批处理实验
week09
- 批处理实验
- 实验过程
-
- 1、Windows下批处理完成实验
-
- 1.1正常文件下:
- 1.2空文件下:
- 1.3大文件下:
- 2、Linux下的shell脚本实现
-
- 2.1 正常文件下:
- 2.2 空文件下:
- 2.2 大文件下:
批处理实验
有两个文本如下,实际中并不知道两文本各有多少行:
文本1.txt
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
ccccccccccccccccccccccccccccccccccccccc
eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
ggggggggggggggggggggggggggggggggggggggg
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
文本2.txt
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj
nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn
要求用Windows下批处理和Linux下的shell脚本完成,两文本交替输出:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
ccccccccccccccccccccccccccccccccccccccc
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj
ggggggggggggggggggggggggggggggggggggggg
nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
要求:
1 尽量不生成临时文件
2 代码要高效,代码尽量简洁
3 给出各种情况的测试结果截图(正常文件,巨大文件,一个空文件,两个空文件)
实验过程
1、Windows下批处理完成实验
1.1正常文件下:
在某文件夹(11月29)中放入文本1.txt和文本2.txt,并编写一个bat脚本实现Windows下批处理过程。

20232831.bat文件的代码如下:
@echo off
set "paths=1.txt"
if not exist "%paths%" (
echo "1.txt does not exist"
goto :eof
)
for %%a in ("%paths%") do (
if %%~za equ 0 (
echo "1.txt empty"
) else (
echo "1.txt not empty"
)
)
set "paths=2.txt"
if not exist "%paths%" (
echo "2.txt does not exist"
goto :eof
)
for %%a in ("%paths%") do (
if %%~za equ 0 (
echo "2.txt empty"
) else (
echo "2.txt not empty"
)
)
for /f "usebackq delims=" %%i in (1.txt) do echo %%i
for /f "usebackq delims=" %%i in (2.txt) do echo %%i
pause>nul
文本1和文本2的内容如下:
文本1.txt:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
ccccccccccccccccccccccccccccccccccccccc
eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
ggggggggggggggggggggggggggggggggggggggg
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
文本2.txt:
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj
nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn
运行结果如下:

1.2空文件下:
当某一txt文件为空或均为空时,结果如下:
二者空:

1空

2空

1.3大文件下:
当某一文件过于巨大时,输出如下(即不输出,代码存在问题):

检查并询问GPT发现,应该使用新方法实现(不再使用 call 和动态变量名称,而是直接输出文件的内容。):
代码修改如下:
@echo off
set "paths=1.txt"
if not exist "%paths%" (
echo "1.txt does not exist"
goto :eof
)
for %%a in ("%paths%") do (
if %%~za equ 0 (
echo "1.txt empty"
) else (
echo "1.txt not empty"
)
)
set "paths=2.txt"
if not exist "%paths%" (
echo "2.txt does not exist"
goto :eof
)
for %%a in ("%paths%") do (
if %%~za equ 0 (
echo "2.txt empty"
) else (
echo "2.txt not empty"
)
)
for /f "usebackq delims=" %%i in (1.txt) do echo %%i
for /f "usebackq delims=" %%i in (2.txt) do echo %%i
pause>nul
输出如下:(融合输出后全部输出1.txt的剩余内容)

2、Linux下的shell脚本实现
2.1 正常文件下:
文本1和文本2的内容如下:
文本1.txt:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
ccccccccccccccccccccccccccccccccccccccc
eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
ggggggggggggggggggggggggggggggggggggggg
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
文本2.txt:
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj
nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn
20232831.sh文件代码如下:
#! /bin/bash
#
# 输出文件的某一行
# 参数1:文件名
# 参数2:输出行数
function printLine() {
pri=`cat $1 | head -n$2 | tail -1f`
#字符串长度是否为0,不为0输出
if [ -n "${pri}" ]
then
echo ${pri}
fi
}
file1=./1.txt
file2=./2.txt
# 比较两个文件行数大小,记录文件行数大的文件
max=
min=
moreTxt=
if [ ${m} -gt ${n} ]
then
max=${m}
min=${n}
moreTxt="${file1}"
else
max=${m}
min=${n}
moreTxt="${file2}"
fi
i=1
while (( i <= ${min} ))
do
printLine ${file1} ${i}
printLine ${file2} ${i}
let i++
done
#输出文件大的行数
while (( i <= ${max} ))
do
printLine ${moreTxt} ${i}
let i++
done
运行过程中,还发现没有.sh文件的权限,因此使用chmod +x 20232831.sh为其添加执行权限。
运行结果如下:

2.2 空文件下:
当文件存在空文件时,运行结果如下(任一空和两个都空):
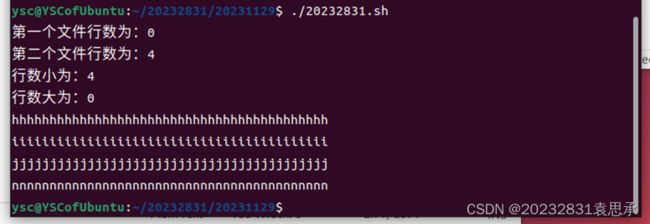


2.2 大文件下:
当1.txt文件巨大,如下所示,共4万余行文本:
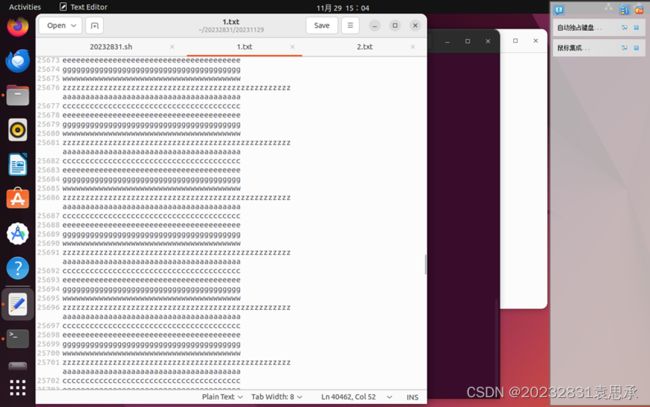
运行结果如下:(即在融合输出后继续输出1.txt的文件内容,与Windows中一致)

完成!