Go语言面试题
1.Go有哪些数据类型
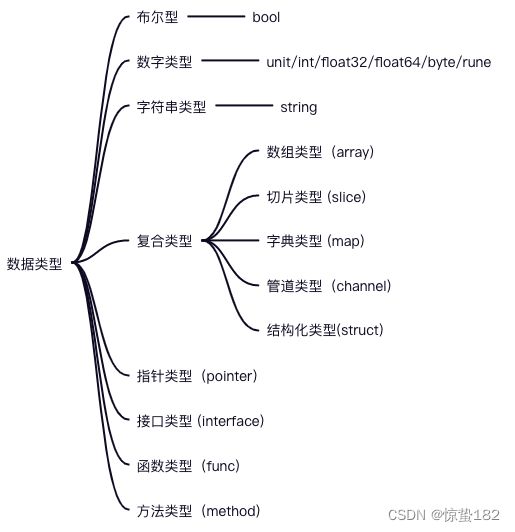 f
f
2.方法与函数的区别
在Go语言中,函数和方法不太一样,有明确的概念区分;函数是指不属于任何结构体、类型的方法,也就是说函数是没有接收者的;而方法是有接收者的。
3.方法值接收者和指针接收者的区别
如果方法的接收者是指针类型,无论调用者是对象还是对象指针,修改的都是对象本身,会影响调用者;
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;
4.函数返回局部变量的指针是否安全
一般来说,局部变量会在函数返回后被销毁,因此被返回的引用就成为了"无所指"的引用,程序会进入未知状态。
但这在 Go 中是安全的,Go 编译器将会对每个局部变量进行逃逸分析。如果发现局部变量的作用域超出该函数,则不会将内存分配在栈上,而是分配在堆上,因为他们不在栈区,即使释放函数,其内容也不会受影响。
5.函数参数传递是值传递还是引用传递
Go语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。
参数如果是非引用类型(int、string、struct等这些),这样就在函数中就无法修改原内容数据;如果是引用类型(指针、map、slice、chan等这些),这样就可以修改原内容数据。
6.defer关键字的实现原理
defer关键字的实现跟go关键字很类似,不同的是它调用的是runtime.deferproc而不是runtime.newproc。在defer出现的地方,插入了指令call runtime.deferproc,然后在函数返回之前的地方,插入指令call runtime.deferreturn。
7.内置函数make和new的区别
变量初始化,一般包括2步,变量声明 + 变量内存分配,var关键字就是用来声明变量的,new和make函数主要是用来分配内存的;
make 只能用来分配及初始化类型为slice、map、chan 的数据,并且返回类型本身。
new 可以分配任意类型的数据,并且置零,返回一个指向该类型内存地址的指针。
8.slice底层实现原理
切片是基于数组实现的,它的底层是数组,它自己本身非常小,可以理解为对 底层数组的抽象。因为基于数组实现,所以它的底层的内存是连续分配的,效 率非常高,还可以通过索引获得数据。
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用 底层数组,设定相关属性将数据读写操作限定在指定的区域内。切片本身是一 个只读对象,其工作机制类似数组指针的一种封装。
9.array和slice的区别
1)数组长度不同
数组初始化必须指定长度,并且长度就是固定的
切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
2)函数传参不同
数组是值类型,将一个数组赋值给另一个数组时,传递的是一份深拷贝,函数传参操作都会复制整个数组数据,会占用额外的内存,函数内对数组元素值的修改,不会修改原数组内容。
切片是引用类型,将一个切片赋值给另一个切片时,传递的是一份浅拷贝,函数传参操作不会拷贝整个切片,只会复制len和cap,底层共用同一个数组,不会占用额外的内存,函数内对数组元素值的修改,会修改原数组内容。
3)计算数组长度方式不同
数组需要遍历计算数组长度,时间复杂度为O(n)
切片底层包含len字段,可以通过len()计算切片长度,时间复杂度为O(1)
10.slice深拷贝和浅拷贝
深拷贝:拷贝的是数据本身,创造一个新对象,新创建的对象与原对象不共享内存,新创建的对象在内存中开辟一个新的内存地址,新对象值修改时不会影响原对象值
浅拷贝:拷贝的是数据地址,只复制指向的对象的指针,此时新对象和老对象指向的内存地址是一样的,新对象值修改时老对象也会变化
11.slice扩容机制
扩容会发生在slice append的时候,当slice的cap不足以容纳新元素,就会进行扩容,扩容规则如下:
如果新申请容量比两倍原有容量大,那么扩容后容量大小 为 新申请容量
如果原有 slice 长度小于 1024, 那么每次就扩容为原来的 2 倍
如果原 slice 长度大于等于 1024, 那么每次扩容就扩为原来的 1.25 倍
如果最终容量计算值溢出,则最终容量就是新申请容量
12.slice为什么不是线程安全的
slice底层结构并没有使用加锁等方式,不支持并发读写,所以并不是线程安全的,使用多个 goroutine 对类型为 slice 的变量进行操作,每次输出的值大概率都不会一样,与预期值不一致; slice在并发执行中不会报错,但是数据会丢失
13.map底层实现原理
Go中的map是一个指针,占用8个字节,指向hmap结构体
源码包中src/runtime/map.go定义了hmap的数据结构:
hmap包含若干个结构为bmap的数组,每个bmap底层都采用链表结构,bmap通常叫其bucket
14.map遍历为什么是无序的
主要原因有2点:
- map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历
- map遍历时,是按序遍历bucket,同时按需遍历bucket中和其overflow bucket中的cell。但是map在扩容后,会发生key的搬迁,这造成原来落在一个bucket中的key,搬迁后,有可能会落到其他bucket中了,从这个角度看,遍历map的结果就不可能是按照原来的顺序了
map 本身是无序的,且遍历时顺序还会被随机化,如果想顺序遍历 map,需要对 map key 先排序,再按照 key 的顺序遍历 map。
15.map为什么是非线程安全的
map默认是并发不安全的,同时对map进行并发读写时,程序会panic
16.map如何查找
Go 语言中读取 map 有两种语法:带 comma 和 不带 comma。当要查询的 key 不在 map 里,带 comma 的用法会返回一个 bool 型变量提示 key 是否在 map 中;而不带 comma 的语句则会返回一个 value 类型的零值。如果 value 是 int 型就会返回 0,如果 value 是 string 类型,就会返回空字符串。
// 不带 comma 用法
value := m["name"]
fmt.Printf("value:%s", value)
// 带 comma 用法
value, ok := m["name"]
if ok {
fmt.Printf("value:%s", value)
}
17.map冲突的解决方式
比较常用的Hash冲突解决方案有链地址法和开放寻址法:
链地址法
当哈希冲突发生时,创建新单元,并将新单元添加到冲突单元所在链表的尾部。
开放寻址法
当哈希冲突发生时,从发生冲突的那个单元起,按照一定的次序,从哈希表中寻找一个空闲的单元,然后把发生冲突的元素存入到该单元。开放寻址法需要的表长度要大于等于所需要存放的元素数量
18.什么是负载因子?map的负载因子为什么是6.5
负载因子(load factor),用于衡量当前哈希表中空间占用率的核心指标,也就是每个 bucket 桶存储的平均元素个数。
Go 官方发现:装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,装载因子越小,填入的元