TS码流解析
实习期间做了一个TS码流解析的项目,总结了一些知识,分享给大家,可能会有写错漏,欢迎指正
1. TS
1.1 TS流与其他流的关系
ES(Elementary Stream): 基本码流,不分段的音频、视频或其他信息的连续码流。
PES(Packetized Elementary Stream):分组的基本码流,将基本码流ES流根据需要分成长度不等的数据包,并加上包头就形成了打包的基本码流PES流。是用来传输ES的一种数据结构。
TS(Transport Stream):传输流,是由固定长度的包组成,含有独立时间基准的一个或多个节目,适用于误码较多的环境,并且从流的任意一段开始都可以独立解码。在MPEG-2系统中,由视频,音频的ES流和辅助数据复接生成的用于实际传输的标准信息流称为MPEG-2传送流。个人理解,TS流是原始的PES流(音视频等)中按照一定的频率插入PSI/SI和一些标识符(辅助数据)信息,然后按固定长度打包形成的传输流。值得注意的是,PSI/SI信息在TS流中并不是只发送一次,而是按照一定的频率插入码流,是重复发送的。
PS(Program Stream):节目流,PS流与TS流的区别在于,PS流的包结构是可变长度的,而TS流的包结构是固定长度的。
1.2 TS包
TS包的长度:188 B或204 B,204 B长度是在188B后面增加了16 B的CRC校验数据。
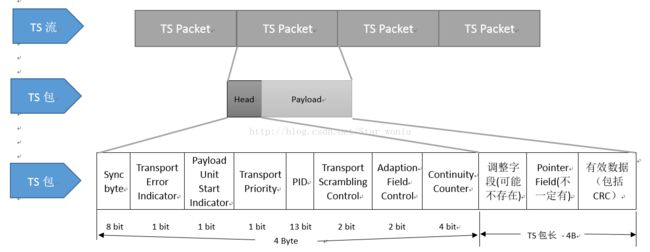
sync_byte: 1B,固定值0x47,TS包的标识符,正常的TS包在0x47的包头标识符往后188/204B之后仍然是0x47【下一个TS包的标识符】
transport_error_Indicator: 1bit,当其为1时,表示该TS包中至少有一个不可纠正的错误位,只有在错误纠正之后,该位才能重新置0【实际获取TS包之后,该位为1的包丢弃】
payload_unit_start_indicator: 1bit,对于PSI数据包,该位为1时,表示该TS包是某个Section的第一个包,并且该包含有pointer_field,该变量的值意义在于,除了调整字段之外,往后pointer_field个字节开始,才是有效数据。对于空包来说,该值为0。
transport_priority: 1bit,表示传输优先级,对于相同PID的TS包,该字段置1的TS包拥有更高的优先级。
PID:13bit,PID可以标识存储于TS包中有效净荷的数据的类型。PID用于TS包阶段用于鉴别各种PSI/SI信息表、电视节目,区分音视频的PES包等,是辨别码流信息性质的关键。
transport_scrambling_control:2bit,用来指示传送流包Payload的加扰方式。【传送流包首部包括调整字段,则不应被加扰;空包也不加扰。】
| Transport_scrambling_control |
描述 |
| 00 |
未加扰 |
| 01 |
用户定义 |
| 10 |
用户定义 |
| 11 |
用户定义 |
adaption_field_control:2bit,表示传送流包首部是否跟随调整字段/Payload【如果全部是调整字段则不含payload】
| adaption_field_control |
描述 |
| 00 |
为ISO/IEC未来使用保留 |
| 01 |
没有调整字段 |
| 10 |
没有payload,全部是调整字段 |
| 11 |
0-182B的调整字段后为有效净荷 |
continuity_counter: 4bit,随着具有相同PID的TS包增加而增加,当它达到最大(31)时,又恢复为0,如果adaption_field_control = 00/10,该连续计数器不增加,因为不含payload。
1.3解析TS包
1.3.1获取包长
TS包的包长有两种——188B或者204B,在解析TS包之前,必须要先判断TS包包长,以便后续进行分析。
本人设计获取包长的方法比较笨拙,在拿到第一个0x47数据之后,让文件指针往后188B,如果是0x47,就让指针继续往下,如此循环10次(可以更多),结果仍旧是0x47,就判断包长为188 B,否则用相同的方法判断204B,通过则包长为204,都不通过就对该文件继续往下搜索,用相同的方法判断包长。
具体流程如下图(以188 B为例):
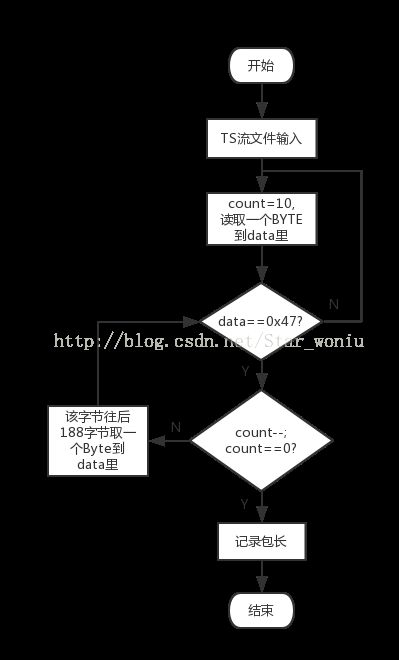
经过分析码流发现,大部分的TS包都是以188 B为指定长度的。
1.3.2 解析TS包头
在获取包长之后,就要对包头信息进行解析并获取有效数据,需要定义一个结构体存储数据:
/*TS包包头的结构体*/
typedef struct CSTSPacketHeader_S
{
BYTE ucSyncByte; //TS包的标识符
BYTE ucTransport_error_indicator; //传输错误指示器,当值为时,表示该包有误
BYTE ucPayload_unit_start_indicator; //有效净荷开始标记位,当值为时,表示该包是某个section的开头,具有pointer_field 字段
BYTE ucTransport_priority; //传输的优先级
WORD wPID; //TS包的ID,用于区分不同的section
BYTE ucTransport_scrambling_control; //指示ts传送流包有效净荷的加扰方式
BYTE ucAdaptation_field_control; //指示是否有调整字段和有效净荷
BYTE ucContinuity_counter; //随着相同PID TS包的增加而增加
}TSPacketHeader;
注:如果想要节省存储空间,可以使用位域的方式定义结构体。BYTE——unsigned char,Word——unsignedshort int
假定包长为188,我们每获取一个TS包,就装进一个长度为188的BYTE型数组里,前4个BYTE就是包头的数据了,获取数据可以逻辑与,左右移,逻辑或的方法进行,具体例子如下:
pstTSHeader->wPID = ((pucTSBuffer[1]& 0x1f) << 8) | pucTSBuffer[2];
1.3.3 判断TS包的有效性
在一个码流中,并不全部都是有效的TS包,需要将一些无效TS包剔除
无效TS包的情况分为五种:
(1) 该TS包往后188B不是0x47的包头标识符(TS包都是连续发送,如果出现包不连续的地方,说明该包数据传送时出错);
(2) TS包存在错误,即transport_error_Indicator的值为1;
(3) TS包全是调整字段(空包),即adaption_field_control的值为10(二进制);
(4) TS包的调整字段属于保留的情况,即adaption_field_control的值为00(二进制);
(5) TS包被加扰,即transport_scrambling_control不为00,(如果有做解扰可以去掉这种情况);
对于这五种情况的TS包我们一律丢弃,直接获取下一个TS包。
1.3.4 确定payload的起始位置
TS包中,Payload的起始位置并不是固定的,会受到调整字段和pointer_field的影响,解析获取包头信息之后就可以确定payload的起始位置payloadPosition了。
首先要判断是不是有调整字段,如果有payloadPosition = 5 + 调整字段长度。
如果没有 payloadPosition= 4。
其次要判断是不是有pointer_field,payload_unit_start_indicator= 1 则有,此时payloadPosition+= 1 + pointer_field;
注:1.这里算出的是数组的下标,从payloadPosition(包括payloadPosition下标)开始都是属于有效数据。
2.TS流里所有的长度都是从长度数据的下一个Byte开始算,比如section_length是5,就是从section_length的下一个Byte开始算,有5个字节的长度,所以第一种情况加的时候要加上调整字段长度本身的1个字节,还有包头4个字节,一共是5个。
开头参考博客 http://blog.chinaaet.com/yuwoo/p/5100018406 感谢!