使用预训练resnet18实现CIFAR-10分类
基于ResNet18网络完成图像分类任务
图像分类(Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
这里,我们使用的计算机视觉领域的经典数据集:CIFAR-10数据集,网络为ResNet18模型,损失函数为交叉熵损失,优化器为Adam优化器,评价指标为准确率。
5.5.1 数据处理
5.5.1.1 数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×3232×32像素。CIFAR-10数据集的示例如 图5.15 所示。

图5.15:CIFAR-10数据集示例
5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。 最终的数据集构成为:
- 训练集:40 000条样本。
- 验证集:10 000条样本。
- 测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import numpy as np import torch from matplotlib import pyplot as plt from torchvision.transforms import transforms import torchvision from torch.utils.data import DataLoader transformer = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])]) trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True, transform=transformer) devset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True, transform=transformer) testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True, transform=transformer) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
![]()
可视化其中一张图片
image, label = trainset[0] print(image.size()) image, label = np.array(image), int(label) plt.imshow(image.transpose(1, 2, 0)) plt.show() print(classes[label])

5.5.2 模型构建
使用torchvision API中的Resnet18进行图像分类实验。
from torchvision.models import resnet18 resnet18_model = resnet18(pretrained=True)
5.5.3 模型训练
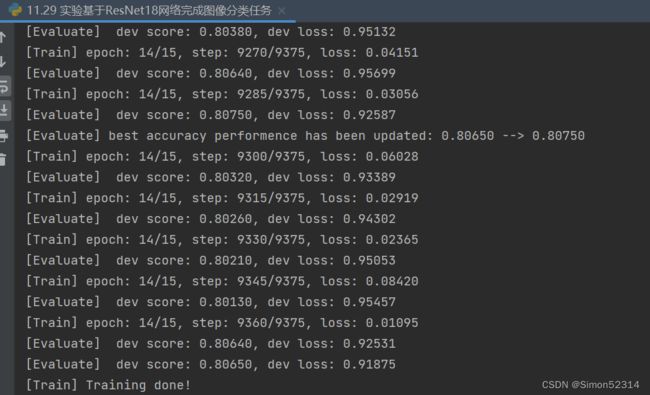
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。 使用训练集和验证集进行模型训练,共训练30个epoch。 在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 学习率大小 lr = 0.001 # 批次大小 batch_size = 64 # 加载数据 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) dev_loader = DataLoader(dev_dataset, batch_size=batch_size) test_loader = DataLoader(test_dataset, batch_size=batch_size) # 定义网络 model = resnet18_model.to(device) # 定义优化器,这里使用Adam优化器以及l2正则化策略,相关内容在7.3.3.2和7.6.2中会进行详细介绍 optimizer = opt.Adam(lr=lr, params=model.parameters(), weight_decay=0.005) # 定义损失函数 loss_fn = F.cross_entropy loss_fn = loss_fn # 定义评价指标 metric = Accuracy(is_logist=True) # 实例化RunnerV3 runner = RunnerV3(model, optimizer, loss_fn, metric) # 启动训练 log_steps = 3000 eval_steps = 3000 runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps, eval_steps=eval_steps, save_path="best_model.pdparams")没有预训练
加预训练的训练结果:

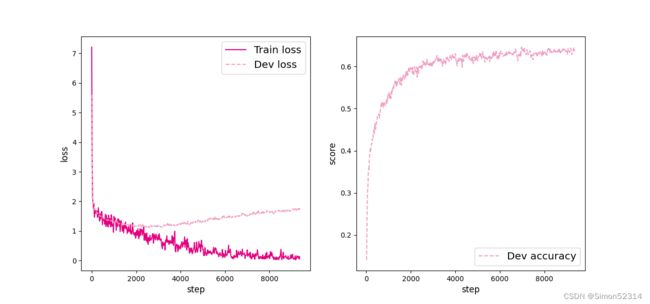

根据训练结果来看,明显加了预训练的模型要收敛的更好,更快,准确率高,损失小。
5.5.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
# 加载最优模型 runner.load_model('best_model.pdparams') # 模型评价 score, loss = runner.evaluate(test_loader) print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))没加预训练:
加预训练:
从测试集上看也明显加了预训练效果要更好。
5.5.5 模型预测
#获取测试集中的一个batch的数据 X, label = next(iter(test_loader)) logits = runner.predict(X,dim=1) #多分类,使用softmax计算预测概率 pred = F.softmax(logits) # print(pred) #获取概率最大的类别 pred_class = torch.argmax(pred[2][0]).cpu().numpy() label = label[2].item() #输出真实类别与预测类别 print("The true category is {} and the predicted category is {}".format(label, pred_class)) #可视化图片 plt.figure(figsize=(2, 2)) imgs, labels = load_cifar10_batch(folder_path=r'C:\Users\29134\PycharmProjects\pythonProject\DL\实验13\cifar-10-batches-py',mode='test') plt.imshow(imgs[2].transpose(1,2,0)) plt.savefig('cnn-test-vis.pdf')没加预训练:
加预训练:




-
实验结论:
根据上面的实验数据可以看出,基于CIFAR-10数据集,ResNet18网络完成图像分类任务中,加上预训练与不加预训练相比,收敛的更快,结果也相对损失小,准确率高。
-
总结及心得体会:
- 这次实验第一感觉就是累,首先第一个就是跑的很慢,第一次模型训练30轮从下午2:30直接干到晚上10:30
- CPU训练时间太长了,直接装CUDA吧,好家伙装完再看竟然入坑了,是CPU版本的torch,
直接把环境删了,重新建立,锻炼了我的耐心。
- 做了这么多的实验,画了那么多的流程图,我感觉这次试验和上面的很多实验的步骤雷同,让我对卷积神经网络有了更深的体验。
- CIFAR10数据集在处理前要先进行归一化处理,这样可以简化模型,提高速度
- torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True, transform=transformer)
上面那串代码给我的一个感觉就是transformer是用来归一化的,结果还是有点出入。
6、什么是“预训练模型”?什么是“迁移学习”?
预训练模型:
预训练模型是指在大规模数据集上事先进行训练的深度学习模型。通常,这种预训练是在某个任务上进行的,例如大规模的语言模型预训练可以是在大量文本数据上进行的。预训练的模型在学习了丰富的特征和模式之后,可以在后续任务上进行微调或迁移学习,以适应特定的领域或任务。预训练模型的目标是通过学习通用的表示和特征,提高模型对各种任务的性能。
通俗理解:就是预训练就是平时做的练习题,预训练可以让我们掌握解题的技巧,增强适应能力,这样在训练就会速度增快。
迁移学习:
迁移学习是一种机器学习方法,它通过将从一个任务学到的知识应用于另一个相关的任务,从而提高学习效果。在深度学习领域,预训练模型为迁移学习提供了有力的工具。具体来说,通过在大规模数据上进行预训练,模型学到了通用的特征和表示,然后可以在相对较小的目标任务数据集上进行微调,以适应目标任务的特定要求。
通俗理解:我们教机器学习了一个猫脸识别模型,这个模型是通过大量的猫脸图片训练得出的。现在我们想让这个模型去识别狗脸,这时就可以使用迁移学习。我们将已经训练好的猫脸识别模型作为基础,然后使用大量的狗脸图片来微调这个模型,使其能够识别狗脸。

参考链接:
基于ResNet18网络完成图像分类任务-CSDN博客