第四课:早期的编程方式、编程语言发展史、编程基础-语句和函数、算法入门、数据结构、阿兰图灵及软件工程
第四课:早期的编程方式、编程语言发展史、编程基础-语句和函数、算法入门、数据结构、阿兰图灵及软件工程
- 第十章:早期的编程方式
-
- 1、早期,程序如何进入计算机
- 2、早期计算机的编程
- 3、现代计算机基础结构——冯诺依曼计算机
- 第十一章:编程语言发展史
-
- 概念梳理
- 1、早期二进制
- 2、汇编器&助记符
- 3、最早高级编程语言“A-0”
- 4、开始广泛应用的高级编程语言
- 5、通用编程语言——COBOL
- 6、现代编程语言1960s-2000
- 7、安全漏洞&补丁由来
- 第十二章:编程基础-语句和函数
-
- 1、变量、赋值语句
- 2、if判断
- 3、while循环
- 4、for循环
- 5、函数
- 第十三章:算法入门
-
- 基本慨念
- 1、选择排序
- 2、大O表示法
- 3、归并排序
- 4、Dijkstra算法
- 第十四章:数据结构
-
- 1、数组 下标
- 2、字符串
- 3、矩阵
- 4、结构体
- 5、指针
- 6、节点
- 7、链表
- 8、队列
- 9、栈
- 10、树
- 11、图
- 第十五章:阿兰图灵
-
- 可判定性问题
- 第十六章:软件工程
-
- 1、对象
- 2、API
- 3、集成开发环境(IDE)
- 4、调试(debug)
- 5、文档与注释
- 6、版本控制
- 7、质量控制测试
- 8、beta alpha
各位小伙伴想要博客相关资料的话关注公众号:chuanyeTry即可领取相关资料!
第十章:早期的编程方式
1、早期,程序如何进入计算机
程序必须人为地输入计算机。
早期,电脑无内存的概念,人们通过打孔纸卡等物理手段,输入数据(数字),进入计算机。
2、早期计算机的编程
- 打孔纸卡/纸带:在纸卡上打孔,用读卡器读取连通电路,进行编程。原因,穿孔纸卡便宜、可靠也易懂。
62500张纸卡=5MB - 数据插线板:通过插拔线路的方式,改变器件之间的连接方式,进行编程。
- 面板开关(1980s 前):通过拨动面板上的开关,进行编程。输入二进制操作码,按存储按钮,推进至下一个内存位,直至操作完内存,按运行键执行程序。(内存式电脑)
3、现代计算机基础结构——冯诺依曼计算机
冯诺依曼计算机的标志是,一个处理器(有算术逻辑单元)+数据寄存器+指令寄存器+指令地址寄存器+内存
第十一章:编程语言发展史
概念梳理
伪代码:用自然语言(中文、英语等)对程序的高层次描述,称为“伪代码”。
汇编器:用于将汇编语言装换成机器语言。一条汇编语句对应一条机器指令。
助记符(汇编器):软件
1、早期二进制
写代码先前都是硬件层面的编程,硬件编程非常麻烦,所以程序员想要一种更通用的编程方法,就是软件。
早期,人们先在纸上写伪代码,用“操作码表”把伪代码转成二进制机器码,翻译完成后,程序可以喂入计算机并运行。
2、汇编器&助记符
背景:1940~1950s,程序员开发出一种新语言,更可读更高层次(汇编码)。每个操作码分配一个简单名字,叫“助记符”。但计算机不能读懂“助记符”,因此人们写了二进制程序“汇编器”来帮忙。
作用:汇编器读取用“汇编语言”写的程序,然后转成“机器码”。
3、最早高级编程语言“A-0”
汇编只是修饰了一下机器码,一般来说,一条汇编指令对应一条机器指令,所以汇编码和底层硬件的连接很紧密,汇编器仍然强迫程序员思考底层逻辑。
1950s,为释放超算潜力,葛丽丝·霍普博士,设计了一个高级编程语言,叫“Arithmetic Language Version 0”,一行高级编程语言可以转成几十条二进制指令。但由于当时人们认为,计算机只能做计算,而不能做程序,A-0未被广泛使用。
过程:高级编程语言→编译器→汇编码/机器码
4、开始广泛应用的高级编程语言
FORTRAN1957 年由 IBM1957 年发布,平均来说,FORTRAN 写的程序,比等同的手写汇编代码短20倍,FORTRAN 编译器会把代码转成机器码。但它只能运行于一种电脑中。
5、通用编程语言——COBOL
1959年,研发可以在不同机器上通用编程语言。
最后研发出一门高级语言:“普通面向商业语言”,简称 COBOL。
每个计算架构需要一个 COBOL 编译器,不管是什么电脑都可以运行相同的代码,得到相同结果。
6、现代编程语言1960s-2000
1960s 起,编程语言设计进入黄金时代。
1960:LGOL, LISP 和 BASIC 等语言。
70年代有:Pascal,C 和 Smalltalk。
80年代有:C++,Objective-C 和 Perl。
90年代有:Python,Ruby 和 Java*。
7、安全漏洞&补丁由来
在1940年代,是用打孔纸带进行的,但程序出现了问题(也就是漏洞),为了节约时间,只能贴上胶带也就是打补丁来填补空隙,漏洞和补丁因此得名。
第十二章:编程基础-语句和函数
1、变量、赋值语句
如a=5,其中a为可赋值的量,叫做变量。把数字5放 a 里面,这叫“赋值语句”,即把一个值赋给一个变量。
2、if判断
可以想成是“如果 X 为真,那么执行 Y,反之,则不执行Y”,if语句就像岔路口,走哪条路取决于条件的真假。
3、while循环
当满足条件时进入循环,进入循环后,当条件不满足时,跳出循环。
4、for循环
for循环不判断条件,判断次数,会循环特定次数,不判断条件。for 的特点是,每次结束,i会+1。
5、函数
当一个代码很常用的时候,我们把它包装成一个函数(也叫方法或者子程序),其他地方想用这个代码,只需要写函数名即可。
第十三章:算法入门
基本慨念
算法:解决问题的基本步骤。
1、选择排序
数组:一组数据。
选择排序的复杂度为O(n²)。
2、大O表示法
大O表示法(算法)的复杂度:算法的输入大小和运行步骤之间的关系,来表示运行速度的量级。
3、归并排序
归并排序的算法复杂度为O(n*log n),n是需要比较+合并的次数,和数组大小成正比,log n是合并步骤所需要的次数,归并排序比选择排序更有效率。
4、Dijkstra算法
一开始复杂度为O(n²),后来复杂度为O(nlog n +I),n表示节点数,I表示有多少条线。
第十四章:数据结构
1、数组 下标
数组(Array),也叫列表(list)或向量(Vector),是一种数据结构。为了拿出数组中某个值,我们要指定一个下标(index),大多数编程语言里,数组下标都从 0 开始,用方括号 [ ] 代表访问数组。
注意:很容易混淆“数组中第 5 个数”和“数组下标为 5 的数”,数组下标为5的数是数组里面的第6个数。
2、字符串
即字母、数字、标点等组成的数组,字符串在内存里以0结尾。
3、矩阵
可以把矩阵看成数组的数组
4、结构体
把几个有关系的变量存在一起叫做结构体。
5、指针
指针是一种特殊变量,指向一个内存地址,因此得名。
6、节点
以指针为变量的结构体叫节点。
7、链表
用节点可以做链表,链表是一种灵活数据结构,能存很多个节点 (node),灵活性是通过每个节点指向下一个节点实现的。链表可以是循环的也可以是非循环的,非循环的最后一个指针是0。
8、队列
“队列”就像邮局排队,谁先来就排前面,这叫先进先出(FIFO——first in first out),可以把“栈”想成一堆松饼,做好一个新松饼,就堆在之前上面,吃的时候,是从最上面开始。
9、栈
栈是后进先出(LIFO)。
10、树
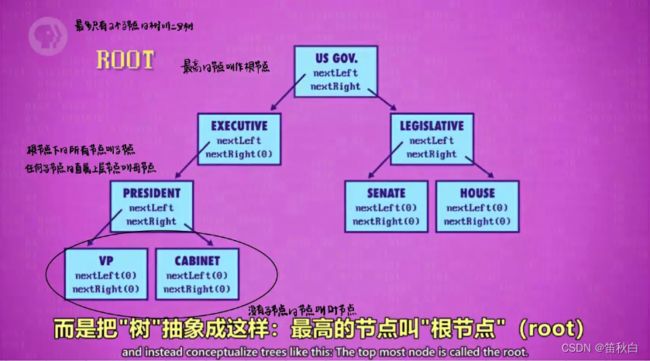
11、图
如果数据随意连接,有循环,我们称之为图。
第十五章:阿兰图灵
可判定性问题
是否存在一种算法,输入正式逻辑语句输出准确的“是”或“否”答案?
- 阿隆佐邱奇,Lambda算子
美国数学家阿隆佐·丘奇,开发了一个叫“Lambda 算子”的数学表达系统,证明其不存在。 - 图灵机
只要有足够的规则,状态和纸带,图灵机可以解决一切计算问题。和图灵机一样完备,叫做图灵完备。 - 停机问题
证明图灵机不能解决所有问题。 - 图灵测试
向人和机器同时发信息,收到的回答无法判断哪个是人,哪个是计算机,则计算机达到了智能程度。
第十六章:软件工程
1、对象
当任务庞大,函数太多,我们需要把函数打包成层级,把相关代码都放一起,打包成对象。对象可以包括其他对象,函数和变量。把函数打包成对象的思想叫做“面向对象编程”,面向对象的核心是隐藏复杂度,选择性的公布功能。
2、API
当团队接收到子团队编写的对象时,需要文档和程序编程接口(API)来帮助合作。API控制哪些函数和数据让外部访问,哪些仅供内部。
3、集成开发环境(IDE)
程序员用来专门写代码的工具。
4、调试(debug)
IDE帮你检查错误,并提供信息,帮你解决问题,这个过程叫调试。
5、文档与注释
文档一般放在一个叫做README的文件里,文档也可以直接写成“注释”,放在源代码里,注释是标记过的一段文字,编译代码时,注释会被忽略。注释的唯一作用是帮助开发者理解代码。
6、版本控制
版本控制,又称源代码管理。大型软件公司会把会把代码放到一个中心服务器上,叫“代码仓库”,程序员可以把想修改的代码借出,修改后再提交回代码仓库。版本控制可以跟踪所有变化,如果发现bug,全部或部分代码,可以“回滚”到之前的稳定版。
7、质量控制测试
可以统称“质量保证测试”(QA),作用是找bug
8、beta alpha
beta版软件,即是软件接近完成,但没有完全被测试过,公司有时会向公众发布beta版,以帮助发现问题。alpha是beta前的版本,一般很粗糙,只在内部测试。