Linux内核分析与应用-学习笔记(一)
*内核版本linux-5.25.0
第一章 概述
1.1 Linux操作系统概述
user->application->os->hardware
os目标:1.提高资源利用率 2.方便用户的使用
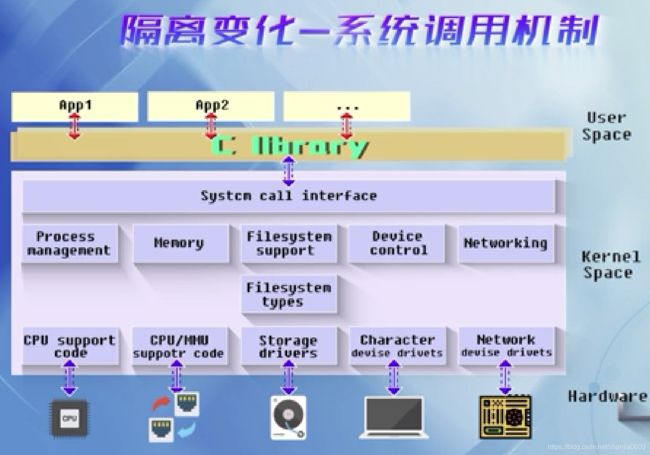
Linux系统的整体结构:

Linux内核的设计理念:机制与策略分离 ( Linux内核提供的是机制 )
系统调用机制->隔离变化

Linux学习:
入门:Linux内核设计与实现
深入理解:深入理解Linux内核
动手:Linux设备驱动程序
1.2 内核结构&模块编程
- 1.单核(可维护性较差)与微内核(效率较低)
- 2.内核源代码目录结构:mm,fs等
- 3.可加载的Linux内核模块LKM
- 内核模块编程入门:
printf->printk(输出到日志文件中)
#include - makefile文件编写:
obj-m:=hello.o
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL:=$(shell uname -r)
LINUX_KERNEL_PATH:=/usr/src/linux-headers-$(LINUX_KERNEL)
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
-
查看printk打印信息,日志信息存放在 /proc/kmsg文件中,通过dmesg命令查看。
-
模块插入内核:sudo insmod + 模块名.ko
-
查看当前系统中的模块:lsmod
-
通过demsg查看系统日志:

-
模块从内核卸载:sudo rmmod + 模块名.ko
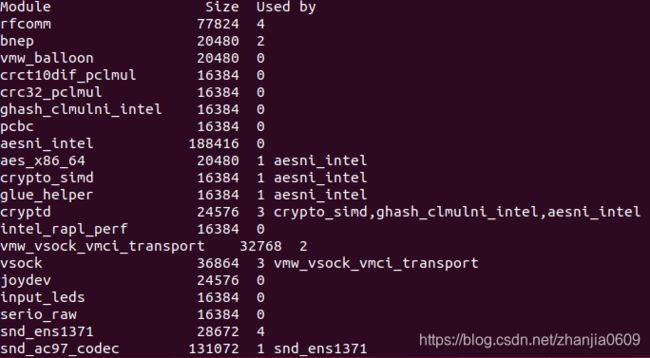
dmesg查看系统日志:

1.3 内核中的双链表结构
- 双链表可以转换为:单链表,队列,栈,二叉树。
- 双链表的定义存在于源代码目录下的/include/linux/types.h中

// 双链表的定义
struct list_head{
struct list_head *next,*prev;
};
- 链表的声明与初始化
内核位置:/include/linux/list.h文件中

其中#define LIST_HEAD_INIT(name) {&(name),&(name)}宏仅进行链表的初始化,而#define LIST_HEAD(name) strcut list_head name = LIST_HEAD_INIT(name)宏完成了链表的声明与初始化。(其实就是把双链表头节点中的next指针和prev指针,指向自己的地址) - 判断空链表

即判断头节点的next指针 - 在链表中增加节点
内核位置:/include/linux/list.h文件中
1.插入节点到指定节点之后:
static inline void list_add(struct list_head *new, struct list_head *head);

2.插入节点到指定节点之前
static inline void list_add_tail();
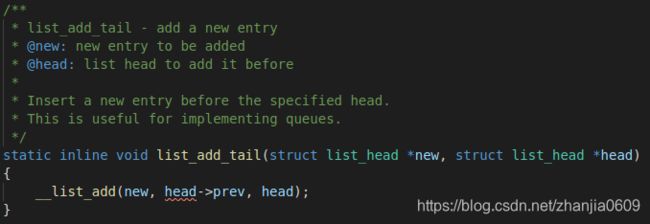
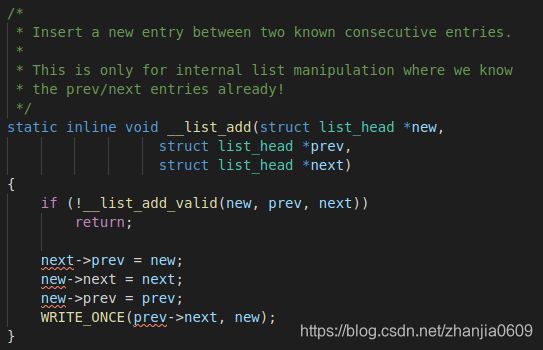
这两个函数均调用了
static inline void __list_add(strcut list_head *new, struct list_head *pre, struct list_head *next);
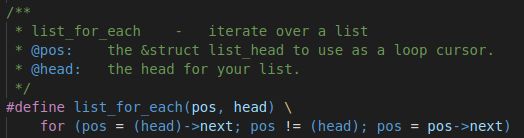
- 遍历链表
内核位置:/include/linux/list.h文件中
#define list_for_each(pos, head)\ for(pos = (head)->next; pos != (head); pos = pos->next)
- 获得节点的起始地址
内核位置:/include/linux/list.h文件中
#define list_entry(ptr, type, member) container_of(ptr, type, member)

其中container_of(ptr, type, member)函数用来求member成员所在的type类型的结构体的首地址。具体实现如下:
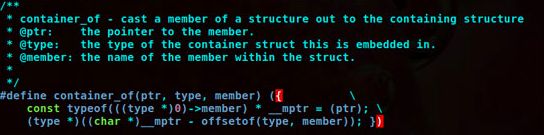

其中((type *)0)->member为member成员在函数体中的相对地址,(char *)__mptr为member成员的绝对地址,用绝对地址减去相对地址,得到其所在结构体的首地址。
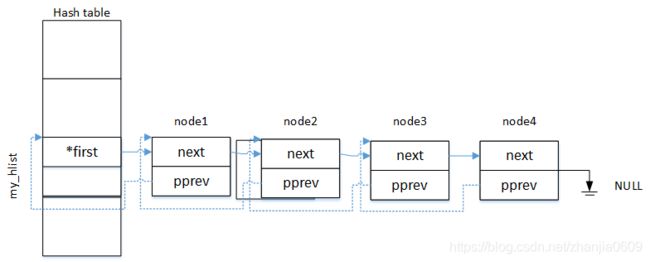
内核中的hash表结构
哈希表原理:此处略过,可以阅读数据结构方面的书籍
hash表的数据结构
内核位置/include/linux/types.h
struct hlist_head{
struct hlist_node *first;
};
struct hlist_node{
struct hlist_node *next, **prev;
};
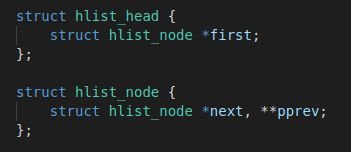
1.那么为什么哈希表中头节点hlist_head与其他节点hlist_node不同,而没有采用相同的结构体呢?
由于哈希表中一般采用单散列的形式,并不需要双链表的双向循环功能,所以Linux内核为了减少开销,并没有用hlist_node来指定哈希表头结点,而是采用了hlist_head结构,以减少存储空间的占用。头结点的数量与数据的总量在同一个数量级。
2.为什么在hlist_node中prev采用了二级指针,而没有采用单链表,或双向链表的形式呢?
(1)若使用单链表结构,在插入节点的时候可以采用在哈希表的头结点之后插入节点,此时时间复杂度为O(1)。但在删除节点的时候必须要遍历链表来寻找待删除节点的前一个节点,此时效率较低。
(2)若prev采用一级指针,则链表的形式如下:

- a.向链表中插入结点
当往链表中插入节点node1的时候,插入方式如下:
my_list.first = node1;
node1->pprev = (struct hlist_node*)&my_hlist;
再继续插入节点node2,node3,node4的时候,插入的方式:
头插法:
my_list.first = node[x];
node[x]->pprev = (struct hlist_node*)&my_hlist;
node[x]->next = node[x-1];
尾插法:
node[x]->next = node[x-1]->next;
node[x]->pprev = node[x-1];
- b.从链表中删除结点
删除node1节点时
(struct hlist_head*)node1->pprev->first = node1->next;
node1->next->pprev = (struct hlist_node*)&my_hlist / node1->pprev;
当删除node2~4其他节点时,
node[x]->pprev->next = node[x]->next;
node[x]->next->pprev = node[x]->pprev;
从节点的插入与删除中,我们可以看到若pprev采用一级指针,则第一个节点的插入与删除操作与其他节点的操作方式是不一样的,同时还需要进行hlist_dead和hlist_node之间的类型强制转换。因此Linux内核中为了统一节点的插入与删除操作方式,将pprev指针设置为了二级指针。
Linux内核中将pprev指针设计为二级指针有如下好处
为了间接改变表头中hlist_node类型first指针的值,使用了二级指针,因此在node节点中pprev中保存的为前一个结点中第一个元素的地址,头结点中即为first指针,其余节点则为next。

- 因此删除第一个节点的操作方式如下
*(node1->pprev) = node1->next;
node1->next->pprev = node1->pprev;
- 删除其余节点的操作方式如下(以node2节点为例):
*(node2->pprev) = node2->next;
node2->next->pprev = node2->pprev;
- 插入第一个节点
node1->pprev = &(my_list->first);
node1->next = my_list->first;//初始化时,first指针指向NULL
mylist->first = node1;
- 插入其余节点(以node2为例)
头插法
node2->pprev = &(my_list->first);
node2->next = my_list->first; // 或node1,为了与插入第一个节点的操作保持一致
my_list->first = node2;
尾插法
node2->pprev = &(node1->next);
node2->next = node1->next;
node1->next = node2;
这样一来所有节点的删除和插入操作方式都是完全一样的。
哈希表中的宏定义
//初始化头结点
#define HLIST_HEAD_INIT { .first = NULL }
//声明并初始化头结点
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
//初始化头结点
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
//初始化其他节点
#define INIT_HLIST_NODE(ptr) ((ptr)->next = NULL, (ptr)->pprev = NULL)

- 其中
{ .first = NULL }这个代码段的作用是,将hlist_head结构体中的first元素初始化为0。是根据结构体中的变量名来区分元素的,自己做了以下实验:
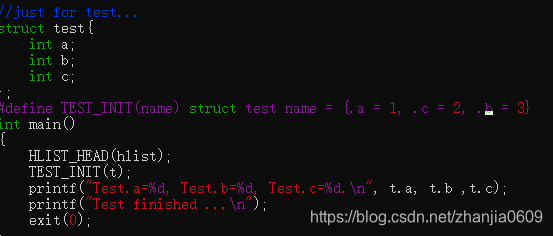
打印结果为:
注:该方法只能在GNU编译器下使用,在vs中测试无效。
内核中的哈希表结构