【数据采集与预处理】数据接入工具Kafka
目录
一、Kafka简介
(一)消息队列
(二)什么是Kafka
二、Kafka架构
三、Kafka工作流程分析
(一)Kafka核心组成
(二)写入流程
(三)Zookeeper 存储结构
(四)Kafka 消费过程
四、Kafka准备工作
(一)Kafka安装配置
(二)启动Kafka
(三)测试Kafka是否正常工作
五、编写Spark Streaming程序使用Kafka数据源
一、Kafka简介
(一)消息队列
消息队列内部实现原理
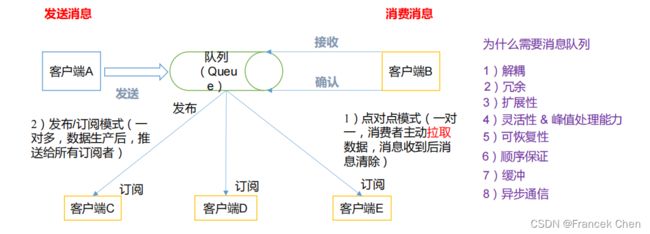
1、点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
2、发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
(二)什么是Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
在流式计算中,Kafka 一般用来缓存数据,Storm 通过消费 Kafka 的数据进行计算。
1、Apache Kafka 是一个开源消息系统。是由 Apache 软件基金会开发的一个开源消息系统项目。
2、Kafka 最初是由 LinkedIn 公司开发,并于 2011 年初开源。2012 年 10 月从 Apache Incubator 毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3、Kafka 是一个分布式消息队列。Kafka 对消息保存时根据 Topic 进行归类,发送消息者称为 Producer,消息接受者称为 Consumer,此外 kafka 集群有多个 kafka 实例组成,每个实例(server)称为 broker。
4、无论是 kafka 集群,还是 consumer 都依赖于 zookeeper 集群保存一些 meta 信息,来保证系统可用性。
二、Kafka架构

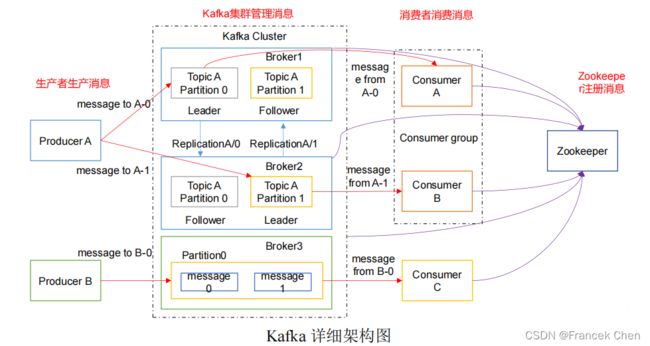
1、Producer :消息生产者,就是向 kafka broker 发消息的客户端;
2、Consumer :消息消费者,向 kafka broker 取消息的客户端;
3、Topic :可以理解为一个队列;
4、Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 CG。topic 的消息会复制(不是真的复制,是概念上的)到所有的 CG,但每个 partion 只会把消息发给该 CG 中的一个 consumer。如果需要实现广播,只要每个 consumer 有一个独立的 CG 就可以了。要实现单播只要所有的 consumer 在同一个 CG。用 CG 还可以将 consumer 进行自由的分组而不需要多次发送消息到不同的 topic;
5、Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多个 topic;
6、Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。kafka 只保证按一个 partition 中的顺序将消息发给consumer,不保证一个 topic 的整体(多个 partition 间)的顺序;
7、Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
三、Kafka工作流程分析
(一)Kafka核心组成

(二)写入流程
Producer写入流程:
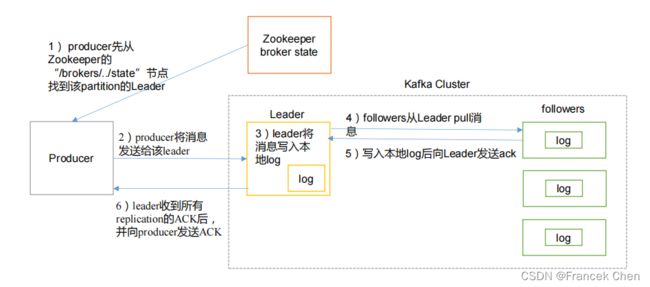
1)producer 先从 zookeeper 的 "/brokers/.../state"节点找到该 partition 的 leader
2)producer 将消息发送给该 leader
3)leader 将消息写入本地 log
4)followers 从 leader pull 消息,写入本地 log 后向 leader 发送 ACK
5)leader 收到所有 ISR 中的 replication 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset)并向 producer 发送 ACK
(三)Zookeeper 存储结构
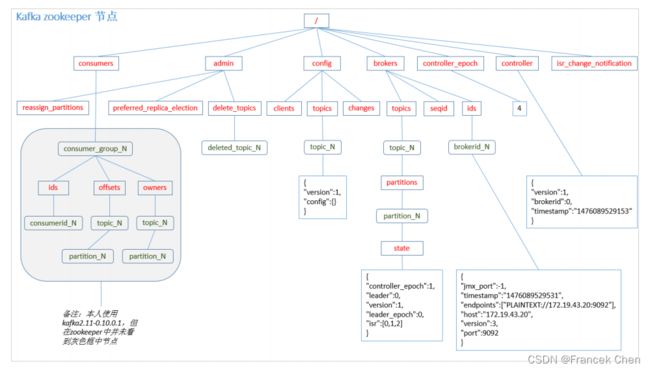
注意:producer 不在 zk 中注册,消费者在 zk 中注册。
(四)Kafka 消费过程
消费者组:

消费者是以 consumer group 消费者组的方式工作,由一个或者多个消费者组成一个组,共同消费一个 topic。每个分区在同一时间只能由 group 中的一个消费者读取,但是多个 group 可以同时消费这个 partition。在图中,有一个由三个消费者组成的 group,有一个消费者读取主题中的两个分区,另外两个分别读取一个分区。某个消费者读取某个分区,也可以叫做某个消费者是某个分区的拥有者。
在这种情况下,消费者可以通过水平扩展的方式同时读取大量的消息。另外,如果一个消费者失败了,那么其他的 group 成员会自动负载均衡读取之前失败的消费者读取的分区。
四、Kafka准备工作
(一)Kafka安装配置
1、到官网下载jar包,保存至“/usr/local/uploads”目录下。
Apache Kafka https://kafka.apache.org/downloads
https://kafka.apache.org/downloads
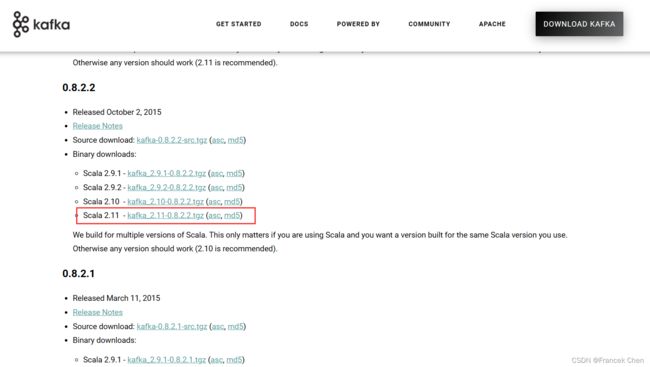
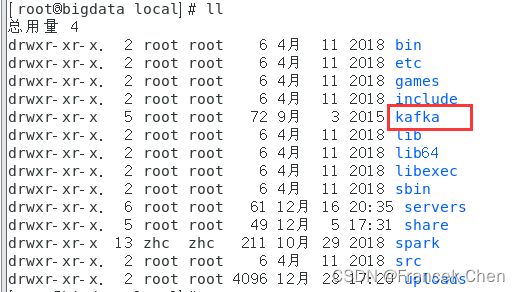
2、解压安装Kafka,并重命名解压后的文件夹。
[root@bigdata uploads]# tar -zxvf kafka_2.11-0.8.2.2.tgz -C /usr/local
[root@bigdata uploads]# cd ..
[root@bigdata local]# mv kafka_2.11-0.8.2.2/ kafka
3、配置Spark环境
[root@bigdata local]# cd ./spark/conf
[root@bigdata conf]# vi spark-env.sh在文件的第一行接着添加如下内容:
:/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*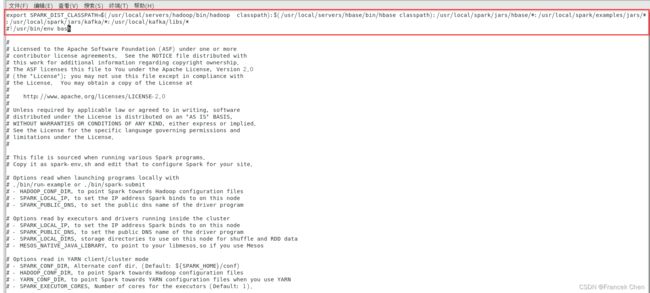
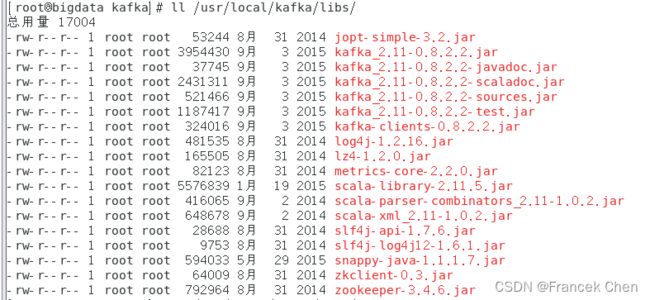
接着,在“/usr/local/spark/jars”目录下新建文件夹kafka,并将“/usr/local/kafka/libs/”目录下的所有jar包都拷贝到“/usr/local/spark/jars/kafka”目录下。
[root@bigdata spark]# cd /usr/local/spark/jars
[root@bigdata jars]# mkdir kafka
[root@bigdata jars]# cd kafka
[root@bigdata kafka]# cp /usr/local/kafka/libs/* .
然后,将“/usr/local/uploads/”下的spark-streaming-kafka-0-8_2.11-2.4.0.jar包也拷贝到“/usr/local/spark/jars/kafka”目录下。
[root@bigdata kafka]# cp /usr/local/uploads/spark-streaming-kafka-0-8_2.11-2.4.0.jar .
spark-streaming-kafka-0-8_2.11-2.4.0.jar的下载地址:
http://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-8_2.11/2.4.0
下图是拷贝完成后的“/usr/local/spark/jars/kafka”目录下的所有jar包。
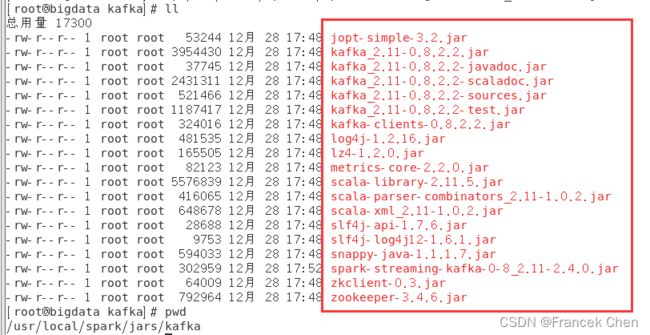
这样,Spark环境就配好了。
(二)启动Kafka
1、启动Zookeeper服务
打开一个终端,输入下面命令启动Zookeeper服务:
[root@bigdata kafka]# cd /usr/local/kafka
[root@bigdata kafka]# ./bin/zookeeper-server-start.sh config/zookeeper.properties
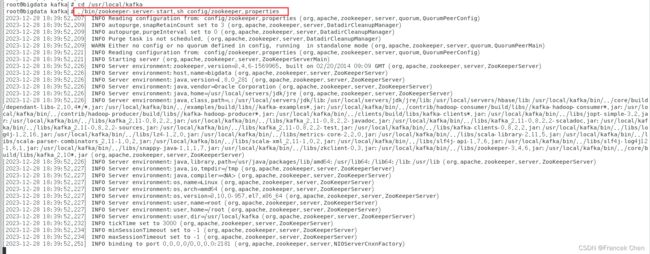
千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了。
2、启动Kafka服务
打开第二个终端,然后输入下面命令启动Kafka服务:
[root@bigdata zhc]# cd /usr/local/kafka
[root@bigdata kafka]# bin/kafka-server-start.sh config/server.properties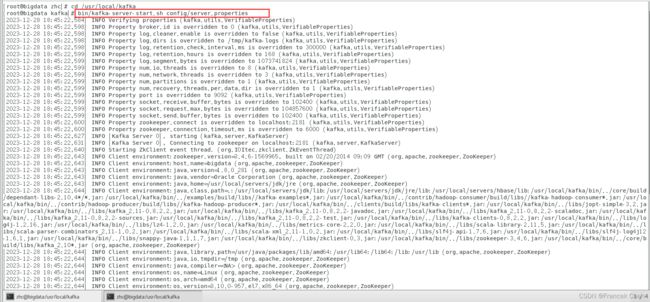
千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了
(三)测试Kafka是否正常工作
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsendertest”的Topic:
[root@bigdata zhc]# cd /usr/local/kafka
[root@bigdata kafka]# ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wordsendertest
#可以用list列出所有创建的Topic,验证是否创建成功
[root@bigdata kafka]# ./bin/kafka-topics.sh --list --zookeeper localhost:2181
replication-factor:每个partition的副本个数
下面用生产者(Producer)来产生一些数据,请在当前终端(记作“数据源终端”)内继续输入下面命令:
[root@bigdata kafka]# ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wordsendertest
上面命令执行后,就可以在当前终端内用键盘输入一些英文单词,比如可以输入:
hello hadoop
hello spark

现在可以启动一个消费者,来查看刚才生产者产生的数据。请另外打开第四个终端,输入下面命令:
[root@bigdata zhc]# cd /usr/local/kafka
[root@bigdata kafka]# ./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wordsendertest --from-beginning
可以看到,屏幕上会显示出如下结果,也就是刚才在另外一个终端里面输入的内容:

五、编写Spark Streaming程序使用Kafka数据源
在“/home/zhc/mycode/”路径下新建文件夹sparkstreaming,再在该文件夹下新建py文件KafkaWordCount.py。
#/home/zhc/mycode/sparkstreaming/KafkaWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: KafkaWordCount.py ", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingKafkaWordCount")
ssc = StreamingContext(sc, 1)
zkQuorum, topic = sys.argv[1:]
kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1})
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
新建一个终端(记作“流计算终端”),执行KafkaWordCount.py,命令如下:
[root@bigdata zhc]# cd /home/zhc/mycode
[root@bigdata mycode]# mkdir sparkstreaming
[root@bigdata mycode]# cd sparkstreaming
[root@bigdata sparkstreaming]# vi KafkaWordCount.py
[root@bigdata sparkstreaming]# spark-submit KafkaWordCount.py localhost:2181 wordsendertest
这时再切换到之前已经打开的“数据源终端”,用键盘手动敲入一些英文单词,在流计算终端内就可以看到类似如下的词频统计动态结果。
