Kubernetes 学习总结(42)—— Kubernetes 之 pod 健康检查详解
Kubernetes 入门
回想 2017 年刚开始接触 Kubernetes 时,碰到 Pod一直起不来的情况,就开始抓瞎。后来渐渐地掌握了一些排查方法之后,这种情况才得以缓解。随着时间推移,又碰到了问题。有一天在部署某个 springboot 微服务时,在开发测试环境部署了好多次,只有几次能成功启动,大部分的部署未能成功启动。但是生产环境却每次都能成功部署。当时这个问题困扰了我很久。由于应用启动时间较长,但是只配置了存活探针,没有配置启动探针。再加上存活探针配置的整体时间又太短了,每台机器的性能又不同,所以导致有时候能启动成功,有时候启动失败。现在想来也是蛮有意思的。要想 Kubernetes 里每个服务的可用性更高,那么对 Pod 的健康检查是少不了的。
Pod 生命周期
谈健康检查之前,首先得一起回顾下 Pod 的生命周期 或者 说是 Pod 的状态。Pod 的生命周期,从 Pending 状态开始, 如果 Pod 中至少有一个应用容器正常启动,则进入 Running 状态,之后,如果 Pod 中的容器正常退出则进入 Succeeded 状态,如果 Pod 中的容器非正常终止则进入 Failed 状态。
Pending 状态:此时 Pod 已经被 K8S 接受并且创建,但是 Pod 内还没有容器被创建,这个过程包括:等待 Pod 被调度的时间、下载镜像的时间。
Running 状态:此时 Pod 已经运行在某个节点上,Pod 内所有容器都已经创建,并且有容器处于如下状态:运行状态、正在启动状态 或 正在重启状态。
Succeeded 状态:此时 Pod 内所有容器都成功执行并且退出。
Failed 状态:此时 Pod 内所有容器都已终止,但是有容器是非正常终止的。
Unknown 状态:无法获取 Pod 状态,通常是因为 Pod 与所在主机通信失败,也可能是别的原因。
重启策略
Pod 的重启是由该 Pod 所处的 Node 节点上的 kubelet 进行判断和控制的。kubelet 会根据重启策略进行相应操作。Pod 的重启策略有 3 个:Always、OnFailure、Never,默认是 Always。
Always:重启策略是 Always 时,那么当容器运行状态是失效时,kubelet 会自动重启该容器,比如:存活探针检测到应用不健康了,就会自动重启 Pod。
OnFailure:重启策略是 OnFailure 时,那么当容器是 Failed 状态时,kubelet 会自动重启该容器。
Never:不论容器运行状态怎样,kubelet 都不会重启该容器。
健康检查
健康检查功能可以保障应用的可用性,以及控制何时可对外的访问。Kubernetes 有 3 种检查探针:LivenessProbe 存活探针、ReadinessProbe 就绪探针、StartupProbe 启动探针。
LivenessProbe 存活探针:判断容器是否存活(Running 状态),如果存活探针检测到容器不健康,则 kubelet 将 kill 掉该容器,并根据容器的重启策略做相应的处理。
ReadinessProbe 就绪探针:判断容器是否可用(Ready 状态),达到 Ready 状态的 Pod 才可以接收请求。kubelet 使用就绪探针检测容器什么时候可以接受请求。
StartupProbe 启动探针:某些应用启动比较慢,例如某个大的单体应用启动时间长达 3 分钟,此时如果只使用存活探针或者就绪探针,很可能应用还没起来,就被 kill 掉了。这种情况可以通过
启动探针来解决。如果配置了启动探针,在存活探针和就绪探针成功之前不会重启容器。说白了就是只要配置了启动探针,那么在应用没成功启动之前,存活探针和就绪探针就不生效。
以上 3 种探针,每种都有 3 种实现方式:
ExecAction:在容器内运行一个命令,如果该命令的返回码为 0,则说明容器是健康的。
TCPSocketAction:通过容器的 IP 地址和端口号进行 TCP 检查,如果能够建立 TCP 连接,则说明容器是健康的。
HTTPGetAction:通过容器的 IP 地址、端口号以及路径,发起 HTTP 请求,如果 HTTP 响应的状态码大于等于 200 且小于 400,则说明容器是健康的。
在部署Java微服务应用时,我一般选用HTTPGetAction方式。
如何选择探针
既然有 3 种探针,那么如何选择呢?
如果你希望容器在检测到失败时,让它被 kill 掉并且自动重启,那就选择存活态探针。
如果你希望在检测成功时 Pod 才能接受请求,那就需要就绪态探针。如果某个应用 A 依赖 应用 B 的启动才能接受请求,那也需要就绪探针。
如果某个应用启动时间较长,那就需要加入启动探针。
成年人的世界不做选择题,3个字,全都要,比如:应用场景是 Spring 微服务时,3 种探针其实都会用上。一个应用启动分 3 个阶段:开始启动 → 成功启动(存活) → 可对外访问。那对应的探针使用顺序为:启动探针 → 存活探针 → 就绪探针。如下图:
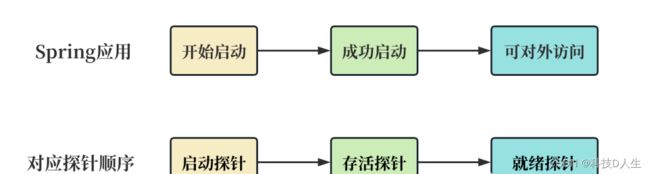
如果只选择存活探针,就很尴尬:
如果配置的存活检测时间太短,那么碰到启动慢的应用,就彻底起不来了,因为应用还没起来就被 kill 掉了。
如果配置的存活检测时间太长,那么应用真到了出现问题的时候,又无法及时被重启,从而影响了整体的可用性。
如果不配置就绪探针的话,也很尴尬:
- 比如有的场景下本身应用起来了,但是依赖的应用还没起来,那么此时还无法对外提供访问能力,此时就不能让请求流量进来。
所以不做选择题,全都要,需要在每个阶段用上对应的探针。
实战
6.1、模拟不健康的应用场景
编排 yaml
比如:对 Pod 进行存活检测,30S 之后,如果不存活则 kill 掉,然后重启。
apiVersion: v1
kind: Pod
metadata:
name: pod-lifecycle
namespace: demo
labels:
app: pod-lifecycle
spec:
containers:
- name: pod-lifecycle
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
# 等待5秒执行第一次探测
initialDelaySeconds: 5
# 探针连续失败了 3 次之后,K8S认为检查已失败,然后触发重启
failureThreshold: 3
# 每5秒执行一次存活探测
periodSeconds: 5
可以看到Pod被重启多次


排查异常
出现问题时也不用慌,可以通过 kubectl get pods -n demo -o wide 和kubectl describe pod pod-lifecycle -n demo 排查。可以清晰的看到异常的原因:存活检查失败。
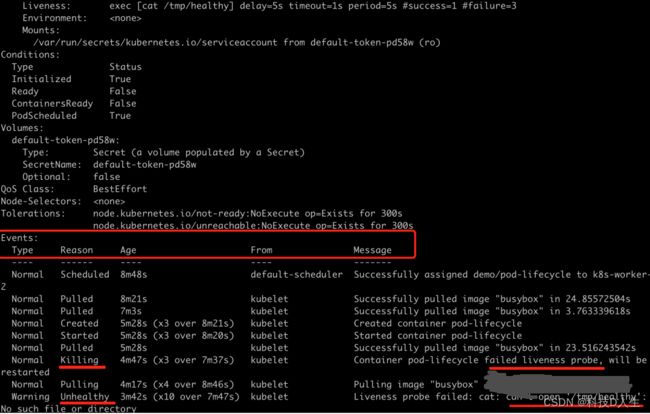
6.2、模拟启动慢的应用
编排 yaml
比如:对 Pod 进行存活检测,30S 之后,如果不存活则kill掉,然后重启。由于模拟了启动比较耗时,所以在容器还未成功启动,就直接被kill掉了,紧接着反复被kill掉。
apiVersion: v1
kind: Pod
metadata:
name: pod-lifecycle-2
namespace: demo
labels:
app: pod-lifecycle-2
spec:
containers:
- name: pod-lifecycle-2
image: busybox
args:
- /bin/sh
- -c
- sleep 20; touch /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
# 等待5秒执行第一次探测
initialDelaySeconds: 5
# 探针连续失败了 2 次之后,K8S认为检查已失败,然后触发重启
failureThreshold: 2
# 每5秒执行一次存活探测
periodSeconds: 5
执行 yaml 之后,可以看到,Pod 重复这样的动作:健康检查失败被重启。

引入 startupProbe 解决此问题
apiVersion: v1
kind: Pod
metadata:
name: pod-lifecycle-3
namespace: demo
labels:
app: pod-lifecycle-3
spec:
containers:
- name: pod-lifecycle-3
image: busybox
args:
- /bin/sh
- -c
- sleep 20; touch /tmp/healthy; sleep 600
startupProbe:
exec:
command:
- cat
- /tmp/healthy
# 等待5秒执行第一次探测
initialDelaySeconds: 5
# 探针连续失败了 10 次之后,K8S认为检查已失败,然后触发重启
failureThreshold: 5
# 每5秒执行一次存活探测
periodSeconds: 5
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
# 等待5秒执行第一次探测
initialDelaySeconds: 5
# 探针连续失败了 2 次之后,K8S认为检查已失败,然后触发重启
failureThreshold: 2
# 每5秒执行一次存活探测
periodSeconds: 5
总结
要想 Kubernetes 里每个服务的可用性更高,那么对 Pod 的健康检查是少不了的。本文重点如下:
Pod 生命周期:
Pending、Running、Succeeded或Failed、UnKnown。Pod 重启策略:
Always、OnFailure、Never。3 种探针类型:
启动探针、存活探针、就绪探针。如何选择探针:一般情况下
全都要。排查 Pod 问题:搭配使用
kubectl get pods -n demo -o wide和kubectl describe pods webapp -n demo。