Syslog、WMI、Windows日志、FTP、SFTP、SCP、NetFlow、JMS、ActiveMQ采集协议
采集协议
Syslog
介绍
在Unix类操作系统上,syslog广泛应用于系统日志。syslog日志消息既可以记录在本地文件中,也可以通过网络发送到接收syslog的服务器。网络传输使用UDP协议,端口号514。接收syslog的服务器可以对多个设备的syslog消息进行统一的存储,或者解析其中的内容做相应的处理。常见的应用场景是网络管理工具、安全管理系统、日志审计系统。
完整的syslog日志中包含产生日志的程序模块(Facility)、严重性(Severity或 Level)、时间、主机名或IP、进程名、进程ID和正文。在Unix类操作系统上,能够按Facility和Severity的组合来决定什么样的日志消息是否需要记录,记录到什么地方,是否需要发送到一个接收syslog的服务器等。由于syslog简单而灵活的特性,syslog不再仅限于 Unix类主机的日志记录,任何需要记录和发送日志的场景,都可能会使用syslog。
长期以来,没有一个标准来规范syslog的格式,导致syslog的格式是非常随意的。最坏的情况下,根本就没有任何格式,导致程序不能对syslog 消息进行解析,只能将它看作是一个字符串。
在2001年定义的RFC3164中,描述了BSD syslog协议。
不过这个规范的很多内容都不是强制性的,常常是“建议”或者“约定”,也由于这个规范出的比较晚,很多设备并不遵守或不完全遵守这个规范。
约定发送syslog的设备为Device,转发syslog的设备为Relay,接收syslog的设备为Collector。Relay本身也可以发送自身的syslog给Collector,这个时候它表现为一个Device。Relay也可以只转发部分接收到的syslog消息,这个时候它同时表现为Relay和Collector。
syslog消息发送到Collector的UDP 514端口,不需要接收方应答,RFC3164建议 Device 也使用514作为源端口。规定syslog消息的UDP报文不能超过1024字节,并且全部由可打印的字符组成。完整的syslog消息由3部分组成,分别是PRI、HEADER和MSG。大部分syslog都包含PRI和MSG部分,而HEADER可能没有。
Syslog服务器
Syslog服务器是专门部署的一套应用系统。用于收集网络中各个节点的系统日志,这些收到的日志一般称为原始日志;然后根据一些格式化模板对原始日志进行格式化,翻译成容易辨识的格式,最后通过图形化界面展示出来。
1.集中管理日志,无需登录每个设备,便于查询。
2.对原始日志进行格式化,翻译成容易辨识的格式,方便解读。
3.可根据日志内容设置告警规则,进行告警。
4.给没有硬盘的设备提供长期存储日志的途径。
BSD syslog格式
<30>Oct 9 22:33:20 hlfedora auditd[1787]: The audit daemon is exiting.
其中“<30>”是PRI部分,“Oct 9 22:33:20 hlfedora”是HEADER部分,“auditd[1787]: The audit daemon is exiting.”是MSG部分。
PRI部分
PRI部分由尖括号包含的一个数字构成,这个数字包含了程序模块(Facility)、严重性(Severity),这个数字是由Facility乘以 8,然后加上Severity得来,取值范围(0~191)。
Priority=Facility*8+Severity
也就是说这个数字如果换成2进制的话,低位的3个bit表示Severity,剩下的高位的部分右移3位,就是表示Facility的值。
Facility
Numerical Code Facility
0 kernel messages 系统内核消息。
1 user-level messages 用户进程。
2 mail system 邮件日志。
3 system daemons 某些守护进程产生的日志。
4 security/authorization messages (note 1) 用户认证时产生的日志,如login命令、su命令。
5 messages generated internally by syslogd syslogd产生的内部消息
6 line printer subsystem 与打印机活动有关。
7 network news subsystem 网络新闻传输协议(nntp)产生的消息。
8 UUCP subsystem UUCP子系统。
9 clock daemon (note 2) 时钟守护进程
10 security/authorization messages (note 1) 用户认证时产生的日志,如login命令、su命令。
11 FTP daemon ftp守护进程
12 NTP subsystem 网络时间协议(ntp)产生的消息。
13 log audit (note 1)
14 log alert (note 1)
15 clock daemon (note 2)
16 local use 0 (local0)
17 local use 1 (local1)
18 local use 2 (local2)
19 local use 3 (local3)
20 local use 4 (local4)
21 local use 5 (local5)
22 local use 6 (local6)
23 local use 7 (local7)
syslog的Facility是早期为Unix操作系统定义的,不过它预留了User(1),Local0~7 (16~23)给其他程序使用 .
Severity
Numerical Code Severity
0 Emergency: system is unusable 紧急情况 ——造成严重错误导致系统不可用,该日志被传送到日志服务器。
1 Alert: action must be taken immediately 告警 ——警报信息,需要通知管理员,该日志被传送到日志服务器。
2 Critical: critical conditions 严重 ——严重错误信息,例如硬盘错误,可能会阻碍程序的部分功能。
3 Error: error conditions 错误 ——一般错误消息。
4 Warning: warning conditions 警告 ——所有攻击行为以及非授权访问(除通信日志外)。
5 Notice: normal but significant condition 通知 ——管理员操作,不是错误,但是可能需要处理。
6 Informational: informational messages 信息 ——通用性消息,一般用来提供有用信息。
7 Debug: debug-level messages 调试 ——调试程序产生的信息。
HEADER部分(可选)
HEADER部分包括两个字段,时间和主机名(或IP)。
时间紧跟在PRI后面,中间没有空格,格式必须是“Mmm dd hh:mm:ss”,不包括年份。“日”的数字如果是1~9,前面会补一个空格(也就是月份后面有两个空格),而“小时”、“分”、“秒”则在前面补“0”。月份取值包括:
Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec。
时间后边跟一个空格,然后是主机名或者IP地址,主机名不得包括域名部分。
因为有些系统需要将日志长期归档,而时间字段又不包括年份,所以一些不标准的syslog格式中包含了年份,例如:
<165>Aug 24 05:34:00 CST 1987 mymachine myproc[10]: %% It’s time to make the do-nuts. %% Ingredients: Mix=OK, Jelly=OK # Devices: Mixer=OK, Jelly_Injector=OK, Frier=OK # Transport:Conveyer1=OK, Conveyer2=OK # %%
这样会导致解析程序将“CST”当作主机名,而“1987”开始的部分作为MSG部分。解析程序面对这种问题,可能要做很多容错处理,或者定制能解析多种syslog格式,而不仅仅是只能解析标准格式。
MSG部分
HEADER部分后面跟一个空格,然后是MSG部分。
有些syslog中没有HEADER部分。这个时候MSG部分紧跟在PRI后面,中间没有空格。
MSG部分又分为两个部分,TAG和Content。其中TAG部分是可选的。
<30>Oct 9 22:33:20 hlfedora auditd[1787]: The audit daemon is exiting.
auditd[1787]是TAG部分,包含了进程名称和进程PID。PID可以没有,这个时候中括号也是没有的。
进程PID有时甚至不是一个数字,例如“root-1787”,解析程序要做好容错准备。
TAG后面用一个冒号隔开Content部分,这部分的内容是应用程序自定义的。
WMI
Windos日志
介绍
Windows操作系统在其运行的生命周期中会记录其大量的日志信息,这些日志信息包括:Windows事件日志(Event Log),Windows服务器系统的IIS日志,FTP日志,Exchange Server邮件服务,MS SQL Server数据库日志等。处理应急事件时,客户提出需要为其提供溯源,这些日志信息在取证和溯源中扮演着重要的角色。
Windows事件日志文件实际上是以特定的数据结构的方式存储内容,其中包括有关系统,安全,应用程序的记录。每个记录事件的数据结构中包含了9个元素(可以理解成数据库中的字段):日期/时间、事件类型、用户、计算机、事件ID、来源、类别、描述、数据等信息。应急响应工程师可以根据日志取证,了解计算机上上发生的具体行为。
Windows系统中自带了一个叫做事件查看器的工具,它可以用来查看分析所有的Windows系统日志。运行 eventvwr 可以快速打开事件查看器。使用该工具可以看到系统日志被分为了两大类:Windows日志和应用程序和服务日志。
系统内置的三个核心日志文件(System,Security和Application)默认大小均为20480KB(20MB),记录事件数据超过20MB时,默认系统将优先覆盖过期的日志记录。其它应用程序及服务日志默认最大为1024KB,超过最大限制也优先覆盖过期的日志记录。
windows日志类型
系统日志
系统日志包含 Windows 系统组件记录的事件。例如,在启动过程中加载驱动程序或其他系统组件失败将记录在系统日志中。系统组件所记录的事件类型由 Windows 预先确定。
默认位置:%SystemRoot%\System32\Winevt\Logs\System.evtx
应用程序日志
应用程序日志包含由应用程序或程序记录的事件。例如,数据库程序可在应用程序日志中记录文件错误。程序开发人员决定记录哪些事件。
默认位置:%SystemRoot%\System32\Winevt\Logs\Application.evtx
安全日志
安全日志包含诸如有效和无效的登录尝试等事件,以及与资源使用相关的事件,如创建、打开或删除文件或其他对象。管理员可以指定在安全日志中记录什么事件。例如,如果已启用登录审核,则对系统的登录尝试将记录在安全日志中。
默认位置:%SystemRoot%\System32\Winevt\Logs\Security.evtx
应用程序及服务日志
Microsoft
Microsoft文件夹下包含了200多个微软内置的事件日志分类,只有部分类型默认启用记录功能,如远程桌面客户端连接、无线网络、有线网路、设备安装等相关日志。
默认位置:%SystemRoot%\System32\Winevt\Logs目录下Microsoft-Windows开头的文件名
Microsoft Office Alerts
微软Office应用程序(包括Word/Excel/PowerPoint等)的各种警告信息,其中包含用户对文档操作过程中出现的各种行为,记录有文件名、路径等信息。
默认位置:%SystemRoot%\System32\Winevt\Logs\OAerts.evtx
Windows PowerShell
Windows自带的PowerShell应用的日志信息。
默认位置:%SystemRoot%\System32\Winevt\Logs\Windows PowerShell.evtx
Internet Explorer
IE浏览器应用程序的日志信息,默认未启用,需要通过组策略进行配置。
默认位置:%SystemRoot%\System32\Winevt\Logs\Internet Explorer.evtx
windows事件类型/级别
Windows事件日志中共有五种事件类型,所有的事件必须拥有五种事件类型中的一种,且只可以有一种。五种事件类型分为:
- 信息(Information):信息事件指应用程序、驱动程序或服务的成功操作的事件。
- 警告(Warning):警告事件指不是直接的、主要的,但是会导致将来问题发生的问题。例如,当磁盘空间不足或未找到打印机时,都会记录一个“警告”事件。
- 错误(Error):错误事件指用户应该知道的重要的问题。错误事件通常指功能和数据的丢失。例如,如果一个服务不能作为系统引导被加载,那么它会产生一个错误事件。
- 成功审核(Success audit):成功的审核安全访问尝试,主要是指安全性日志,这里记录着用户登录/注销、对象访问、特权使用、账户管理、策略更改、详细跟踪、目录服务访问、账户登录等事件,例如所有的成功登录系统都会被记录为“ 成功审核”事件。
- 失败审核(Failure audit):失败的审核安全登录尝试,例如用户试图访问网络驱动器失败,则该尝试会被作为失败审核事件记录下来。
Windows事件属性
Windows事件日志属性如下:
属性名 描述
事件ID 标识特定事件类型的编号。描述的第一行通常包含事件类型的名称。例如,6005 是在启动事件日志服务时所发生事件的 ID。此类事件的描述的第一行是“事件日志服务已启动”。产品支持代表可以使用事件 ID 和来源来解决系统问题。
来源 记录事件的软件,可以是程序名(如“SQL Server”),也可以是系统或大型程序的组件(如驱动程序名)。例如,“Elnkii”表示 EtherLink II 驱动程序。
级别 事件严重性的分类,以下事件严重性级别可能出现在系统和应用程序日志中: 信息:指明应用程序或组件发生了更改,如操作成功完成、已创建了资源,或已启动了服务。 警告:指明出现的问题可能会影响服务器或导致更严重的问题(如果未采取措施)。 错误:指明出现了问题,这可能会影响触发事件的应用程序或组件外部的功能。 关键:指明出现了故障,导致触发事件的应用程序或组件可能无法自动恢复。以下事件严重性级别可能出现在安全日志中: 审核成功 :指明用户权限练习成功。 审核失败:指明用户权限练习失败。在事件查看器的正常列表视图中,这些分类都由符号表示。
用户 事件发生所代表的用户的名称。如果事件实际上是由服务器进程所引起的,则此名称为客户端 ID;如果没有发生模仿的情况,则为主 ID。如果适用,安全日志项同时包含主 ID 和模仿 ID。当服务器允许一个进程采用另一个进程的安全属性时就会发生模拟的情况
操作代码 包含标识活动或应用程序引起事件时正在执行的活动中的点的数字值。例如,初始化或关闭
日志 已记录事件的日志的名称
任务类别 用于表示事件发行者的子组件或活动。
关键字 可用于筛选或搜索事件的一组类别或标记。示例包括“网络”、“安全”或“未找到资源”
计算机 发生事件的计算机的名称。该计算机名称通常为本地计算机的名称,但是它可能是已转发事件的计算机的名称,或者可能是名称更改之前的本地计算机的名称
日期和时间 记录事件的日期和时间
常用的事件id
Windows 的日志以事件 id 来标识具体发生的动作行为。
事件ID 说明
1102 清理审计日志
4624 账号登录成功
4625 账号登录失败
4634 账号注销成功
4647 用户启动的注销
4672 使用超级用户(如管理员)进行登录
4720 创建用户
4726 删除用户
4732 将成员添加到启用安全的本地组中
4733 将成员从启用安全的本地组中移除
4688 创建新进程
4689 结束进程
每个成功登录的事件都会标记一个登录类型,不同登录类型代表不同的方式:
登录类型 描述 说明
2 交互式登录(Interactive) 用户在本地进行登录。
3 网络(Network) 最常见的情况就是连接到共享文件夹或共享打印机时。
4 批处理(Batch) 通常表明某计划任务启动。
5 服务(Service) 每种服务都被配置在某个特定的用户账号下运行。
7 解锁(Unlock) 屏保解锁。
8 网络明文(NetworkCleartext) 登录的密码在网络上是通过明文传输的,如FTP。
9 新凭证(NewCredentials) 使用带/Netonly参数的RUNAS命令运行一个程序。
10 远程交互,(RemoteInteractive) 通过终端服务、远程桌面或远程协助访问计算机。
11 缓存交互(CachedInteractive) 以一个域用户登录而又没有域控制器可用
WMI简介
WMI就是Windows Managerment Instrumentation(Windows管理规范),是Windows中的一个核心管理技术。WMI为访问大量的Windows管理数据和方法提供了一个统一的机制。WMI通过脚本、C++程序接口、.Net类(系统管理)和命令行工具(WMIC)提供了对这个信息的访问。WMI的功能还包括事件、远程、查询、查看、计划和实施用户扩展及更多内容。可以理解为Windows提供了一个api来操作Windows系统。
简而言之,用户可以使用 WMI 管理本地和远程计算机。
WMI体系结构

WMI 体系结构由三个主层组成:
- 托管资源和提供程序
- WMI 基础结构
- 使用者
托管资源和提供程序
托管资源是任意逻辑或物理组件,通过使用 WMI 进行公开和管理。可以使用 WMI 管理的 Windows 资源包括:计算机系统、磁盘、外围设备、事件日志、文件、文件夹、文件系统、网络组件、操作系统子系统、性能计数器、打印机、进程、注册表设置、安全性、服务、共享、SAM 用户和组、Active Directory、Windows 安装程序、Windows 驱动程序模式 (WDM) 设备驱动程序,以及 SNMP 管理信息基 (MIB) 数据等。
WMI 托管资源通过一个提供程序与 WMI 通讯。
提供程序是一个监控一个或者多个托管对象的COM接口。在 WMI 和托管资源之间扮演着中间方的角色。提供程序代表使用者应用程序和脚本从 WMI 托管资源请求信息,并发送指令到 WMI 托管资源。
WMI 基础结构
WMI基础结构是Windows系统的系统组件。它包含两个模块:包含WMI Core的WMI Service(WMI服务,Winmgmt)和WMI Repository(WMI存储库)。
WMI存储库是通过WMI Namespace(WMI命名空间)组织起来的。在系统启动时,WMI服务会创建诸如root\default、root\cimv2和root\subscription等WMI命名空间,同时会预安装一部分WMI类的定义信息到这些命名空间中。其他命名空间是在操作系统或者产品调用有关WMI提供者(WMI Provider)时才被创建出来的。简而言之,WMI存储库是用于存储WMI静态数据的存储空间。
WMI服务扮演着WMi提供者、管理应用和WMI存储库之间的协调者角色。一般来说,它是通过一个共享的服务进程Svchost来实施工作的。当第一个管理应用向WMI命名空间发起连接时,WMI服务将会启动。当管理应用不再调用WMI时,WMI服务将会关闭或者进入低内存状态。如我们上图所示,WMI服务和上层应用之间是通过COM接口来实现的。当一个应用通过接口向WMI发起请求时,WMI将判断该请求是请求静态数据还是动态数据。
- 如果请求的是一个静态数据,WMI将从WMI存储库中查找数据并返回;
- 如果请求的是一个动态数据,比如一个托管对象的当前内存情况,WMI服务将请求传递给已经在WMI服务中注册的相应的WMI提供者。WMI提供者将数据返回给WMI服务,WMI服务再将结果返回给请求的应用。
WMI 使用者
WMI 使用者是与 WMI 基础结构交互的管理应用程序或脚本。 管理应用程序可以通过调用WMI的 COM API 或 WMI 的脚本 API来查询、枚举数据、运行提供程序方法或订阅事件。
WQL语句查询
WQL是WMI中的查询语言,全称是WMI query language。WQL语法格式和sql一样,不过要注意这些语句并不能直接在命令行执行。
当执行任何 WMI 查询时,除非显式提供命名空间,否则将隐式使用默认的命名空间 ROOT\CIMV2。
一共有三种类别的查询:
实例查询
实例查询是最常见的用于获取 WMI 对象实例的 WQL 查询。
SELECT [cLASS PROPERTY NAME | *] FROM [CLASS NAME]
//查询正在运行的进程的可执行文件中包含Chrome的结果
SELECT * FROM Win32_Process WHERE Name LIKE "%chrome%"
事件查询
事件查询提供了报警机制,触发事件的类。用于一个WMI事件注册机制,如WMI对象的创建,修改或删除。事件分为内部事件和外部事件。
SELECT [Class property name|*] from [INTRINSIC CLASS NAME] WITHIN [POLLING IINTERVAL]
SELECT [Class property name|*] FROM [EXTRINSIC CLASS NAME]
//插入时的事件查询触发器
SELECT * FROM Win32_VolumeChangeEvent WHERE EventType = 2
//交互式用户登录的事件查询触发器
SELECT * FROM __InstanceCreationEvent WITHIN 15 WHERE TargetInstance ISA 'Win32_LogonSession' AND TargetInstance.LogonType = 2
架构查询
架构查询用于检索类定义 (而不是类实例) 和架构关联。 类提供程序使用架构查询来指定他们在注册时支持的类。
SELECT [Class property name|*] FROM [Meta_Class
//查询所有以Win32开头的WMI类
SELECT * FROM Meta_Class WHERE __Class LIKE "Win32%"
FTP
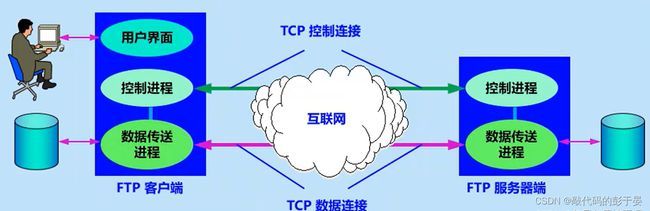
介绍
FTP(文件传输协议)是一种多通道协议,意为FTP协议有多个端口与外界进行通信,工作模式有FTP服务器和FTP客户端。默认使用TCP端口的20和21端口,20端口用于数据传输,21端口用于控制连接。
主要作用是为了用户上传和下载文件。
工作方式
控制连接
客户端与FTP服务器建立文件上传下载连接时,它首先向服务器的TCP 21端口发起一个建立连接的请求,FTP服务器接收来自客户端的请求,完成连接的建立
数据连接
客户端与ftp服务器建立连接之后,就可以进行数据传输了,传输文件的过程叫做ftp数据连接。
ftp数据连接又分为两种传输模式:主动传输和被动传输,主动和被动都是以服务器进行参照的。
- 主动传输:
客户端通过任意端口N(N>1024)向服务器的ftp端口(默认是21)发送连接请求,服务器接收连接,建立一条命令链路。当需要传送数据时,客户端在命令链路上用PORT命令告诉服务器客户端生成的端口是N+1。于是服务器从20端口向客户端N+1端口发送连接请求,建立一条数据传输链路路,用来文件的上传和下载
在这里要说明一下为什么客户端端口是N+1,因为客户端在与服务器建立控制连接服务时,与服务器的21端口连接的是N端口,N端口被占用,所以用N+1端口与服务器的20端口建立数据连接服务
- 被动传输
客户端通过任意端口N(N>1024)向服务器的ftp端口(默认是21)发送连接请求并监听N+1端口。服务器接收客户端请求,建立一条命令链路。当需要传送数据时,服务器在命令链路上用PASV命令告诉客户端服务器随机生成的端口P(P>1024).于是客户端通过N+1端口向服务器的P端口发送连接请求,建立一条数据链路用来传送数据。
被动模式与主动模式不同的地方就是客户端启动数据连接。在主动模式下,客户端在命令通道上建立连接后,服务器将启动与客户端的数据连接。而在被动模式下,建立命令通道后,由客户端启动与服务器的数据连接。
因为这个区别,可以得出两者的优势和缺陷。比如主动模式有利于管理 FTP 服务端,因为只需要打开 21 端口的“准入”、20 端口的“准出” 即可,但是由于服务器连接到客户端的端口随机,所以客户端有可能会触发防火墙,甚至直接被防火墙拦截掉。反之被动模式则有利于管理客户端。
SFTP
介绍
SFTP,称为 安全文件传输协议。SSH File Transfer Protocol的缩写,SFTP与FTP有着几乎一样的语法和功能,但FTP与SFTP 完全没关系。SFTP是SSH内含协议,也就是说只要ssh服务器启动了,sftp就可使用,不需要额外安装(SFTP 为 SSH的其中一部分.),它的默认端口和SSH一样为22。
FTP与SFTP的区别
- SFTP通过使用加密/解密技术来保障传输文件的安全性,因此SFTP的传输效率比普通的FTP要低,但sftp的安全性要比ftp高,因此sftp通常用于报表、对账单等对安全性要求较高的场景。
- SFTP要求客户端必须由服务器进行身份验证,并且数据传输必须通过安全通道(SSH)进行,即不传输明文密码或文件数据。它允许对远程文件执行各种操作,有点像远程文件系统协议。SFTP允许从暂停传输,目录列表和远程文件删除等操作中恢复。
- 并不像FTP是基于文本的传输,SFTP是基于数据包的传输,SFTP会将一些文本指令转化为二进制指令来进行传输。从长远来看,SFTP相对于FTP在这方面也或多或少的减少了数据的传输。
- 另外,SFTP也不像FTP那样需要构建两个连接来进行数据传输。在SFTP中仅仅只是通过一条主控制连接来完成文件的传输,不需要还为数据的传输另外开辟一条独立的数据连接,一个端口就可以搞定。这样就省去了考虑很多防火墙在网络中所带来的限制问题。
- 还有就是通过SFTP进行文件传输时,能传递更多的文件属性,比如文件权限,时间,大小等等。这些在FTP中是做不到的。
SCP
介绍
Linux scp命令用于Linux之间复制文件和目录。scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。 也就是说只要ssh服务器启动了,scp就可使用,不需要额外安装它的默认端口和SSH一样为22。
除开远程服务器之间的文件复制这个特殊情况, scp会先解析命令行参数, 然后打开一个到远程服务器的连接. 再通过这个连接起另一个scp进程, 这个进程的运行方式可以是源模式(source)也可以是宿模式(sink).
源端:协议信息是由文本和二进制数据混合构成的。
- 普通文件:协议消息的类型, 文件的权限位, 长度及文件名都会以文本的方式发送。
- 二进制文件:二进制数据传输前需要传输的文本信息可能更多. 源端会一直等宿端的回应, 直到等到回应才会传输下一条协议文本. 在送出最后一条协议文本后, 源端会传出一个大小为零的字符’\0’来表示真正文件传输的开始. 当文件接收完成后, 宿端会给源端发送一个’\0’。
宿端:来自源端的每条消息和每个传输完毕的文件都需要宿端的确认和响应. 宿端会返回三种确认消息: 0(正常), 1(警告)或2(严重错误, 将中断连接). 消息1和2可以跟一个字符串和一个换行符, 这个字符串将显示在scp的源端. 无论这个字符串是否为空, 换行符都是不可缺少的.
ssh知识
SSH是一种协议标准,其目的是实现安全远程登录以及其它安全网络服务。
SSH工作原理
对称加密,指加密解密使用同一套秘钥。
Client:

Server:

对称加密的加密强度高,很难破解。但是在实际应用过程中不得不面临一个棘手的问题:如何安全的保存密钥呢?尤其是考虑到数量庞大的Client端,很难保证密钥不被泄露。一旦一个Client端的密钥被窃据,那么整个系统的安全性也就不复存在。为了解决这个问题,非对称加密应运而生。非对称加密有两个密钥:“公钥”和“私钥”。
两个密钥的特性:公钥加密后的密文,只能通过对应的私钥进行解密。而通过公钥推理出私钥的可能性微乎其微
非对称加密方案的登录流程:

- 1.远程Server收到Client端用户TopGun的登录请求,Server把自己的公钥发给用户。
- 2.Client使用这个公钥,将密码进行加密。
- 3.Client将加密的密码发送给Server端。
- 4.远程Server用自己的私钥,解密登录密码,然后验证其合法性。
- 5.若验证结果,给Client相应的响应。
私钥是Server端独有,这就保证了Client的登录信息即使在网络传输过程中被窃据,也没有私钥进行解密,保证了数据的安全性,这充分利用了非对称加密的特性。
这样就一定安全了吗?
上述流程会有一个问题:Client端如何保证接受到的公钥就是目标Server端的?,如果一个攻击者中途拦截Client的登录请求,向其发送自己的公钥,Client端用攻击者的公钥进行数据加密。攻击者接收到加密信息后再用自己的私钥进行解密,不就窃取了Client的登录信息了吗?这就是所谓的中间人攻击

SSH中是如何解决这个问题的?
- 基于口令的认证
从上面的描述可以看出,问题就在于如何对Server的公钥进行认证?在https中可以通过CA来进行公证,可是SSH的publish key和private key都是自己生成的,没法公证。只能通过Client端自己对公钥进行确认。通常在第一次登录的时候,系统会出现下面提示信息:
The authenticity of host 'ssh-server.example.com (12.18.429.21)' can't be established.
RSA key fingerprint is 98:2e:d7:e0:de:9f:ac:67:28:c2:42:2d:37:16:58:4d.
Are you sure you want to continue connecting (yes/no)?
上面的信息说的是:无法确认主机ssh-server.example.com(12.18.429.21)的真实性,不过知道它的公钥指纹,是否继续连接?
之所以用fingerprint代替key,主要是key过于长(RSA算法生成的公钥有1024位),很难直接比较。所以,对公钥进行hash生成一个128位的指纹,这样就方便比较了。
如果输入yes后,会出现下面信息:
Warning: Permanently added 'ssh-server.example.com,12.18.429.21' (RSA) to the list of known hosts.
Password: (enter password)
该host已被确认,并被追加到文件known_hosts中,然后就需要输入密码,之后的流程就按照图1-3进行。
2.基于公钥认证
在上面介绍的登录流程中可以发现,每次登录都需要输入密码,很麻烦。SSH提供了另外一种可以免去输入密码过程的登录方式:公钥登录。流程如下:

- 1.Client将自己的公钥存放在Server上,追加在文件authorized_keys中。
- 2.Server端接收到Client的连接请求后,会在authorized_keys中匹配到Client的公钥pubKey,并生成随机数R,用Client的公钥对该随机数进行加密得到pubKey®
,然后将加密后信息发送给Client。 - 3.Client端通过私钥进行解密得到随机数R,然后对随机数R和本次会话的SessionKey利用MD5生成摘要Digest1,发送给Server端。
- 4.Server端会也会对R和SessionKey利用同样摘要算法生成Digest2。
- 5.Server端会最后比较Digest1和Digest2是否相同,完成认证过程。
SCP命令说明
### linux的scp命令可以在linux服务器之间复制文件和目录。
scp [参数] [原路径] [目标路径]
### 当前服务器传输文件:目录之间
scp -r /opt /mnt
### 远程服务器传输文件:远程传输
scp -r /opt [email protected]:/mnt
### 从远程服务端复制到当前客户端
scp [email protected]:/opt/zook.sh /mnt/
### 从指定的服务端复制到指定的客户端
scp -r [email protected]:/opt [email protected]:/mnt/
参数 说明
-1 强制scp命令使用协议ssh1
-2 -2 强制scp命令使用协议ssh2
-4 -4 强制scp命令只使用IPv4寻址
-6 -6 强制scp命令只使用IPv6寻址
-B -B 使用批处理模式(传输过程中不询问传输口令或短语)
-C -C 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
-p -p 保留原文件的修改时间,访问时间和访问权限。
-q -q 不显示传输进度条。
-r -r 递归复制整个目录。
-v -v 详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
-c -c cipher 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
-F -F ssh_config 指定一个替代的ssh配置文件,此参数直接传递给ssh。
-i -i identity_file 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
-l -l limit 限定用户所能使用的带宽,以Kbit/s为单位。
-o -o ssh_option 如果习惯于使用ssh_config(5)中的参数传递方式,
-P -P port 注意是大写的P, port是指定数据传输用到的端口号。
-S -S program 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。
FTP 、SFTP 、SCP 都可以用来传输文件,区别主要为
- FTP 基于TCP来传输文件,明文传输用户信息和数据。
- SFTP 基于SSH来加密传输文件,可靠性高,可断点续传。
- SCP 是基于SSH来加密拷贝文件,但要知道详细目录,不可断点续传。
Netflow
介绍
Netflow技术最早是于1996年由思科公司的Darren Kerr和Barry Bruins发明的,并于同年5月注册为美国专利,专利号为6,243,667。Netflow技术首先被用于网络设备对数据交换进行加速,并可同步实现对高速转发的IP数据流(Flow)进行测量和统计。经过多年的技术演进,Netflow原来用于数据交换加速的功能已经逐步由网络设备中的专用ASIC芯片实现,而对流经网络设备的IP数据流进行测量和统计的功能也已更加成熟,并成为了当今互联网领域公认的最主要的IP/MPLS流量分析,统计和计费行业标准。Netflow技术能对IP/MPLS网络的通信流量进行详细的行为模式分析和计量,并提供网络运行的详细统计数据。
NetFlow的版本
-
NetFlow V1:为NetFlow技术的第一个实用版本,在如今的实际网络环境中已经不建议使用。
-
NetFlow V5:增加了对数据流BGP AS信息的支持,是当前主要的实际应用版本。
-
NetFlow V7:思科Catalyst交换机设备支持的一个版本,需要利用交换机的MLS或CEF处理引擎。
-
NetFlow V8:增加了网络设备对NetFlow统计数据进行自动汇聚的功能,大大降低对数据输出的带宽需求。
-
NetFlow V9:一种全新的灵活和可扩展的NetFlow数据输出格式,采用了基于模板的统计数据输出,方便添加需要输出的数据域和支持多种Netflow新功能。
工作原理
数据导入
NetFlow利用标准的交换模式处理数据流的第一个IP包数据,生成NetFlow 缓存
随后进行两大职能:
- 同样的流,直接从缓存读,不走路由表
- 缓存同时也进行了统计
NetFlow使用七元组来区分每一个Flow:
SIP+DIP+SPORT+DPORT +Layer 3 protocol type + TOS byte() + Router or switch interface
源IP地址+源端口号+目的IP地址+目的端口号+协议类+服务种类+输入接口
Netflow通过识别flow的信息,将flow加入到缓存中。随着flow数量的增加,缓存中的表项也在不断增加,所以需要一个缓存维护机制来清理一些过期flow。对flow的超时的指定方式:
- 空闲超过了指定空闲时间长度
- 长连接会话强制超时
- 缓存空间耗尽所触发的强制超时
- TCP FIN/RST触发的超时。
数据导出
Netflow的数据导出是一种使用UDP的主动推送机制。
Netflow封装的格式是header+每个flow的详细记录。
NetFlow用途
利用Netflow技术可以监测网络上的IP Flow信息
IP Flow信息,可以回答用户的下面问题(5W1H):
- who:源IP地址
- when:开始时间、结束时间
- where:从哪:From(源IP,源端口)、到哪:To(目的IP,目的端口)
- what:协议类型,目标IP,目标端口
- how:流量大小,流量包数
- why:基线,阈值,特征
采集到的netflow流量信息可以帮助进行:
- 网络行为分析
- 业务访问情况分析
- 网络规划
- 流量计费
- 病毒检测
- 等等
JMS
介绍
JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的API,绝大多数MOM提供商都对JMS提供支持。也就是java消息操作标准API。
发展历史
出于历史原因,JMS为发送和接收提供了四组可选接口信息。
- JMS 1.0定义了两个特定于域的API,一个用于点对点消息传递(队列)和一个用于发布/订阅(主题)。尽管由于向后的原因,这些仍然是JMS的一部分兼容性它们应该被认为是完全被后来的API所取代。
- JMS 1.1引入了一个新的统一API,它提供了一组可以用于点对点和发布/订阅消息。这里称之为经典API
- JMS 2.0引入了一个简化的API,它提供了经典API的所有特性,但需要更少的接口,使用更简单
- 每个API都提供了一组不同的接口,用于连接JMS提供程序和发送数据和接收消息。但是,它们都共享一组用于表示消息和消息目的地,并提供各种实用程序功能。
所有接口都在javax.jms包中。
JMS组成
JMS Provider(提供者) 实现 JMS 接口规范的消息中间件,也就是 MQ 服务器
JMS Producer(生产者) 创建和发送 JMS 消息的客户端应用
JMS Consumer(消费者) 接收和处理 JMS 消息的客户端应用
JMS Message(消息) 消息由消息头、消息属性和消息体组成
JMS Queue(消息队列) 消息保存的地方,用于点对点的消息模型
JMS Topic(消息主题) 消息保存的地方,用于发布订阅的消息模型
JMS 消息模型
点对点消息模型(Point-to-Point )
消息提供方和消息消费方通过先进先出队列 提供给消息消费者,消息消费者从队列主动拉取数据。

该消息模型的特点:
a、每个消息只有一个消费者,消息一旦被消费,就不在消息队列中了。
b、提供者和消费者之间在时间上没有依赖性,也就是说当提供者发送了消息之后,不管消费者有没有正在运行,它不会影响到消息被发送到队列。
c、每条消息仅会传送给一个消费者。可能会有多个消费者在一个队列中侦听,但是每个队列中的消息只能被队列中的一个消费者所消费。
d、消息存在先后顺序。一个队列会按照消息服务器将消息放入队列中的顺序,把它们传送给消费者。当已被消费时,就会从队列头部将它们删除(除非使用了消息优先级)。
e、消费者在成功接收消息之后需向队列应答成功。
发布/订阅消息模型(Publish/Subscribe)
发布订阅模式是一个基于消息传送的模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,出于离线状态。

该消息模型的特点:
a、每个消息可以有多个消费者。
b、发布者和订阅者之间有时间上的依赖性。针对某个主题的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息,而且只能消费订阅时间之后的消息;
c、JMS允许订阅者创建一个可持久化的订阅。这样,即使订阅者宕机恢复后,也能接收宕机时生产者发布的消息。
d、每条消息都会传送给称为订阅者的多个消息消费者。
f、消息是被推送给消费者的。
JMS API 接口
####经典API

ConnectionFactory 客户端用来创建连接的受管对象;可以通过 JNDI 来查找 ConnectionFactory 对象。
Connection 客户端到 JMS 提供者之间的活动连接。
Session 发送和接收消息的一个单线程上下文
Destination 由 Session 创建的 Queue 或 Topic 对象。
MessageProducer 由 Session创建的对象,用于发送消息到 Queue 或 Topic。
MessageCosumer 由 Session 创建的对象,用于接收 Queue 或 Topic 中的消息。
Message 消费者和生产者之间传送的数据。
MessageListener 消息监听器,消费者注册消息监听器,有消息到达,将调用该接口的 onMessage 方法。
简化 API

简化 API 与传统 API 提供的消息功能是一样的,但是它需要的接口更少、使用更方便。 简化 API 提供的主要接口如下:
ConnectionFactory:客户端用来创建连接的受管对象,传统API也会使用此接口。
JMSContext:客户端到 JMS 提供者之间的活动连接,以及发送和接收消息的一个单线程上下文。
JMSProducer:由 JMSContext 创建的对象,用于发送消息到 Queue 或 Topic。
JMSConsumer:由 JMSContext 创建的对象,用于接收 Queue 或 Topic 中的消息
在简化 API 中,一个 JMSContext 对象封装了传统 API 中 Connection 和 Session 两个对象的行为。
JMS Message
JMS 消息由 消息头、消息属性、消息体 三部分组成。
消息头
消息头中包含了消息的设置信息,例如:投放的目的地(topic、partation)、消息的唯一标识 messageId(一般JMS会自动生成,也可由生产方来主动生成)
JMSDestination 消息发送的目的地,主要有 Queue 和 Topic,它们都是 Destination 的实现。
JMSDeliveryMode:消息传输模式,有两种模式:持久化模式和非持久化模式;持久化的消息在消息服务器宕机后再重启不会丢失,而非持久化的消息则会丢失,可通过将消息设置为持久化来保证消息的可靠性,Queue 中的消息默认是持久化的,Topic 中的消息默认是非持久化的。
JMSExpiration:消息的过期时间,默认永不过期。若给 MessageProducer 对象设置了 timeToLive 属性值或者在调用 MessageProducer.send() 时指定了 timeToLive 的值,则消息将在 timeToLive 之后过期;如果设置 timeToLive 的值为 0,则永不过期,也可以给消息设置 JMSExpiration 属性值指定该消息的过期时间。消息发送后,在消息过期后若还没有被消费则会被清除。
JMSPriority 消息的优先级,有 0-9 十个级别,0-4 是普通消息,5-9 是加急消息。JMS 不要求 MQ 严格按照这十个优先等级发送消息,但必须保证加急消息先于普通消息到达目的地,默认的消息优先级是 4 级。
JMSMessageID 每条消息的唯一标识,默认由 MQ 产生,也可以自定义。
JMSTimestamp 消息发送时的时间。
JMSCorrelationID 关联的消息 ID,通常用在需要回传消息的时候。
JMSReplyTo 消息回复的目的地,其值为一个 Topic 或 Queue, 这个由发送者设置,但是接收者可以决定是否响应。
JMSRedelivered 消息是否重复发送过,如果该消息之前发送过,那么这个属性的值需要被设置为 true;客户端可以根据这个属性的值来确认这个消息是否重复发送过,以避免重复处理。
JMSType 消息类型,包括 TextMessage、BytesMessage、MapMessage、StreamMessage 和 ObjectMessage。
消息体
消息传输的内容
消息属性
消息属性可看作消息头的补充,消息属性按类型可以分为标准属性(JMSX 作为前缀),消息组件自定义的属性(JMS_ 作为前缀),以及应用自定义的属性。自定义的属性不要以前面两种为前缀。标准的JMSX属性如下:

JMS的可靠性
JMS提供了持续化/ack确认机制/事务 来保证消息的可靠性(防止消息丢失,消息的重复消费)
持久化
- 当服务宕机时,数据不丢失,会保存在服务器本地,持久化可以保证消息在未被消费方消费前不丢失。Queue 中的消息默认是持久化的,Topic中的消息默认是非持久化的。
- 消息的持久化可以在两个地方设置:
- a、调用生产者的 MessageProducer.setDeliveryMode() 方法,设置该生产者生产的所有消息的持久化模式,除非单独为某个消息设置了持久化模式
- b、调用消息的 Message.setJMSDeliveryMode(),只设置这一条消息的持久化模式
事务
- acid生产者消费者为了保证多条消息发送保证同步提交和同步消费,可以开启事务功能。
ACK确认机制
1.自动ack消费者自动ack
2.手动ack 需要自己手动提交ack信息
3.运行重复签收,用于可以多消费者签收的消息
ActiveMQ
介绍
ActiveMQ™是最流行的开源,多协议,基于Java的消息服务器。它支持行业标准协议,因此用户可以通过广泛的语言和平台获得客户选择的好处。可以使用C,C ++,Python,.Net等连接。使用无处不在的AMQP协议集成您的多平台应用程序。使用STOMP通过websockets 在Web应用程序之间交换消息 。
官网:http://activemq.apache.org/
使用步骤
1 创建连接工厂
2 创建连接
3 启动连接
4 建立会话
5 创建队列
6 创建生产者
7 创建消息
8 发送消息
9 提交
编写生产者类
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
public class ActiveMQProducter {
public static void main(String[] args) throws Exception{
// 连接工厂
// 使用默认用户名、密码、路径
// 因为:底层实现:final String defaultURL = "tcp://" + DEFAULT_BROKER_HOST + ":" + DEFAULT_BROKER_PORT;
// 所以:路径 tcp://host:61616
//1 创建连接工厂
ActiveMQConnectionFactory connectionFactory = new ActiveMQConnectionFactory();
//2 创建连接
Connection connection = connectionFactory.createConnection();
//3 打开连接
connection.start();
//4 创建会话
//第一个参数:是否开启事务
//第二个参数:消息是否自动确认
Session session = connection.createSession(true, Session.AUTO_ACKNOWLEDGE);
//创建队列
Queue queue = session.createQueue("hello20181119");
//5 创建生产者
MessageProducer producer = session.createProducer(queue);
//6 创建消息
Message message = session.createTextMessage("helloworld");
//7 发送消息
producer.send(message);
//8 关闭消息
session.commit();
producer.close();
session.close();
connection.close();
System.out.println("消息生产成功");
}
}
编写消费者
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
public class ActiveMQConsumer {
public static void main(String[] args) throws Exception {
//创建连接工厂
ActiveMQConnectionFactory connectionFactory = new ActiveMQConnectionFactory();
//创建连接
Connection connection = connectionFactory.createConnection();
//开启连接
connection.start();
//创建会话
/** 第一个参数,是否使用事务
如果设置true,操作消息队列后,必须使用 session.commit();
如果设置false,操作消息队列后,不使用session.commit();
*/
Session session = connection.createSession(true, Session.AUTO_ACKNOWLEDGE);
//创建队列
Queue queue = session.createQueue("hello20181119");
//创建消费者
MessageConsumer consumer = session.createConsumer(queue);
while(true){
//失效时间,如果10秒内没有收到新的消息,说明没有消息存在,此时可以退出当前循环
TextMessage message = (TextMessage) consumer.receive(10000);
if(message!=null){
System.out.println(message.getText());
}else {
break;
}
}
//关闭连接
session.commit();
session.close();
connection.close();
System.out.println("消费结束0");
}
}