2-多媒体数据压缩国际标准
文章目录
- 多媒体数据压缩编码的重要性和分类
-
- 为什么要压缩?
-
-
- 计算: 未压缩音频的数据率
- 简答: 环绕声系统-作业题9(简述7.4.3全景声)
- 计算: 未压缩图像的数据量-作业题10(估计尺寸及容量)
- 计算: 未压缩视频的数据率
-
- 为什么能压缩?
- 数据压缩编码的两大类
-
- 无损压缩
-
- 算法: LZ77-作业题6-(简述LZ77算法的思想)
- 算法: LZ78
- 算法: RLE-作业题7(RLE编码的适用范围)
- 算法: Binary RLE(不懂)
- 影响数据压缩的因素-作业题5(列举压缩/解压缩算法的常用评价指标)
- 常见数据压缩方法分类与基本原理
-
- 量化与向量量化原理
-
- 量化原理
- 矢量量化
- 算法: Huffman编码-作业题12
- 算法: 算术编码-作业题13
- 算法: 预测编码(不懂)
- 变换编码
-
- 算法: DCT变换(离散余弦变换)-作业题14(试分析DCT和DFT变换)
- 音频压缩标准
-
- 话音编码基础
- 三种话音编码器
-
- 波形编译码器-作业题15(试对比 CD 和 SACD 所采用的编码方式)&作业题16(简述 ADPCM 的基本思想)
- 音源编译码器-作业题17(简述音源编译码器基本原理)
- 混合编译码
-
- 简答: ACELP(代数码激励线性预测)-作业题18(简述 ACELP 的基本思想)
- MPEG Audio
-
-
- 简答: MPEG-1-作业题19(简述 MPEG1 Audio 中 L1/L2/L3 区别)
- 算法: MPEG-2 Audio
-
- Pre-Echo
-
- Dolby Audio
-
-
- 简答: Dolby AC-3-作业题22(以 Dolby AC-3 为例,分析消除多声道冗余有哪些可行途径)&作业题23(试分析 Dolby EAC-3 中“Spectral Extension”利用了哪些听觉特性)
-
- 移动通信网中的音频编码
-
- GSM系统中使用的四种编码
-
- 简答: EVS-作业题20(与传统移动通信网络中的话音编码相比,EVS 引入了哪些新思想)
- 蓝牙音频编码-作业题21(LC3 对提高音频质量有哪些思想)
多媒体数据压缩编码的重要性和分类
为什么要压缩?

计算: 未压缩音频的数据率
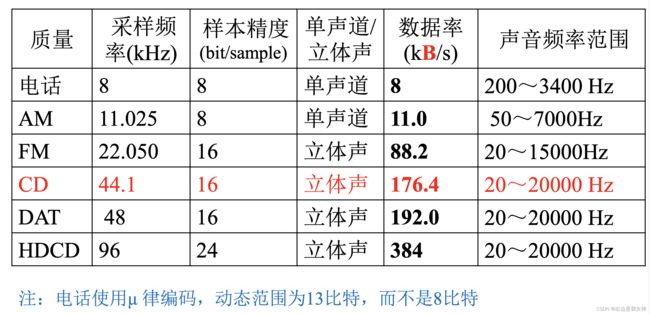
采样频率 ( H z ) × 样本精度 ( b i t ) × 声道数 采样频率(Hz)\times 样本精度(bit)\times 声道数 采样频率(Hz)×样本精度(bit)×声道数
上述公式的数据单位为 b i t / s bit/s bit/s, 注意转换.
简答: 环绕声系统-作业题9(简述7.4.3全景声)
环绕声道需要处理全频段的音频信号,因此这些声道的采样频率通常为 40kHz;重低音声道主要处理低频信号,这些声道可能只需要处理低于约 200Hz 的音频信号。因此重低音声道的采样频率可以低于环绕声道。
计算: 未压缩图像的数据量-作业题10(估计尺寸及容量)

dpi: 每英寸长度内像素个数.
通常是24位: RGB共3个通道,每个通道用8位表示.


计算: 未压缩视频的数据率

为什么能压缩?
信息量: 从N个相等的可能事件中选出某一事件所需的信息度量和含量. 从数学上定义信息量为 I ( P ( x ) ) = − log 2 ( P ( x ) ) ( b i t ) I(P(x))=-\log_2(P(x))(bit) I(P(x))=−log2(P(x))(bit)

数据压缩编码的两大类

无损压缩
算法: LZ77-作业题6-(简述LZ77算法的思想)
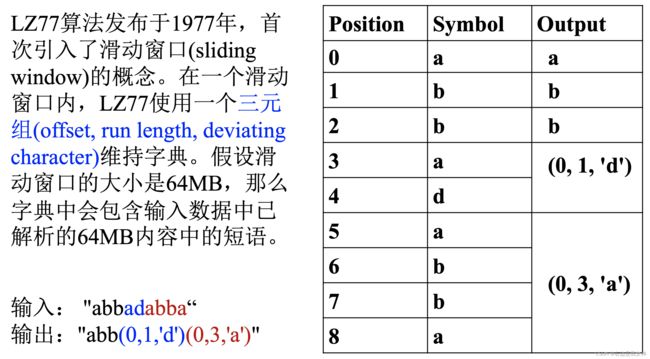

O: 与压缩位置的偏移距离;
L: 匹配长度;
C: 匹配字符串的下一个位置的字符;
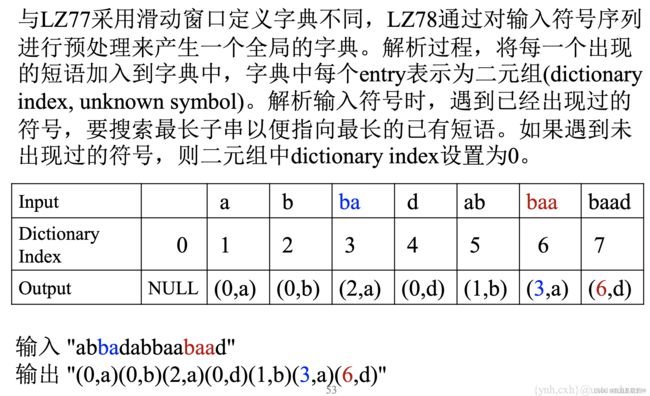
算法: LZ78
算法: RLE-作业题7(RLE编码的适用范围)

重复性高, 简单的图形图像.
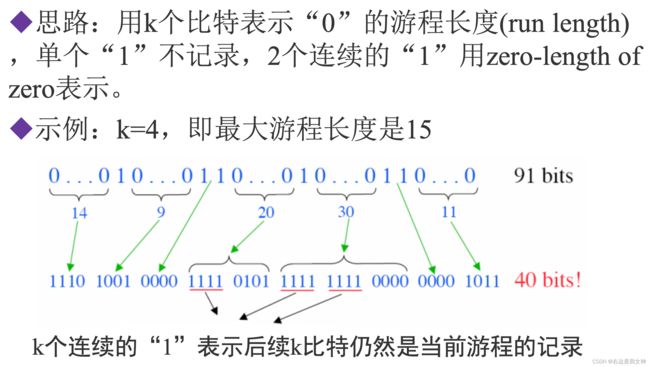
算法: Binary RLE(不懂)
影响数据压缩的因素-作业题5(列举压缩/解压缩算法的常用评价指标)
- 压缩比: 压缩前后的文件大小和数据量进行比较;
- 速度: 分为压缩速度和解压缩速度;
- 质量: 客观评估(通过一种具体算法来统计多媒体数据压缩结果的损失)和主观评估(给予人的视觉感知);
- 硬件/软件: 硬件和软件的选取与压缩/解压缩算法的复杂度有密切关系;
- 功耗: 低碳.
常见数据压缩方法分类与基本原理

量化与向量量化原理
量化原理
量化的目的: 量化处理是使数据比特率下降的强有力措施.
量化的本质: 量化处理把一批输入量化到一个输出级上, 所以量化处理是一个多对一的处理过程, 是不可逆的过程. 因此, 量化中存在信息丢失, 即引起量化误差.
数据压缩编码中的量化不是指A/D变换后的量化, 而是指以PCM码为输入, 经过正交变换, 差分, 或预测处理后, 熵编码之前, 对正交变换系数, 差值或预测误差的量化处理.
均匀量化与非均匀量化.
矢量量化
矢量量化编码是图像, 语音信号编码技术中的一种新型量化编码方法.
矢量量化编码方法一般是有失真编码方法.
矢量量化相对于标量量化而提出. 对于PCM数据, 一个数一个数地进行量化叫标量量化. 对这些数据分组, 每组K个数构成一个K维向量, 以向量为单元进行量化, 称为矢量量化.
均匀量化:是一种将信号连续幅度均匀分层的量化方法。
非均匀量化:是一种在输入信号的动态范围内量化间隔不相等的量化方法。
标量量化:对于PCM数据,一个数一个数地进行量化的方法。
矢量量化:对于PCM数据,先分组,每组K个数构成一个K维矢量,然后以矢量为单元,逐个矢量进行量化的方法。
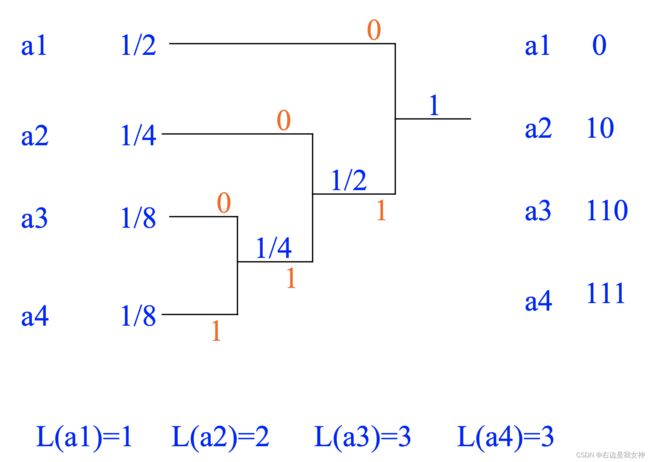
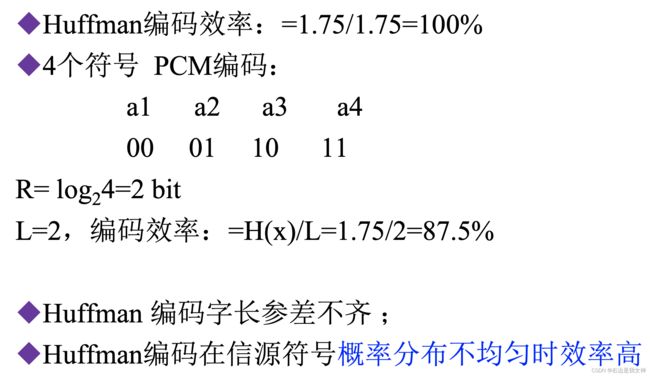
算法: Huffman编码-作业题12
利用变字长最佳编码实现信源符号按概率大小顺序排序.


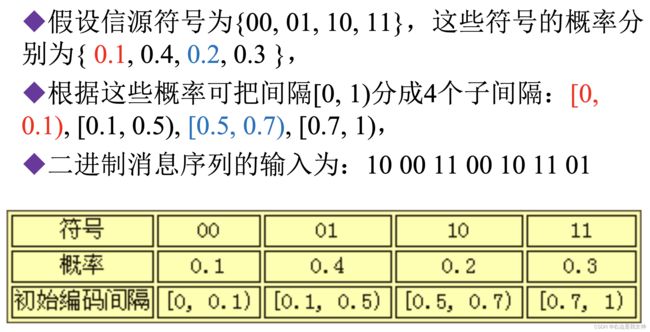
算法: 算术编码-作业题13

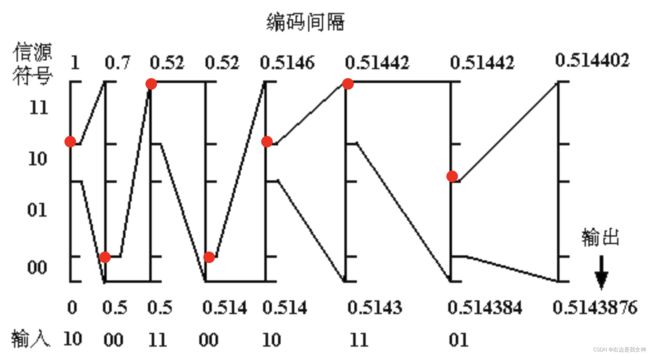

算法: 预测编码(不懂)

变换编码
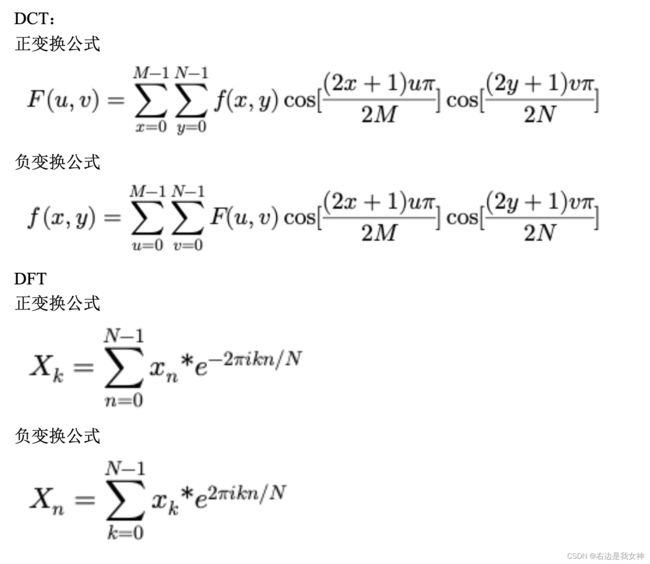
算法: DCT变换(离散余弦变换)-作业题14(试分析DCT和DFT变换)
DCT将图像分成由不同频率组成的小块,然后进行量化。在量化过程中,舍弃高频分量,剩下的低频分量被保存下来用于后面的图像重建。
DCT 8*8图像块
- 将图像分解为8*8的图像块
- 将表示像素的RGB系统转换成YUV系统
- 然后从左至右,从上至下对每个图像块做DCT变换,舍弃高频分量,保留低频分量
- 对余下的图像块进行量化压缩,由压缩后的数据所组成的图像大大缩减了存储空间
- 解压缩时对每个图像块做DCT反转换(IDCT),然后重建一幅完整的图像
试分析DCT和DFT的区别,并写出正变换与反变换的公式。
DCT 为离散余弦变换,DFT 为离散傅里叶变换。他们在处理信号的方式上有所 不同,主要区别为:
- 信号类型:DFT适用于复数信号,DCT适用于实数信号。
- 变换核:DFT 使用复指数函数作为变换核,DCT 使用余弦函数作为变换核。
- 能量集中性:DCT比DFT更能集中能量。
音频压缩标准
话音编码基础

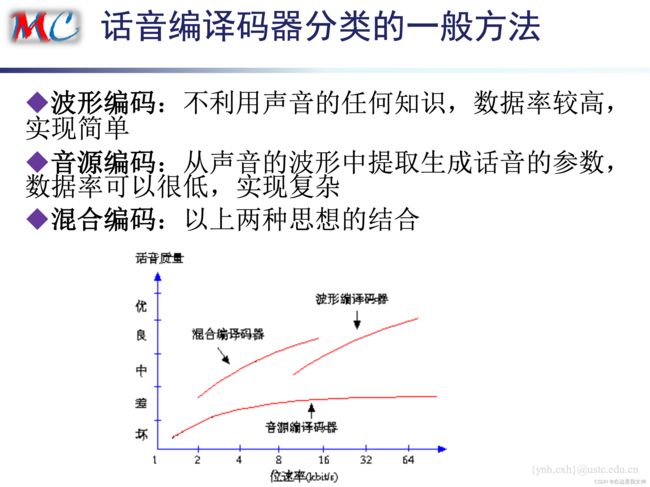
三种话音编码器
波形编译码器-作业题15(试对比 CD 和 SACD 所采用的编码方式)&作业题16(简述 ADPCM 的基本思想)
代表: PCM(脉冲编码调制)
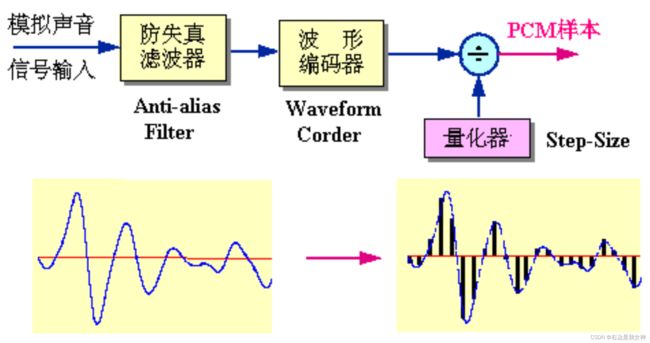
采样, 量化(分级), 编码(不同等级按规则编码, 二进制)的过程.
DM(增量调制):
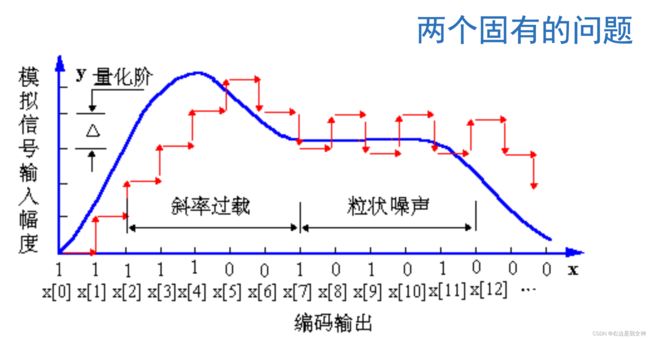
在对语音信号采样时,编码系统会比较相邻两个时刻的采样值,若信号幅度增加,则编码为1;若信号幅度减少,则编码为0.
斜率过载:当输入信号变化速率过快时,比较器的输出跟不上输入信号的快速变化(输出时山峰高度不够)。
粒状噪声:当输入信号变化较慢时,相邻两个采样值的差值非常接近0,此时比较器的输出会在0和1之间跳变。

传统光盘的编码方式: 采用PCM, 16bit, 采样频率为44.1kHz;
SACD: 采用DM, 1bit, 采样频率为2.8224MHz.
APCM:自适应脉冲编码调制. 根据信号特性动态调整脉冲编码,以在不同信道条件下实现更高的传输效率和可靠性。在好的信道条件下,它可以使用更多的编码符号,减少每个符号的振幅(位数),从而实现高速传输,而在较差的条件下可以通过增加振幅来提高可靠性。
DPCM:差分脉冲编码调制.DPCM的主要思想是在传输数据前对信号的差分进行编码,而不是直接编码原始信号样本。DPCM首先计算相邻信号样本之间的差异,然后将这些差异进行编码。这种方法可以减小数据中冗余信息,因为通常相邻样本之间的差异较小。
ADPCM:自适应差分脉冲编码调制.差分编码:ADPCM采用差分编码方式,通过计算相邻采样点之间的差异来表示音频信号。这意味着它不直接编码原始采样值,而是编码差分值,通常用于表示音频信号中的变化。ADPCM的一个重要特点是自适应性,即它可以根据音频信号的特性自动调整编码参数,以更好地适应不同的音频信号。这可以提高编码效率和音质。
G.721: G.721,也称为ADPCM(Adaptive Differential Pulse Code Modulation),是国际电信联盟(ITU)发布的一项标准,用于数字音频编码和压缩。
子带编码(SBC): 略.
音源编译码器-作业题17(简述音源编译码器基本原理)

线性预测编码(LPC): 略.

混合编译码
简答: ACELP(代数码激励线性预测)-作业题18(简述 ACELP 的基本思想)
EFR是一种ACELP编码器.
ACELP(Algebraic Code Excited Linear Prediction)的思想是将语音信号编码和压缩为尽可能小的比特率,同时保持足够高的音频质量。为了实现这一目标,ACELP采用了以下核心思想:
线性预测编码(Linear Predictive Coding,LPC):ACELP基于LPC模型,该模型用于描述语音信号中的声道特性。通过LPC分析,ACELP可以估计语音信号的谱特性,从而对声音进行分解。
代数码激励:ACELP引入了代数码激励的概念,它表示语音信号的激励部分。这个概念允许ACELP使用代数码方式来表示语音信号的激励,包括脉冲序列、激励码本身和声道增益。这种表示方式更有效地捕捉了语音信号的特性,尤其是非周期性和瞬时特性。
自适应性:ACELP具有自适应性,它可以适应不同的语音信号和信道条件。编码器根据输入信号的特性来选择最佳的模型参数,以更好地匹配信号,从而提高编码效率和音频质量。
低比特率编码:ACELP的一个关键目标是以较低的比特率对语音信号进行编码。这种低比特率编码使其在有限的带宽和存储资源下非常有用,如移动通信、VoIP通话等。
总之,ACELP的思想是通过代数码激励、LPC分析和自适应性来高效地表示和编码语音信号,以实现高质量的语音传输和存储。这一思想使其成为许多语音编码标准的基础,用于实现高效的语音通信和语音存储。
MPEG Audio


简答: MPEG-1-作业题19(简述 MPEG1 Audio 中 L1/L2/L3 区别)
视频和音频的第一个压缩标准. MPEG代表动画图像专家组, "1"表示第一个.
MPEG-1 分为三代, 第三代最为出名, 称为MP3.
在每一代之间,在保留相同的输出质量之外,压缩率都比上一代高。
与JPEG类似,MPEG-1音频编码标准也是一个有损压缩系统。但MPEG-1音频编码标准对于高抽样速率的立体声音频信号来说,能够实现透明的、感觉无损的压缩。

MPEG-1 Layer1采用每声道192kbit/s,每帧384个样本,32个等宽子带,固定分割数据块。子带编码用DCT(离散余弦变换)和(快速傅立叶变换)计算子带信号量化bit数。采用基于频域掩蔽效应的心理声学模型,使量化噪声低于掩蔽值。量化采用带死区的线性量化器,主要用于数字盒式磁带(DCC)。
MPEG-1 Layer2采用每声道128kbit/s,每帧1152个样本,32个子带,属不同分帧方式。采用共同频域和时域掩蔽效应的心理声学模型,并对高、中,低频段的比特分配进行限制,并对比特分配、比例因子,取样进行附加编码。Layer2 广泛用于数字电视,CD-ROM,CD-I和VCD等。
MPEG-1 Layer3采用每声道64kbit/s,用混合滤波器组提高频率分辨率,按信号分辨率分成6X32或18X32个子带,克服平均32个子带的Layer1,Layer2在中低频段分辨率偏低的缺点。采用心理声学模型2,增设不均匀量化器,量化值进行熵编码。主要用于ISDN(综合业务数字网)音频编码。

算法: MPEG-2 Audio

Pre-Echo
在声音信号的主要音频事件(如声音冲击或音符)之前出现短暂的、低音量的回声。

Dolby Audio


简答: Dolby AC-3-作业题22(以 Dolby AC-3 为例,分析消除多声道冗余有哪些可行途径)&作业题23(试分析 Dolby EAC-3 中“Spectral Extension”利用了哪些听觉特性)




移动通信网中的音频编码
GSM系统中使用的四种编码
在GSM(Global System for Mobile Communications)系统中,有四种主要的语音编码方法,通常称为GSM编码算法。这些编码方法用于将语音信号转换为数字格式以在移动通信网络中传输。以下是这四种GSM编码方法:
Full Rate (FR) 编码:全速率编码是GSM系统中最常用的编码方法之一。它采用编码率为13 kbit/s的编码器,将语音信号转换为数字格式。Full Rate 编码提供了相对较高的音质,适用于标准语音通话。
Half Rate (HR) 编码:半速率编码是为了在GSM系统中减少带宽占用而引入的。它采用编码率为5.6 kbit/s的编码器,将语音信号压缩,然后以更低的速率进行传输。半速率编码适用于一些不那么关键的语音通话情境,以降低网络负载。
Enhanced Full Rate (EFR) 编码:增强全速率编码是一种高质量的语音编码方法,采用更高的编码率(12.2 kbit/s)来提供更好的音质。EFR 编码通常用于提供高质量语音服务,如音频会议和高级通信服务。
Adaptive Multi-Rate (AMR) 编码:自适应多速率编码是一种更先进的语音编码标准,与GSM系统中的传统编码方法略有不同。AMR 编码采用可变比特率,具有多个不同的编码模式,以根据网络条件和需求动态选择合适的编码方式。这使其能够提供更好的音质和更高的效率,适用于各种通话情境。
这四种编码方法在GSM网络中提供了不同的平衡,可以根据通话质量要求和网络条件来选择合适的编码方式。不同的编码方法在音质和带宽利用率方面有所不同,因此可以根据特定情况进行选择。通常,Full Rate 编码用于标准通话,Half Rate 编码用于降低带宽占用,而EFR和AMR编码用于高质量语音通话和特殊服务。
简答: EVS-作业题20(与传统移动通信网络中的话音编码相比,EVS 引入了哪些新思想)
EVS(Enhanced Voice Service)引入了一些新的思想和技术,以改进语音编码和提供更高质量的音频传输。以下是一些EVS引入的新思想和特点:
高音质范围:EVS 支持更宽的音频带宽范围,允许传输更多的音频频率成分,从而提供更高质量的音质。这扩展了语音编码的范围,提供更自然和清晰的声音。
可变比特率:EVS 具有可变比特率的能力,允许根据网络条件和需求自动调整编码比特率。这使其能够在不同网络环境下提供适当的音质,同时最大程度地减小网络带宽的利用。
宽带语音和高清音频支持:EVS 提供宽带语音和高清(HD)音频质量的支持,使通话更生动逼真。这是一项重大改进,使音质接近面对面交流。
多编码模式:EVS 支持多个编码模式,根据通话内容和网络条件进行自适应选择。这包括单声道和立体声编码,以适应不同的应用场景。
自适应性:EVS 具有高度自适应性,可以动态调整编码参数以适应不同语音内容和网络条件,从而提高编码效率和音频质量。
多媒体应用:EVS 不仅适用于语音通话,还可用于多媒体通信,如视频通话、语音邮件和音频流媒体。这使其支持更广泛的通信应用。
总之,EVS 引入了更高音质、可变比特率、宽带语音、多编码模式和自适应性等新思想,以满足现代通信需求,特别是在高速移动通信网络和高清语音通话方面。它的设计旨在提供卓越的语音通信体验,并在多种应用中提供更高质量的音频传输。
蓝牙音频编码-作业题21(LC3 对提高音频质量有哪些思想)
LC3,全名为"Low Complexity Communication Codec",是一种低复杂度的语音编解码器,旨在提供高质量的音频通信体验。LC3 的设计目标是将其用于多种通信应用,包括语音通话、音频会议、语音助手和音频流媒体等。
以下是 LC3 编解码器的一些关键特点和亮点:
高音质:LC3 提供出色的音质,支持宽带语音通信,使声音更加自然和清晰。
低复杂度:LC3 具有低复杂度的特点,这意味着它可以在资源受限的设备上高效运行,包括移动设备和嵌入式系统。
多应用支持:LC3 适用于各种通信应用,从传统的语音通话到高质量音频通信,以及音频流媒体和多媒体通信。
自适应性:LC3 具有可变比特率的能力,可以根据网络条件和需求调整编码参数。这使其能够在不同网络环境下提供适当的音质,同时最大程度地减小网络带宽的利用。
开放标准:LC3 是一个开放标准,这意味着它可以在各种设备和平台上广泛应用,而不受特定供应商的限制。
LC3 的出现旨在提供更好的音频通信体验,特别是在现代通信技术中的各种应用中。它强调了音质、低复杂度和灵活性,使其成为许多通信设备和服务的理想选择。这个编解码器可以应用于各种领域,改进了音频通信的质量和性能。
LC3(Low Complexity Communication Codec)在提高音频质量方面采用了一些关键思想和技术,以确保用户在各种通信应用中获得更好的听觉体验。以下是一些 LC3 改善音频质量的思想:
宽带音频支持:LC3 支持宽带音频通信,这意味着它能够传输更多的音频频率成分,从而提供更自然和清晰的声音。这比传统窄带编码器能够提供更高质量的音频。
可变比特率:LC3 具有可变比特率的能力,可以根据网络条件和需求动态调整编码参数。在良好的网络条件下,它可以提供更高比特率以获得更高的音质,而在带宽受限或不太理想的网络环境下,它可以减小比特率以维持通信。
低复杂度编解码:LC3 被设计为低复杂度编解码器,这意味着它可以在资源受限的设备上高效运行,而不会增加过多的计算负担。这有助于确保在各种设备上实现更好的音频质量,包括移动设备和嵌入式系统。
自适应性:LC3 具有自适应性,它可以根据通话内容和网络条件动态调整编码参数,以提高编码效率和音频质量。这使其能够在不同网络环境下提供一致的音质和通信质量。
噪声处理: 
LD-MDCT:
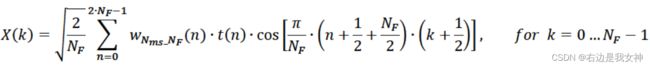
LD-MDCT(Low-Delay Modified Discrete Cosine Transform)是一种变换编码方法,通常用于音频和语音编码中。它被设计为在低延迟通信或实时音频处理应用中使用,以提供高质量的音频编码和解码。以下是对LD-MDCT的主要特点和工作原理的介绍:
低延迟编码:LD-MDCT 的一个主要特点是低延迟编码。这意味着它可以在实时通信和音频处理应用中使用,例如电话通话、音频会议和音频流媒体,而不引入显著的通信延迟。
MDCT 变换:LD-MDCT 使用了MDCT(Modified Discrete Cosine Transform)变换,这是一种广泛用于音频编码的技术。MDCT 变换可以将时间域的音频信号转换为频域,使编码器能够更有效地表示音频信号的频谱特性。
量化和编码:LD-MDCT 采用量化和编码方法,将频域系数映射为数字数据。编码器使用压缩算法对频域系数进行编码,以减小数据传输或存储的需求。
自适应性:LD-MDCT 可以具有自适应性,根据音频信号的特性和网络条件来调整编码参数。这有助于在不同通信环境下提供一致的音质和通信质量。
高音质:尽管低延迟是其主要特点,LD-MDCT 也注重音质。它可以提供相对高质量的音频编码,特别适用于实时通信中要求高音质的场景。
应用领域:LD-MDCT 可以用于各种通信应用,包括语音通话、音频会议、音频流媒体以及实时音频处理应用。它适用于需要低延迟的情况,同时要求较高音质的应用。
总的来说,LD-MDCT 是一种在低延迟通信和实时音频处理中使用的音频编码方法,它结合了低延迟和高音质的要求,以满足不同应用场景的需要。