MySQL中的索引
目录
目录
目录
索引概述-->
介绍--->
优缺点--->
索引结构-->
编辑
存储引擎支持情况--->
BTree--->
B+Tree--->
Hash--->
Hash特点--->
思考题
索引分类-->
InnoDB存储引擎中--->
聚集索引--->
二级索引--->
执行过程--->
思考题
索引语法-->
代码示范--->
SQL性能分析-->
SQL执行频率--->
慢日志查询--->
代码演示--->
profile详情--->
代码演示--->
explain执行计划-->
代码演示--->
索引使用-->
验证索引效率--->
代码示范--->
最左前缀法则--->
代码示范--->
范围查询--->
代码示范--->
索引失效情况--->
索引失效情况一--->
代码示范--->
索引失效情况二--->
代码示范--->
SQL提示--->
代码示范--->
覆盖索引&回表查询--->
代码示范--->
前缀索引--->
代码示范--->
工作流程--->
单列索引和联合索引--->
代码示范--->
联合索引查询流程
索引设计原则--->
总结
索引概述-->
介绍--->
优缺点--->


索引结构-->
存储引擎支持情况--->
BTree--->
每当节点到5个Key时,中间值向上分裂,左边小于中间值,右边大于中间值
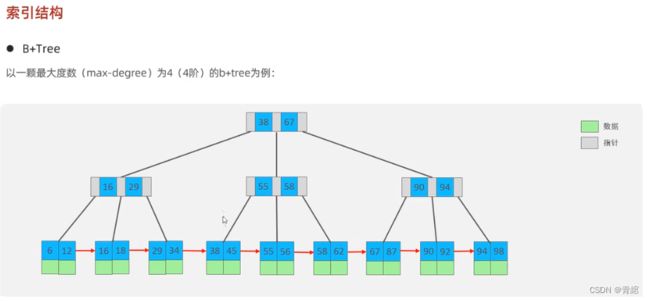
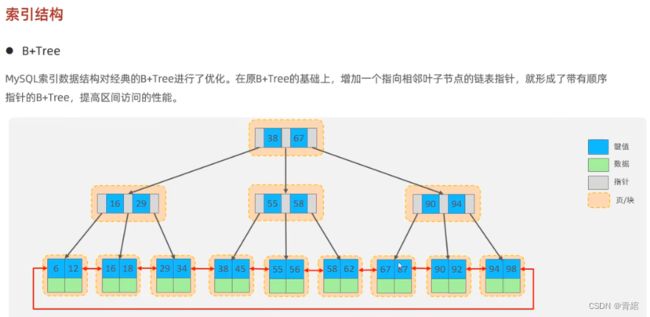
B+Tree--->
MySQL优化处理--->
BTree的基础上,分裂的同时将本身放在叶子节点形成链表,左边小于中间值,右边大于等于中间值
Hash--->
Hash特点--->
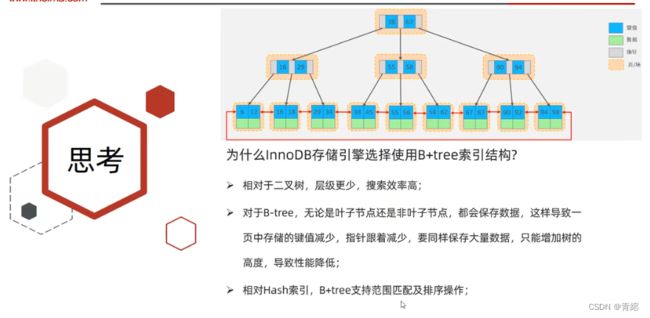
思考题





索引分类-->
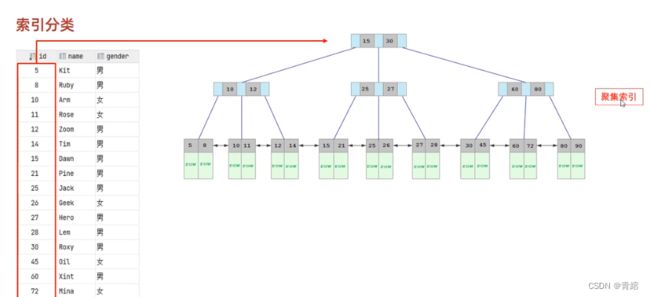
InnoDB存储引擎中--->
聚集索引--->
此处叶子节点row存放的就是每一行的数据
二级索引--->
此处叶子节点存放id
执行过程--->
先在二级索引中,拿'Arm与Lee'比较,小于'Lee',继续找左边
与'Geek'比较,小于'Geek',继续找左边
找到'Arm'存储的id为10
此时在聚集索引中再通过id=10找到对应的行数据返回
这样的查询方式也叫回表查询
思考题
解答-->
select * from user where id = 10;效率高
原因是直接进行聚集索引查询,省去了二级索引的查询
高度每+1,key = 原key * 1171 * 16






索引语法-->
代码示范--->
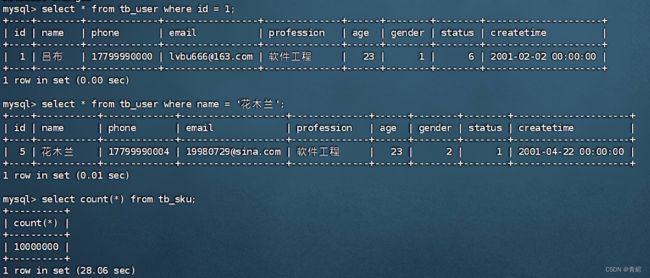
-- 创建数据库 CREATE DATABASE IF NOT EXISTS itcast DEFAULT CHARSET utf8mb4 ; use itcast; -- 准备表和数据 id为主键 CREATE TABLE tb_user( id int primary key auto_increment COMMENT 'id', name varchar(10) COMMENT '姓名', phone char(11) COMMENT '电话', email varchar(20) COMMENT '邮箱', profession varchar(10) COMMENT '专业', age int COMMENT '年龄', gender int COMMENT '性别', status int COMMENT '状态', createtime DATETIME COMMENT '入职时间' ) COMMENT '用户表'; INSERT INTO tb_user VALUES (1,'吕布','17799990000','[email protected]','软件工程',23,1,6,'2001-02-02 00:00:00'), (2,'曹操','17799990001','[email protected]','通讯工程',33,1,6,'2001-03-05 00:00:00'), (3,'赵云','17799990002','177999908139.com','英语',34,1,2,'2002-03-02 00:00:00'), (4,'孙悟空','17799990003','[email protected]','工程造价',54,1,0,'2001-07-02 00:00:00'), (5,'花木兰','17799990004','[email protected]','软件工程',23,2,1,'2001-04-22 00:00:00'); -- 需求 -- 1.name字段为姓名字段,该字段的值可能会重复,为该字段创建索引 create index idx_user_name on tb_user(name); -- 2.phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引 create unique index idx_user_phone on tb_user(phone); -- 3.为profession、age、status创建联合索引 create index idx_user_pro_age_sta on tb_user(profession,age,status); -- 4.为email建立合适的索引来提高查询效率 create index idx_user_email on tb_user(email); -- 查询索引 show index from tb_user;结果--->


SQL性能分析-->
SQL执行频率--->
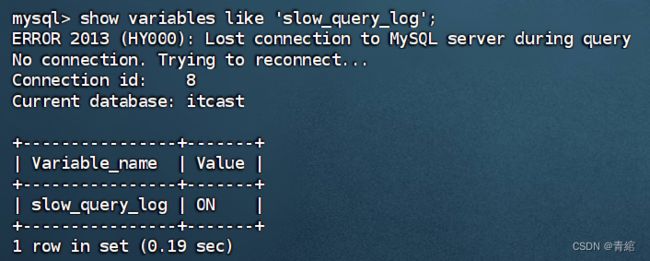
慢日志查询--->
代码演示--->
查询慢日志查询--->
使用vi编辑器配置信息--->此时状态为OFF关闭
返回后重新启动mysql服务器--->
再次查询--->此时状态为ON打开
查找存放慢日志文件的位置--->此时文件中存放的只有一些基本信息
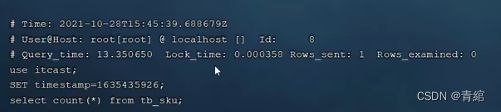
查询1000w条数据--->出现慢查询日志
profile详情--->
使用-->
代码演示--->
启用profiling--->
进行三个查询操作--->
通过profiles操作查看每条sql的耗时基本情况--->
通过profiles操作查看sql语句各个阶段的耗时情况--->
通过profiles操作查看sql语句各个阶段cpu的使用情况--->
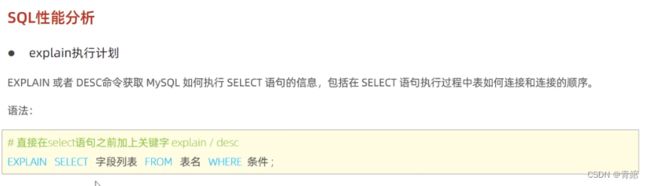
explain执行计划-->
explain执行计划各字段含义:
代码演示--->
查看sql语句的执行计划--->
id值相同--->
id值不同--->
















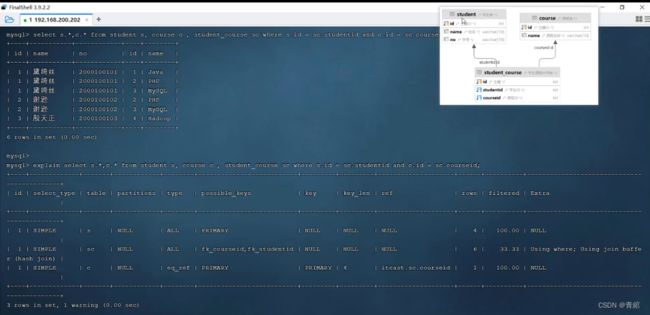

索引使用-->
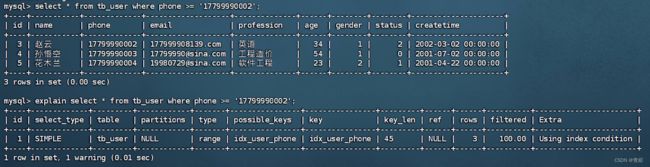
验证索引效率--->
代码示范--->
创建索引前--->
创建索引--->
创建索引后--->




最左前缀法则--->
代码示范--->
从索引最左列开始,并且没跳过索引中的列--->
从索引最左列开始,并且没跳过索引中的列,不包含最后一个索引--->
只用最左列的索引--->
不包含最左列的索引,只使用后两个索引--->没调用索引,因为不符合最左前缀法则
包含最左列的所有,但不包含中间的索引,包含最后的索引--->最后的索引失效了,因为最左前缀法则跳过了某一列,后面的所有列索引都会失效
先执行age和status,最后执行最左列的索引--->全部索引生效,最左前缀法则没有规定最左列索引放的位置

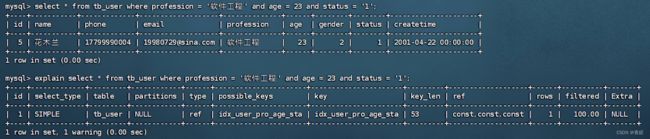





范围查询--->
代码示范--->
查询最左索引和age,经过>符号后继续执行status--->不执行status索引
查询最左索引和age,经过>=符号后继续执行status--->执行全部索引



索引失效情况--->
索引失效情况一--->
代码示范--->
正常查询一段数据--->调用了所有索引
进行了函数运算并查询--->没调用任何索引
正常查询一段数据--->调用了所有索引
字符串没有用引号查询数据--->可能用到所有索引,但实际没有使用
使用尾部模糊匹配--->用到所有索引
使用头部模糊匹配--->没用到索引
索引失效情况二--->
代码示范--->
只用age和id查询--->age没索引,id有索引,结果:id索引可能用到,实际都没用到
解决--->给age添加索引
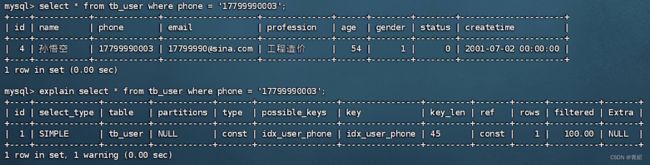
通过phone条件从第三条数据开始查询--->使用了所有索引
通过phone条件从第一条数据开始查询--->没有使用索引:只要大部分数据满足要求,就走全表扫描,不走索引
类上图
SQL提示--->
代码示范--->
在已经创建联合索引的情况下,再创建单列索引--->
在profession同时有联合索引和单列索引的情况下执行--->MySQL优化器自动选择了联合索引
使用use建议MySQL使用该单列索引执行--->使用了单列索引
使用ignore让MySQL忽略单列索引执行--->使用了联合索引
使用force让MySQL强制使用单列索引执行--->使用了单列索引
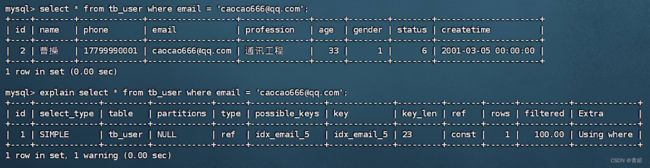
覆盖索引&回表查询--->
能够在聚集索引或二级索引中直接找到select要的所有信息就是覆盖索引
需要回表,先通过二级索引查到主键,再去聚集索引查找select字段的就是回表查询
代码示范--->
使用联合索引查询一段数据--->
select指定查询id、profession和id、profession、age以及id、profession、age、status其他同上--->执行计划都相同
代码同上(select多指定一个name)--->Extra由Using where, Using index变为Using index condition(前者效率更高)
前缀索引--->
代码示范--->
获取email的索引选择性--->
截取email字符串1-9和1-7的索引选择性--->1-9为1不会重复,1-8为0.8会重复,1-5也为0.8会重复
结果:如果对选择性要求很高,就使用1-9选择性为1,如果要平衡索引体积和选择性就选1-5选择性为0.8
创建email前缀索引,取前五个--->
通过前缀索引查询字段--->
工作流程--->
截取email前五个字段,lvbu5,在辅助索引中找到lvbu6对应的值-->回表查询-->找到id对应的row,再拿row和完整字符串[email protected]比较,相同则返回,不同则回到辅助索引中往链表后一个查询,然后继续回表比较
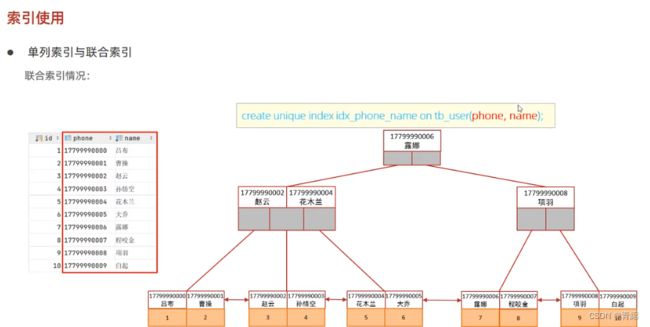
单列索引和联合索引--->
代码示范--->
根据两个字段查询一段数据--->只走了一个字段
创建一个phone和name的唯一联合索引,再次进行查询--->只用到了phone索引
使用use建议使用联合索引再次进行查询--->
结果:NULL表示要用到回表查询,Using index效率更高
联合索引查询流程
先根据phone查询,如果phone相同再根据name查询










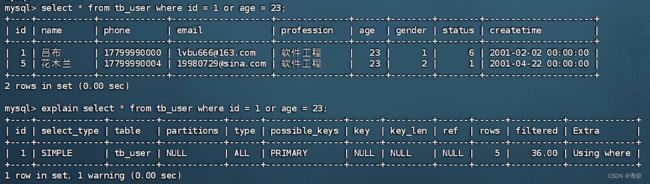



















索引设计原则--->

总结

