Oracle 学习(2)
过滤和排序数据
where条件过滤
日期格式
查询10号部门的员工信息:SQL> select * from emp where deptno=10
查询”KING”的信息:SQL> select * from emp where ename= 'KiNg ' 未选定行。
注意:字符串大小写敏感。
SQL> select * from emp where ENAME='KING'; 则正确
查询入职日期为1981年11月17日的员工:
SQL> select * from emp where hiredate= '1981-11-17 ' 可以吗?
参看:SQL> select sysdate from dual 查看系统当前的日期 (注意其格式)。
SQL> select * from emp where hiredate= '17-11月-81 '
获取系统当前日期格式: SQL> select * from v$nls_parameters (数据字典,类似于tab)
设置列宽度:SQL> col parameter for a30
修改日期格式:SQL> alter session set NLS_DATE_FORMAT = 'yyyy-mm-dd '
再次查询:SQL> select * from emp where hiredate= '1981-11-17 '
SQL> alter session set NLS_DATE_FORMAT = 'yyyy-mm-dd hh24:mi:ss' 显示带有时间的日期
SQL> select sysdate from dual 再次查看系统时间
改回系统默认格式:SQL> alter session set NLS_DATE_FORMAT = 'DD-MON-RR';
- 字符和日期要包含在单引号中。
- 字符大小写敏感,日期格式敏感。
- 默认的日期格式是 DD-MON-RR
比较运算
普通比较运算符:
= 等于(不是==) > 大于
>= 大于等于 < 小于
<= 小于等于 <> 不等于(也可以是!=)
查询薪水不等于1250的员工信息:SQL> select * from emp where sal <> 1250;
BETWEEN…AND: 介于两值之间。
查询工资在1000-2000之间的员工:
使用比较运算符:SQL> select * from emp where sal >=1000 and sal<2000 (注意第二个sal不能省)
用between and:SQL> select * from emp where sal between 1000 and 2000
注意:1.包含边界 2. 小值在前,大值在后。 (对于日期也是如此)
查询81年2月至82年2月入职的员工信息:
SQL> select * from emp where hiredate between '1-2月-81' and '30-1月-82'
IN:在集合中。(not in 不在集合中)
查询部门号为10和20的员工信息:
(1)SQL> select * from emp where deptno=10 or deptno=20
(2)SQL> select * from emp where deptno in (10, 20)
SQL> select * from emp where deptno not in (10, 20) (30号部门的员工信息)
使用比较运算符该怎么写呢?
但是:如果是 ….. not in (10, 20, NULL) 可不可以呢?
☆NULL空值:如果结果中含有NULL,不能使用not in 操作符, 但可以使用in操作符。
课后思考为什么???
like:模糊查询‘%’匹配任意多个字符。‘_’匹配一个字符。
查询名字以S开头的员工:SQL> select * from emp where ename like 'S% ' (注意:S小写、大写不同)
查询名字是4个字的员工:SQL> select * from emp where ename like '_ _ _ _'
增加测试例子:向表中插入员工:
SQL> insert into emp(empno, ename, sal, deptno) values(1001, ' TOM_ABC ', 3000, 10)
SQL> delete from emp where empno=8888;
查询名字中包含_的员工:
SQL> select * from emp where ename like '% _ % ' 正确吗?
转义字符:
SQL> select * from emp where ename like '%\_% ' escape '\'
转义单引号本身:
SQL> select 'hello '' world' from dual 使用两个单引号来完成转义。
逻辑运算
AND 逻辑并
OR 逻辑或
NOT 逻辑非
如果…..where 表达式1 and 表达式2;
…..where 表达式2 and 表达式1; 这两句SQL语句功能一样吗?效率一样吗?
※SQL优化:
SQL在解析where的时候,是从右至左解析的。 所以: and时应该将易假的值放在右侧
or时应该将易真的值放在右侧
order by 排序
- 使用 ORDER BY 子句排序
- ASC(ascend): 升序。默认采用升序方式。
- DESC(descend): 降序
- ORDER BY 子句在SELECT语句的结尾。
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date ;
查询员工信息,按月薪排序:SQL> select * from emp order by sal 结尾加desc (descending)降序
order by 之后可以跟那些内容呢?
order by + 列名,表达式,别名,序号。 注意:语法要求order by 子句应放在select的结尾。
SQL> select ename, sal, sal*12 from emp order by sal * 12 desc
序号:默认:ename→1, sal→2,sal*12→3
SQL> select ename, sal, sal*12, from emp order by 2 desc 按月薪进行排序。
如果:SQL> select * from emp order by deptno, sal 会怎么样排序呢?
order by后有多列时,列名之间用逗号隔分,order by会同时作用于多列。上例的运行结果会在同一部门内升序,部门间再升序。
SQL> select * from emp order by deptno, sal desc 逆序呢?
desc 只作用于最近的一列,两列都要降序排,则需要两个desc。即:
SQL> select * from emp order by deptno desc, sal desc
查询员工信息, 按奖金由高到低排序:
SQL> select * from emp order by comm desc
结果前面的值为NULL, 数据在后面,如果是一个100页的报表,这样显示肯定不正确。较为人性化的显示应该将空值放在最后, 即:
SQL> select * from emp order by comm desc nulls last (注意:是nulls 而不是null)
- 排序的规则
- 可以按照select语句中的列名排序
- 可以按照别名列名排序
- 可以按照select语句中的列名的顺序值排序
- 如果要按照多列进行排序,则规则是先按照第一列排序,如果相同,则按照第二列排序;以此类推
单行函数
单行函数:只对一行进行变换,产生一个结果。函数可以没有参数,但必须要有返回值。如:concat、nvl
- 操作数据对象
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以转换数据类型
- 可以嵌套
- 参数可以是一列或一个值
字符函数
操作对象是字符串。
大致可分为两大类:一类是大小写控制函数,主要有lower、upper、initcap:
SQL> select lower('HeLlo, WORld') 转小写, upper('HellO, woRld') 转大写, initcap('hello, world') 首字母大写 from dual
另一类是字符控制函数:有CONCAT、SUBSTR、LENGTH/LENGTHB、INSTR、LPAD | RPAD、TRIM、REPLACE
substr(a, b):从a中,第b位开始取(计数从1开始),取到结尾
SQL> select substr('helloworld', 3) from dual
substr(a, b, c):从a中,第b位开始,向右取c位。
SQL> select substr('hello world', 3, 5) from dual
length:字符数, lengthb:字节数:
SQL> select length('hello world') 字符数, lengthb('hello world') 字节数 from dual;
select length('hello world') "字符数", lengthb('hello world') "字节数" from dual;
注意中英文差异。
instr:在母串中查找子串, 找到返回下标,计数从1开始。没有返回0
SQL> select instr('hello world', 'llo') from dual
lpad:左填充,参1:待填充的字符串,参2:填充后字符串的总长度(字节), 参3:填充什么 rpad:右填充。
SQL> select lpad('abcd', 10, '*') 左, rpad('abcd', 10, '#') 右 from dual
SQL> select lpad('abcd', 15, '你')左填充, rpad('abcd', 16, '我') 右填充 from dual
trim:去掉前后指定的字符
SQL> select trim('H' from 'Hello worldH') from dual
注意语法,期间含有from关键字。
replace:替换
SQL> select replace('hello world', 'l', '*') from dual
删除字符串'hello world'中的字符'l':
SQL> select replace('hello world', 'l', '') from dual
数值函数
- ROUND: 四舍五入
ROUND(45.926, 2) 45.93
- TRUNC: 截断
TRUNC(45.926, 2) 45.92
- MOD: 求余
MOD(1600, 300) 100
round(45.926, 2) 2表达的含义是保留两位小数,第二个参数如果是0可以省略不写。
SQL> select round(45.926, 2) 一, round(45.926, 1) 二, round(45.926, 0) 三, round(45.926, -1) 四, round(45.926, -2) 五 from dual
将上例中的所有round 替换为 trunc
正、负表示小数点之后,或小数点以前的位数。
SQL> select mod(1600, 600) from dual
时间函数
在Oracle中日期型的数据,既有日期部分,也有时间部分。
SQL> select sysdate from dual; (这里没有时间部分,因为系统默认的格式中不显示时间)
SQL> select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') from dual
SQL> select to_char(sysdate, 'day') from dual 可以显示当前日期星期几
日期加、减数字得到的结果仍为日期。单位:天
显示 昨天、今天、明天:
SQL> select (sysdate-1) 昨天, (sysdate) 今天, (sysdate + 1) 明天 from dual
SQL> select to_char(sysdate-1, 'yyyy-mm-dd') 昨天, to_char(sysdate, 'yyyy-mm-dd') 今天, to_char(sysdate+1, 'yyyy-mm-dd') 明天 from dual
既然一个日期型的数据加上或者减去一个数字得到的结果仍为日期,两个日期相减,得到的就是相差的天数。
计算员工的工龄:
SQL> select ename, hiredate, (sysdate - hiredate) 天, (sysdate - hiredate)/7 星期, (sysdate - hiredate)/30 月, (sysdate - hiredate)/365 年 from emp
注意:日期和日期可以相减,但是不允许相加。 日期只能和数字相加!
SQL> select sysdate+hiredate from emp
日期函数
上面求取员工工龄的结果不精确,如果想将其算准确,可以使用日期函数来做。
months_between:两个日期值相差的月数(精确值) 跟between…and无关
SQL> select ename, hiredate, (sysdate-hiredate)/30 一, months_between(sysdate, hiredate) 二 from emp
add_months:在某个日期值上,加上多少的月,正数向后计算,负数向前计算。
计算95个月以后是哪年、哪月、那天:
SQL> select add_months(sysdate, 95) 哪一天 from dual
last_day:日期所在月的最后一天。
SQL> select last_day(sysdate) from dual
next_day:指定日期的下一个日期
SQL> select next_day(sysdate, '星期一') from dual 从当前时间算起,下一个星期一
round、trunc 对日期型数据进行四舍五入和截断
SQL> select round(sysdate, 'month'), round(sysdate, 'year') from dual
SQL> select trunc (sysdate, 'month'), round(sysdate, 'year') from dual
转换函数
在不同的数据类型之间完成转换。将“123” 转换为 123。有隐式转换和显示转换之分。
隐式转换:
SQL> select * from emp where hiredate = '17-11月-81' 由Oracle数据库来做
显示转换:
SQL> select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') from dual 通过转换函数来完成。
隐式转换,前提条件是:被转换的对象是可以转换的。 (ABC→625 可以吗?)
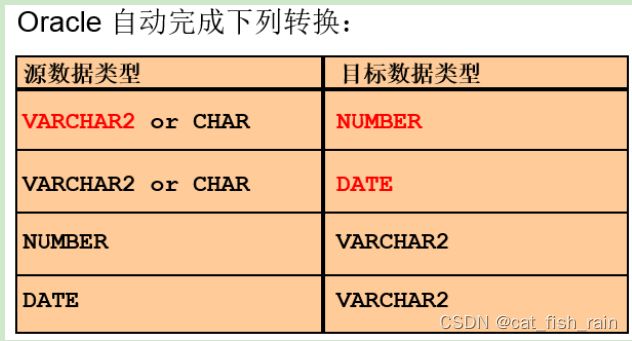
显示转换:借助to_char(数据,格式)、to_number、to_date函数来完成转换。


如果隐式转换和显示转换都可以使用,应该首选哪个呢?
※SQL优化:如果隐式、显示都可以使用,应该首选显示,这样可以省去Oracle的解析过程。
练习:在屏幕上显示如下字符串:
2015-05-11 16:17:06 今天是 星期一
SQL> select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss "今天是" day') from dual
在固定的格式里加入自定义的格式,是可以的,必须要加“”。
反向操作:已知字符串“2015-05-11 15:17:06 今天是 星期一”转化成日期。 to_date函数
SQL> select to_date('2015-05-11 15:17:06 今天是 星期一', 'yyyy-mm-dd hh24:mi:ss "今天是" day') from dual
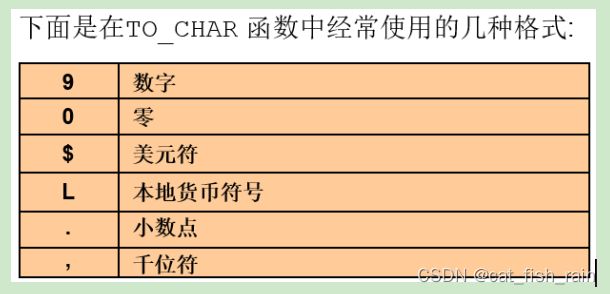
查询员工的薪水:2位小数, 本地货币代码, 千位符
SQL> select to_char(sal, 'L9,999.99') from emp 'L9,999.99'之间没有空格
将¥2,975.00转化成数字:
SQL> select to_number('¥2,975.00', 'L9,999.99') 转成数字 from dual
通用函数(了解)
这些函数适用于任何数据类型,同时也适用于空值:
- NVL (expr1, expr2)
- NVL2 (expr1, expr2, expr3)
- NULLIF (expr1, expr2)
- COALESCE (expr1, expr2, ..., exprn)
nvl2: 是nvl函数的增强版。 nvl2(a, b, c) 当a = null 返回 c, 否则返回b
使用nvl2求员工的年收入:
SQL> select empno, ename, sal, sal*12, sal * 12 + nvl2(comm, comm, 0) 年薪 from emp
nullif: nullif(a, b) 当 a = b 时返回null, 不相等的时候返回a值。
SQL> select nullif('L9,999.99', 'L9,999.99') from dual
coalesce: coalesce(a, b, c, …, n) 从左向右找参数中第一个不为空的值。
SQL> select comm, sal, coalesce(comm, sal) 结果值 from emp
条件表达式
例子:老板打算给员工涨工资, 要求:
总裁(PRESIDENT)涨1000,经理(MANAGER)涨800,其他人涨400. 请将涨前,涨后的薪水列出。
select ename, job, sal 涨前薪水, 涨后薪水 from emp 涨后的薪水是根据job来判断的
思路: if 是总裁('PRESIDENT') then +1000
else if 是经理('MANAGER') then +800
else +400
但是在SQL中无法实现if else 逻辑。当有这种需求的时候,可以使用case 或者 decode
case: 是一个表达式,其语法为:
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
SQL> select ename, job, sal 涨前薪水, case job when 'PRESIDENT' then sal+1000
when 'MANAGER' then sal+800
else sal + 400
end 涨后薪水
from emp
注意语法:when then 与下一个when then以及end之间没有“,”分割符。
decode:是一个函数,其语法为:
DECODE(col|expression, search1, result1
[, search2, result2,...,]
[, default])
除第一个和最后一个参数之外,中间的参数都是成对呈现的 (参1, 条件, 值, 条件, 值, …, 条件, 值, 尾参)
SQL> select ename, job, sal 涨前薪水, decode(job, 'PRESIDENT', sal + 1000,
'MANAGER', sal + 800,
sal + 400) as 涨后薪水
from emp