信息论安全中常用的符号与术语(附详细解释)
1. ![]()
GF代表伽罗瓦域(Galois field),与通常所说的有限域类似。q代表该有限域内有q个元素。
2. 
实数域
3. 
复数域
4. ![]()
自然数,![]() 代表正整数
代表正整数
5. 
字母集,也可以包含数字,本质就是一个集合。![]() 代表集合的基数,也就是集合中包含元素的个数
代表集合的基数,也就是集合中包含元素的个数
6. 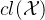
集合的闭包,其中cl来源于单词closure。在给定的关系中,添加最少的元素,使其具有某种性质,则称添加后的集合为该性质上关系的闭包。
7. ![]()
集合的凸包,解释为一个给定点集所包含的最小凸集。其中co来源于单词convex。
8. 
在信息论安全中会出现,代表指示函数。当 x 属于该集合时,该函数的值为 1;当 x 不属于该集合时,该函数的值为 0
9. 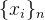
代表有n个元素的集合,也就是![]()
10. ![]()
集合中的某个元素
11. ![]()
绝对值运算
12. ![]()
通俗来讲就是往上取整,数学表达则是:寻找一个整数n,使其满足![]()
13. ![]()
通俗来讲就是往下取整,数学表达则是:寻找一个整数n,使其满足![]()
14. ![[x,y]](http://img.e-com-net.com/image/info8/ae9d585c36d84f6a8519cdc93df49fc2.png)
信息论中通常需要整数序列,通常代表x与y之间的整数。为了让集合的个数最大,通常左边下取整![]() ,右边上取整
,右边上取整![]()
15. ![]()
当x是正数时,取其本身;当当x是负数时,直接取0,数学表达为![]()
16. ![]()
正负号指示函数。当x为正数时,该函数为+1;当x为负数时,该函数为-1;通常来讲,当x取0时,也规定函数值为+1。数学表达为:

17. 
n长的序列![]()
18. 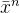
n长的序列,且每一个位置的元素均一样为![]()
19. 
信息论中通常代表一个很小的正实数,类似计算复杂性领域的可忽略性质。
20. ![]()
某些关于的函数,本来就是一个很小的数。当足够小后,该函数也趋近于0,如下:
![]()
21. ![]()
代表与和n相关的函数,与刚好相反,该函数代表当n足够大时,该函数趋近于0,如下:
![]()
22. 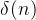
代表与n相关的函数,该函数代表当n足够大时,该函数趋近于0,如下:
![]()
备注:因为信息论安全很多时候需要研究渐近安全,所以会包括一些极限的性质。
23. ![]()
通常代表列向量,包含n个元素,也就是![]()
24. ![]()
向量的转置,列向量转为行向量。
25. ![]()
Hermitian转置,其实就是通常所说的共轭转置
26. ![]()
一个矩阵H有m行n列,其中第i行第j列记为![]() ,当然
,当然![]()
27. ![]()
矩阵H的行列式
28. ![]()
矩阵的迹,其中tr来源于单词trace。代表将该矩阵对角线上的元素相加,也可以是特征值相加。
29. ![]()
矩阵的秩,其中rk来源于单词rank。代表矩阵H中线性独立的行/列向量的个数
30. ![]()
矩阵的核,Ker来源于单词kernel,类比矩阵的零空间:所有经过变换矩阵后变成了零向量的向量组成的集合。
31. 
可代表随机变量,其取值范围在集合
32. 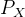
针对随机变量X的概率分布
33. ![]()
代表高斯分布,其均值为 ,方差为
,方差为
34. ![]()
代表伯努利分布,类比以前学过的两点分布。其中p代表取1的概率为p,那么取0的概率则为1-p,如下:
| 取值 | 概率 |
| 1 | p |
| 0 | 1-p |
35. ![]()
条件概率。代表给定Y时,X的概率
36. ![]()
代表强典型集。密码学中一个相对复杂的概念,此处做一个简单的解释:
在有限的集合上,对应着概率分布。取![]() ,通常为一个很小的数,序列
,通常为一个很小的数,序列![]() 称为典型集,需要满足如下要求:
称为典型集,需要满足如下要求:
![]()
![]() 可以看成字母a在n长序列中实际出现的频数,
可以看成字母a在n长序列中实际出现的频数,![]() 则代表频率,
则代表频率,![]() 代表实际的概率,
代表实际的概率,![]() 代表两者的差值很小。这跟初高中学习频率与概率的区别,很类似。如果一个序列满足这个条件,则被称之为“典型”。
代表两者的差值很小。这跟初高中学习频率与概率的区别,很类似。如果一个序列满足这个条件,则被称之为“典型”。
也就是典型集![]() 包含了所有频率与实际概率接近的序列集合,其中代表很小的数,n代表序列的长度,X代表随机变量。
包含了所有频率与实际概率接近的序列集合,其中代表很小的数,n代表序列的长度,X代表随机变量。
如果将这个地方的概率推广到联合概率,则会出现联合强典型集![]() 。
。
| 符号 | 解释 |
| 强典型集 | |
| 联合强典型集 | |
| 条件强典型集 | |
| 弱典型集 | |
| 弱联合典型集 |
有关它们的具体区别和解释都可以单列一篇,等以后再补上吧。
37. ![]()
随机变量X的期望值
38. ![]()
随机变量X的方差
39. ![]()
事件X具体的概率
40. ![]()
随机变量X的香农熵,用来纪念香农而取名。

41. ![]()
如果随机变量只能取0或1时,则称之为二进制香农函数。
42. ![]()
离散型随机变量X的碰撞熵。令![]() 代表随机变量的概率分布,碰撞熵的定义如下:
代表随机变量的概率分布,碰撞熵的定义如下:
![]()
也就是对概率分布中的概率值求数学期望,再求其对数值。注意此处的数学期望不是对随机变量X求期望,与以前的理解会不一样。对概率的值求均值的本质就是,概率的值乘以其概率,也就是概率的平方,最后再相加即可。所以碰撞熵也可以写做:
![]()
碰撞熵与碰撞概率相关,代表两个独立实验得到相同概率分布的概率。
43. ![]()
代表随机变量X的最小熵。因为最小熵对应的是最大的概率,所以右下角出现了 ,数学表达式如下:
,数学表达式如下:![]()
44. ![]()
代表连续型随机变量X的微分熵。很容易理解,离散型随机变量的熵叫香农熵,连续型随机变量的熵叫微分熵。计算公式几乎一样,只不过将求和改为积分:
![]()
45. ![]()
代表随机变量X与Y之间的互信息。互信息的计算来源于熵和条件熵,如下:
![]()
可以简单看成变量X与Y之间的关联性。
46. ![]()
P代表概率,e代表错误率,C代表码字。整个表达式代表码字C的解码错误概率。
47. ![]()
信息论中可代表码字C的条件信息量总平均值(equivocation)。
48. ![]()
码字C的信息泄露量
49. ![]()
通常应用于密钥提取算法中,代表能够保证的密钥均匀性的多少。
50. ![]()
分别代表下极限与上极限。
51. ![]()
代表函数f(x)与g(x)之间是存在定量关系的,这个关系要求两者的比值不能无限,如下:
![]()
由此我们可以说,当x值足够大时,函数g(x)的值不能为0.且当x趋近于某一值a时,两者是存在定量关系的。