【谷粒商城高级篇】Elasticsearch:全文检索
谷粒商城笔记合集
| 分布式基础篇 | 分布式高级篇 | 高可用集群篇 |
|---|---|---|
| ===简介&环境搭建=== | ===Elasticsearch=== | |
| 项目简介与分布式概念(第一、二章) | Elasticsearch:全文检索(第一章) | |
| 基础环境搭建(第三章) | ===商品服务开发=== | |
| ===整合SpringCloud=== | 商品服务 & 商品上架(第二章) | |
| 整合SpringCloud、SpringCloud alibaba(第四、五章) | ===商城首页开发=== | |
| ===前端知识=== | 商城业务:首页整合、Nginx 域名访问、性能优化与压力测试 (第三、四、五章) | |
| 前端开发基础知识(第六章) | 缓存与分布式锁(第六章) | |
| ===商品服务开发=== | ===商城检索开发=== | |
| 商品服务开发:基础概念、三级分类(第七、八章) | 商城业务:商品检索(第七章) | |
| 商品服务开发:品牌管理(第九章) | ||
| 商品服务开发:属性分组、平台属性(第十、十一章) | ||
| 商品服务:商品维护(第十二、十三章) | ||
| ===仓储服务开发=== | ||
| 仓储服务:仓库维护(第十四章) | ||
| 基础篇总结(第十五章) |
一、Elasticsearch - 全文检索⚠️
1.1 介绍
1.1.1 概述
https://www.elastic.co/cn/what-is/elasticsearch/
全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。
他可以快速地存储、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用他

Elatic 的底层是开源库 Lucene。但是,你没法直接用,必须自己写代码调用它的接口,Elastic 是 Lunce 的封装,提供了 REST API 的操作接口,开箱即用
REST API:天然的跨平台
官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
官网中文:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
社区中文:http://doc.codingdict.com/elasticsearch/
1.1.2 新版本改变
-
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch 是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed 最终在Lucene,中的处理方式是一样的。
-
两个不同 type下的两个user_ name, 在ES同-个索引下其实被认为是同一一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同typpe中的相同字段称就会在处理中出现神突的情况,导致Lucene处理效率下降。
-
去掉type就是为了提高ES处理数据的效率。
ES 7.x
URL 中的 type 参数 可选,比如索引一个文档不再要求提供文档类型
ES 8.X
不在支持 URL 中的 type 参数
解决
- 将索引从多类型迁移到单类型,每种类型文档一个独立的索引
- 将已存在的索引下的类型数据,全部迁移到指定位置即可,详见数据迁移
1.2 基本概念
1.1.1 index(索引库)
-
动词:相当于 MySQL 中的 insert;
-
名词:相当于MySQL 中的 DataBase
1.1.2 Type(类型表)
-
在 Index(索引)中,可以定义一个或多个类型
-
类似于 MySQL 中的 Table,每一种类型的数据放在一起
1.1.3 Document(文档记录)
保存在某个索引(index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格式 的,Document 就像是 MySQL 中某个 Table 里面的内容
1.1.4 倒排索引机制

1.3 Docker 安装⚠️
1.2.1 下载镜像
-
存储和检索数据 elasticsearch
[root@tencent ~]# docker pull elasticsearch:7.4.2 7.4.2: Pulling from library/elasticsearch d8d02d457314: Pull complete ... docker.io/library/elasticsearch:7.4.2 -
可视化检索数据 kibana
[root@tencent ~]# docker pull kibana:7.4.2 7.4.2: Pulling from library/kibana d8d02d457314: Already exists bc64069ca967: Pull complete ... docker.io/library/kibana:7.4.2
1.2.2 创建 ElasticSearch 实例
-
修改云服务器安全组开放对应端口、关闭云服务器内部防火墙(systemctl stop firewalld)
-
创建挂载文件夹,修改文件夹访问权限,并配置实例的可访问IP
#创建挂载文件夹 [root@tencent ~]# mkdir -p /mydata/elasticsearch/config [root@tencent ~]# mkdir -p /mydata/elasticsearch/data #修改文件夹访问权限 [root@tencent ~]# chmod -R 777 /mydata/elasticsearch/ #配置实例的可访问IP:注意空格 [root@tencent ~]# echo "http.host: 0.0.0.0" > /mydata/elasticsearch/config/elasticsearch.yml -
启动容器
[root@tencent ~]# docker run -d -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins --name elasticsearch elasticsearch:7.4.2 871aabbc89e051fa0039b609e9ab62545049e49a515ad6cd27bcad0a3ecb828e
1.2.3 创建 Kibana 实例
-
修改云服务器安全组开放对应端口、关闭云服务器内部防火墙(systemctl stop firewalld)
-
启动容器:注意连接自己的 ElasticSearchIP
[root@tencent ~]# docker run -d -p 5601:5601 --restart=always -e ELASTICSEARCH_HOSTS=http://114.132.162.129:9200 --name kibana kibana:7.4.2 b03f6cf5a34d67ba5d3aed9e008f01d9c5d60774fc173296f771859ebe1450f4
1.2.4 创建 nginx 实例
-
修改云服务器安全组开放对应端口、关闭云服务器内部防火墙(systemctl stop firewalld)
-
创建挂载文件夹,修改文件夹访问权限
[root@tencent ~]# mkdir -p /mydata/nginx [root@tencent ~]# chmod -R 777 /mydata/nginx/ -
随便启动一个 nginx容器实例,只是为了复制出配置文件
[root@tencent ~]# docker run -d -p 80:80 --name nginx nginx:1.10 Unable to find image 'nginx:1.10' locally 1.10: Pulling from library/nginx 6d827a3ef358: Pull complete ... Status: Downloaded newer image for nginx:1.10 80949d4515be6853587d3adab6ffbdf9e549f0d2c5744accc0c30406af7b5bda -
将 nginx容器实例 内的配置文件拷贝到配置文件将要挂载的目录下: /mydata/nginx/conf/
#拷贝配置文件夹 [root@tencent ~]# docker cp nginx:/etc/nginx /mydata/nginx/ #将拷贝的配置文件夹重命名 [root@tencent ~]# mv /mydata/nginx/nginx /mydata/nginx/conf -
删除当前 nginx容器实例
[root@tencent ~]# docker rm -f nginx nginx -
启动容器
[root@tencent ~]# docker run -d -p 80:80 --restart=always -v /mydata/nginx/html:/usr/share/nginx/html -v /mydata/nginx/logs:/var/log/nginx -v /mydata/nginx/conf/:/etc/nginx --name nginx nginx:1.10 a18002f9e5f28109179fa3793668a674e5d3beeceae704c2c13ae48b3547dfd4
1.4 基本API
1.4.1 _cat
-
查看所有节点
[root@tencent ~]# curl localhost:9200/_cat/nodes 127.0.0.1 16 98 0 0.25 0.12 0.10 dilm * 871aabbc89e0 -
查看 es 健康状况
[root@tencent ~]# curl localhost:9200/_cat/health 1672815803 07:03:23 elasticsearch green 1 1 2 2 0 0 0 0 - 100.0% -
查看主节点
[root@tencent ~]# curl localhost:9200/_cat/master vjHGwsKwTOKrDuosASba3A 127.0.0.1 127.0.0.1 871aabbc89e0 -
查看所有索引(show databases;)
[root@tencent ~]# curl localhost:9200/_cat/indices green open .kibana_task_manager_1 NrHQV5ylQM-NMHUa7NFkfg 1 0 2 0 46.2kb 46.2kb green open .kibana_1 Cl7QiHVHTTK3crkAzTd1Yw 1 0 8 0 32kb 32kb
1.4.2 POST、PUT
乐观锁修改:?if_seq_no=4&if_primary_term=1
-
PUT:必须带id
- 新增:不存在该id指定的记录
- 修改:已经存在该id指定的记录
PUT 114.132.162.129:9200/customer/external/1 { "name":"John Doe" } -
POST:可以不带id
-
不带id:总是新增
-
带id
- 新增:不存在该id指定的记录
- 修改:已经存在该id指定的记录
#总是新增 POST 114.132.162.129:9200/customer/external/ { "name":"John Doe" } #新增、修改 POST 114.132.162.129:9200/customer/external/1 { "name":"John Doe" } -
1.4.3 查询
GET 114.132.162.129:9200/customer/external/1
结果:
{
"_index": "customer", // 在那个索引
"_type": "external", // 在那个类型
"_id": "1", // 记录id
"_version": 8, // 版本号
"_seq_no": 11, // 并发控制字段,每次更新就会+1,用来做乐观锁
"_primary_term": 1, // 同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": { // 真正的内容
"name": "John Doe"
}
}
1.4.4 更新
-
PUT:不能使用_update
-
POST
-
带 _update:会对比源文档数据
POST 114.132.162.129:9200/customer/external/1/_update { "doc":{ "name":"hi" } } -
不带 _update:不会对比源文档数据
-
使用场景
- 大并发更新:不带update
- 大并发查询并偶尔更新:带update
1.4.5 删除
#删除文档
DELETE customer/external/1
#删除索引
DELETE customer
1.4.6 批量API:bulk
bulk API 按顺序执行所有的action (动作)。如果一个单个的动作因任何原因而失败,它将继续处理它后面剩余的动作。当bulkAPI 返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是不是失败了。
-
指定 索引+类型
POST customer/external/_bulk {"index":{"_id":"1"}} {"name":"John Doe"} {"index":{"_id":"2"}} {"name":"John Doe"} -
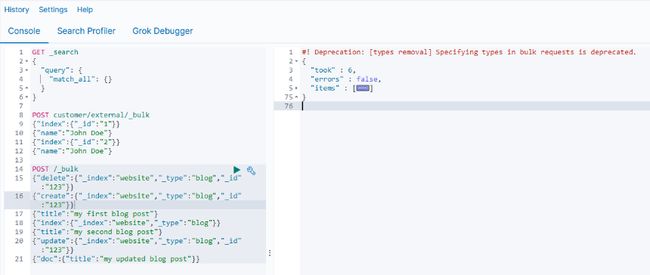
不指定 索引+类型
POST /_bulk {"delete":{"_index":"website","_type":"blog","_id":"123"}} {"create":{"_index":"website","_type":"blog","_id":"123"}} {"title":"my first blog post"} {"index":{"_index":"website","_type":"blog"}} {"title":"my second blog post"} {"update":{"_index":"website","_type":"blog","_id":"123"}} {"doc":{"title":"my updated blog post"}}
1.4.7 导入样本测试数据
官方为我们准备了一份顾客银行账户信息虚构的 JSON 文档样本,每个用户都有下列的 schema (模式):https://github.com/elastic/elasticsearch/tree/7.4/docs/src/test/resources/accounts.json
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "[email protected]",
"city": "Brogan",
"state": "IL"
}
导入测试数据
POST /bank/account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"[email protected]","city":"Brogan","state":"IL"}
...
1.5 存储:Mapping
1.5.1 概述
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/mapping.html
Mapping 是用来定义一个文档(document),以及他所包含的属性(field)是如何存储索引的,比如使用 mapping来定义的:
- 哪些字符串属性应该被看做全文本属性(full text fields)
- 那些属性包含数字,日期或者地理位置
- 文档中的所有属性是能被索引(_all 配置)
- 日期的格式
- 自定义映射规则来执行动态添加属性
自动猜测的映射类型

1.5.2 字段类型
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/mapping-types.html
对象数组
使用Nested类型。否则 Es 会进行扁平化处理,检索过程中会有问题。
多字段
通常用于为不同目的用不同的方法索引同一个字段。例如,string 字段可以映射为一个 text 字段用于全文检索,同样可以映射为一个 keyword 字段用于排序和聚合。另外,你可以使用 standard analyzer,english analyzer,french analyzer 来索引一个 text 字段
这就是 muti-fields 的目的。大多数的数据类型通过 fields 参数来支持 muti-fields。
1.5.3 创建映射
PUT /my_index
{
"mappings": {
"properties": {
"age":{
"type": "integer"
},
"name":{
"type": "keyword"
},
"email":{
"type": "text"
}
}
}
}
1.5.4 查看映射
GET /my_index/_mapping
1.5.5 添加映射
PUT /my_index/_mapping
{
"properties": {
"id":{
"type": "keyword",
"index":false
}
}
}
1.5.6 更新映射
对于已经存在的映射字段,我们不能更新,更新必须创建新的索引进行数据迁移
1.6 检索
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/getting-started-search.html
1.6.1 SearchAPI
ES 支持两种基本方式检索:
-
一个是通过使用 REST request URL,发送搜索参数,(uri + 检索参数)
GET /bank/_search?q=*&sort=account_number:asc -
另一个是通过使用 REST request body 来发送他们,(uri + 请求体)
GET /bank/_search { "query": { "match_all": {} }, "sort": [ { "account_number": "asc" } ] }
HTTP 客户端工具(POSTMAN),get请求不能携带请求体,我们变为 post也是一样的 我们 POST 一个 JSON风格的查询请求体到 _search API
需要了解,一旦搜索结果被返回,ES 就完成了这次请求的搜索,并且不会维护任何服务端的资源或者结果的 cursor(游标)
响应结果解释
{
"took" : 4, //运行查询所用的时间,以毫秒为单位
"timed_out" : false, //搜索请求是否超时
"_shards" : { //搜索了多少分片,以及有多少分片成功、失败或被跳过的明细。
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000, //找到了多少匹配的文档
"relation" : "eq"
},
"max_score" : null, //找到的最相关文档的分数
"hits":[
{
"_index" : "bank",
"_type" : "account",
"_id" : "0",
"_score" : null, //文档的相关性得分(使用时不适用`match_all`)
"_source" : {...},
"sort" : [ //文档的排序位置(不按相关性分数排序时)
0
]
},
...
]
}
}
1.6.2 QueryDSL
1)基本语法格式
ES 提供了一个可以执行查询的 Json 风格的 DSL (domain-specifig langurage 领域特定语言),这个被称为 Query DSL ,该查询语言非常全面,并且刚开始的时候优点复杂,真正学好对他的方法是从一些基础的示例开始的
-
一个查询语句 的典型结构
{ QUERY_NAME:{ ARGUMENT:VALUE, ARGUMENT:VALUE..... } }GET /bank/_search { "query": { //定义如何查询 "match_all": {} //查询类型【代表查询所有的数据】,可以在es的 query 中组合非常多的查询类型完成复杂查询 } } -
如果针对某个字段,那么它的结构如下
{ QUERY_NAME:{ FIELD_NAME:{ ARGUMENT:VALUE, ARGUMENT:VALUE..... } } }GET /bank/_search { "query": { "match_all": {} }, "sort": [ //多字段排序,会在前序字段相等时后续字段继续排序,否则以前序为准 { "account_number": { "order": "desc" } } ], "from": 10, //完成分页功能 "size": 10 //完成分页功能 }
2)返回部分字段
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [ //多字段排序,会在前序字段相等时后续字段继续排序,否则以前序为准
{
"account_number": {
"order": "desc"
}
}
],
"from": 10, //完成分页功能
"size": 10, //完成分页功能
"_source": [ //指定返回的字段
"balance",
"firstname"
]
}
3)match【文本匹配】
- 基本类型:精准匹配
- 文本类型:需要进行模糊匹配。全文检索按照评分进行排序,会对检索条件进行分词匹配
GET /bank/_search
{
"query": {
"match": {
"address": "mill lane"
}
}
}
精确匹配
GET /bank/_search
{
"query": {
"match": {
"address.keyword": "mill lane"
}
}
}
4)match_phrase【不分词匹配】
将需要匹配的值当成一个整体单词(不分词)进行检索
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "mill lane"
}
}
}
5)multi_match【字段匹配】
会进行分词匹配
GET bank/_search
{
"query":{
"multi_match": {
"query": "mill Road",
"fields": ["address","city"]
}
}
}
6)bool 【复合查询】
bool 用来做复合查询
复合语句可以合并 任何 其他嵌套语句,包括复合语句,了解这一点是很重要的,这就意味着,复合语句之间可以互相嵌套,可以表达式非常复杂的逻辑
- must:必须出现在匹配的文档中,并将有助于得分
- must_not:不能出现在匹配的文档中
- should:满足将有助于得分,不满足也可以
- 注意:在复合查询中,如果不包含 must、filter 子句,一个或多个 should 子句必须有相匹配的文件。匹配 should 条件的最小数可通过设置 minimum_should_match 参数。
GET /bank/_search
{
"query": {
"bool": {
"must": [ //必须满足
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [ //必须不满足
{
"match": {
"age": "18"
}
}
],
"should": [ //满足最好,不满足也可以
{
"match": {
"lastname": "Wallace"
}
}
]
}
}
}

7)filter【结果过滤】
不计算相关性得分。为了不计算分数 ES 会自动检查场景并且优化查询的执行
GET /bank/_search
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
8)term【数值匹配】
和 match 一样,匹配某个属性的值
- match:全文检索字段用
- term:非text字段匹配用
GET bank/_search
{
"query":{
"match_phrase": {
"address": "789 Madison Street"
}
}
}
9)aggregations【执行聚合】
聚合提供了从数据分组和提取数据的能力,最简单的聚合方法大致等于 SQL GROUP BY 和 SQL 聚合函数,在 ES 中,你有执行搜索返回 hits (命中结果) 并且同时返回聚合结果,把一个响应中的所有 hits(命中结果)分隔开的能力,这是非常强大有效的,你可以执行查询和多个聚合,并且在一个使用中得到各自的(任何一个的)返回结果,使用一次简洁简化的 API 来避免网络往返
-
搜索address中包含mill的所有人的年龄分布以及平均年龄
GET /bank/_search { "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "avgAgg":{ "avg": { "field": "age" } } }, "size": 0 } -
按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET /bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 }, "aggs": { "avgBalance": { "avg": { "field": "balance" } } } } }, "size": 0 } -
查出所有年龄分布,并且这些年龄段中M的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资
GET /bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 }, "aggs": { "ageGenderAgg": { "terms": { "field": "gender.keyword", "size": 10 }, "aggs": { "ageGenderBalanceAgg": { "avg": { "field": "balance" } } } }, "ageBalanceAgg":{ "avg": { "field": "balance" } } } } }, "size": 0 }
1.7 分析:分词
1.7.1 概述
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/analysis.html
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立的单词),然后输出 token 流
列如,witespace tokenizer 遇到的空白字符时分割文本,它会将文本 “Quick brown fox” 分割为 【Quick brown fox】
该 tokenizer (分词器)还负责记录各个term (词条)的顺序或 position 位置(用于phrase短语和word proximity词近邻查询),以及
term (词条)所代表的原始 word (单词)的start(起始)和end (结束)的 character offsets (字符偏移量) (用于 高亮显示搜索的内容)。
Elasticsearch 提供了很多内置的分词器,可以用来构建custom analyzers(自定义分词器)
1.7.2 安装 ik 分词器
-
下载插件包,版本需要对应:https://github.com/medcl/elasticsearch-analysis-ik/releases?page=8
-
将插件包解压到 ik文件夹 中
-
将 ik文件夹 上传至 elasticsearch容器实例 挂载的插件目录下:/mydata/elasticsearch/plugins/

-
验证 ik分词器 插件是否安装成功

-
重启 elasticsearch容器实例

注意:不能用默认的 elasticsearch-plugin.install xxx.zip 进行自动安装
1.7.3 测试
-
标准分词器:standard
POST _analyze { "analyzer": "standard", "text": "我是中国人" } -
ik分词器:ik_smart
POST _analyze { "analyzer": "ik_smart", "text": "我是中国人" } -
ik分词器:ik_max_word
{ "analyzer": "ik_max_word", "text": "我是中国人" }
1.7.4 自定义词库
将自己扩展的字典部署到 nginx容器实例
-
在 nginx容器实例 的资源目录下创建属于 elasticsearch 的资源文件夹
#注意,此处目录已于nginx容器实例进行挂载 [root@tencent ~]# mkdir /mydata/nginx/html/es -
在 elasticsearch资源文件夹 下创建分词字典文件,并在字典文件中添加单词
[root@tencent ~]# touch /mydata/nginx/html/es/fenci.txt [root@tencent ~]# vim /mydata/nginx/html/es/fenci.txt 乔碧罗 尚硅谷 -
修改 elasticsearch插件ik 的配置文件:IKAnalyzer.cfg.xml
[root@tencent ~]# vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://114.132.162.129/es/fenci.txt</entry> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> -
重启 elasticsearch容器实例
[root@tencent ~]# docker restart elasticsearch elasticsearch
测试
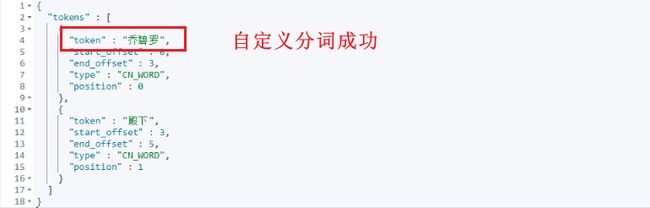
POST _analyze
{
"analyzer": "ik_max_word",
"text": "乔碧罗殿下"
}
1.8 数据迁移
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/docs-reindex.html
-
创建新的索引,并指定好正确的映射
PUT /new_bank { "mappings" : { "properties" : { "account_number" : { "type" : "long" }, "address" : { "type" : "text" }, "age" : { "type" : "keyword" }, "balance" : { "type" : "keyword" }, "city" : { "type" : "keyword" }, "email" : { "type" : "keyword" }, "employer" : { "type" : "text" }, "firstname" : { "type" : "keyword" }, "gender" : { "type" : "keyword" }, "lastname" : { "type" : "text" }, "state" : { "type" : "keyword" } } } } -
数据迁移
POST _reindex { "source": { "index": "bank" }, "dest": { "index": "new_bank" } } ## 将旧索引的 type 下的数据进行迁移 POST _reindex { "source": { "index":"twitter", "type":"tweet" }, "dest":{ "index":"twweets" } } -
验证数据迁移是否成功
GET /new_bank/_search
1.9 SpringBoot整合⚠️
1.9.1 概述
9300:TCP
-
Spring-data-elasticsearch:transport-api.jar
-
SpringBoot版本不同,
transport-api.jar不同,不能适配 es 版本 -
7.x 已经不在适合使用,8 以后就要废弃
9200:HTTP
-
JestClient 非官方,更新慢
-
RestTemplate:默认发送 HTTP 请求,ES很多操作都需要自己封装、麻烦
-
HttpClient:同上
-
Elasticsearch - Rest - Client:官方RestClient,封装了 ES 操作,API层次分明
最终选择 Elasticsearch - Rest - Client (elasticsearch - rest - high - level - client)
1.9.2 创建微服务:bilimall-search⚠️
-
创建 bilimall-search 模块

-
修改maven配置文件 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.1.8.RELEASEversion> <relativePath/> parent> <groupId>cn.lzwei.bilimallgroupId> <artifactId>bilimall-searchartifactId> <version>0.0.1-SNAPSHOTversion> <name>bilimall-searchname> <description>检索服务description> <properties> <java.version>17java.version> <spring-cloud.version>Greenwich.SR3spring-cloud.version> properties> <dependencies> <dependency> <groupId>cn.lzwei.bilimallgroupId> <artifactId>bilimall-commonartifactId> <version>0.0.1-SNAPSHOTversion> <exclusions> <exclusion> <groupId>com.baomidougroupId> <artifactId>mybatis-plus-boot-starterartifactId> exclusion> exclusions> dependency> dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-dependenciesartifactId> <version>${spring-cloud.version}version> <type>pomtype> <scope>importscope> dependency> dependencies> dependencyManagement> project> -
创建配置文件 application.yaml:配置nacos注册中心
spring: cloud: nacos: discovery: server-addr: 114.132.162.129:8848 #配置nacos注册中心 application: name: bilimall-search #配置服务名 jackson: date-format: yyyy-MM-dd HH:mm:ss #统一日期格式 server: port: 13000 #配置服务端口号 -
在nacos配置中心创建新的命名空间:search
-
创建配置文件 bootstrap.properties:配置nacos配置中心
spring.application.name=bilimall-search spring.cloud.nacos.config.server-addr=114.132.162.129:8848 spring.cloud.nacos.config.namespace=01a1f653-59fe-4267-b01c-228b872a52f6 -
修改主启动类:开启服务注册与发现功能,添加注解
@EnableDiscoveryClient
1.9.3 整合⚠️
-
导入 rest-high-level-client 依赖,修改 SpringBoot:2.1.8.RELEASE 对 elasticsearch 的版本管理
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-getting-started-maven.html
<properties> <java.version>17java.version> <elasticsearch.version>7.4.2elasticsearch.version> <spring-cloud.version>Greenwich.SR3spring-cloud.version> properties> <dependency> <groupId>org.elasticsearch.clientgroupId> <artifactId>elasticsearch-rest-high-level-clientartifactId> <version>7.4.2version> dependency> -
添加 rest-high-level-client 配置类,将客户端对象注入spring容器中,添加请求配置项:cn/lzwei/bilimall/search/config/BilimallElasticsearchConfig.java
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-getting-started-initialization.html
@Configuration public class BilimallElasticsearchConfig { @Bean public RestHighLevelClient restHighLevelClient(){ Node node = new Node(new HttpHost("114.132.162.129", 9200, "http")); RestHighLevelClient restHighLevelClient = new RestHighLevelClient(RestClient.builder(node)); return restHighLevelClient; } } -
在 rest-high-level-client 配置类中添加请求配置项:cn/lzwei/bilimall/search/config/BilimallElasticsearchConfig.java
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-low-usage-requests.html#java-rest-low-usage-request-options
@Configuration public class BilimallElasticsearchConfig { public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); // builder.addHeader("Authorization", "Bearer " + TOKEN); // builder.setHttpAsyncResponseConsumerFactory( // new HttpAsyncResponseConsumerFactory // .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024)); COMMON_OPTIONS = builder.build(); } } -
测试输入spring是否成功
@RunWith(SpringRunner.class) @SpringBootTest public class BilimallSearchApplicationTests { @Resource RestHighLevelClient restHighLevelClient; @Test public void test(){ System.out.println(restHighLevelClient); } }#整合成功! org.elasticsearch.client.RestHighLevelClient@48c5698
1.9.4 测试:保存数据
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-document-index.html

-
BilimallSearchApplicationTests:索引一条数据
@RunWith(SpringRunner.class) @SpringBootTest public class BilimallSearchApplicationTests { @Resource RestHighLevelClient restHighLevelClient; @Test public void testIndex() throws IOException { IndexRequest request = new IndexRequest("test_index"); request.id("1"); Person person = new Person(); person.setAge(22); person.setGender("男"); person.setName("张三"); String jsonString = JSON.toJSONString(person); request.source(jsonString, XContentType.JSON); IndexResponse indexResponse = restHighLevelClient.index(request, BilimallElasticsearchConfig.COMMON_OPTIONS); } @Data class Person{ private String name; private Integer age; private String gender; } }
1.9.5 测试:检索数据
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-search.html
搜索blank索引中address包含mill的所有人的年龄分布以及平均年龄
-
创建用于接收数据的实体类:cn/lzwei/bilimall/search/entries/Account.java
@Data @ToString public class Account { private int account_number; private int balance; private String firstname; private String lastname; private int age; private String gender; private String address; private String employer; private String email; private String city; private String state; } -
编写数据检索测试方法:cn/lzwei/bilimall/search/BilimallSearchApplicationTests.java
@RunWith(SpringRunner.class) @SpringBootTest public class BilimallSearchApplicationTests { @Resource RestHighLevelClient restHighLevelClient; //检索数据:搜索blank索引中address包含mill的所有人的年龄分布以及平均年龄 @Test public void testSearch() throws IOException { //1.创建搜索请求 SearchRequest searchRequest = new SearchRequest(); //2.设置索引 searchRequest.indices("bank"); //3.创建搜索条件 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //3.1、包含mill的所有人 sourceBuilder.query(QueryBuilders.matchQuery("address","mill")); //3.2、按年龄分布 sourceBuilder.aggregation(AggregationBuilders.terms("ageAgg").field("age").size(10)); //3.3、求平均年龄 sourceBuilder.aggregation(AggregationBuilders.avg("avgAgg").field("age")); //4.设置搜索条件 searchRequest.source(sourceBuilder); //5.开始搜索 SearchResponse response = restHighLevelClient.search(searchRequest, BilimallElasticsearchConfig.COMMON_OPTIONS); //6.获取返回的数据 SearchHit[] hits = response.getHits().getHits(); for (SearchHit hit : hits) { String string = hit.getSourceAsString(); Account account = JSON.parseObject(string, Account.class); System.out.println(account); } //7.处理聚合结果 Aggregations aggregations = response.getAggregations(); //7.1、年龄分布情况 Terms ageAgg = aggregations.get("ageAgg"); for (Terms.Bucket bucket : ageAgg.getBuckets()) { Long key = (Long) bucket.getKey(); Long docCount = bucket.getDocCount(); System.out.printf("年龄%d的有%d人",key,docCount); System.out.println(); } //7.2、平均年龄 Avg avgAgg = aggregations.get("avgAgg"); double value = avgAgg.getValue(); System.out.printf("平均年龄为%f",value); } }