在CentOS7上安装Hadoop分布式系统
- 项目背景:
Hadoop原来是Apache Lucene下的一个子项目,它最初是从Nutch项目中分离出来的专门负责分布式存储以及分布式运算的项目。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。Hadoop由分布式存储HDFS和分布式计算MapReduce两部分组成。HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说, Hadoop 通常是指一个更广泛的概念 —— Hadoop 生态圈 。
项目需求:
(1)功能需求:可以使用root用户搭建和管理hdfs。三台机器的防火墙必须是关闭的。确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置) ;确保/etc/hosts文件配置了ip和hostname的映射关系;确保配置了两台台机器;免密登陆认证(克隆会更加方便);确保所有机器时间同步;jdk和hadoop的环境变量配置。
(2)经济分析: 首先,Hadoop集群的确是一个高性价比的解决方案。其次,它所需的软件是开源的,这样就可以降低成本。可以自由下载Apache Hadoop发行版。最后,Hadoop集群通过支持商用硬件控制了成本。不必购买服务器级硬件,便可以搭建一个强大的Hadoop集群。
(3)通用性:Hadoop的工作原理在于将数据拆分成片,并将每个“分片”分配到特定的集群节点上进行分析。数据不必均匀分布,因为每个数据分片都是在独立的集群节点上进行单独处理的。
Hadoop集群的并行处理能力能明显提高分析速度,但随着要分析的数据量的增加,集群的处理能力可能会收到影响。可以通过添加额外的集群节点方式,来有效的扩展集群。
(4)安全性:不能损害集群的功能,架构一致,不能和Hadoop架构冲突,能够解决安全的威胁
软件架构:
WinSCP:开源图形化SFTP客户端,是一个Windows环境下使用SSH的开源图形化SFTP客户端。同时支持SCP协议。它的主要功能就是在本地与远程计算机间安全的复制文件。.winscp也可以链接其他系统,比如linux系统。
操作系统:win11;
虚拟软件:VMware
虚拟机系统:CentOS7
虚拟机:主机名:master IP:192.068.181.130
主机名:slave1 IP:192.168.181.131
软件包存储路径:/home/lq
JDK:使用Java1.8版本
Hadoop:hadoop -3.3.4
用户:root
使用技术
熟练掌握Linux指令,以及HDFS的结构模型管理数据。
项目实现
5.1 搭建集群前的准备工作:
·首先对传输过来的Hadoop文件解压生成如图的目录:

·安装ssh
yum install openssh*
安装成功:

启动ssh服务,查看状态
systemctl enable sshd
systemctl status sshd

验证ssh能否正常启动
ssh localhost

生成key
cd ~/
ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
cd .ssh
cat id_dsa.pub >>authorized_keys

在.ssh目录下查看key是否生成

·安装JDK
使用java1.8版本
yum -y install java-1.8.0-openjdk*
·找到java的安装路径
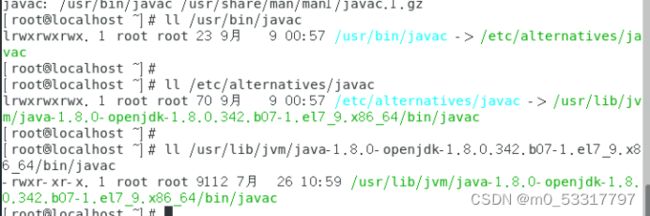
whereis javac

·Java真实路径:
ll /usr/bin/javac
ll /etc/alternatives/javac
ll /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64/bin/javac
·配置hadoop和java的环境
·打开hadoop-env.sh

在文件末尾输入一下内容进行环境配置:
HDFS_DATANODE_USER=root ‘
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
vim ~/.bashrc
在文本末尾添加以下内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64 export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH

运行文件:
source ~/.bashrc
·关闭防火墙以及seLinux
systemctl stop firewalld
setenforce 0

![]()
· 通过创建快照对现有主机进行拍照快照,通过快照克隆第二个虚拟机。
5.2搭建Hadoop分布式系统:
·修改主机名称:(两台主机均实现)
vim /etc/hostname
vim /etc/hosts
![]()
在主节点下将hostname的内容改为:master
在另一台主机下的hostname改为:slave1
修改网络映射:
所有的虚拟机都进行如下操作:
vim /etc/hosts
[master主机的IP] master
[slave1主机的IP] slave1
·配置hadoop在/usr/local/hadoop/etc/hadoop目录下:
配置core-site.xml:
fs.defaultFS hdfs://master:9000 hadoop.tmp.dir file:/usr/local/hadoop/tmp
配置 /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64 export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
配置hdfs-site.xml:
dfs.replication
2
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
配置mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
配置yarn-site.xml:
yarn.resoucemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
修改workers文件,添加以下内容:
master
slave1同步文件,利用scp指令实现将master节点的环境配置复制到slave1节点:
scp -r /usr/local/hadoop/etc/hadoop/workers root@slave1:/usr/local/hadoop/etc/hadoop/
scp -r /usr/local/hadoop/etc/hadoop/core-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp -r /usr/local/hadoop/etc/hadoop/hdfs-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp -r /usr/local/hadoop/etc/hadoop/mapred-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp -r /usr/local/hadoop/etc/hadoop/yarn-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp -r /etc/profile root@slave1:/etc/profile· 重启虚拟机
·格式化文件系统
hdfs namenode -format
 ·启动HDFS
·启动HDFS

·修改网络为静态
cd /etc/sysconfig/network-scripts/
vim ifcfg-ens33
将BOOTPROTO状态改为"static",在后续添加主机IP地址,网关地址,子网掩码,DNS1,DNS2
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="ad427e49-302c-4724-813f-d0f07cac5a5f"
DEVICE="ens33"
ONBOOT="yes"IPADDR=192.168.181.130
GATEWAY=192.168.181.2
NETMASK=255.255.255.0
DNS1=218.4.4.4
DNS2=8.8.8.8
在命令行格式下可以ping通即为,修改正常:

·通过浏览器查看:
在网址输入框内输入192.168.181.130:9870(我的主机IP+端口号)查看两个节点运行正常:
