ShardingSphere数据库分库分表、数据库中间件
shardingSphere
- 一、了解
-
- 1.1、简介
- 1.2、垂直切分
- 1.2、水平切分
- 1.3、分库分表应用和问题
- 二、Sharding-JDBC
-
- 1.1、简介
- 1.2、springboot整合实现水平分库、分表
-
- 1.2.1 水平分表
- 1.2.2 水平分库
- 1.3、springboot整合实现垂直分库、分表
-
- 1.3.1、垂直分库
- 1.4、Sharding-jdbc公共表
- 1.5、sharding-jdbc读写分离
- 三、Sharding-proxy
-
- 1.1、简介
- 1.2、下载安装
- 1.3、修改配置
- 1.4、分库分表配置
- 1.5、主从复制配置
- 四、执行原理
-
- 1、`sql解析`
- 2、`sql路由`
- 3、`SQL改写`
- 4、`SQL执行`
- 5、`结果归并`
一、了解
1.1、简介
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
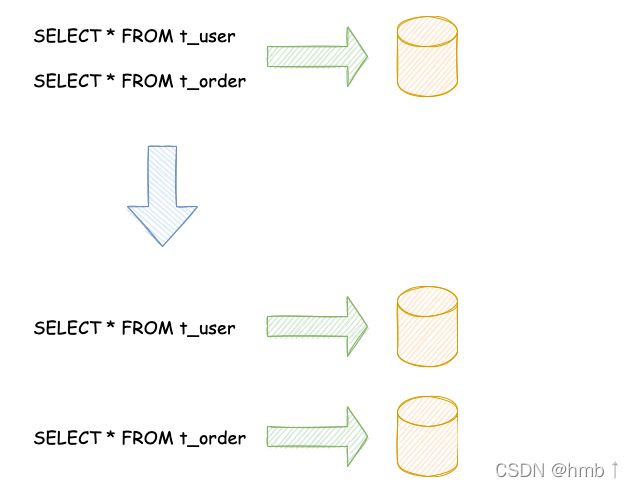
1.2、垂直切分
它的核心理念是专库专用,就是根据业务,把我们的数据存在不同的数据库上。如下图用户和订单表存在两个数据库上。
1.2、水平切分
相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。

1.3、分库分表应用和问题
应用:
- 在数据库设计时考虑垂直分库和垂直分表(将一个表的字段拆分成两个表)
- 随着数据量的增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库,水平分表。
- 数据量很大的项目适合分库分表
问题:
- 跨节点连接查询问题(分页、排序等)
- 多数据源管理问题
二、Sharding-JDBC
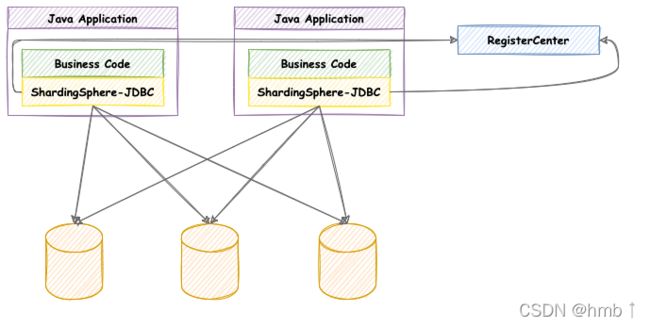
1.1、简介
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
1.2、springboot整合实现水平分库、分表
1.2.1 水平分表
实现内容:
id是奇数数据保存到表1,id是偶数保存到表2
就是根据配置文件实现分库分表,以下是代码示例
1、引入sharding-jdbc依赖
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
其他依赖 druid、mysql、mybatisplus
2、新建两张表
表字段一样。

3、配置
更多详情配置看官网
5.x版本
4.x版本:4.x版本配置
水平分表配置:
spring.main.allow-bean-definition-overriding=true #这个配置没加可能会报错
# 配置真实数据源
spring.shardingsphere.datasource.names=m1
# 配置第 1 个数据源
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/sharding-jdbc?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
## 配置第 2 个数据源
#spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
#spring.shardingsphere.datasource.ds2.jdbc-url=jdbc:mysql://localhost:3306/sharding-jdbc?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
#spring.shardingsphere.datasource.ds2.username=root
#spring.shardingsphere.datasource.ds2.password=123456
# 标准分片表配置
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
# <table-name>
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
# 注意事项
# 行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}。
# 分布式序列策略配置: 指定course表里主键id生成策略为雪花
# 分布式序列列名称 <table-name>
spring.shardingsphere.sharding.tables.course.key-generator.column=id
# 分布式序列算法名称 <table-name>
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 分表策略,# 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
4、测试示例
插入成功,观察数据库
可以看到,已经按我们想要奇数插入 表1,偶数插入表2
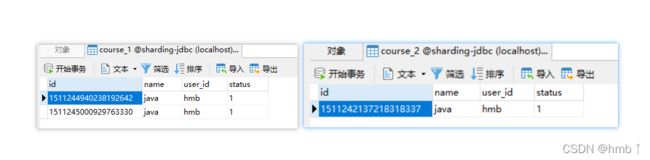
分表后查询测试
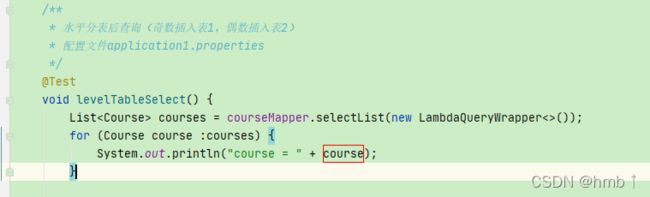
可以看到把两个表的数据都查询出来了
 测试代码:
测试代码:
package com.example.demo;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.example.demo.entity.Course;
import com.example.demo.mapper.CourseMapper;
import org.junit.jupiter.api.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
class DemoApplicationTests {
@Resource
private CourseMapper courseMapper;
/**
* 水平分表添加数据(奇数插入表1,偶数插入表2)
* 配置文件application1.properties
*/
@Test
void levelTableAdd() {
Course course = new Course();
course.setName("java");
course.setUserId("hmb");
course.setStatus("1");
courseMapper.insert(course);
}
/**
* 水平分表后查询(奇数插入表1,偶数插入表2)
* 配置文件application1.properties
*/
@Test
void levelTableSelect() {
List<Course> courses = courseMapper.selectList(new LambdaQueryWrapper<>());
for (Course course :courses) {
System.out.println("course = " + course);
}
}
}
1.2.2 水平分库
1、在另一个库里新增一样的表
 2、修改配置
2、修改配置
spring.main.allow-bean-definition-overriding=true
# 配置真实数据源
spring.shardingsphere.datasource.names=m1,m2
# 配置第 1 个数据源
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/sharding-jdbc?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://你的第二个库ip:3306/sharding-jdbc?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456
# 标准分片表配置
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
# <table-name>
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
# 注意事项
# 行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}。
# 分布式序列策略配置: 指定course表里主键id生成策略为雪花
# 分布式序列列名称 <table-name>
spring.shardingsphere.sharding.tables.course.key-generator.column=id
# 分布式序列算法名称 <table-name>
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 分表策略,# 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{id % 2 + 1}
# 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。
# 没写表名,就是所有的表
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
#指定表分库
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
相较于分表,多了分库的策略

测试示例
测试代码和上面一样,这里不在贴出来。
直接看结果
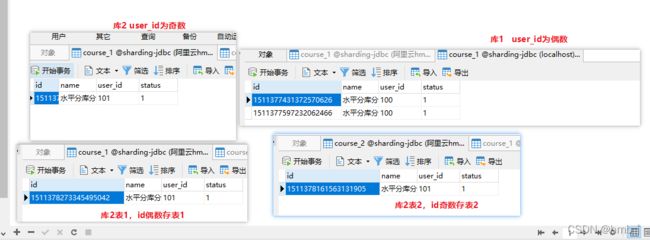 查询结果,两个库和四个表的数据都查询出来了。
查询结果,两个库和四个表的数据都查询出来了。

1.3、springboot整合实现垂直分库、分表
1.3.1、垂直分库
1、配置文件
spring.main.allow-bean-definition-overriding=true
# 配置真实数据源
spring.shardingsphere.datasource.names=m1,m2
# 配置第 1 个数据源
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/sharding-jdbc?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://你的第二库ip:3306/sharding-jdbc?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456
#--------------------------------------------------user表------------------------------------------------
spring.shardingsphere.sharding.tables.user.actual-data-nodes=m2.user
#配置数据库里面的user专库专用
spring.shardingsphere.sharding.tables.user.key-generator.column=user_id
# 分布式序列算法名称 <table-name>
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 分表策略,# 分库策略,user表插入到表2
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user
#--------------------------------------------------course表------------------------------------------------
# 标准分片表配置
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
# <table-name>
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course1
# 注意事项
# 行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}。
# 分布式序列策略配置: 指定course表里主键id生成策略为雪花
# 分布式序列列名称 <table-name>
spring.shardingsphere.sharding.tables.course.key-generator.column=id
# 分布式序列算法名称 <table-name>
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#指定表分库
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=course1
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
测试代码示例
package com.example.demo;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.example.demo.entity.Course;
import com.example.demo.entity.User;
import com.example.demo.mapper.UserMapper;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
/**
* 垂直分库,对应配置application3.properties
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class VerticalDataBase {
@Autowired
UserMapper userMapper;
/**
* 垂直分库,user表的数据插在库2
*/
@Test
public void verticalDataBaseAdd() {
User user = new User();
user.setUserId(111L);
user.setUsername("垂直分库");
user.setUstatus("1");
userMapper.insert(user);
}
/**
* 垂直分库后查询
*/
@Test
public void verticalDataBaseSelect() {
List<User> Users = userMapper.selectList(new LambdaQueryWrapper<>());
for (User user :Users) {
System.out.println("user = " + user);
}
}
}
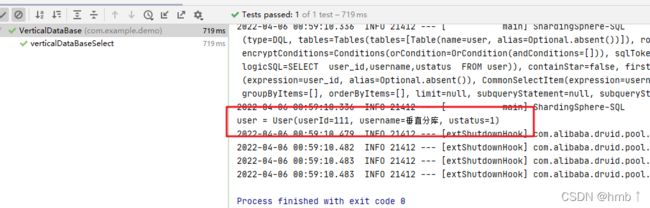
测试结果,插入user,就到表2的user,插入course就到表1去

执行查询方法也都能查出来
1.4、Sharding-jdbc公共表
1、公共表:
- 存储固定数据的表,表数据很少发生变化,查询时经常进行关联
- 在每个数据库种创建相同结构公共表
- 操作表时,
会往所有的表一起操作(如添加数据,每个数据库这个公共表都会一起添加)

2、添加配置
#--------------------------------------------------配置公共表------------------------------------------------
spring.shardingsphere.sharding.broadcast-tables=dict
spring.shardingsphere.sharding.tables.dict.key-generator.column=d_id
spring.shardingsphere.sharding.tables.dict.key-generator..type=SNOWFLAKE
3、代码测试
/**
* 公共表,对应配置application4.properties
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class PublicTable {
@Autowired
DictMapper dictMapper;
/**
* 公共表,会往所有的公共表都添加数据
*/
@Test
public void publicTableAdd() {
Dict dict = new Dict();
dict.setValue("11");
dict.setDstatus("11");
dictMapper.insert(dict);
}
/**
* 公共表,会往所有的公共表都修改数据
*/
@Test
public void publicTableUpdate() {
Dict dict = new Dict();
dict.setValue("22");
dict.setDstatus("22");
UpdateWrapper<Dict> wrapper = new UpdateWrapper<>();
wrapper.eq("d_id",718974918749847553L);
dictMapper.update(dict,wrapper);
}
/**
* 公共表,会往所有的公共表都删除数据
*/
@Test
public void publicTableDel() {
dictMapper.deleteById(718974918749847553L);
}
}
测试成功,表都一起操作。
1.5、sharding-jdbc读写分离
前提条件,mysql已经配置过主从复制
配置可以看:mysql主从复制
添加修改配置:
# 主库从库逻辑数据源定义 ds0 为 user_db
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-sourcename=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-sourcenames=s0
# 配置 user_db 数据库里面 t_user 专库专表
#spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user
# t_user 分表策略,固定分配至 ds0 的 t_user 真实表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
jdbc——Git仓库地址:
链接: https://gitee.com/hmb000/sharding-jdbc.git
三、Sharding-proxy
1.1、简介
定位为透明化的数据库代理端,就是开着程序帮我们代理。

1.2、下载安装
下载地址:https://shardingsphere.apache.org/document/current/cn/downloads/
4.x版本:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/downloads/
解压后文件夹
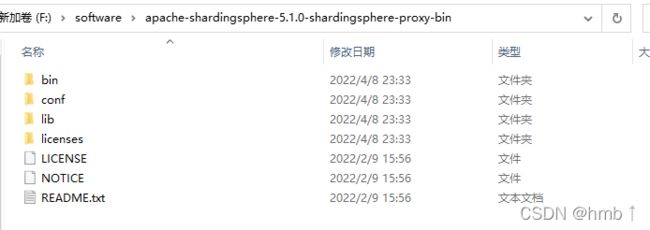
1.3、修改配置
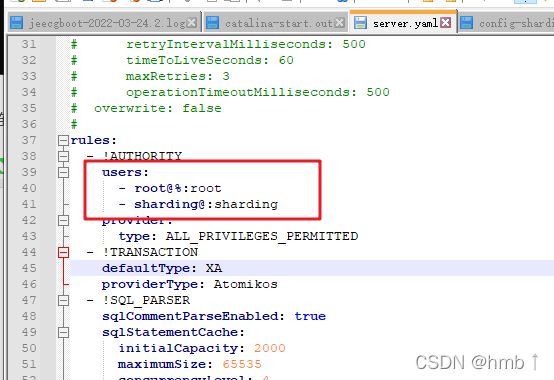
1、打开conf文件,修改server.yml

打开注释,可以在这里配置用户权限,详细配置看
链接: https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-proxy/yaml-config/authentication/
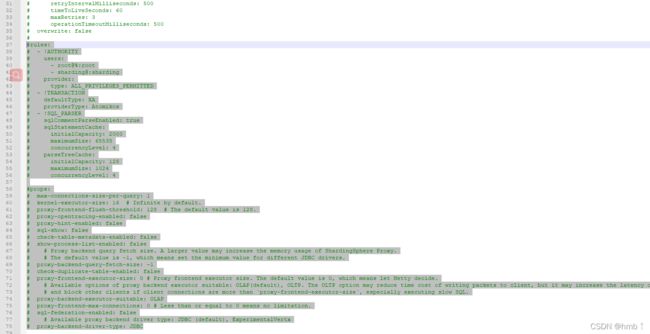
4.x版本从authentication下面放开注释

2、复制mysql驱动
在你的maven仓库中找到mysql驱动
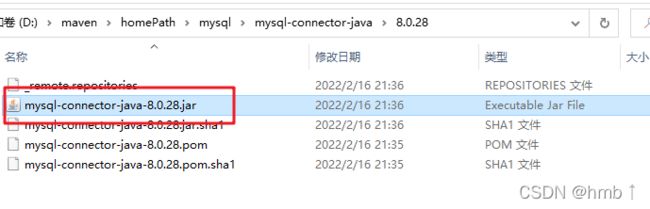
复制到sharding-proxy的lib里
 3、、修改config-sharding.yaml添加分片配置的规则
3、、修改config-sharding.yaml添加分片配置的规则
直接复制这个改一下,配置往下看

4、启动
直接打开bin文件里start。window用bat文件,linux用sh文件
5.x启动成功界面:
 4.x启动成功界面
4.x启动成功界面
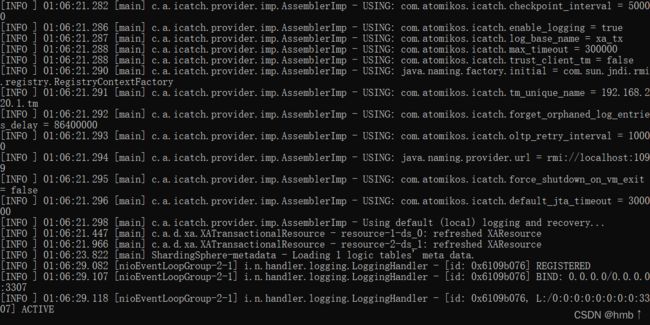
连接sharding-proxy代理的数据库,默认端口3307,
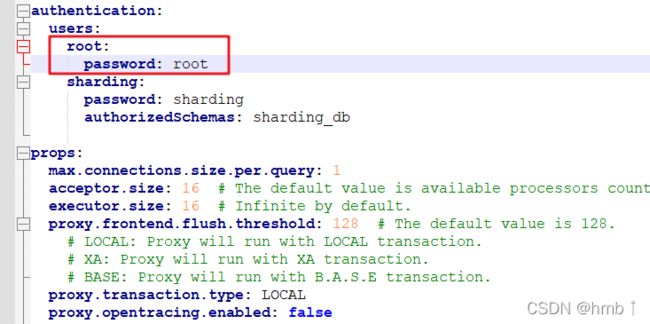
账号密码就是你server.yml的配置,如我的配置账号密码都是root

5.x版本:
4.x版本:
我配置的连接的两个数据的表
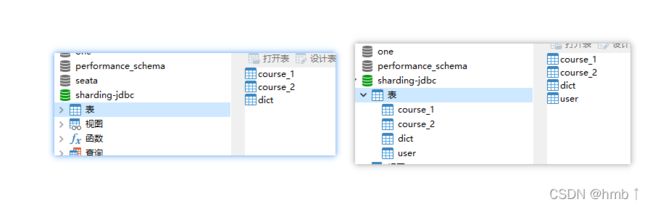
连接后可以看到我们配置的两个数据库的表和数据,proxy都集中在这里了,
比如我course表里面的数据,是我数据源1和数据源2的course表聚合在一起的。

1.4、分库分表配置
配置在配置文件里都有例子,大家自己跟着改一下就可以了
4.x版本:
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_item_id
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy:
none:
5.x版本:
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/sharding-jdbc?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://你的第二个ip:3306/sharding-jdbc?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
#第1个表规则为,id为偶数就添加到数据源1,在添加到表2,奇数添加到数据源2,表1(添加数据源和表的字段自己去区分开就能分库分表了,这里只是做简单的例子)
course:
# 标准分片表配置, 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
actualDataNodes: ds_${0..1}.course_${1..2}
tableStrategy:
standard:
# 分库分表策略,以id为分片键
shardingColumn: id
# 策略名,对应下方的 shardingAlgorithms里的配置规则名
shardingAlgorithmName: course_inline
# 指定course表里主键id生成策略为雪花
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
#第二个表规则为,指定user数据就直接添加到数据源2的user表
user:
# 标准分片表配置, 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
actualDataNodes: ds_1.user
tableStrategy:
standard:
# 分库分表策略,以id为分片键
shardingColumn: user_id
# 策略名,对应下方的 shardingAlgorithms里的配置规则名
shardingAlgorithmName: user_inline
# 指定user表里主键id生成策略为雪花
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
#绑定表规则列表
bindingTables:
- course,user
defaultDatabaseStrategy:
standard:
shardingColumn: id,user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
# 分库分表策略
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${id % 2}
course_inline:
type: INLINE
props:
algorithm-expression: course_${id % 2+1}
user_inline:
type: INLINE
props:
algorithm-expression: user
keyGenerators:
snowflake:
type: SNOWFLAKE
scalingName: default_scaling
scaling:
default_scaling:
input:
workerThread: 40
batchSize: 1000
rateLimiter:
type: QPS
props:
qps: 50
output:
workerThread: 40
batchSize: 1000
rateLimiter:
type: TPS
props:
tps: 2000
streamChannel:
type: MEMORY
props:
block-queue-size: 10000
completionDetector:
type: IDLE
props:
incremental-task-idle-minute-threshold: 30
dataConsistencyChecker:
type: DATA_MATCH
props:
chunk-size: 1000
修改完配置启动后,在sharding-proxy代理的数据库执行添加语句。

添加成功,course根据我们的配置自动添加到了数据源2的表2,而sharding_db有着所有的数据。
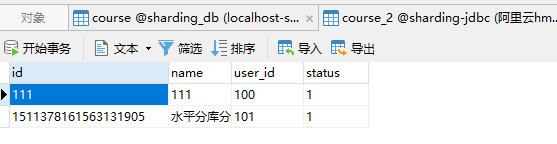 查看proxy代理的数据库course表此时的数据
查看proxy代理的数据库course表此时的数据

所以我们在项目上代码上都不需要修改,
.
只需要配置直接连接sharding-proxy的数据库,执行语句时,就会直接帮我分配到各个数据源去了。
.
而我们配置的各个表的数据都会聚合在proxy的数据库中。所以查全部就可以直接查出来
1.5、主从复制配置
修改config-readwrite-splitting.yaml文件
前提,mysql已经配置好主从复制
schemaName: readwrite_splitting_db
dataSources:
write_ds:
url: jdbc:mysql://127.0.0.1:3306/demo_write_ds?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
read_ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_read_ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
read_ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_read_ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
# 直接指定哪个库是写,哪个库是从。
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
type: Static
props:
write-data-source-name: write_ds
read-data-source-names: read_ds_0,read_ds_1
修改后启动,我的写会自动写在我们配置的库里,读会从从库里读。
四、执行原理
 执行步骤:
执行步骤:
1、sql解析
我们查询时,查询的时逻辑表,不是真实表,sharding会根据关键字位置改写我们的sql,使其能够查询到真实的数据库。
例如sql为:
SELECT user_id,name FROM t_user WHERE status = 'NORMAL' AND age > 18;
会将我们的sql解析成以下几部分
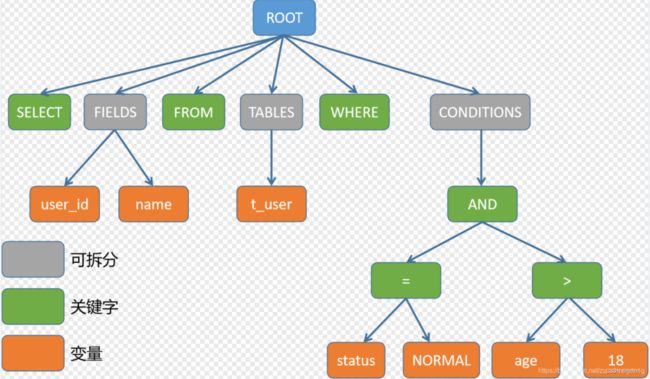
2、sql路由
SQL路由就是把针对逻辑表的数据操作映射到对数据结点操作的过程。根据解析上下文匹配数据库和表的分片策略,并生成路由路径。
根据分片键进行路由的场景可分为直接路由、标准路由、笛卡尔路由等。
标准路由:
标准路由是Sharding-Jdbc最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是BETWEEN或IN时,则路由结果不一定落入唯一的库(表),因此一条逻辑SQL最终可能被拆分为多条用于执行的真实SQL。
拆分例子:
SELECT user_id,name FROM t_user_0 WHERE status = 'NORMAL' AND age > 1;
SELECT user_id,name FROM t_user_1 WHERE status = 'NORMAL' AND age > 1;
笛卡尔路由:
笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。
SELECT user_id,name FROM t_user_0 a left join t_order_0 b ON a.id = b.user_id WHERE a.status = 'NORMAL' AND a.age > 1;
SELECT user_id,name FROM t_user_0 a left join t_order_1 b ON a.id = b.user_id WHERE a.status = 'NORMAL' AND a.age > 1;
SELECT user_id,name FROM t_user_1 a left join t_order_0 b ON a.id = b.user_id WHERE a.status = 'NORMAL' AND a.age > 1;
SELECT user_id,name FROM t_user_1 a left join t_order_1 b ON a.id = b.user_id WHERE a.status = 'NORMAL' AND a.age > 1;
全库表路由:
对于不携带分片键的SQL,则采取广播路由的方式。根据SQL类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这5种类型。其中全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL(数据查询)和DML(数据操纵),以及DDL(数据定义)等。
SELECT user_id,name FROM t_user_0 WHERE name = 'NORMAL';
SELECT user_id,name FROM t_user_1 WHERE name = 'NORMAL';
SELECT user_id,name FROM t_user_2 WHERE name = 'NORMAL';
和标准查询区别是 : 标准查询有分片字段,可以根据分片的配置找到配置的那几个表,全库表查询不携带分片键,会查询配置的所有数据库
3、SQL改写
因为我们在开发过程中面向逻辑表书写的SQL并不能够直接在真实的数据库中执行,需要将逻辑SQL改写为能在真实数据库中可以正确执行的SQL。
例如逻辑sql:
SELECT name FROM t_user WHERE user_id=1;
会根据配置被改写为
SELECT name FROM t_user_0 WHERE user_id=1;
SELECT name FROM t_user_1 WHERE user_id=1;
还有一种情况,当Sharding-JDBC需要在结果归并时获取相应数据,但该数据并未能通过查询的SQL返回。 这种情况主要是针对GROUP BY和ORDER BY。结果归并时,需要根据GROUP BY和ORDER BY的字段项进行分组和排序,但如果原始SQL的选择项中若并未包含分组项或排序项,则需要对原始SQL进行改写。比如有这样一个逻辑SQL:
SELECT name FROM t_user ORDER BY create_time;
由于原始SQL中并不包含需要在结果归并中需要获取的,因此需要对SQL进行补列改写。补列之后的SQL是:
SELECT name, create_time FROM t_user ORDER BY create_time;
4、SQL执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行,也不是直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率,他能在以下两种模式自适应切换:
内存限制模式:
使用此模式的前提是, Sharding-JDBC对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。
连接限制模式:
使用此模式的前提是,Sharding-JDBC严格控制对一次操作所耗费的数据库连接数量。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,那么只会创建唯一的数据库连接,并对其200张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。
内存限制模式适用于OLAP操作(面向事务,事务不可能弄多线程。),可以通过放宽对数据库连接的限制提升系统吞吐量; 连接限制模式适用于OLTP操作,OLTP通常带有分片键,会路由到单一的分片,因此严格控制数据库连接,以保证在线系统数据库资源能够被更多的应用所使用,是明智的选择。
5、结果归并
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
结果归并从功能划分可分为:遍历、排序、分组、分页和 聚合 5种类型,它们是组合而非互斥的关系。
遍历归并:
它是最为简单的归并方式。 只需将多个数据结果集合并为一个单向链表即可。在遍历完成链表中当前数据结果集之后,将链表元素后移一位,继续遍历下一个数据结果集即可。
排序归并:
由于在SQL中存在ORDER BY语句,因此每个数据结果集自身是有序的,因此只需要将数据结果集当前游标指向的数据值进行排序即可。 这相当于对多个有序的数组进行排序,归并排序是最适合此场景的排序算法。
ShardingSphere在对排序的查询进行归并时,将每个结果集的当前数据值进行比较(通过实现Java的Comparable接口完成),并将其放入优先级队列。 每次获取下一条数据时,只需将队列顶端结果集的游标下移,并根据新游标重新进入优先级排序队列找到自己的位置即可。
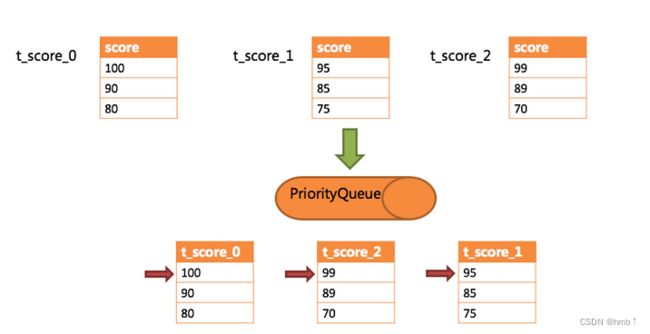
通过一个例子来说明ShardingSphere的排序归并,下图是一个通过分数进行排序的示例图。 图中展示了3张表返回的数据结果集,每个数据结果集已经根据分数排序完毕,但是3个数据结果集之间是无序的。 将3个数据结果集的当前游标指向的数据值进行排序,并放入优先级队列,t_score_0的第一个数据值最大,t_score_2的第一个数据值次之,t_score_1的第一个数据值最小,因此优先级队列根据t_score_0,t_score_2和t_score_1的方式排序队列。
下图则展现了进行next调用的时候,排序归并是如何进行的。 通过图中我们可以看到,当进行第一次next调用时,排在队列首位的t_score_0将会被弹出队列,并且将当前游标指向的数据值(也就是100)返回至查询客户端,并且将游标下移一位之后,重新放入优先级队列。 而优先级队列也会根据t_score_0的当前数据结果集指向游标的数据值(这里是90)进行排序,根据当前数值,t_score_0排列在队列的最后一位。 之前队列中排名第二的t_score_2的数据结果集则自动排在了队列首位。
在进行第二次next时,只需要将目前排列在队列首位的t_score_2弹出队列,并且将其数据结果集游标指向的值返回至客户端,并下移游标,继续加入队列排队,以此类推。 当一个结果集中已经没有数据了,则无需再次加入队列。
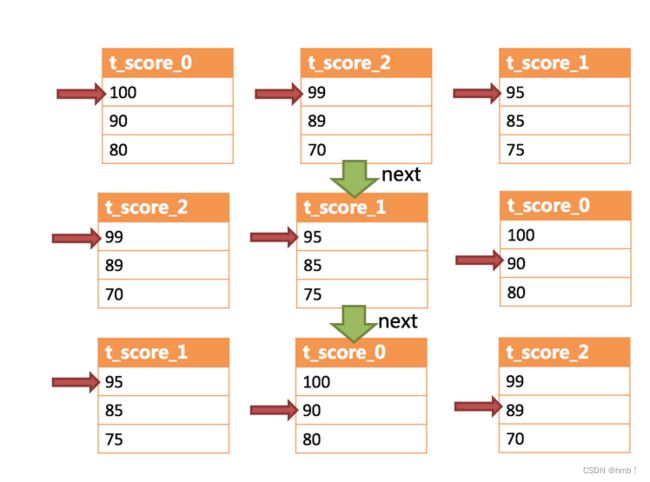 可以看到,对于每个数据结果集中的数据有序,而多数据结果集整体无序的情况下,ShardingSphere无需将所有的数据都加载至内存即可排序。 它使用的是流式归并的方式,每次next仅获取唯一正确的一条数据,极大的节省了内存的消耗。
可以看到,对于每个数据结果集中的数据有序,而多数据结果集整体无序的情况下,ShardingSphere无需将所有的数据都加载至内存即可排序。 它使用的是流式归并的方式,每次next仅获取唯一正确的一条数据,极大的节省了内存的消耗。
聚合归并:
无论是流式分组归并还是内存分组归并,对聚合函数的处理都是一致的。 除了分组的SQL之外,不进行分组的SQL也可以使用聚合函数。 因此,聚合归并是在之前介绍的归并类的之上追加的归并能力,即装饰者模式。聚合函数可以归类为比较、累加和求平均值这3种类型。
比较类型的聚合函数是指MAX和MIN。它们需要对每一个同组的结果集数据进行比较,并且直接返回其最大或最小值即可。
累加类型的聚合函数是指SUM和COUNT。它们需要将每一个同组的结果集数据进行累加。
求平均值的聚合函数只有AVG。它必须通过SQL改写的SUM和COUNT进行计算。
结果归并从结构划分可分为:流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
内存归并 很容易理解,他是将所有分片结果集的数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回
流式归并 是指每一次从数据库结果集中获取到的数据,都能够通过游标逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。