python使用pycrawlers批量下载huggingface上的模型与数据文件
文章目录
- 前言
- 一、git下载
- 二、huggingface_hub下载
-
- 安装
- 使用
- 三、pycrawlers的使用
-
- 1. 安装
- 2. 批量下载
- 3. 单个下载
- 4. 示例
- 5. 后台下载
- 6. 断点续传
- 7. 使用token登陆hugging face账号下载
-
- 7.1 查看token
- 7.2 使用token
- 总结
前言
现在从下载huggingface的文件一般有两种方法git或 huggingface_hub,这两种方法适合下载单个小型模型的文件,那么想一次下载多个文件呢?
现介绍pycrawlers这个python包,使用这个包可以轻松实现批量下载,以及进度显示,断点续传。
一、git下载
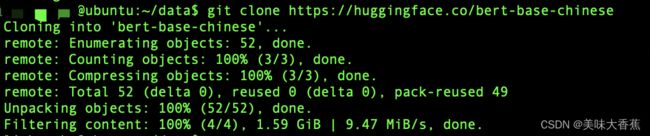
上面的例子使用git下载了bert-base-chinese,可以从图片上看到只有下载的大概情况,并没有每个文件的详细下载情况。
当模型文件较大的时候,会卡在 Unpacking objects: 100% (52/52), done. ,
等模型全部下载完成才会显示 Filtering content: 100% (4/4), 1.59 GiB | 9.47 MiB/s, done.
这会导致我们无法知道下载的进度,进而不知道多久才能下完,是否要选择后台下载。
二、huggingface_hub下载
官方下载方法,下载单个模型推荐使用此方法。官方文档:https://huggingface.co/docs/huggingface_hub/guides/download
安装
pip install huggingface-hub
使用
from huggingface_hub import snapshot_download
snapshot_download("bert-base-chinese", local_dir='./bert-base-chinese', resume_download=True)
三、pycrawlers的使用
1. 安装
pip install pycrawlers
由于huggingface升级会导致旧版本不可用,推荐使用最新版本
2. 批量下载
代码如下(示例):
from pycrawlers import huggingface
# 实例化类
hg = huggingface()
urls = ['https://huggingface.co/albert-base-v2/tree/main',
'https://huggingface.co/dmis-lab/biosyn-sapbert-bc5cdr-disease/tree/main']
# 批量下载
# 默认保存位置在当前脚本所在文件夹 ./
hg.get_batch_data(urls)
# 自定义下载位置
# paths = ['./model_1/albert-base-v2', './model_2/']
# hg.get_batch_data(urls, paths)
3. 单个下载
代码如下(示例):
from pycrawlers import huggingface
# 实例化类
hg = huggingface()
url = 'https://huggingface.co/albert-base-v2/tree/main'
# 单个下载
# 默认保存位置在当前脚本所在文件夹 ./
hg.get_data(url)
# 自定义下载位置
# path = './model_1/albert-base-v2'
# hg.get_data(url, path)
4. 示例
以下载 https://huggingface.co/albert-base-v2/tree/main 为例
5. 后台下载
可以使用nohup 执行python文件实现后台下载,当下载大的文件的时候非常方便。
例:
nohup python3 -u download_models.py > dm.log 2>&1 &
使用下面命令同步查看日志:
tail -f dm.log
6. 断点续传
版本1.0.0以上支持断点续传,无需配置
7. 使用token登陆hugging face账号下载
hugging face上有一些模型和数据集需要我们进行申请经审核同意后才能下载,这时我们就需要使用token登陆hugging face账号进行下载。
7.1 查看token
- 登陆上自己的账号,
- 进入到任意一个模型下载页面
- 打开开发者工具,查看cookie,找到token如下图

7.2 使用token
代码例子如下:
from pycrawlers import huggingface
# 你的token
token = ''
hg = huggingface(token=token)
hg.get_data('https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat/tree/main')
总结
以上就是使用pycrawlers批量下载huggingface上的模型与数据文件的全部内容了,欢迎交流。
pycrawlers以后还会拓展其他下载功能,敬请期待。
本文仅供学习交流,未经同意严禁转载