【Python高阶技巧】正则表达式
一、正则表达式
二、正则表达式三个基础方法、re模块的基础使用
三、元字符匹配、字符串的r标记
一、正则表达式
正则表达式是一种用于匹配字符串模式的表达式。它提供了一种灵活、强大的文本匹配和搜索的方法。正则表达式通常由字符和特殊字符组成,用于描述字符串的特定模式。
以下是正则表达式的基本概念和语法:
-
普通字符: 匹配与其自身相同的字符,例如字母、数字、空格等。
-
元字符: 具有特殊含义的字符,例如
.、*、+、?、^、$等。 -
字符类: 使用方括号
[]表示,匹配其中任意一个字符。例如,[aeiou]匹配任意一个元音字母。 -
反义字符类: 使用
[^]表示,匹配除括号内字符之外的任意一个字符。例如,[^0-9]匹配任意一个非数字字符。 -
预定义字符类: 匹配常见的字符类,例如
\d匹配数字,\w匹配单词字符,\s匹配空白字符。 -
数量词: 用于指定匹配的次数,例如
*表示零次或多次,+表示一次或多次,?表示零次或一次,{n}表示恰好 n 次,{n,}表示至少 n 次,{n,m}表示 n 到 m 次。 -
转义字符: 使用反斜杠
\进行转义,将其后的字符视为普通字符。例如,\.匹配实际的点字符。 -
分组和捕获: 使用圆括号
()进行分组,形成子表达式。分组可以用于应用数量词,或者在匹配时捕获匹配的内容。 -
反向引用: 在正则表达式中引用之前捕获的内容。例如,
(a)\1匹配两个连续的字母 “aa”。 -
锚点: 用于指定匹配的位置,例如
^表示字符串的开头,$表示字符串的结尾。
正则表达式可以在不同编程语言和文本编辑器中使用,例如在Python、JavaScript、Java、C#等中都有内置的正则表达式支持。它们在文本处理、数据提取、验证输入等方面都有广泛应用。
二、正则表达式三个基础方法、re模块的基础使用
正则表达式
正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。
简单来说,正则表达式就是使用:字符串定义规则,并通过规则去验证字符串是否匹配。
比如,验证一个字符串是否是符合条件的电子邮箱地址,只需要配置好正则规则,即可匹配任意邮箱。
比如通过正则规则: ( ^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$) 即可匹配一个字符串是否是标准邮箱格式
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
但如果不使用正则,使用if else来对字符串做判断就非常困难了。
re模块的基础使用
在Python中,re 模块提供了正则表达式的支持,用于进行字符串匹配、搜索和替换。以下是 re 模块的一些基础用法:
- 导入模块:
import re
- 使用
re.search进行匹配:
pattern = r"hello"
text = "Hello, World! This is a hello message."
match = re.search(pattern, text)
if match:
print("Pattern found:", match.group())
else:
print("Pattern not found.")
- 使用
re.match进行匹配:
pattern = r"Hello"
text = "Hello, World! This is a hello message."
match = re.match(pattern, text)
if match:
print("Pattern found at the beginning:", match.group())
else:
print("Pattern not found at the beginning.")
- 使用
re.findall进行全局匹配:
pattern = r"hello"
text = "Hello, World! This is a hello message. Say hello!"
matches = re.findall(pattern, text)
if matches:
print("Patterns found:", matches)
else:
print("Pattern not found.")
- 使用
re.finditer进行迭代匹配:
pattern = r"hello"
text = "Hello, World! This is a hello message. Say hello!"
matches = re.finditer(pattern, text)
for match in matches:
print("Pattern found at index", match.start())
- 使用
re.sub进行替换:
pattern = r"hello"
text = "Hello, World! This is a hello message. Say hello!"
replacement = "hi"
new_text = re.sub(pattern, replacement, text)
print("Original text:", text)
print("Modified text:", new_text)
这些示例演示了 re 模块中一些常用函数的基本用法。在使用正则表达式时,可以根据具体的匹配需求选择合适的函数。正则表达式的语法和规则更加复杂,可以根据需要深入学习和使用。
match方法
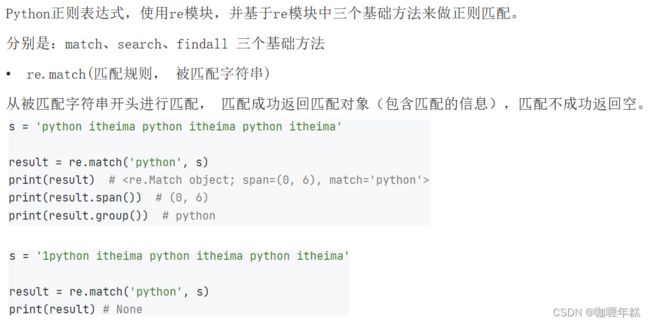
search方法
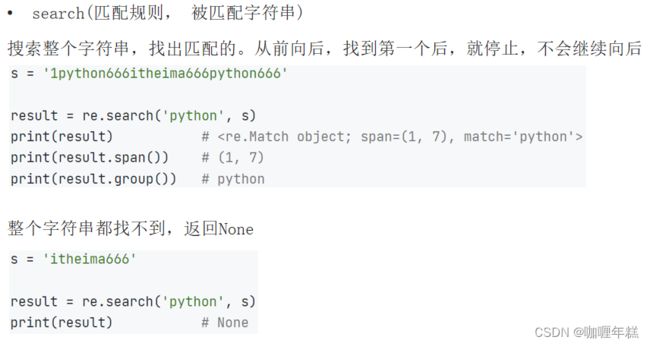
findall方法
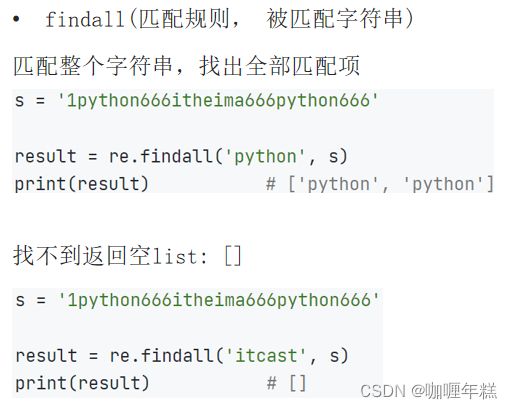
代码
"""
演示Python正则表达式re模块的3个基础匹配方法
"""
import re
s = "1python itheima python python"
# match 从头匹配
result = re.match("python", s)
print(result)
# print(result.span())
# print(result.group())
# search 搜索匹配
result = re.search("python2", s)
print(result)
# findall 搜索全部匹配
result = re.findall("python", s)
print(result)
总结
- 什么是正则表达式
是一种字符串验证的规则,通过特殊的字符串组合来确立规则
用规则去匹配字符串是否满足
如(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)可以表示为一个标准邮箱的格式 - re模块的三个主要方法
re.match,从头开始匹配,匹配第一个命中项re.search,全局匹配,匹配第一个命中项re.findall,全局匹配,匹配全部命中项
三、元字符匹配、字符串的r标记
正则表达式的各类元字符规则
在正则表达式中,元字符是具有特殊含义的字符,它们用于构建模式以匹配字符串。以下是一些常用的元字符和它们的匹配规则:
-
.(点):匹配任意字符(除了换行符\n)。pattern = r"b.t" text = "bat, bet, bit, bot, but" matches = re.findall(pattern, text) print(matches) # Output: ['bat', 'bet', 'bit', 'bot', 'but'] -
^:匹配字符串的开头。pattern = r"^Hello" text = "Hello, World! This is a greeting." match = re.search(pattern, text) if match: print("Pattern found at the beginning.") else: print("Pattern not found at the beginning.") -
$:匹配字符串的结尾。pattern = r"message$" text = "This is a simple message" match = re.search(pattern, text) if match: print("Pattern found at the end.") else: print("Pattern not found at the end.") -
*:匹配前一个字符零次或多次。pattern = r"go*gle" texts = ["ggle", "gogle", "google", "gooogle"] for text in texts: if re.match(pattern, text): print(f"Pattern found in {text}") -
+:匹配前一个字符一次或多次。pattern = r"go+gle" texts = ["ggle", "gogle", "google", "gooogle"] for text in texts: if re.match(pattern, text): print(f"Pattern found in {text}") -
?:匹配前一个字符零次或一次。pattern = r"go?gle" texts = ["ggle", "gogle", "google", "gooogle"] for text in texts: if re.match(pattern, text): print(f"Pattern found in {text}")
这些元字符可以用于构建复杂的模式,实现更灵活的字符串匹配。正则表达式的语法还包括其他元字符和特殊符号,具体取决于匹配的需求。
字符串的r标记的作用
在Python中,字符串前面带有 r(原始字符串标记)的字符串被称为原始字符串。这种字符串在处理正则表达式、文件路径等需要使用反斜杠 \ 的情况下特别有用。r 表示"raw"(原始),它告诉解释器不要处理反斜杠 \,而是将其视为普通字符。
以下是使用原始字符串的一些情况和好处:
-
正则表达式:
# 普通字符串中的正则表达式模式 pattern = "\\d+" # 使用原始字符串,不需要双反斜杠 pattern_raw = r"\d+" -
文件路径:
# 普通字符串中的文件路径 file_path = "C:\\Users\\Username\\Documents\\file.txt" # 使用原始字符串,简化文件路径 file_path_raw = r"C:\Users\Username\Documents\file.txt" -
正则表达式中的转义字符:
# 匹配反斜杠字符的正则表达式 pattern = "\\\\" # 使用原始字符串,不需要四个反斜杠 pattern_raw = r"\\"
使用原始字符串可以减少对反斜杠进行转义的繁琐操作,使代码更清晰、易读。在处理需要大量反斜杠的场景中,使用原始字符串能够减少错误,并提高代码的可维护性。
元字符匹配

案例
-
匹配账号,只能由字母和数字组成,长度限制6到10位
规则为:^[0-9a-zA-Z]{6, 10}$ -
匹配QQ号,要求纯数字,长度5-11,第一位不为0
规则为:^[1-9][0-9]{4, 10}&
[1-9]匹配第一位,[0-9]匹配后面4到10位 -
匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
规则为:^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+& -
[\w-]+表示出现a-z A-Z 0-9 _ 和 - 字符最少一个,最多不限 -
(\.[\w-]+)*,表示出现组合 . 和 a-z A-Z 0-9 _ -的组合最少0次,最多不限
用于匹配:[email protected]中的ced.efg这部分 -
@表示匹配@符号 -
(qq|163|gmail)表示只匹配这3个邮箱提供商 -
(\.[\w-]+)+表示a-z A-Z 0-9 _ -的组合最少1次,最多不限
用于匹配[email protected]中的.com.cn这种
最后使用+表示最少一次,即比如:.com
多了可以是:.com.cn.eu这样
代码
"""
演示Python正则表达式使用元字符进行匹配
"""
import re
# s = "itheima1 @@python2 !!666 ##itccast3"
#
# result = re.findall(r'[b-eF-Z3-9]', s) # 字符串前面带上r的标记,表示字符串中转义字符无效,就是普通字符的意思
# print(result)
# 匹配账号,只能由字母和数字组成,长度限制6到10位
r = '^[0-9a-zA-Z]{6,10}$'
s = '123456_'
print(re.findall(r, s))
# 匹配QQ号,要求纯数字,长度5-11,第一位不为0
r = '^[1-9][0-9]{4,10}$'
s = '1050148902'
print(re.findall(r, s))
# 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
# [email protected]
# [email protected]
# {内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}@{内容}.{内容}.{内容}
r = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
# s = '[email protected]'
#s = '[email protected]'
s = '[email protected]'
print(re.match(r, s))
r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
这是一个用于匹配邮箱地址的正则表达式。以下是正则表达式中每个部分的解释:
^: 匹配字符串的开头。[\w-]+: 匹配至少一个或更多(+)字母、数字或连字符(-)。(\.[\w-]+)*: 匹配零个或多个(*)点(.)后跟至少一个或更多字母、数字或连字符的组合。@: 匹配邮箱地址中的@符号。(qq|163|gmail): 匹配三个选项之一,即qq、163或gmail。(\.[\w-]+)+: 匹配至少一个或更多点(.)后跟至少一个或更多字母、数字或连字符的组合。$: 匹配字符串的结尾。
因此,该正则表达式可以用于验证符合特定格式的邮箱地址,例如 [email protected]、[email protected] 等。请注意,这只是一个简单的例子,实际的邮箱地址验证可能需要更复杂的正则表达式,以涵盖更多的情况。
总结
- 字符串的r标记表示,字符串内转移字符无效,作为普通字符使用
- 正则表达式的元字符规则
当涉及到元字符匹配时,我们可以将其分为四个主要类别:单字符匹配、数量匹配、边界匹配和分组匹配。
以下是每个类别的元字符及其功能,以HTML表格的形式呈现:
单字符匹配
| 字符 | 功能 |
|---|---|
| . | 匹配任意字符(除了换行符) |
| \d | 匹配任意数字 |
| \D | 匹配任意非数字字符 |
| \w | 匹配任意字母数字字符 |
| \W | 匹配任意非字母数字字符 |
| \s | 匹配任意空白字符 |
| \S | 匹配任意非空白字符 |
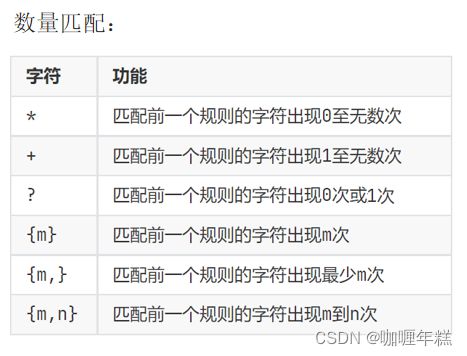
数量匹配
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符零次或多次 |
| + | 匹配前一个字符一次或多次 |
| ? | 匹配前一个字符零次或一次 |
| {n} | 匹配前一个字符恰好 n 次 |
| {n,} | 匹配前一个字符至少 n 次 |
| {n,m} | 匹配前一个字符 n 到 m 次 |
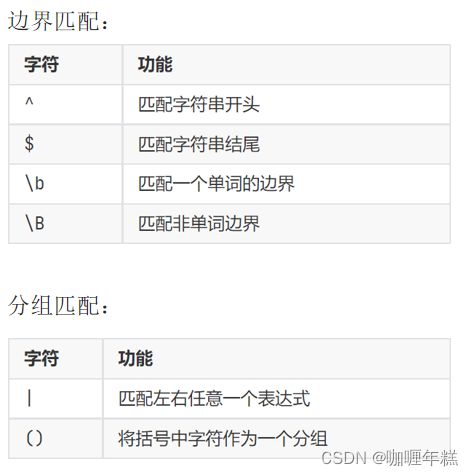
边界匹配
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| \b | 匹配单词的边界 |
| \B | 匹配非单词边界 |
分组匹配
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| ( ) | 将括号中字符作为一个分组 |
| (...) | 创建捕获组 |
| (?P |
创建命名捕获组 |
| \1, \2, ... | 引用捕获组 |
这些表格列出了每个类别中一些常用的元字符及其功能。正则表达式的语法和规则更加复杂,可以根据需要深入学习和使用。
注意:
正则表达式中的{m,n}表示匹配前面的模式至少 m 次,最多 n 次。在{m,n}中,m 和 n 之间不应该有空格。因此,正确的写法是{m,n},而不是{m, n}。