Autoscaler 中 VPA 的设计与实现
Pod 自动垂直伸缩(Vertical Pod Autoscaler,VPA)是 K8s 中集群资源控制的重要一部分。它的主要目的有:
- 通过自动化更新 Pod 所需资源(CPU、内存等)的方式来降低集群的维护成本
- 提升集群资源的利用率,减少集群中容器发生 OOM 或 CPU 饥饿[1]的风险
本文以 VPA 为切入点,对 Autoscaler[2] 的 VPA 设计与实现原理进行了分析。本文源代码基于 Autoscaler HEAD fbe25e1[3]。
Autoscaler VPA 整体架构
Autoscaler 的 VPA 会根据 Pod 的资源真实用量来自动调整 Pod 的资源需求量。它通过定义 VerticalPodAutoscaler[4] CRD 来实现 VPA,简单来说,该 CRD 定义了哪些 Pod(通过 Label Selector 选取)使用何种更新策略(Update Policy)来更新以某种方式(Resources Policy)计算的资源值。
Autoscaler 的 VPA 由如下几个模块配合实现:
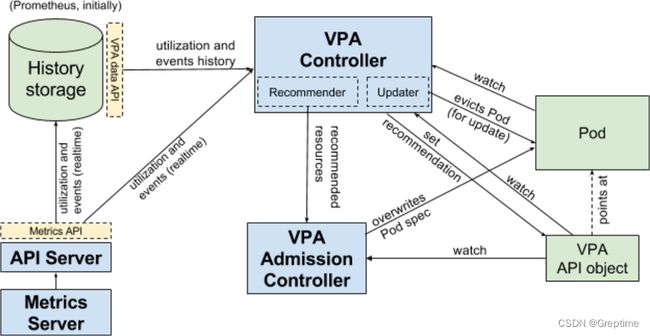
- `Recommender`,负责计算每个 VPA 对象管理下的所有 Pod 的资源推荐值
- Admission Controller,负责拦截所有 Pod 的创建请求,并依据 Pod 所属的 VPA 对象,重填 Pod 的资源值字段
- Updater,负责 Pod 资源的实时更新
Recommender
Autoscaler 的 VPA Recommender 是以 Deployment 形式部署的。在 VerticalPodAutoscaler CRD 的 spec 中,可以通过`Recommenders` 字段指定一个或多个 VPA Recommender(默认使用名为`default`的 VPA Recommender)。
VPA Recommender 的核心组成结构包括:
- `ClusterState`表示整个集群的对象状态,主要包含 Pod 和 VPA 对象的状态,充当了一个本地缓存的作用
- `ClusterStateFeeder`定义了一系列集群对象或资源状态的获取方式,这些获取的状态最终都会存储在`ClusterState`中
VPA Recommender 会定期执行一次推荐资源值的计算,执行周期可由`--recommender-interval`参数指定(默认为 1 min)。执行期间,VPA Recommender 首先通过`ClusterStateFeeder`全量加载 VPA、Pod 资源和实时 Metrics 数据到`ClusterState`。最后 VPA Recommender 将计算的 Pod 资源推荐值写入至 VPA 对象。
Pod 资源的推荐值是通过 Autoscaler VPA 定义的推荐值算子(Estimator)计算。主要的计算方式围绕`PercentileEstimator`算子展开,该算子会根据 Pod 内每个容器的一组历史资源状态计算出一个分布,并取该分布的某个分位点(例如,95分位点)对应的资源值作为最终的资源推荐值。
Admission Controller
Autoscaler 的 VPA Admission Controller 以 Deployments 形式部署,并默认在`kube-system`命名空间下以名为`vpa-webhook`的 Service 提供 HTTPS 服务。
VPA Admission Controller 主要负责创建并启动 Admission Server,其整体执行过程如下:
- 注册 Pod 和 VPA 对象的 Handler,负责处理各自对象的请求
- 注册 Calculator,以获取 Recommender 中计算的资源推荐值
- 注册 Mutating Admission Webhook,以拦截 Pod 对象的创建请求和 VPA 对象的创建、更新请求
针对拦截到的请求,Admission Server 会调用相关 Handler,将 Autoscaler VPA Recommender 计算的资源推荐值以 JSON Patch[5] 的方式回填至原始对象字段。
以 Pod 对象为例,其 Handler 对应的GetPatches方法如下:
// vertical-pod-autoscaler/pkg/admission-controller/resource/pod/handler.go
func (h *resourceHandler) GetPatches(ar *admissionv1.AdmissionRequest) ([]resource_admission.PatchRecord, error) {
raw, namespace := ar.Object.Raw, ar.Namespace
pod := v1.Pod{}
err := json.Unmarshal(raw, &pod)
// ...
controllingVpa := h.vpaMatcher.GetMatchingVPA(&pod) // 获取控制该 Pod 的 VPA 资源
patches := []resource_admission.PatchRecord{}
for _, c := range h.patchCalculators {
partialPatches, err := c.CalculatePatches(&pod, controllingVpa) // 根据每种 calculator 的计算方式返回 patch
patches = append(patches, partialPatches...)
}
return patches, nil
}Updater
Autoscaler 的 VPA Updater 以 Deployment 形式部署。VPA Updater 用于决定哪些 Pods 需要根据 VPA Recommender 计算的资源推荐值进行调整,VPA Updater 对 Pod 的资源调整采用驱逐再重建的方式(同时也考虑了 Pod Disruption Budget[6])。VPA Updater 自身并没有资源更新的能力,而是只负责驱逐 Pod,再次创建 Pod 时则依赖 VPA Admission Controller 来更新资源值。
每次资源更新调用的都是 VPA Updater 的`RunOnce`方法,该方法会枚举每个 VPA 资源及其对应的 Pods,筛选出在当前 VPA 中需要进行资源更新的 Pods 并对它们逐一进行驱逐。
// vertical-pod-autoscaler/pkg/updater/logic/updater.go
func (u *updater) RunOnce(ctx context.Context) {
// ...
vpaList, err := u.vpaLister.List(labels.Everything()) // 列出所有 VPA 资源
vpas := make([]*vpa_api_util.VpaWithSelector, 0)
for _, vpa := range vpaList {
selector, err := u.selectorFetcher.Fetch(vpa)
vpas = append(vpas, &vpa_api_util.VpaWithSelector{
Vpa: vpa,
Selector: selector,
})
}
podsList, err := u.podLister.List(labels.Everything()) // 列出所有 Pod 资源
allLivePods := filterDeletedPods(podsList) // 过滤掉所有被删除的 Pod(即 DeletionTimestamp 不为空的)
controlledPods := make(map[*vpa_types.VerticalPodAutoscaler][]*apiv1.Pod)
for _, pod := range allLivePods {
controllingVPA := vpa_api_util.GetControllingVPAForPod(pod, vpas) // 获取当前 Pod 对应的 VPA 资源
if controllingVPA != nil {
controlledPods[controllingVPA.Vpa] = append(controlledPods[controllingVPA.Vpa], pod)
}
}
for vpa, livePods := range controlledPods {
evictionLimiter := u.evictionFactory.NewPodsEvictionRestriction(livePods, vpa)
podsForUpdate := u.getPodsUpdateOrder(filterNonEvictablePods(livePods, evictionLimiter), vpa) // 获取需要进行资源更新的 Pod 以进行驱逐
for _, pod := range podsForUpdate {
if !evictionLimiter.CanEvict(pod) { // 判断是否能驱逐
continue
}
evictErr := evictionLimiter.Evict(pod, u.eventRecorder) // 执行驱逐
}
}
}更新优先级
在上述方法的最后,VPA Updater 通过`getPodsUpdateOrder`方法返回一个需要资源更新的 Pods 列表,列表中的 Pod 是按照更新优先级从高到低排序的。
Pod 的更新优先级是通过GetUpdatePriority方法计算的,其返回值类型`PodPriority`中的`ResourceDiff`字段表示了所有资源类型差值(请求值与推荐值差的绝对值)的归一化总和。最后在使用更新优先级对 Pod 进行排序时,`ResourceDiff`就是排序所使用的标准。
// vertical-pod-autoscaler/pkg/updater/priority/priority_processor.go
func (*defaultPriorityProcessor) GetUpdatePriority(pod *apiv1.Pod, _ *vpa_types.VerticalPodAutoscaler, recommendation *vpa_types.RecommendedPodResources) PodPriority {
// ...
totalRequestPerResource := make(map[apiv1.ResourceName]int64) // 请求资源的总值,按资源类型分类
totalRecommendedPerResource := make(map[apiv1.ResourceName]int64) // 推荐资源的总值,按资源类型分类
for _, podContainer := range pod.Spec.Containers {
recommendedRequest := vpa_api_util.GetRecommendationForContainer(podContainer.Name, recommendation) // 获取该容器对应的推荐值
for resourceName, recommended := range recommendedRequest.Target {
totalRecommendedPerResource[resourceName] += recommended.MilliValue()
lowerBound, hasLowerBound := recommendedRequest.LowerBound[resourceName]
upperBound, hasUpperBound := recommendedRequest.UpperBound[resourceName]
// 几种边界情况的判断...
}
}
resourceDiff := 0.0 // 所有资源类型差值的总和
for resource, totalRecommended := range totalRecommendedPerResource {
totalRequest := math.Max(float64(totalRequestPerResource[resource]), 1.0)
resourceDiff += math.Abs(totalRequest-float64(totalRecommended)) / totalRequest // 对每种资源类型差值都进行了归一化
}
return PodPriority{
ResourceDiff: resourceDiff,
// ...
}
}驱逐事件
对于每一个需要更新资源值的 Pod,VPA Updater 都会先检测该 Pod 是否能被驱逐,若能,则将其驱逐;若不能,则跳过此次驱逐。
VPA Updater 对 Pod 是否能够被驱逐的判断是通过`CanEvict`方法来完成的。它既保证了一个 Pod 对应的 Controller 只能驱逐可容忍范围内的 Pod 副本数,又保证了该副本数不会为 0(至少为 1)。
// vertical-pod-autoscaler/pkg/updater/eviction/pods_eviction_restriction.go
func (e *podsEvictionRestrictionImpl) CanEvict(pod *apiv1.Pod) bool {
cr, present := e.podToReplicaCreatorMap[getPodID(pod)] // 根据 pod ID 找到其控制器
if present {
singleGroupStats, present := e.creatorToSingleGroupStatsMap[cr]
if pod.Status.Phase == apiv1.PodPending {
return true // 对于处于 Pending 状态的 Pod,可以被驱逐
}
if present {
shouldBeAlive := singleGroupStats.configured - singleGroupStats.evictionTolerance // 由 evictionToleranceFraction 控制,表示最多能驱逐的副本数
if singleGroupStats.running-singleGroupStats.evicted > shouldBeAlive {
return true // 对于可容忍的驱逐数量之内,可以被驱逐
}
if singleGroupStats.running == singleGroupStats.configured &&
singleGroupStats.evictionTolerance == 0 &&
singleGroupStats.evicted == 0 {
return true // 若所有 Pods 都在运行,并且可容忍的驱逐数量过小,则只可以驱逐一个
}
}
}
return false
}`Evict`函数负责对一个 Pod 进行驱逐,即指对目的 Pod 发送一个驱逐请求。
总结
Autoscaler 是 Kubernetes 社区维护的一个集群自动化扩缩容工具库,VPA 只是其中的一个模块。目前许多公有云的 VPA 实现,也都与 Autoscaler 的 VPA 实现类似,比如 GKE 等。但 GKE 相比 Autoscaler[7] 还存在一些改进:
- 在资源推荐值计算时,额外考虑了支持最大节点数与单节点资源限额
- VPA 能够通知 Cluster Autoscaler 来调整集群容量
- 将 VPA 作为一个控制面的进程,而非 Worker 节点中的 Deployments
但无论如何,Autoscaler 的 VPA 是基于对 Pod 的驱逐重建完成的。在部分对驱逐敏感的场景下,Autoscaler 其实并不能很好的胜任 VPA 工作。面对这种场景时,就需要一种可以原地更新 Pod 资源的技术了。
参考链接
1. https://en.wikipedia.org/wiki/Starvation_(computer_science)
2. https://github.com/kubernetes/autoscaler
3. https://github.com/kubernetes/autoscaler/tree/fbe25e1708cef546e6b114e93b06f03346c39c24
4. https://github.com/kubernetes/autoscaler/blob/fbe25e1708cef546e6b114e93b06f03346c39c24/vertical-pod-autoscaler/pkg/apis/autoscaling.k8s.io/v1/types.go#L53
5. https://jsonpatch.com/
6. https://kubernetes.io/docs/concepts/workloads/pods/disruptions/
7. https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler
8. https://shawnh2.github.io/post/2023/09/30/vpa-in-autoscaler.html