操作的用户,用户名为数据库名+rw作为后缀
- 对数据库只有读操作的用户,用户名为数据库名+ro作为后缀,如果同一个库需要有多个读操作的用户,则用序号区分
- DBA在数据查询、自动化脚本编写时使用只读用户dbaro,对数据库实例进行管理使用超级管理员用户
- 对内部管理的不同角色创建不同用户,比如数据备份使用dbbackup、数据复制用户使用repl,业务系统用户名根据业务名称而定
- 密码管理
- 数据库的用户密码要强制符合强密码设置,避免数据库密码泄露引发安全事件,建议密码统一使用不低于8位的长度,包括数字、大写字母、小写字母、特殊字符
- 用户权限管理
- 新增加的应用分配的数据库用户权限严格按照权限最小化进行管理,比如一个应用的数据库权限默认只有insert、delete、update、select权限,如果不能满足需求,再根据实际需求评估是否可开通
- 对于数据库的访问应进行IP访问白名单控制
- 日志管理
- 中继日志和binlog日志不宜保留太长时间,建议设置自动清理MySQL中继日志和binlog日志。binlog日志在本地的保留时间可根据磁盘空间大小设置,通常建议本地保存7~14天
- 慢查询日志和错误日志管理
- 开发规范
- 命名规范
- 基本规范
- 统一存储引擎
- 添加注释
- 控制单表数据量
- 字段设计规范
- 选择最小数据类型
- 避免使用TEXT、BLOB
- 索引设计规范
- 单张表索引数量限制,建议含主键在内不超过5个
- 合理创建联合索引
- 主键字段限制,建议使用自增ID值
- SQL开发规范
- 查询条件参数与值类型匹配
- 查询字段按需获取
- 注意关联查询
- 避免JOIN多个大表且没有where条件过滤,如果程序中大量使用多表关联的操作,或者关联缓存join_buffer_size设置得不合理,很容易造成服务器内存溢出,从而影响数据库性能的稳定性
- 备份及恢复管理
- 实时备份。通过MySQL复制特性,在两个数据中心做主从复制,由此实现数据的实时备份,当主数据中心发生故障时,可用备数据中心的数据来恢复
- 定时备份。Xtrabackup
- 数据恢复
- 从业务连续性保障的角度出发,应定期对生产环境数据库进行恢复验证,包括验证备份数据恢复执行过程,验证数据有效性,验证恢复状态,验证应用调用数据库是否正常等
- 演练完成后,还应该记录好操作过程、现象及结果,对于演练过程中遇到的问题也需要特别关注其发生的原因并找到解决办法
- 当生产数据库真正遇到需要从数据备份来恢复数据的情况时,备份数据是唯一能恢复生产运行的希望,如果不能恢复,其打击可以说是毁灭性的
立体化监控体系
监控体系
流行监控系统
Nagios
- 服务端运行的守护进程会定时通过NRPE(Nagios Remote Plugin Executor)访问远程主机上的脚本,获取脚本执行结果
- NRPE由运行于服务端的check_nrpe和运行于每个被监控服务器本地的NRPE守护进程两部分组成。NRPE所访问的脚本也可以理解成插件,相当于提供一套服务端与客户端通信的框架

Ganglia
- 运行在各个节点上的gmond进程采集CPU、内存、硬盘、网络流量情况等方面的数据,然后汇总到gmetad服务端,由gmetad通过RRDtool存储数据,最后将历史数据通过gweb组件进行界面化展示
- Ganglia的特色是收集数据,并可将所有数据汇总到一个界面集中展示,能够支持多种数据接口,可以方便地扩展监控
- Ganglia本身也能支持集群化部署,不管是gmond还是gmetad都可以横向扩展,也可以说Ganglia天生支持分布式监控架构

Zabbix
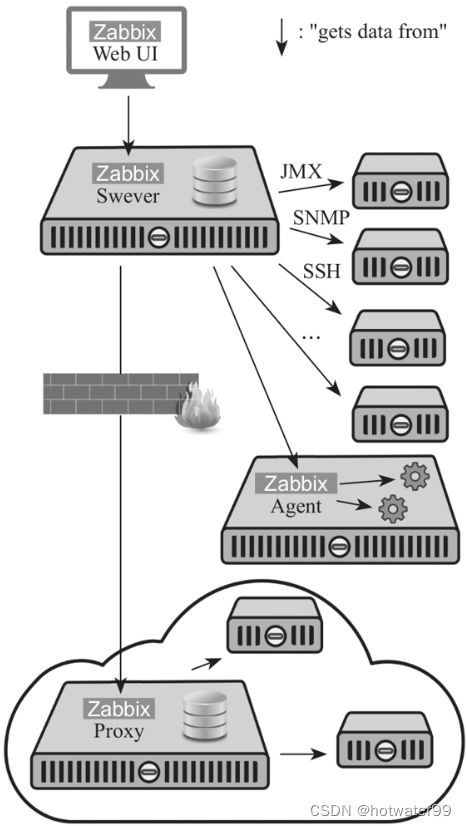
- 企业级开源分布式监控解决方案,支持从数以万计的服务器、虚拟机、网络设备中收集指标数据
- Zabbix对容器层监控的支持并不太好
- Zabbix监控体系是由Zabbix Server(服务端)、客户端Agent、数据库服务以及Proxy(可选组件)组成
- Zabbix Server用来获取Agent采集到的各项数据,并将这些数据存储到数据库中,当Agent节点很多,单台Server无法响应时,就会使用Proxy这个可选组件来分担Zabbix Server的负载
Open-Falcon
- 小米运维团队开源的企业级监控工具,实现了对服务器、操作系统、中间件、应用等的全面监控,是一款灵活、可扩展并且高性能的监控解决方案
- 在设计层面Open-Falcon把微服务、模块化思想进行到底,由众多模块组成
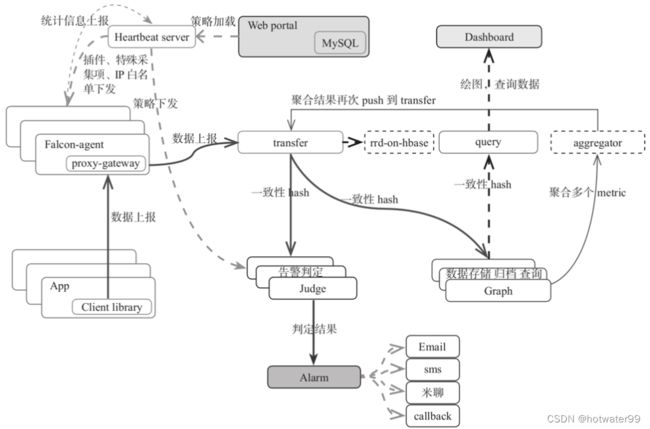
- Falcon-agent:专用于数据上报的本地代理,自动发现、自动采集,每台服务器上都要安装。另外,Falcon-agent还提供了一个proxy-gateway,用户可以通过HTTP接口将数据push到gateway,再由gateway转发到服务端
- Heartbeat server(以下简称HBS):心跳服务器,简称HBS服务。每个Agent都要定期连接HBS服务上报自己的状态,包括主机名、IP地址、Agent版本和插件版本,并从HBS获取自己要采集的端口或进程信。HBS支持水平扩展,可以通过类似LVS这类组件提供VIP给Agent连接,而无须对Agent节点做任何变更
- transfer:转发相关的服务,用于接收Agent上报的监控数据,并对数据进行处理,根据一致性Hash规则对数据进行分片,而后推送给Judge和Graph组件
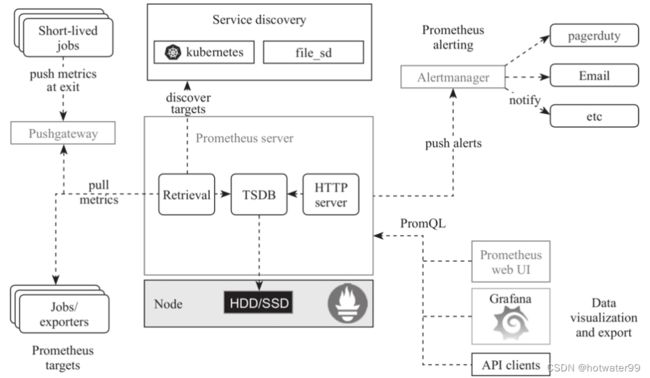
Prometheus
- Prometheus是一款真正面向服务监控而设计的监控系统,非常适合虚拟化环境的VM或Docker容器,是为数不多的适合Docker、Kubernetes(以下简称K8S)环境的监控系统
- Prometheus通过HTTP周期性抓取被监控节点的数据,只要目前对象提供了HTTP接口,并且返回的数据符合Prometheus定义的数据格式,就可以接入监控系统,不需要任何SDK或者其他集成过程
- Prometheus的本质是时间序列数据库
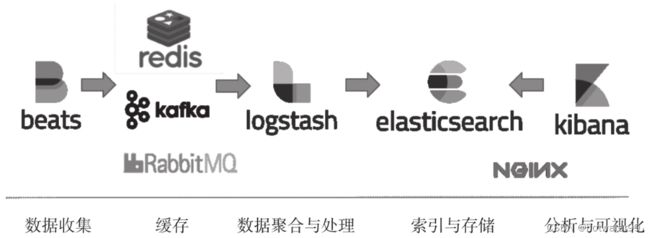
Elastic Stack组合
- ElasticSearch是基于Lucene的开源分布式搜索引擎
- Logstash是服务器端数据处理管道,可以对日志进行收集、过滤、分析等操作,能够同时从多个来源采集、转换数据,然后将数据发送到如ElasticSearch中存储
- Kibana是ElasticSearch的前端展示工具,可以让用户在ElasticSearch中使用图形和图表对数据进行可视化
规划监控体系
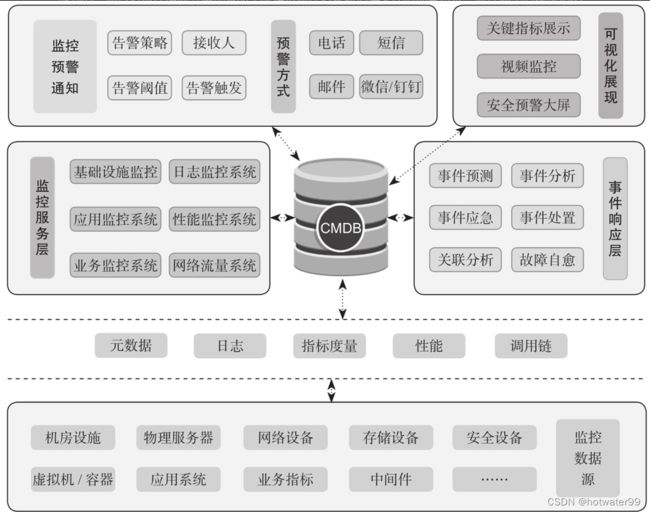
- 监控数据源层
对应各类监控对象,通过数据源获取包括监控元数据、日志、度量值、性能状态、分析调用链等在内的各类信息 - 监控服务层
完成各项监控数据的收集、存储和分析。数据主要来自监控数据源层,部分基础元数据会来自CMDB
监控指标模型
延迟(Latency):表示请求所需花费的时间
流量(Traffic):表示系统承载的用户或交易的量级
错误数(Error):表示当前系统发生错误的评价维度
饱和度(Saturation):表示当前资源使用的饱和情况
事件响应与监控告警
- 事件管理系统需要对外提供统一接口,以实现对外部系统事件的对接
- 事件管理系统要收集和汇总来自不同系统的各类事件,实现监控事件集中管理、聚合收敛、关联分析
- 要对包括基础监控、业务监控、全链路监控等在内的各套监控系统的告警信息进行事件多维度分析,为实现事件的关联分析、应急处置策略、事件影响范围评估、故障预测等智能化分析提供数据支持,为故障自愈的实施提供支持
- 要通过系统,对事件的发现、处置、定级、跟踪等进行流程化管控,通过对事件提供统一受理入口,解决IT运维团队多系统对接处理困境,提升事件响应效率
- 事件的关联分析是形成故障树
- 一是如何评估事件的影响或重要性,也即给出其处理优先级(建议)
- 二是如何处理,也即制定清晰的事件应急响应策略(知识库)
全链路监控

- 性能和稳定性
- 性能损耗
- 最好能做到根据服务的流量来动态调整采集样本比例,通过配置采样率,只对一部分请求分析链路调用关系
- 如果组件的稳定性不足,那么容易导致全链路的稳定性沦陷
- 代码侵入性
- 建议在公共组件和中间件上做文章
- 扩展性
- 处理能力扩展
- 插件的多样性
- 数据分析及展示
再谈监控
- 对于监控任务达到一定量级的企业,需要设置专职监控体系建设团队,持续增加和优化监控系统工具
- 需要设置专职指标优化团队,作为监控系统的使用者,持续推动监控指标的补充完善,推动监控系统功能建设
- 在监控实施过程中不能片面地追求监控指标的覆盖度,监控的核心目标是为业务稳定运行保驾护航,从实施层面来看,监控归纳起来就两条:少漏报和少误报