Java技术栈 —— Redis的雪崩、穿透与击穿
Java技术栈 —— Redis的雪崩、穿透与击穿
- 〇、实验的先导条件(Nginx+Jmeter)
- 一、Redis缓存雪崩、缓存穿透、缓存击穿
-
- 1.1 雪崩
- 1.2 穿透
- 1.3 击穿
- 二、Redis应用场景——高并发
-
- 2.1 单机部署的高并发问题与解决(JVM级别锁)
- 2.2 集群部署的高并发问题与解决(分布式锁)
-
- 2.2.1 代码1(存在非原子操作与释放问题)
- 2.2.2 代码2(finally块中,存在释放其它线程锁的可能性)
- 2.2.3 代码3(redisson)
-
- 2.2.3.1 Java中嵌入Lua脚本
- 2.2.4 对代码3的性能优化、redis主从架构锁失效问题的解决方案
-
- 2.2.4.1 性能优化的解决(分段锁,重要)
- 2.2.4.2 主从架构锁失效问题的解决
-
-
- 2.2.4.2.1 zookeeper
- 2.2.4.2.2 redis的RedLock
-
〇、实验的先导条件(Nginx+Jmeter)
首先你需要掌握Nginx负载均衡与Jmeter压测工具,搭建过程与使用方式,见参考文章。
| 参考文章或视频链接 |
|---|
| [1] 《Java技术栈 —— Nginx的使用》 |
| [2] 2 ways to install Apache JMeter on Ubuntu 22.04 LTS Linux |
一、Redis缓存雪崩、缓存穿透、缓存击穿
关于雪崩、穿透与击穿的原理,可以先看本节的参考文章[1],代码以后再写到文章中。
1.1 雪崩
1.2 穿透
1.3 击穿
| 一、参考文章或视频链接 |
|---|
| [1] 【什么是Redis缓存雪崩、穿透、击穿,十分钟给你讲的明明白白】- bilibili |
二、Redis应用场景——高并发
高并发导致的问题,本质就是资源争抢。 在操作系统中,这类问题的雏形有哲学家用餐问题、进程争夺计算资源,相关解决机制有信号量机制,所以道理都是相通的,高并发在计算机领域并不是什么新鲜事,只是落地到应用场景,会有一些其它考量。就像古代兵符印信,或是倚天屠龙记中说的“武林至尊,宝刀屠龙,号令天下,莫敢不从!倚天不出,谁与争锋?”,听谁的问题的解决方法啊,就是象征物在谁手上就听谁的,包括抢职位争权力,也可以理解为一种并发,谁坐到了那个位置,才有号令的权力,但是权力是致命毒药,要小心哦!
首先导入jedis依赖,从而可以用java程序包操纵redis,以下是完整依赖。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.28version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>3.0.3version>
dependency>
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.6.5version>
dependency>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>5.1.0version>
dependency>
然后,我们开始复现高并发问题。首先是假设你已经搭建了一个简单的SpringBoot项目架构,并且相关的Nginx配置也已配置好,可以看 参考文章[5] 《Java技术栈 —— Nginx的使用》第3.1节,那正是我为本文而写,项目demo搭好了,port号也初步定为9998。
| 二、参考文章或视频链接 |
|---|
| [1] Java guide(Jedis) - Redis Offical Website |
| [2] Intro to Jedis – the Java Redis Client Library |
| [3] Redis可视化工具 RedisInsight | The best Redis GUI |
| [4] 示例代码来源,图灵诸葛老师,讲的确实很好: 【这可能是目前讲的最好的Redis高并发架构教程,堪称Redis架构实战的天花板!】 |
| [5] 《Java技术栈 —— Nginx的使用》 |
2.1 单机部署的高并发问题与解决(JVM级别锁)
(1)先在redis中设置缓存好一个键值对,键的名字为store,这是我们要高并发的对象。
$ redis-cli
127.0.0.1:6379> SETNX store 2000
127.0.0.1:6379> get store
"2000"
(2)写一段操作redis获取store值的代码,完整项目代码最后会附上开源地址。
@RestController
public class demoController {
public static int count = 0;
@RequestMapping("deduct_stock_then_get_stock")
public Integer deductStock(){
Jedis jedis = new Jedis("127.0.0.1", 6379);
int currentStock = Integer.parseInt(jedis.get("stock"));
if (currentStock > 0){
currentStock--;
jedis.set("stock", String.valueOf(currentStock));
System.out.println("扣减成功,剩余库存"+currentStock);
}else{
System.out.println("扣减失败,库存不足");
}
return currentStock;
}
}
启动项目并访问http://127.0.0.1:9998/deduct_stock_then_get_stock,让我们先看看效果,慢慢迭代,好的,现在浏览器上已经返回了当前库存数量,显示是199不要在意,这个数字随时可以在redis中修改。
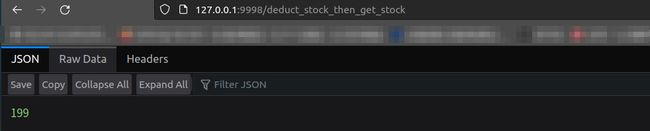
然后我们用Jmeter,模拟多个用户同时访问 http://127.0.0.1:9998/deduct_stock_then_get_stock,上面这段Java代码会出什么问题呢?简单来说,就是会出现超卖问题。按下面的过程配置,并点击绿色的启动箭头![]() ,就开启了压测。
,就开启了压测。



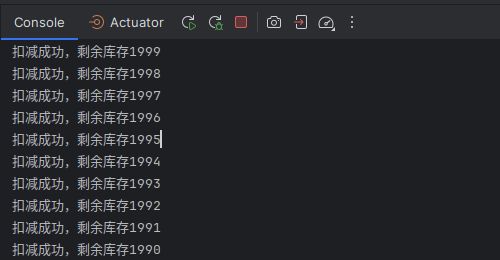
这是控制台输出的结果,果然,出现了超卖问题,这说明会有多个用户都看到了相同的1999库存,很明显是有问题的,这是因为多个用户同时进入了相同段代码的执行过程,并且都拿到了一个currentStock变量作为副本,而这个变量在获取的时候出现了值相同的情况。

@RestController
public class demoController { //方法(2)以函数为单位上锁,写成 public synchronized Integer deductStock(){
@RequestMapping("deduct_stock_then_get_stock")
public Integer deductStock(){
Jedis jedis = new Jedis("127.0.0.1", 6379);
synchronized (this){ //方法(1)以对象为单位上锁
int currentStock = Integer.parseInt(jedis.get("stock")); //上一段未加synchronized的代码,问题出在这里,都获取到了一样的值,那么再进行currentStock--,就是1999了
if (currentStock > 0){
currentStock--;
jedis.set("stock", String.valueOf(currentStock));
System.out.println("扣减成功,剩余库存"+currentStock);
}else{
System.out.println("扣减失败,库存不足");
}
return currentStock;
}
}
}
只加了一个锁,问题解决,那么到目前为止,单机部署的高并发问题,可以算解决了,如果集群部署的话,上面这段代码还有用吗?
2.2 集群部署的高并发问题与解决(分布式锁)
根据参考视频[4]所说,上面的代码也只是解决了单机部署下的高并发问题,如果是集群部署,启动了多个服务分别部署在不同机器上呢?这个时候Nginx会分发请求到不同服务实例上,还会出现上面的超卖现象吗?答案是会的,这相当于线程A在服务A上执行扣库存,线程B在服务B上执行扣库存,这两个线程压根不归同一个JVM虚拟机进程管,是没办法用上面的加synchronized关键字去限制的,具体可以看视频讲解。但是,只要思想不滑坡,办法总比困难多,请看。PS:你能想象,其实12306是全世界最能抗高并发的软件吗?总有些东西在微不足道的角落里熠熠生辉,独自发热。
还是刚刚那段,在单机部署上解决了高并发问题的代码,我们来多启动一个服务,只是端口不同。
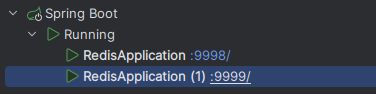
由于在参考文章[5]中,我已经配置了Nginx,所以我们的Jmeter测试地址,应该改为http://127.0.0.1:8011/deduct_stock_then_get_stock,看下面的两张截图,和视频[5]里说的一样,确实在集群部署时会出现超卖问题。


下面是加上分布式锁的解决方法, 但是仍然存在问题。
2.2.1 代码1(存在非原子操作与释放问题)
@RestController
public class demoController {
@RequestMapping("deduct_stock_then_get_stock")
public Integer deductStock(){
String lockKey = "product_100";
Jedis jedis = new Jedis("127.0.0.1", 6379);
long result = jedis.setnx(lockKey,"xxx"); // 获取分布式锁
if(result == 0){
System.out.println("争抢分布式锁失败");
/*
注意,这里实际使用会有问题,不应该return,只是作为示例
争抢分布式锁失败的话也应该程门立雪,三顾茅庐,不可半途而返,
半途而返会导致许多业务请求被扼杀
*/
return 500;
}
//*****重要思维*****
//业务逻辑,可能出异常,导致分布式锁无法释放,永远要考虑系统的业务逻辑被某种不可抗力因素停止,不管是运维还是什么,程序要具备健壮性。
int currentStock = Integer.parseInt(jedis.get("stock"));
if (currentStock > 0) {
currentStock--;
jedis.set("stock", String.valueOf(currentStock));
System.out.println("扣减成功,剩余库存" + currentStock);
} else {
System.out.println("扣减失败,库存不足");
}
jedis.del(lockKey); //释放分布式锁
return currentStock;
}
}
2.2.2 代码2(finally块中,存在释放其它线程锁的可能性)
下面的代码对上面的代码做了两处改进:
(1)将获取与设置超时时间这两步,组合成原子操作,不可分离。
(2)增加clientID,保证释放的是自己加的锁,但在释放仍旧可能存在问题,视频中提到用redisson进行解决,见 redisson - github wiki,redisson与jedis区别在于,jedis只是提供一些原生命令的实现,redisson可以提供分布式锁的实现能力。
@RequestMapping("deduct_stock_then_get_stock")
public Integer deductStock(){ //集群版
//(1)获得分布式锁
String lockKey = "product_100";
Jedis jedis = new Jedis("127.0.0.1", 6379);
String clientID = UUID.randomUUID().toString(); //唯一ID,加锁人的身份
// String result = jedis.setex(lockKey, 10, clientID); //该命令是原子命令,将获取与设置超时时间这两步,组合成原子操作,不可分离,但还是存在问题,如业务逻辑执行较慢,锁已经超时释放了业务逻辑还没执行完,又导致了并发
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientID, 10, TimeUnit.SECONDS); //该命令是原子命令,将获取与设置超时时间这两步,组合成原子操作,不可分离,但还是存在问题,如业务逻辑执行较慢,锁已经超时释放了业务逻辑还没执行完,又导致了并发
stringRedisTemplate.opsForValue().get(lockKey);
if(result == Boolean.FALSE){
System.out.println("争抢分布式锁失败"); // 分布式锁争抢失败应该等待,而不应该直接return
return 500;
}
try{
//*****重要思维*****
//(2)执行业务逻辑,可能出异常,导致分布式锁无法释放,永远要考虑系统的业务逻辑被某种不可抗力因素停止,不管是运维还是什么,要具备健壮性。
//此处可能存在的异常有:
// (2.1)业务逻辑执行失败,但finally可以正常释放分布式锁
// (2.2)应用被重启,连finally都无法执行,那么就需要令分布式锁自动过期
int currentStock = Integer.parseInt(jedis.get("stock"));
if (currentStock > 0) {
currentStock--;
jedis.set("stock", String.valueOf(currentStock));
System.out.println("扣减成功,剩余库存" + currentStock);
} else {
System.out.println("扣减失败,库存不足");
}
return currentStock;
}finally{
//(3)出异常时释放分布式锁,这里释放分布式锁可能存在问题
if (clientID.equals(jedis.get(lockKey))){
//自己加的锁才能释放,中间还可能存在执行时间的间隔,开一个分线程,将分布式锁加时,检测这把分布式锁还是否加载在该主线程中,加时到直到业务逻辑执行完成为止
jedis.del(lockKey);
}
}
}
2.2.3 代码3(redisson)
@RequestMapping("deduct_stock_then_get_stock_cluster_redisson")
public Integer deductStock3(){ //集群+redisson版
//(1)获得分布式锁
String lockKey = "product_100";
Jedis jedis = new Jedis("127.0.0.1", 6379);
RLock redissonLock = redisson.getLock(lockKey); //获取RLock对象
try{
redissonLock.lock(); //(2)上锁,底层调用redis命令时用到了lua脚本
//(3)业务逻辑
int currentStock = Integer.parseInt(jedis.get("stock"));
if (currentStock > 0) {
currentStock--;
jedis.set("stock", String.valueOf(currentStock));
System.out.println("扣减成功,剩余库存" + currentStock);
} else {
System.out.println("扣减失败,库存不足");
}
return currentStock;
}finally{
//(4)释放锁
redissonLock.unlock();
}
}
redisson是一种Redis Java client,上述redisson的使用方法,也是大厂在生产环境会用到的,但上面的代码还有两个问题:
(1)性能问题,虽然没有超卖,但会导致系统性能问题,需要开始性能优化。
(2)redis主从架构下,锁失效问题。比如Master同步给Slave分布式锁时,Master正好挂掉,然后重新选举的Master正好没有同步到这把锁,就失效了。
| 2.2.3 参考文章或视频链接 |
|---|
| [1] 1. Overview of Redisson - GitHub |
2.2.3.1 Java中嵌入Lua脚本
什么是Lua脚本?我第一次听说Lua,是在敖丙解说B站出事那次,最后定位到一段Lua写的gcd()代码,久闻大名却未上手实操过。请看本节参考文章[1]。
| 2.2.3.1 参考文章或视频链接 |
|---|
| [1] Lua:about - Offical Website |
2.2.4 对代码3的性能优化、redis主从架构锁失效问题的解决方案
2.2.4.1 性能优化的解决(分段锁,重要)
先了解下并发编程集合类ConcurrentHashMap,这是一个高并发的Java集合类且线程安全,其保证线程安全的原理是,使用分段锁。受此启发,性能优化也可以用分段加锁,每个线程去不同的段位请求锁即可。
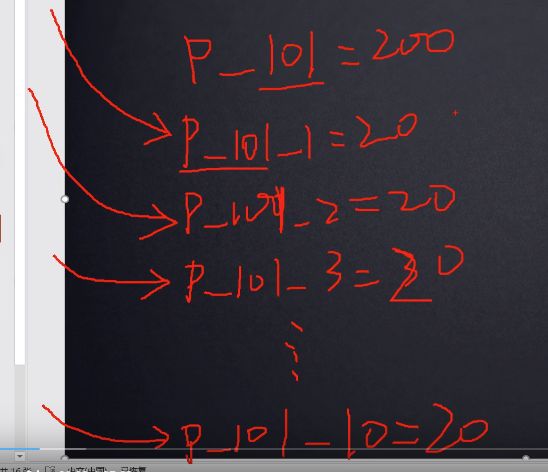
| 2.2.4.1 参考文章或视频链接 |
|---|
| [1] 《详解ConcurrentHashMap》- CSDN |
2.2.4.2 主从架构锁失效问题的解决
CAP原则:zookeeper是CP架构,重在维持数据一致性;redis是AP架构,重在可用性。
2.2.4.2.1 zookeeper
使用zookeeper,zookeeper解决主从架构锁失效问题更合适,但会牺牲一点性能。
| 2.2.4.2.1 参考文章或视频链接 |
|---|
| [1] What is Apache ZooKeeper? |
| [2] Welcome to Apache ZooKeeper |
| [3] 《2.0 Zookeeper 安装配置》- 菜鸟 |
| [4] 《zookeeper快速入门一:zookeeper安装与启动》 |
2.2.4.2.2 redis的RedLock
要超过半数redis节点加锁成功才算成功,这样的原理又回到了zookeeper,还是会损失加锁的性能,所以RedLock实现的是否完善依旧存在争议。
