Linux内核学习笔记
- 进程管理
- 1.1. 进程
- 1.2. 进程描述符
- 1.3. 进程的状态
- 1.4. 线程描述符
- 1.5. 内核中双向列表的实现
- 1.6. 进程的标识和定位
- 1.7. 进程组织
- 1.7.1. 等待队列
- 1.7.2. 等待队列的操作
- 1.7.3. 进程资源限制
- 1.8. 进程切换
- 1.8.1. 进程上下文和硬件上下文
- 1.8.2. 任务状态段
- 1.8.3. 执行进程切换
- 1.9. 进程创建
- 1.9.1. 写时拷贝
- 1.9.2. fork()
- 1.9.3. 线程
- 1.9.4. 内核线程
- 1.10. 进程终结
最近在学Linux内核的知识,主要通过看《Linux内核设计与实现》和《深入理解Linux内核》这两本书,学习过程中感受到自己需要一种最直观但又深入的方式来展示这些知识,于是想吧自己的学到的东西用自己觉得最好的方式展示出来,加深自己的理解。
1. 进程管理
1.1. 进程
进程是处于执行期的程序以及相关资源的总称,注意包含了两个方面:
- 程序代码;
- 资源。比如说打开的文件,挂起的信号,内核内部数据,处理器状态,一个或多个具有内存映射的内存地址空间,一个或多个执行线程,存放全局变量的数据段等;
1.2. 进程描述符
进程的所有信息存放在一个叫做“进程描述符”(process descriptor)的struct中,结构名叫做task_struct,该结构定义在
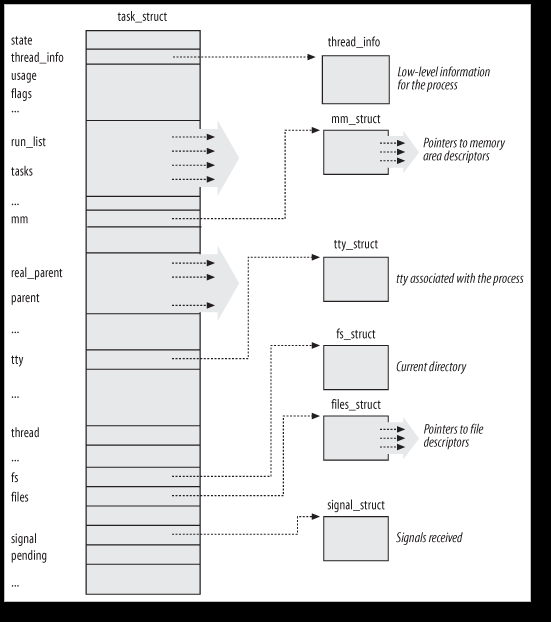
1.3. 进程的状态
task_struct中的state字段描述了该进程当前所处的状态,进程可能的状态必然是下面5种当中的一种:
- TASK_RUNNING(运行) -- 进程正在执行,或者在运行队列中等待执行。这是进程在用户空间中唯一可能的状态。
- TASK_INTERRUPTIBLE(可中断) -- 进程正在睡眠(阻塞),等待某些条件的达成。一个硬件中断的产生、释放进程正在等待的系统资源、传递一个信号等都可以作为条件唤醒进程。
- TASK_UNINTERRUPTIBLE(不可中断) -- 与可中断状态类似,除了就算是收到信号也不会被唤醒或准备投入运行,对信号不做响应。这个状态通常在进程必须在等待时不受干扰或等待事件很快就会发生时出现。例如,当进程打开一个设备文件,相应的设备驱动程序需要探测某个硬件设备,此时进程就会处于这个状态,确保在探测完成前,设备驱动程序不会被中断。
- __TASK_TRACED -- 被其它进程跟踪的进程,比如ptrace对程序进行跟踪。
- __TASK_STOPPED -- 进程停止执行。通常这种状态发生在接收到SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU等信号的时候。此外,在调试期间接收到任何信号,都会使进程进入这种状态。
可以通过set_task_state()函数来改变一个进程的状态:`set_task_state(task, state);`
1.4. 线程描述符
与task_struct结构相关的一个小数据结构是thread_info(线程描述符)。对于每一个进程,内核把它内核态的进程堆栈和进程对应的thread_info这两个数据结构紧凑地存放在一个单独为进程分配的存储区域内。X86上,struct_info在文件
struct thread_info {
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
int preempt_count; /* 0 => preemptable,
<0 => BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* ESP of the previous stack in
case of nested (IRQ) stacks */
__u8 supervisor_stack[0];
#endif
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};
内核用一个thread_union来方便地表示一个进程的thread_info和内核栈:(
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
thread_info和进程的内核态堆栈在内存中的存放方式如下图:
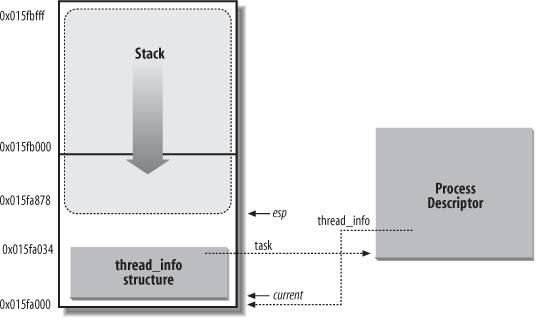
图中,esp寄存器是CPU栈指针,用来存放栈顶单元的地址。两者紧密结合起来存放的主要好处是:内核很容易从esp寄存器的值获得当前在CPU上正在运行的进程的thread_info的地址(例如,如果thread_union结构长度为2^13字节即8K,那么只要屏蔽掉esp的低13位即可得到对应的thread_info的基址),继而可以得到该进程的task_struct的地址。对于像x86那样寄存器较少的硬件体系结构,只要通过栈指针就能得到当前进程的task_struct结构,避免了使用额外的寄存器专门记录。(对于PowerPC结构,它有一个专门的寄存器保存当前进程的task_struct地址,需要时直接取用即可。)
内核中大部分处理进程的代码都是直接通过task_struct进行的,可以通过current宏查找到当前正在运行进程的task_struct。硬件体系不同,该宏的实现不同,它必须针对专门的影印件体系结构做处理。想PowerPC可以直接去取寄存器的值,对于x86,则在内核栈的尾端创建thread_info结构,通过计算偏移间接地查找task_struct结构,比如上面说的“那么只要屏蔽掉esp的低13位”。
1.5. 内核中双向列表的实现
我们知道进程描述符是放在双向链表中的。为了理解内核中双向链表的实现,我们先来了解一下list_head数据结构:(
struct list_head {
struct list_head *next, *prev;
};
一个双向链表的元素包含一个类型为list_head的变量,list_head结构里面,next和prev分别表示通用双向列表向前和向后的指针元素。需要注意的是,next和prev所指向的是另一个list_head结构的地址,而非这个链表元素的地址。(要得到这个链表元素的地址,可以用list_entry()宏来得到,具体见下面)
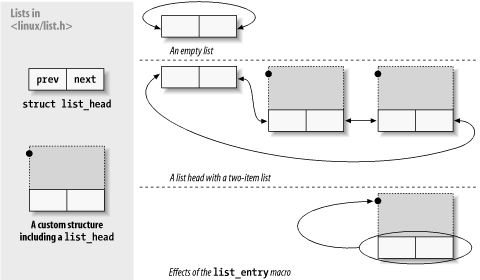
对包含了list_head的双向列表,有以下的处理函数和宏:
- list_add(n, p)
把n指向的元素插入p指向的元素之后 - list_add_tail(n, p)
把n指向的元素插入p指向的元素之前 - list_del(p)
删除p所指向的元素 - list_empty(p)
检查p指向的链表是否为空 - list_entry(p, t, m)
返回类型为t的数据结构的地址,其中类型t中含有list_head字段,且list_head字段的地址为p,名字为m。也就是在链表中找到一个元素,这个元素的类型为t,这个元素里面包含了类型为list_head的名称为m的属性。 - list_for_each(p, h)
对表头地址h指定的链表进行扫描,在每次循环时,通过p返回指向链表元素的list_head结构的指针。 - list_for_each_entry(p, h, m)
与list_for_each类似,只是返回的是链表元素的指针,也就是包含了地址为p的名称为m的list_head的元素的指针,而不是list_head结构本身的地址。
作为一个例子,我们来看看list_entry宏是怎么实现的^_^ 在SRC/include/linux/list.h中有如下宏:
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
container_of宏则在SRC/drivers/staging/rtl8192e/rtllib.h:
#ifndef container_of
/**
* container_of - cast a member of a structure out to the containing structure
*
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
#endif
看起来很有意思,我们仔细分析一下上面的这一段宏。
- ((type *)0)
把0强制转换为type类型的指针,它指向一个空的type类型 - ((type *)0)->member)*__mptr = (ptr);
从上面得到的空的type类型得到类型中名称为member的一项,把ptr强制转换为member的类型的指针,赋值给变量__mptr - offsetof(type, member)
宏得到的是在类型type的内存结构中,名称为member的一个属性相对预type的基地址的偏移量。offsetof的宏定义在SRC/include/linux/stddef.h中:#undef offsetof #ifdef __compiler_offsetof #define offsetof(TYPE,MEMBER) __compiler_offsetof(TYPE,MEMBER) #else #define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) #endif
还是同样的方法,把0强制转换为TYPE类型的指针,找到这个指针代表的TYPE元素的MEMBER属性,得到它的地址,由于是由0强制转换而来,所以这个地址就是MEMBER属性相对与TYPE结构在内存中的偏移地址。再把这个偏移地址转换为size_t类型。所谓size_t类型,也就是用sizeof函数返回值的类型,也就是用char来衡量的一个数据结构的大小的值。 - (type *)((char *)__mptr - offsetof(type, member))
把之前赋值好的__mptr强制转换为char指针类型,这样可以和offsetof得到的偏移值做减法,由member的地址减去member相对于type的偏移值,得到的就是type的地址了。最后再把这个地址转换为type类型的指针。这样我们就得到了"container"的指针。 事实上这里还涉及到字节对齐的问题。比如说struct S1 { char c; int i; }; S1 s1;我们可能会想,char占1字节,int占4字节,那么sizeof(s1)等于5字节么?不是的,事实上sizeof(s1)等于8字节。这就是所谓的“字节对齐”,之所以要字节对齐是因为这样有助于加快计算机的取数速度。编译器默认会让宽度为2的基本数据类型(short等)都位于能被2整除的地址上,让宽度为4的基本数据类型(int等)都位于等被4整除的地址上,以此类推。这样,两个数中间就可能需要加入填充字节。 字节对齐的细节和编译器实现相关,但一般而言,满足三个准则:- 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
- 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
- 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
基本类型是指前面提到的像char、short、int、float、double这样的内置数据类型,这里所说的“数据宽度”就是指其sizeof的大小。由于结构体的成员可以是复合类型,比如另外一个结构体,所以在寻找最宽基本类型成员时,应当包括复合类型成员的子成员,而不是把复合成员看成是一个整体。但在确定复合类型成员的偏移位置时则是将复合类型作为整体看待。比如有:struct S3 { char c1; S1 s; char c2 };S1的最宽简单成员的类型为int,S3在考虑最宽简单类型成员时是将S1“打散”看的,所以S3的最宽简单类型为int,这样,通过S3定义的变量,其存储空间首地址需要被4整除,整个sizeof(S3)的值也应该被4整除。 (更多关于内核中链表的知识,参考:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/index.html)
1.6. 进程的标识和定位
内核通过PID来唯一地标识每一个进程。PID有个默认的最大值,一般是32768,这个值在`#define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000)` 也可以通过修改/proc/sys/kernel/pid_max的值来提高上限。
为了能高效地从PID导出对应的进程描述符指针(而不是顺序扫描链表),内核引入了4个散列表。(是4个的原因是由于进程描述符中包含了4个不同类型的PID的字段,每种类型的PID需要自己的散列表):
| Hash表的类型 | 字段名 | 说明 |
| PIDTYPE_PID | pid | 进程的PID |
| PIDTYPE_TGID | tgid | 线程组领头进程的PID |
| PIDTYPE_PGID | pgrp | 进程组领头进程的PID |
| PIDTYPE_SID | session | 会话领头进程的PID |
在最新的task_struct结构中:pid和tgid直接是这个struct的成员:
pid_t pid; pid_t tgid;
而pgrp和session是通过下面这两个函数取得的:
static inline struct pid *task_pgrp(struct task_struct *task)
{
return task->group_leader->pids[PIDTYPE_PGID].pid;
}
static inline struct pid *task_session(struct task_struct *task)
{
return task->group_leader->pids[PIDTYPE_SID].pid;
}
而group_leader在task_struct中定义如下:
struct task_struct *group_leader; /* threadgroup leader */
内核初始化期间动态地为4个三列表分配空间,并把它们的地址存入pid_hash数组。
内核用pid_hashfn宏把PID转换为表索引(kernel/pid.c):
#define pid_hashfn(nr, ns) \
hash_long((unsigned long)nr + (unsigned long)ns, pidhash_shift)
其中hash_long在
/* 2^31 + 2^29 - 2^25 + 2^22 - 2^19 - 2^16 + 1 */
#define GOLDEN_RATIO_PRIME_32 0x9e370001UL
/* 2^63 + 2^61 - 2^57 + 2^54 - 2^51 - 2^18 + 1 */
#define GOLDEN_RATIO_PRIME_64 0x9e37fffffffc0001UL
#if BITS_PER_LONG == 32
#define GOLDEN_RATIO_PRIME GOLDEN_RATIO_PRIME_32
#define hash_long(val, bits) hash_32(val, bits)
#elif BITS_PER_LONG == 64
#define hash_long(val, bits) hash_64(val, bits)
#define GOLDEN_RATIO_PRIME GOLDEN_RATIO_PRIME_64
#else
#error Wordsize not 32 or 64
#endif
static inline u64 hash_64(u64 val, unsigned int bits)
{
u64 hash = val;
/* Sigh, gcc can't optimise this alone like it does for 32 bits. */
u64 n = hash;
n <<= 18;
hash -= n;
n <<= 33;
hash -= n;
n <<= 3;
hash += n;
n <<= 3;
hash -= n;
n <<= 4;
hash += n;
n <<= 2;
hash += n;
/* High bits are more random, so use them. */
return hash >> (64 - bits);
}
static inline u32 hash_32(u32 val, unsigned int bits)
{
/* On some cpus multiply is faster, on others gcc will do shifts */
u32 hash = val * GOLDEN_RATIO_PRIME_32;
/* High bits are more random, so use them. */
return hash >> (32 - bits);
}
static inline unsigned long hash_ptr(const void *ptr, unsigned int bits)
{
return hash_long((unsigned long)ptr, bits);
}
#endif /* _LINUX_HASH_H */
上面的函数很有趣,我们来仔细看一下。
首先,hash的方式是,让key乘以一个大数,于是结果溢出,就把留在32/64位变量中的值作为hash值,又由于散列表的索引长度有限,我们就取这hash值的高几为作为索引值,之所以取高几位,是因为高位的数更具有随机性,能够减少所谓“冲突”。什么是冲突呢?从上面的算法来看,key和hash值并不是一一对应的。有可能两个key算出来得到同一个hash值,这就称为“冲突”。
那么,乘以的这个大数应该是多少呢?从上面的代码来看,32位系统中这个数是0x9e370001UL,64位系统中这个数是0x9e37fffffffc0001UL。这个数是怎么得到的呢?“Knuth建议,要得到满意的结果,对于32位机器,2^32做黄金分割,这个大树是最接近黄金分割点的素数,0x9e370001UL就是接近 2^32*(sqrt(5)-1)/2 的一个素数,且这个数可以很方便地通过加运算和位移运算得到,因为它等于2^31 + 2^29 - 2^25 + 2^22 - 2^19 - 2^16 + 1。对于64位系统,这个数是0x9e37fffffffc0001UL,同样有2^63 + 2^61 - 2^57 + 2^54 - 2^51 - 2^18 + 1。
从程序中可以看到,对于32位系统计算hash值是直接用的乘法,而对于64位系统,gcc似乎没有类似的优化,所以用的是位移运算和加运算来计算。首先n=hash, 然后n左移18位,hash-=n,这样hash = hash * (1 - 2^18),下一项是-2^51,而n之前已经左移过18位了,所以只需要再左移33位,于是有n <<= 33,依次类推,最终算出了hash值。
现在我们已经可以通过pid_hashfn把PID转换为一个index了,接下来我们再来想一想其中的问题。首先,由上面介绍的算法我们可以看出,不同的PID/TGID/PGRP/SESSION的ID(没做特殊声明前一般用PID作为代表),有可能会对应到相同的hash表索引,也就是冲突(colliding)。内核用双链表来存储一个索引对于的进程描述符,另外,我们知道同一个线程组中的进程具有同一个TGID。这样,对于一个TGID值,其对应的进程可能是好多个。为了解决这些问题,内核把hash表指向了一个进程的链表。具体指向的是task_struct结构中pids数组的对于PID类型的一项当中的pid_chain结构,类型是hlist_node。下面我们看一个基于TGID的例子,pid_hash数组中的第二项存了这个hash表,hash表的地71个元素对应了一个进程链表,tgid=4351和246的进程在这个链表中,hash表指向。但是tgid=4351的进程可能有多个,于是通过类型为list_head的pid_list链接到下一个具有同样tgid的进程。也就是说,具有同一个pid(可能是4种类型中的一种)的进程们只有一个能存在于hash表中。
下面的图片说明了hash和进程链表的关系:
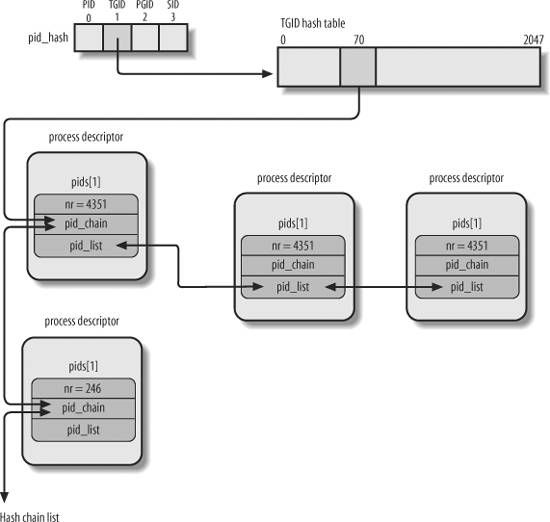
上图中,TGID=4351和TGID=246的两个进程对应到了同一个索引。
task_struct中有个叫pids的成员,相关的代码和介绍如下:
/* 在/linux-2.6.11/include/linux/sched.h中 */
struct task_struct {
... ...
/* PID/PID hash table linkage. */
struct pid pids[PIDTYPE_MAX];
... ...
};
... ...
/* 在/linux-2.6.11/include/linux/pid.h中 */
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_TGID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX /* PIDTYPE_MAX表示pid所表示的类型的最大数 */
};
struct pid
{
/* Try to keep pid_chain in the same cacheline as nr for find_pid */
int nr;
struct hlist_node pid_chain;
/* list of pids with the same nr, only one of them is in the hash */
struct list_head pid_list;
};
(注意:上面的情况只适用于版本2.6.11)
对于内核,线程只是共享了一些资源的进程,也用进程描述符来描述。getpid(获取进程ID)系统调用返回的也是tast_struct中的tgid, 而tast_struct中的pid则由gettid系统调用来返回。在执行ps命令的时候不展现子线程,也是有一些问题的。比如程序a.out运行时,创建 了一个线程。假设主线程的pid是10001、子线程是10002(它们的tgid都是10001)。这时如果你kill 10002,是可以把10001和10002这两个线程一起杀死的,尽管执行ps命令的时候根本看不到10002这个进程。如果你不知道linux线程背后的故事,肯定会觉得遇到灵异事件了。
下面是处理PID散列表的函数和宏:
- do_each_task_pid(nr, type, task) while_each_task_pid(na, type, task)
循环作用在PID值等于nr的PID链表上,链表的类型由参数type给出,task指向当前被扫描的元素的进程描述符。
- find_task_by_pid_type(type, nr)
在type类型的散列表中查找PID等于nr的进程。
- find_tsk_by_pid(nr)
同find_task_by_pid_type(PIDTYPE_PID, nr)
- attach_pid(task, type, nr)
把task指向的PID等于nr的进程描述符插入type类型的散列表中。
- detach_pid(task, type)
从type类型的PID进程链表中删除task所指向的进程描述符。
- next_thread(task)
返回PIDTYPE_TGID类型的散列表链表中task指示的下一个进程。
1.7. 进程组织
1.7.1. 等待队列
进程往往需要等待某个事件的发生才能继续进行下去,可能是需要等待一个磁盘操作的终止,等待释放系统资源,或者等待时间经过一个固定的间隔等等。内核通过等待队列来实现这方面的功能,希望等待特定事件的进程把自己放进合适的等待队列,并放弃控制权。所以,等待队列表示一组睡眠的进程,当某一条件变为真时,由内核唤醒它们。
等待队列由双向链表实现,每一个等待队列都有一个等待队列头(wait queue head), 其类型是名为wait_queue_head_t的数据结构:
/**/ struct __wait_queue_head { spinlock_t lock; /* 自旋锁 */ struct list_head task_list; /* 指向链表 */ }; typedef struct __wait_queue_head wait_queue_head_t;
由于等待队列是由中断处理程序和主要内核函数修改的,所以必须对链表进行保护,防止它被同时访问,这样的同步是通过wait_queue_head结构中的lock自旋锁实现的。task_list是等待进程链表的头。
等待队列链表中元素的类型为wait_queue_t:
/* linux/wait.h> */
typedef struct __wait_queue wait_queue_t;
struct __wait_queue {
unsigned int flags;
#define WQ_FLAG_EXCLUSIVE 0x01
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
等待队列链表中的元素代表一个睡眠的进程。在wait_queue_t结构中,这个进程的进程描述符的地址存放在private字段中。
有的时候,如果有两个或者多个进程等待互斥访问某一要释放的资源,这时候,就只需要唤醒其中的一个进程,不然全部唤醒的话,它们又会去抢着用那个资源,最后的结果是只有一个进程抢到,其它进程又要去睡觉,白白醒来一次耗费资源。为了解决这样的问题,内核把睡眠进程分为两种:互斥进程(等待队列元素中flags字段为1)和非互斥进程(flags字段为0),互斥进程由内核有选择地唤醒,而非互斥进程则由内核一次全部唤醒。
wait_queue_t中,func字段标识等待队列中的睡眠进程应该用什么方式来唤醒。
1.7.2. 等待队列的操作
- DECLARE_WAIT_QUEUE_HEAD(name)宏定义一个新等待队列的头,它静态地声明一个叫name的等待队列的头变量并对该变量的lock和task_list字段进行初始化。
- init_waitqueue_head()宏函数初始话动态分配的等待队列的头变量。
- init_waitqueue_entry(q, p)函数初始化wait_queue_t结构的变量q:
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p) { q->flags = 0; q->private = p; q->func = default_wake_function; } int default_wake_function(wait_queue_t *wait, unsigned mode, int flags, void *key);default_wake_function是唤醒非互斥的进程的函数。 - prepare_to_wait() 和 prepare_to_wait_exclusive()宏把一个进程加入到一个等待队列中去,让它睡眠。
- wait_event() 和wait_event_interruptible()宏用来把一个进程加入到等待队列中去,知道某个条件成立。 我们可以看一下wait_event()宏的定义:
/** * wait_event - sleep until a condition gets true * @wq: the waitqueue to wait on * @condition: a C expression for the event to wait for * * The process is put to sleep (TASK_UNINTERRUPTIBLE) until the * @condition evaluates to true. The @condition is checked each time * the waitqueue @wq is woken up. * * wake_up() has to be called after changing any variable that could * change the result of the wait condition. */ #define wait_event(wq, condition) \ do { \ if (condition) \ break; \ __wait_event(wq, condition); \ } while (0) #define __wait_event_timeout(wq, condition, ret) \ do { \ DEFINE_WAIT(__wait); \ \ for (;;) { \ prepare_to_wait(&wq, &__wait, TASK_UNINTERRUPTIBLE); \ if (condition) \ break; \ ret = schedule_timeout(ret); \ if (!ret) \ break; \ } \ finish_wait(&wq, &__wait); \ } while (0)
1.7.3. 进程资源限制
每个进程都有一组相关的资源限制(recource limit),限制了进程能够使用的系统资源的数量。
对当前进程的资源限制放在current->signal-rlim字段:
/* RLIM_NLIMITS 标识不通的资源项 */ struct rlimit rlim[RLIM_NLIMITS];
rlim是struct rlimit的数据结构,该结构定义在
struct rlimit {
unsigned long rlim_cur; /* 当前使用的值 */
unsigned long rlim_max; /* 最大可使用的值 */
};
1.8. 进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。
1.8.1. 进程上下文和硬件上下文
一般的程序在用户空间执行,当一个程序执行了系统调用或者出发了某个异常,它就陷入了内核空间。此时,我们称内核“代表进程执行”并处于进程上下文中。在此上下文中current宏是有效的。除非在此间隙有更高优先级的进程需要执行并由调度器做出了相应调整,否则在内核退出的时候,程序恢复在用户空间继续执行。
每个进程可以拥有自己的地址空间,但所有进程必须共享CPU寄存器。所以,在恢复一个进程执行之前,必须确保每个寄存器装入了挂起进程时的值。这组必须装入寄存器的数据就称为硬件上下文(hardware context)。
1.8.2. 任务状态段
TSS 全称task state segment,是指在操作系统进程管理的过程中,任务(进程)切换时的任务现场信息。内核为每个CPU创建一个TSS。每个TSS有它自己的8字节的任务状态段描述符(Task State Segment Descriptor, TSSD)。
TSS在任务切换过程中起着重要作用,通过它实现任务的挂起和恢复。在任务切换过程中,首先,处理器中各寄存器的当前值被自动保存到TR(任务寄存器)所指向的TSSD代表的TSS中,然后,下一任务的TSS的TSSD被装入TR;最后,从TR所指定的TSSD代表的TSS中取出各寄存器的值送到处理器的各寄存器中。由此可见,通过在TSS中保存任务现场各寄存器状态的完整映象,实现任务的切换。Linux创建的TSSD存放在全局描述符表(GDT)中,GDT的基地址存放在每个CPU的gdtr寄存器中。每个CPU的tr寄存器包含相应TSS的TSSD选择符,事实上还存了两个隐藏的非编程字段:TSSD的Base字段(指向对应的TSS的地址)和Limit字段,这样CPU就可以直接对TSS寻址而不用从GDT中检索TSS的地址。
在每次进程切换时,被替换进程的硬件上下文必须保存在某个地方,这个地方就是进程描述符的类型为thread_struct的thread字段:
/**/ struct task_struct { ... /* CPU-specific state of this task */ struct thread_struct thread; ... }
这个数据结构包含的字段涉及大部分CPU寄存器,但不包括诸如eax、ebx等等这些通用寄存器,它们的值保留在内核堆栈中。
1.8.3. 执行进程切换
本质上说,每个进程切换由两步组成:
- 切换页全局目录以安装一个新的地址空间;
- 切换内核态堆栈和硬件上下文。
第一个步骤我们暂时不讨论,我们先来简单看看第二步的具体过程。这个过程由switch_to宏执行,该宏有3个参数:prev,next和last,prev表示当前的进程描述符,next表示准备切换到的进程的进程描述符,last表示这次切换发生后eax寄存器的值所存的地方(注意,在进程切换时,eax、ebx等等这些通用寄存器的值是不变的)。last有什么意义呢?我们看一个例子:进程A切换到进程B,再切换到C进程,最后又从进程C切换回进程A。切换回A后,寄存器和thread字段的值都是当初冻结A时的值,也就是prev=A,next=B,这样我们就找不到C了,而找到C在进程调度的过程中很有用,我们需要有个地方来存当前进程到底是从哪个进程切换过来的,这就是last的作用。具体过程如下(由switch_to宏执行): - 把当前进程A的prev的值存入eax寄存器,eax=A;
- 进程切换到B,prev=B,把eax的值读入到last,last=A;
- 此时需要切换到进程C,把prev的值存到eax,eax=B;
- 进程切换到C,prev=C,把eax的值读入到last,last=B;
- 此时需要切换回进程A,把prev的值存入eax,eax=C;
- 切换到进程A,prev=A,把eax的值读入last,last=C; 这样在进程A中,通过last就可以直达它是从哪个进程切换过来的。
进程切换示例图: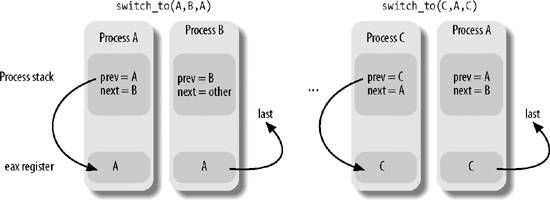
具体的切换由一系列的各种寄存器的值的切换组成,在此我们不做深入研究。
1.9. 进程创建
Linux非常依赖进程创建来满足用户的需求,比如在shell中输入一条命令,shell进程就生成一个新进程,新进程执行shell的另一个拷贝。
Linux中,进程的创建分为两个过程:fork()和exec()。fork()通过拷贝当前进程创建一个子进程。子进程与父进程的区别仅仅在于PID,PPID(父进程的进程号)和某些资源和统计量(如挂起的信号,它没有必要被继承)。exec()复杂读取可执行文件并将其载入地址空间开始运行。
1.9.1. 写时拷贝
Linux的fork()使用“写时拷贝”(copy-on-write)来实现,这是一种可以推迟甚至免除拷贝数据的技术。也就是说,内核此时并不赋值整个进程地址空间,而是让父进程和子进程共享同一个拷贝。只有在需要写入时,数据才会被复制,从而使各个进程拥有各自的拷贝,在此之前,只是以只读的方式共享。在页根本不会被写入的情况下(比如fork()之后立即调用exec())它们就无需复制了。
1.9.2. fork()
- fork()
Linux通过clone()系统调用实现fork()。这个调用通过一系列的参数标志来指明父、子进程需要共享的资源。fork(), vfork(), __clone()库函数都根据各自需要的参数标志去调用clone(), 然后由clone()去调用do_fork().
clone()参数的标志如下:
| 参数标志 | 含义 |
| CLONE_FILES | 父子进程共享打开的文件 |
| CLONE_FS | 父子进程共享文件系统信息 |
| CLONE_IDLETASK | 将PID设置为0(只供idle进程使用)TODO |
| CONE_NEWNS | 为子进程创建新的命名空间(即它自己的已挂载文件系统视图),不能同时设置CLONE_FS和CLONE_NEWNS |
| CLONE_PARENT | 指定子进程鱼父进程拥有同一个父进程。即设置子进程的父进程(进程描述符中的parent和real_parent字段)为调用进程的父进程 |
| CLONE_PTRACE | 继续调试子进程。如果父进程被跟踪,则子进程也被跟踪 |
| CLONE_SETTID | 将TID回写致用户空间。TODO |
| CLONE_SETTLS | 为子进程创建新的TLS |
| CLONE_SIGHAND | 父子进程共享信号处理函数及被阻断的信号 |
| CLONE_SYSVSEM | 父子进程共享SYstem V SEM_UNDO 语义。TODO |
| CLONE_THREAD | 父子进程放入相同的线程组 |
| CLONE_VFOK | 调用vfork(),所以父进程准备睡眠等待子进程将其唤醒 |
| CLONE_UNTRACED | 防止跟踪进程在子进程上强制执行CLONE_PTRACE,即使CLONE_PTRACE标志失去作用 |
| CLONE_STOP | 以TASK_STOPED状态开始进程 |
| CLONE_CHILD_CLEARTID | 清除子进程的TID TODO |
| CLONE_CHILD_SETTID | 设置子进程的TID |
| CLONE_PARENT_SETTID | 设置父进程的TID |
| CLONE_VM | 父子进程共享地址空间 |
负责创建进程的函数的层次结构
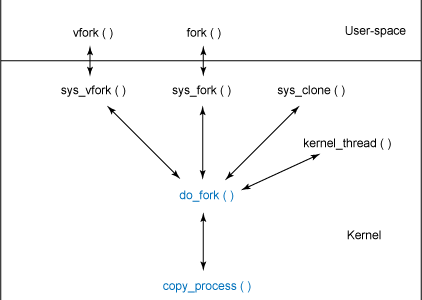
让我们看看do_fork主要内容如下:
做一些权限和用户态命名空间的检查(TODO), 调用copy_process函数得到新进程的进程描述符,如果copy_process返回成功,则唤醒新进程并让其投入运行。内核有意选择子进程首先执行。因为一般子进程会马上调用exec()函数,这样可以避免写时拷贝的额外开销。现在我们再来看一看copy_process()函数到底做了些什么:
copy_process()创建子进程的进程描述符以及执行它所需要的所有其它内核数据结构,但并不真的执行子进程:
- 检查参数clone_flags所传递标志的一致性。标志必须遵守一定的规则,不符合这些规则的话它就返回错误代号。
- 调用security_task_create()以及稍后调用的security_task_alloc()执行所有附加的安全检查。
- 调用dup_task_struct()为新进程创建一个内核栈、thread_info结构和task_struct, 这些值与当前进程的值相同。此时,子进程和父进程的进程描述符是完全相同的。dup_task_struct()的工作如下:
- prepare_to_copy(), 如果有需要,把一些寄存器(FPU)2的内容保存到父进程的thread_info结构中,稍后,这些值会复制到子进程的thread_info结构中;
- tsk = alloc_task_struct();获得task_struct结构,ti = alloc_thread_info();获得task_info结构, 把父进程的值考到新的结构中,并把tsk和ti链接上:tsk->thread_info = ti;ti->task = tsk;
- 把新进程描述符的使用计数器(tsk->usage)置为2,用来表示进程描述符正在被使用而且其相应的进程处于活动状态。
- 返回tsk.
- 检查并确保新创建这个子进程后,当前用户所拥有的进程数目没有超出给它分配的资源的限制。
- 检查系统中的进程数量是否超过max_threads变量的值。系统管理员可以通过写/proc/sys/kernel/threads-max文件来改变这个值。
- 新进程着手使自己与父进程区别开来。进程描述符内的许多成员都要被清0或设为初始值。那些不是从父进程继承而来的成员,主要是些统计信息,大部分的数据依然未被修改。 + 根据传递给clone()的参数标志,copy_process()拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等。一般情况下,这些资源是会在给定进程的所有线程之间共享的,不能共享的资源则拷贝到新进程里面去。
- 调用sched_fork()函数,把子进程状态设置为TASK_RUNNING,并完成一些进程调度需要的初始化。
- 根据clone_flags做一些进程亲子关系的初始化,比如clone_flags中有CLONE_PARENT|CLONE_THREAD,则把子进程的real_parent的值等于父进程的real_parent的值。
- 根据flags对是否需要跟踪子进程做一些初始化;
- 执行SET_LINKS()宏把新进程描述符插入进程链表,SET_LINKS宏定义在
中。 - 判断子进程是否要被跟踪,做一些设置。
- 调用attch_pid()把新进程描述符插入到pidhash[PIDTYPE_PID]散列表。
- 做一些扫尾工作,修改一些计数器的值,并返回新进程的进程的进程描述符指针tsk。在copy_process()函数成功返回后,do_fork()函数将唤醒新创建的进程并投入运行。
1.9.3. 线程
对于Linux,内核并没有线程这个概念。Linux把所有的线程都当做进程来实现,线程仅仅被视为一个与其他进程共享某些资源的进程。在调用clone()时,指定特别的clone_flags就能创建一个线程。
1.9.4. 内核线程
内核通过内核线程(kernel thread)来完成一些经常需要在后台完成的操作,比如刷缓存,高级电源管理等等。内核线程和普通进程的区别在于内核线程没有独立的地址空间,它只在内核态运行。
内核线程只能由其它内核线程创建,内核是通过从kthreadd内核进程中衍生出所有新的内核线程来自动处理这一点的。创建一个新的内核线程的方法如下:
/**/ struct task_struct *kthread_create(int (*threadfn)(void *data), void *data, const char namefmt[], ...);
新的任务是由kthread内核进程通过clone()系统调用创建的,新进程创建后处于不可运行状态,需要用wake_up_process()来唤醒,唤醒后,它运行threadfn函数,以data作为参数,新内核线程的名字叫namefmt。
进程0 所有进程都是由一个pid=0的祖先繁衍出来的,它叫做进程0,它是Linux在初始化阶段从无到有造出来的,使用的是静态的数据结构(其他进程的数据结构都是动态分配的)。
进程1 进程0会创建一个新进程:进程1,也就是init进程,init进程被调度到后会运行init()方法,完成内核的初始化,然后用execve()系统调用装入可执行程序init,于是init进程从内核线程转变为普通进程。
1.10. 进程终结
所有进程的终止都是由do_exit()函数来处理的(位于
这样与进程相关联的所有资源都被释放掉了(当然预其它进程共享的资源不会被释放)。进程不可运行(实际上也没有地址空间让它运行)并处于EXIT_ZOMBIE状态。它占用的所有内存就是内核栈、thread_info结构和task_struct结构。当父进程发出了与被终止进程相关的wait()类系统调用之后,这些内存才会被释放。