Kafka的高性能原理
本文来说下Kafka的高性能设计
文章目录
- 什么是高性能设计
- Kafka高性能设计的全景图
- 生产消息的性能优化手段
-
- 批量发送消息
- 消息压缩
- 高效序列化
- 内存池复用
- 存储消息的性能优化手段
-
- IO 多路复用.
- 磁盘顺序写
- Page Cache
- 分区分段结构
- 消费消息的性能优化手段
-
- 稀疏索引.
- mmap
- 零拷贝
- 批量拉取
- 本文小结
什么是高性能设计
我们暂且把 Kafka 抛在一边,先尝试理解下高性能设计的本质。
有过高并发开发经验的同学,对于线程池、多级缓存、IO 多路复用、零拷贝等技术概念早就了然于胸,但是返璞归真,这些技术手段的本质到底是什么?
这其实是一个系统性的问题,至少需要深入到操作系统层面,从 CPU 和存储入手,去了解底层的实现机制,然后再自底往上,一层一层去解密和贯穿起来。
但是站在更高的视角来看,我认为:高性能设计其实万变不离其宗,一定是从「计算和 IO」这两个维度出发,去考虑可能的优化点。
那「计算」维度的性能优化手段有哪些呢?无外乎这两种方式:
- 让更多的核来参与计算:比如用多线程代替单线程、用集群代替单机等。
- 减少计算量:比如用索引来取代全局扫描、用同步代替异步、通过限流来减少请求处理量、采用更高效的数据结构和算法等。
再看下「IO」维度的性能优化手段又有哪些? 可以通过 Linux 系统的 IO 栈图来辅助思考。

可以看到,整个 IO 体系结构是分层的,我们能够从应用程序、操作系统、磁盘等各个层次来考虑性能优化,而所有这些手段又几乎围绕以下两个方面展开:
- 加快 IO 速度:比如用磁盘顺序写代替随机写、用 NIO 代替 BIO、用性能更好的 SSD 代替机械硬盘等。
- 减少 IO 次数或者 IO 数据量:比如借助系统缓存或者外部缓存、通过零拷贝技术减少 IO 复制次数、批量读写、数据压缩等。
上面这些内容可以理解成高性能设计的「道」,当然绝不是几百字就可以说清楚的,我更多的是抛砖引玉,用另外一个视角来看高并发,给大家一个方向上的指引。
当大家抓住了「计算和 IO」这两个最本质的东西,然后以这两点作为根,再去探究这两个维度分别有哪些性能优化手段?它们的原理又是什么样的?便能一层一层剥开高性能设计的神秘面纱,形成可靠的知识体系。
这种分析方法可用来研究 Kafka,同样可以用来研究我们熟知的 Redis、ES 以及其他高性能的应用系统。
Kafka高性能设计的全景图
有了高性能设计的思维模式后,我们再回到 Kafka 本身进行分析。
前文提到过 Kafka 的性能优化手段非常丰富,至少有 10 条以上的精妙设计,虽然我们可以从计算和 IO 两个维度去联想这些手段,但是要完整地记住它们,似乎也不是件容易的事。
这样就引出了另外一个话题:我们应该选用一条什么样的脉络,去串联这些优化手段呢?
之前的文章做过分析:不管 Kafka 、RocketMQ 还是其他消息队列,其本质都是「一发一存一消费」。
我们完全可以顺着这条主线去做结构化梳理。基于这个思路,便形成了下面这张 Kafka 高性能设计的全景图,我按照生产消息、存储消息、消费消息 3 个模块,将 Kafka 最具代表性的 12 条性能优化手段做了归类。

有了这张全景图,下面我再挨个分析下每个手段背后的大致原理,并尝试解读下 Kafka 的设计哲学。
生产消息的性能优化手段
我们先从生产消息开始看,下面是 Producer 端所采用的 4 条优化手段。
批量发送消息
Kafka 作为一个消息队列,很显然是一个 IO 密集型应用,它所面临的挑战除了磁盘 IO(Broker 端需要对消息持久化),还有网络 IO(Producer 到 Broker,Broker 到 Consumer,都需要通过网络进行消息传输)。
在上一篇文章已经指出过:磁盘顺序 IO 的速度其实非常快,不亚于内存随机读写。这样网络 IO 便成为了 Kafka 的性能瓶颈所在。
基于这个背景, Kafka 采用了批量发送消息的方式,通过将多条消息按照分区进行分组,然后每次发送一个消息集合,从而大大减少了网络传输的 overhead。
看似很平常的一个手段,其实它大大提升了 Kafka 的吞吐量,而且它的精妙之处远非如此,下面几条优化手段都和它息息相关。
消息压缩
消息压缩的目的是为了进一步减少网络传输带宽。而对于压缩算法来说,通常是:数据量越大,压缩效果才会越好。
因为有了批量发送这个前期,从而使得 Kafka 的消息压缩机制能真正发挥出它的威力(压缩的本质取决于多消息的重复性)。对比压缩单条消息,同时对多条消息进行压缩,能大幅减少数据量,从而更大程度提高网络传输率。
有文章对 Kafka 支持的三种压缩算法:gzip、snappy、lz4 进行了性能对比,测试 2 万条消息,效果如下:
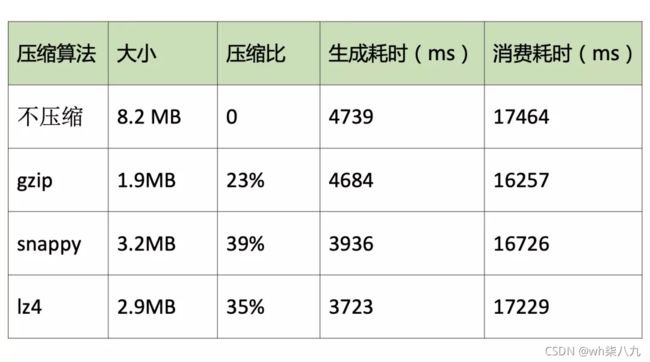
整体来看,gzip 压缩效果最好,但是生成耗时更长,综合对比 lz4 性能最佳。
其实压缩消息不仅仅减少了网络 IO,它还大大降低了磁盘 IO。因为批量消息在持久化到 Broker 中的磁盘时,仍然保持的是压缩状态,最终是在 Consumer 端做了解压缩操作。
这种端到端的压缩设计,其实非常巧妙,它又大大提高了写磁盘的效率。
高效序列化
Kafka 消息中的 Key 和 Value,都支持自定义类型,只需要提供相应的序列化和反序列化器即可。因此,用户可以根据实际情况选用快速且紧凑的序列化方式(比如 ProtoBuf、Avro)来减少实际的网络传输量以及磁盘存储量,进一步提高吞吐量。
内存池复用
前面说过 Producer 发送消息是批量的,因此消息都会先写入 Producer 的内存中进行缓冲,直到多条消息组成了一个 Batch,才会通过网络把 Batch 发给 Broker。
当这个 Batch 发送完毕后,显然这部分数据还会在 Producer 端的 JVM 内存中,由于不存在引用了,它是可以被 JVM 回收掉的。
但是大家都知道,JVM GC 时一定会存在 Stop The World 的过程,即使采用最先进的垃圾回收器,也势必会导致工作线程的短暂停顿,这对于 Kafka 这种高并发场景肯定会带来性能上的影响。
有了这个背景,便引出了 Kafka 非常优秀的内存池机制,它和连接池、线程池的本质一样,都是为了提高复用,减少频繁的创建和释放。
具体是如何实现的呢?其实很简单:Producer 一上来就会占用一个固定大小的内存块,比如 64MB,然后将 64 MB 划分成 M 个小内存块(比如一个小内存块大小是 16KB)。
当需要创建一个新的 Batch 时,直接从内存池中取出一个 16 KB 的内存块即可,然后往里面不断写入消息,但最大写入量就是 16 KB,接着将 Batch 发送给 Broker ,此时该内存块就可以还回到缓冲池中继续复用了,根本不涉及垃圾回收。最终整个流程如下图所示:

了解了 Producer 端上面 4 条高性能设计后,大家一定会有一个疑问:传统的数据库或者消息中间件都是想办法让 Client 端更轻量,将 Server 设计成重量级,仅让 Client 充当应用程序和 Server 之间的接口。
但是 Kafka 却反其道而行之,采取了独具一格的设计思路,在将消息发送给 Broker 之前,需要先在 Client 端完成大量的工作,例如:消息的分区路由、校验和的计算、压缩消息等。这样便很好地分摊 Broker 的计算压力。
可见,没有最好的设计,只有最合适的设计,这就是架构的本源。
存储消息的性能优化手段
存储消息属于 Broker 端的核心功能,下面是它所采用的 4 条优化手段。
IO 多路复用.
对于 Kafka Broker 来说,要做到高性能,首先要考虑的是:设计出一个高效的网络通信模型,用来处理它和 Producer 以及 Consumer 之间的消息传递问题。
先引用 Kafka 2.8.0 源码里 SocketServer 类中一段很关键的注释:

通过这段注释,其实可以了解到 Kafka 采用的是:很典型的 Reactor 网络通信模型,完整的网络通信层框架图如下所示:
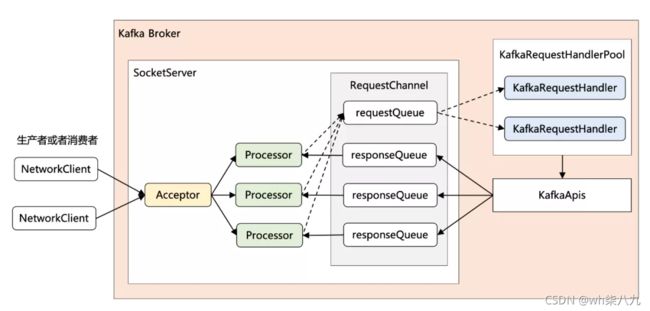
通俗点记忆就是 1 + N + M:
- 1:表示 1 个 Acceptor 线程,负责监听新的连接,然后将新连接交给 Processor 线程处理。
- N:表示 N 个 Processor 线程,每个 Processor 都有自己的 selector,负责从 socket 中读写数据。
- M:表示 M 个 KafkaRequestHandler 业务处理线程,它通过调用 KafkaApis 进行业务处理,然后生成 response,再交由给 Processor 线程。
对于 IO 有所研究的同学,应该清楚:Reactor 模式正是采用了很经典的 IO 多路复用技术,它可以复用一个线程去处理大量的 Socket 连接,从而保证高性能。Netty 和 Redis 为什么能做到十万甚至百万并发?它们其实都采用了 Reactor 网络通信模型。
磁盘顺序写
通过 IO 多路复用搞定网络通信后,Broker 下一步要考虑的是:如何将消息快速地存储起来?
在 Kafka 存储选型的奥秘 一文中提到了:Kafka 选用的是「日志文件」来存储消息,那这种写磁盘文件的方式,又究竟是如何做到高性能的呢?
这一切得益于磁盘顺序写,怎么理解呢?
Kafka 作为消息队列,本质上就是一个队列,是先进先出的,而且消息一旦生产了就不可变。这种有序性和不可变性使得 Kafka 完全可以「顺序写」日志文件,也就是说,仅仅将消息追加到文件末尾即可。
有了顺序写的前提,我们再来看一个对比实验,从下图中可以看到:磁盘顺序写的性能远远高于磁盘随机写,甚至高于内存随机写。

原因很简单:对于普通的机械磁盘,如果是随机写入,性能确实极差,也就是随便找到文件的某个位置来写数据。但如果是顺序写入,因为可大大节省磁盘寻道和盘片旋转的时间,因此性能提升了 3 个数量级。
Page Cache
磁盘顺序写已经很快了,但是对比内存顺序写仍然慢了几个数量级,那有没有可能继续优化呢?答案是肯定的。
这里 Kafka 用到了 Page Cache 技术,简单理解就是:利用了操作系统本身的缓存技术,在读写磁盘日志文件时,其实操作的都是内存,然后由操作系统决定什么时候将 Page Cache 里的数据真正刷入磁盘。
通过下面这个示例图便一目了然。

那 Page Cache 究竟什么时候会发挥最大的威力呢?这又不得不提 Page Cache 所用到的两个经典原理。
Page Cache 缓存的是最近会被使用的磁盘数据,利用的是「时间局部性」原理,依据是:最近访问的数据很可能接下来再访问到。而预读到 Page Cache 中的磁盘数据,又利用了「空间局部性」原理,依据是:数据往往是连续访问的。
而 Kafka 作为消息队列,消息先是顺序写入,而且立马又会被消费者读取到,无疑非常契合上述两条局部性原理。因此,页缓存可以说是 Kafka 做到高吞吐的重要因素之一。
除此之外,页缓存还有一个巨大的优势。用过 Java 的人都知道:如果不用页缓存,而是用 JVM 进程中的缓存,对象的内存开销非常大(通常是真实数据大小的几倍甚至更多),此外还需要进行垃圾回收,GC 所带来的 Stop The World 问题也会带来性能问题。可见,页缓存确实优势明显,而且极大地简化了 Kafka 的代码实现。
分区分段结构
磁盘顺序写加上页缓存很好地解决了日志文件的高性能读写问题。但是如果一个 Topic 只对应一个日志文件,显然只能存放在一台 Broker 机器上。
当面对海量消息时,单机的存储容量和读写性能肯定有限,这样又引出了又一个精妙的存储设计:对数据进行分区存储。
我在 Kafka 架构设计的任督二脉 一文中详细解释了分区(Partition)的概念和作用,它是 Kafka 并发处理的最小粒度,很好地解决了存储的扩展性问题。随着分区数的增加,Kafka 的吞吐量得以进一步提升。
其实在 Kafka 的存储底层,在分区之下还有一层:那便是「分段」。简单理解:分区对应的其实是文件夹,分段对应的才是真正的日志文件。
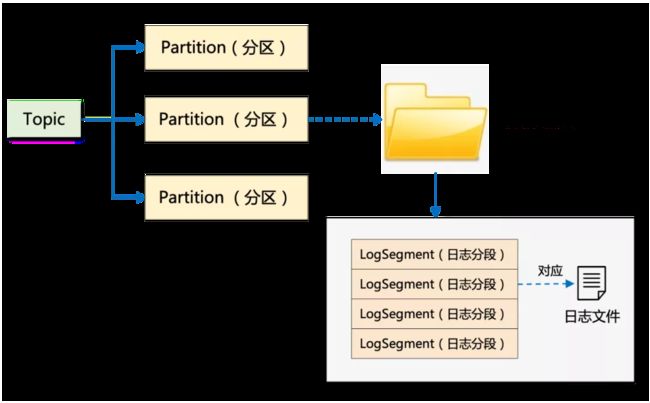
每个 Partition 又被分成了多个 Segment,那为什么有了 Partition 之后,还需要 Segment 呢?
如果不引入 Segment,一个 Partition 只对应一个文件,那这个文件会一直增大,势必造成单个 Partition 文件过大,查找和维护不方便。
此外,在做历史消息删除时,必然需要将文件前面的内容删除,只有一个文件显然不符合 Kafka 顺序写的思路。而在引入 Segment 后,则只需将旧的 Segment 文件删除即可,保证了每个 Segment 的顺序写。
消费消息的性能优化手段
Kafka 除了要做到百万 TPS 的写入性能,还要解决高性能的消息读取问题,否则称不上高吞吐。下面再来看看 Kafka 消费消息时所采用的 4 条优化手段。

稀疏索引.
如何提高读性能,大家很容易想到的是:索引。Kafka 所面临的查询场景其实很简单:能按照 offset 或者 timestamp 查到消息即可。
如果采用 B Tree 类的索引结构来实现,每次数据写入时都需要维护索引(属于随机 IO 操作),而且还会引来「页分裂」这种比较耗时的操作。而这些代价对于仅需要实现简单查询要求的 Kafka 来说,显得非常重。所以,B Tree 类的索引并不适用于 Kafka。
相反,哈希索引看起来却非常合适。为了加快读操作,如果只需要在内存中维护一个「从 offset 到日志文件偏移量」的映射关系即可,每次根据 offset 查找消息时,从哈希表中得到偏移量,再去读文件即可。(根据 timestamp 查消息也可以采用同样的思路)
但是哈希索引常驻内存,显然没法处理数据量很大的情况,Kafka 每秒可能会有高达几百万的消息写入,一定会将内存撑爆。
可我们发现消息的 offset 完全可以设计成有序的(实际上是一个单调递增 long 类型的字段),这样消息在日志文件中本身就是有序存放的了,我们便没必要为每个消息建 hash 索引了,完全可以将消息划分成若干个 block,只索引每个 block 第一条消息的 offset 即可,先根据大小关系找到 block,然后在 block 中顺序搜索,这便是 Kafka “稀疏索引” 的设计思想。

采用 “稀疏索引”,可以认为是在磁盘空间、内存空间、查找性能等多方面的一个折中。有了稀疏索引,当给定一个 offset 时,Kafka 采用的是二分查找来高效定位不大于 offset 的物理位移,然后找到目标消息。
mmap
利用稀疏索引,已经基本解决了高效查询的问题,但是这个过程中仍然有进一步的优化空间,那便是通过 mmap(memory mapped files) 读写上面提到的稀疏索引文件,进一步提高查询消息的速度。
注意:mmap 和 page cache 是两个概念,网上很多资料把它们混淆在一起。此外,还有资料谈到 Kafka 在读 log 文件时也用到了 mmap,通过对 2.8.0 版本的源码分析,这个信息也是错误的,其实只有索引文件的读写才用到了 mmap.
究竟如何理解 mmap?前面提到,常规的文件操作为了提高读写性能,使用了 Page Cache 机制,但是由于页缓存处在内核空间中,不能被用户进程直接寻址,所以读文件时还需要通过系统调用,将页缓存中的数据再次拷贝到用户空间中。
而采用 mmap 后,它将磁盘文件与进程虚拟地址做了映射,并不会招致系统调用,以及额外的内存 copy 开销,从而提高了文件读取效率。
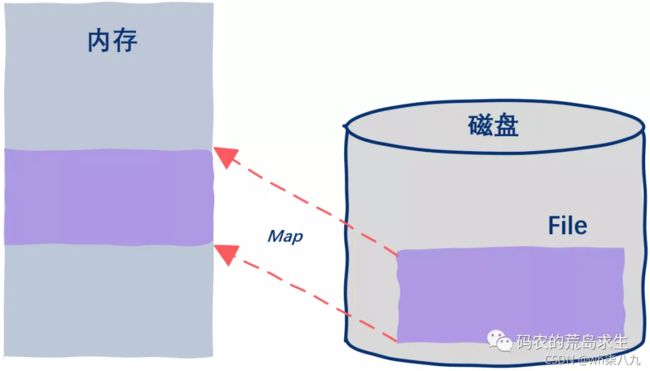
具体到 Kafka 的源码层面,就是基于 JDK nio 包下的 MappedByteBuffer 的 map 函数,将磁盘文件映射到内存中。
至于为什么 log 文件不采用 mmap?其实是一个特别好的问题,这个问题社区并没有给出官方答案,网上的答案只能揣测作者的意图。个人比较认同 stackoverflow 上的这个答案:
mmap 有多少字节可以映射到内存中与地址空间有关,32 位的体系结构只能处理 4GB 甚至更小的文件。Kafka 日志通常足够大,可能一次只能映射部分,因此读取它们将变得非常复杂。然而,索引文件是稀疏的,它们相对较小。将它们映射到内存中可以加快查找过程,这是内存映射文件提供的主要好处。
零拷贝
消息借助稀疏索引被查询到后,下一步便是:将消息从磁盘文件中读出来,然后通过网卡发给消费者,那这一步又可以怎么优化呢?
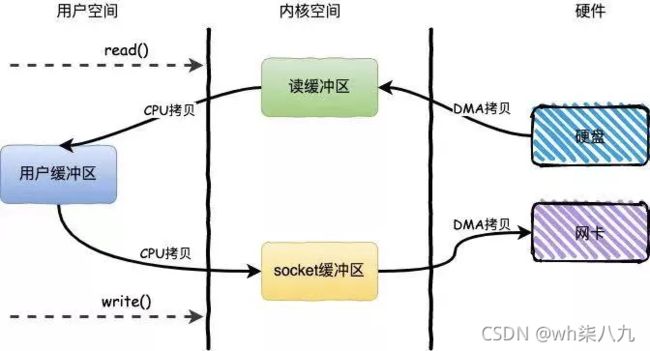
Kafka 用到了零拷贝(Zero-Copy)技术来提升性能。所谓的零拷贝是指数据直接从磁盘文件复制到网卡设备,而无需经过应用程序,减少了内核和用户模式之间的上下文切换。
下面这个过程是不采用零拷贝技术时,从磁盘中读取文件然后通过网卡发送出去的流程,可以看到:经历了 4 次拷贝,4 次上下文切换。
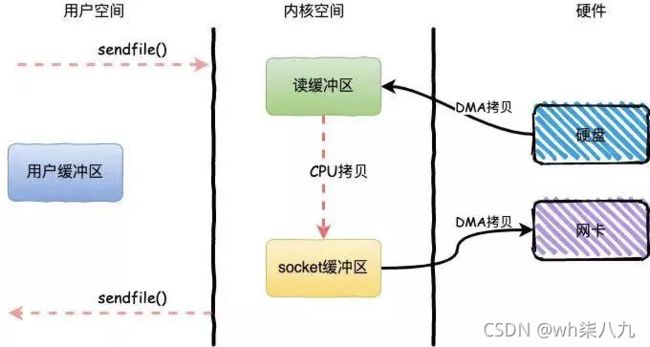
如果采用零拷贝技术(底层通过 sendfile 方法实现),流程将变成下面这样。可以看到:只需 3 次拷贝以及 2 次上下文切换,显然性能更高。
批量拉取
和生产者批量发送消息类似,消息者也是批量拉取消息的,每次拉取一个消息集合,从而大大减少了网络传输的 overhead。
另外,在前面介绍过,生产者其实在 Client 端对批量消息进行了压缩,这批消息持久化到 Broker 时,仍然保持的是压缩状态,最终在 Consumer 端再做解压缩操作。
本文小结
本文从生产者,kafka服务器和消费者三个层面介绍了kafka这个MQ高性能的原因,对kafka有了进一步的理解与掌握。