双指针Two Point【代码笔记】
双指针【Two Point】
双指针,顾名思义定义两个左右指针,解决题目的问题
双指针又分为很多小类:
- 双指针滑动窗口
- 快慢指针
- 用于替换字母
- 加法问题
双指针滑动窗口模板
先上霜神leetcode刷题笔记中总结的模板【当然我是用python将其复刻出来】
left, right = 0, -1
while left < len(s):
if right+1 < len(s) and 其他约束条件 :
操作约束条件
right += 1
else:
操作约束条件
left += 1
result = max(result, right - left + 1)
根据我自己的做题,我又总结了另一套模板
left, right = 0, 0
while right < len(s):
根据约束条件移动右指针来寻找完成约束条件的窗口
while 约束条件成立:
记录结果
left += 1 # 移动左指针
right += 1 # 移动右指针
力扣真题
无重复字符的最长子串 mid
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
哈哈哈这个一眼滑动窗口,上模板,记得要稍微改动哦
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
lenth = len(s)
left, right = 0,-1
result = 0
while left < lenth:
if right+1 < lenth and s[right+1] not in s[left:right+1]:
right += 1
else:
left += 1
result = max(result,right-left+1)
return result
最小覆盖子串 hard
不亏是hard难度的,这道题难在难在,如何去确定操作约束的条件
我刚开始直接套模板,但在具有重复值的t那出现了bug,所以故事告诉我们不能直接抄答案
下面让我们看看正确的思路:
- 记录t中出现的字符的次数和总数
- 利用右指针先找到出现了所有字符的窗口,利用每个字符的数量和总数判断
- 找到过后进入左指针操作环节
- 先比较记录中长度是否更小
- 准备移动左指针前,要判断一下这个左指针在不在t内,在的话要将总数补回来,还有这个字符数补回来
下面我们直接看看代码
from collections import defaultdict
class Solution:
def minWindow(self, s: str, t: str) -> str:
c = defaultdict(int) # 创建一个字典
# 记录t中出现的字符数量
for i in t:
c[i] += 1
result, ans = float('inf'),""
lens, counter = len(s), len(t)
left, right = 0, 0
# 移动右指针先寻找包含了所有需要字符的窗口
while right < lens:
if c[s[right]] > 0:
counter -= 1
c[s[right]] -= 1
right += 1
# 当找到所有在t中出现的字符之后再进行操作
while counter == 0:
# 记录长度并比较
if result > right - left:
result = right - left
ans = s[left:right]
# 这个时候要准备移动左指针了,但我们要判断一下这个左指针在不在t内,在的话要操作
if c[s[left]] == 0:
counter += 1
c[s[left]] += 1
left += 1
return ans
替换后的最长重复字符
给你一个字符串 s 和一个整数 k 。你可以选择字符串中的任一字符,并将其更改为任何其他大写英文字符。该操作最多可执行 k 次。
在执行上述操作后,返回包含相同字母的最长子字符串的长度。
输入:s = "ABAB", k = 2
输出:4
解释:用两个'A'替换为两个'B',反之亦然。
同样使用二号模板,与之前题目思路类似,寻找最多出现的为基准,其他的作为被替换的值,使用count记录字母的频率。
class Solution:
def characterReplacement(self, s: str, k: int) -> int:
left,right = 0,0
count = [0 for _ in range(26)]
s_len = len(s)
ans = 0
while right < s_len:
count[ord(s[right]) - ord('A')] += 1
other = sum(count) - max(count)
print(other)
while other > k :
# print(ord(s[left]))
other -= 1
count[ord(s[left]) - ord('A')] -= 1
left += 1
ans = max(ans,right-left+1)
right += 1
return ans
找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
这道题与上一道题一样,同样要对出现的内容做记录,当出现的值不在p中或者窗口长度超过了p时,就要移动左指针了,记得小心左指针超过了右指针,我在调试的时候就发现了这个问题,所以补充了这个条件。当同于存储的字典与p形成的字典一样时,就证明满足要求了
class Solution:
def findAnagrams(self, s: str, p: str) -> List[int]:
temp_dict,window_dict = {},{}
# 统计p中每个字符的个数并存入字典中
for key in p:
temp_dict[key] = temp_dict.get(key,0)+1
left,right = -1,0
return_index = []
while right < len(s):
# 不断扩张右窗口,并把右指针指向的字符作为键储存于窗口字典中,如果键已存在,则键值加一
key = s[right]
window_dict[key] = window_dict.get(key,0)+1
# 如果窗口中有键是不存在与temp字典里,或者窗口的键值和大于字典里的键值和的话,左窗口不断收缩直至左指针等于右指针
while (key not in p or sum(window_dict.values()) > len(p)) and left+1 <= right:
# 收缩左窗口,相对应键值减一,如果减到0就直接把键删掉
window_dict[s[left+1]]-=1
# 清除空间释放内存
if window_dict[s[left+1]] == 0:
del window_dict[s[left+1]]
left+=1
# 如果两个窗口字典和temp字典相等,那么此时窗口内的字符串就是字母异位词,将左窗口的索引储存在return列表里即可
if temp_dict == window_dict:
return_index.append(left+1)
right+=1
return return_index
字符串的排列
给你两个字符串s1 和 s2 ,写一个函数来判断 s2是否包含 s1的排列。如果是,返回 true ;否则,返回 false 。
换句话说,s1的排列之一是 s2 的 子串 。
输入:s1 = "ab" s2 = "eidbaooo"
输出:true
解释:s2 包含 s1 的排列之一 ("ba").
这题和上一题也一样,就不多分析了
class Solution:
def checkInclusion(self, s1: str, s2: str) -> bool:
windowdic,tempdict = {},{}
for item in s1:
if item not in tempdict:
tempdict[item] = 1
else:
tempdict[item] += 1
# print(tempdict)
right,left = 0,0
s2_len = len(s2)
while right < s2_len:
key = s2[right]
windowdic[key] = windowdic.get(key,0)+1
while (key not in s1 or sum(windowdic.values())>len(s1)) and left <= right:
windowdic[s2[left]] -= 1
if windowdic[s2[left]] == 0:
del windowdic[s2[left]]
left += 1
if tempdict == windowdic:
return True
right += 1
return False
乘积小于 K 的子数组
给你一个整数数组 nums 和一个整数 k ,请你返回子数组内所有元素的乘积严格小于 k 的连续子数组的数目。
输入:nums = [10,5,2,6], k = 100
输出:8
解释:8 个乘积小于 100 的子数组分别为:[10]、[5]、[2],、[6]、[10,5]、[5,2]、[2,6]、[5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于 100 的子数组。
代码:
class Solution:
def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int:
left,right = 0,0
temp_multiplt = 1
len_nums = len(nums)
ans = 0
while right < len_nums:
key = nums[right]
temp_multiplt = temp_multiplt * key
while temp_multiplt >= k and left<=right:
temp_multiplt = temp_multiplt / nums[left]
left += 1
ans += right - left + 1
right += 1
print(ans)
return ans
划分字母区间
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
输入:S = "ababcbacadefegdehijhklij"
输出:[9,7,8]
解释:
划分结果为 "ababcbaca", "defegde", "hijhklij"。
每个字母最多出现在一个片段中。
像 "ababcbacadefegde", "hijhklij" 的划分是错误的,因为划分的片段数较少。
说实话,这道题没啥思路,想了十几分钟,顶不住了看了一下相关标签的提示:贪心、双指针
贪心算法我接触的比较少(初出茅庐嘛),看到了一共比较形象的题解,我觉得他这个不错,下面展示一下
图解举例:【引用代码随想录Carl的图画的太好让人理解了,也很好的表达了本题的含义】
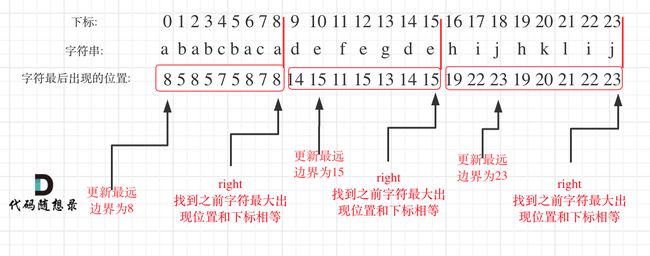
leetcode题解博主Nehzil分析到:分析题意可知,同一个字母只能出现在同一个片段,显然同一个字母的第一次出现的下标位置和最后一次出现的下标位置必须出现在同一个片段。因此在遍历字符串过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界{当你出现的下标和自己当前的位置相等时就认为是最远边界分割点},说明这个边界就是分割点了。【隐含的含义就是此时前面出现过所有字母都已经达到了最远的边界了】
下面附上代码
class Solution:
def partitionLabels(self, s: str) -> List[int]:
d = {k:v for v,k in enumerate(s)} # 保存每个字符最后出现的位置
print(d)
res = []
start = 0 # 一段的开始位置
end = 0 # 一段的结束位置
for i in range(len(s)): # 遍历字符串
end = max(end, d[s[i]]) # 结尾要包含当前字符出现的最后位置
if i == end: # 当前区间所有字符的最后出现位置都包括在[start, end]内
res.append(end - start + 1)
start = end + 1
return res
print(d)
这道题还是很值的学习的,是道不错的贪心+双指针的题目(感觉这里双指针用的不多)
数组中的最长山脉
把符合下列属性的数组 arr 称为 山脉数组 :
arr.length >= 3- 存在下标
i(0 < i < arr.length - 1),满足arr[0] < arr[1] < ... < arr[i - 1] < arr[i]、arr[i] > arr[i + 1] > ... > arr[arr.length - 1]
给出一个整数数组 arr,返回最长山脉子数组的长度。如果不存在山脉子数组,返回 0 。
输入:arr = [2,1,4,7,3,2,5]
输出:5
解释:最长的山脉子数组是 [1,4,7,3,2],长度为 5。
这题不算特别难,但也属于经典的双指针的做法了。
先利用指针寻找到能成为山峰的值,再利用双指针对两边进行遍历,找到当前山峰可以形成的山脉
class Solution:
def longestMountain(self, A: List[int]) -> int:
n = len(A)
res = 0
for i in range(n-2):
if A[i] < A[i+1] and A[i+1] > A[i+2]: #找到可以成为山峰的值
j = i-1 # 左边的指针
currnt = 3 # 目前能构成山峰的山的数量
left = A[i] # 左峰值
while j >= 0 and A[j] < left: #往左延伸
left = A[j] #更新左峰
j -= 1
currnt += 1
j = i+3 # 右边的指针
right = A[i+2]
while j < n and A[j] < right: #往右延伸
right = A[j] #更新右
j += 1
currnt += 1
res = max(res,currnt)
return res
救生艇
给定数组 people 。people[i]表示第 i 个人的体重 ,船的数量不限,每艘船可以承载的最大重量为 limit。
每艘船最多可同时载两人,但条件是这些人的重量之和最多为 limit。
返回 承载所有人所需的最小船数 。
输入:people = [3,2,2,1], limit = 3
输出:3
解释:3 艘船分别载 (1, 2), (2) 和 (3)
这题我们可以先将人们的重量从小到大的排序先(这题有个隐藏条件,就是最重的人的重量不会超过limt
- 当最重的与最轻的加起来,都超过了limit,那就让这个最重的单独一艘船
- 否则就让这个最重的和这个最轻的一艘
class Solution:
def numRescueBoats(self, people: List[int], limit: int) -> int:
ans = 0
people.sort()
left,right = 0,len(people) - 1
while left <= right:
if people[left] + people[right] > limit:
right -= 1
else:
left += 1
right -= 1
ans += 1
return ans
寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间。
输入:nums = [3,1,3,4,2]
输出:3
这道题与在链表中寻找环结构类似,这里需要在数组中寻找环的结构。当找到构成环的结点时,即重复的值,后,寻找这个环的起点就好
nums.length == n + 1注意题目给出的这个条件,有助于我们怎么去实现环,怎么去制定快慢指针,毕竟他是个数组不是链表嘛,所以得注意
class Solution:
def findDuplicate(self, nums: List[int]) -> int:
fast,slow = 0,0
# 寻找环状结构
while True:
fast = nums[nums[fast]]
slow = nums[slow]
if fast == slow:
break
# 找到环状结构入口
find = 0
while True:
find = nums[find]
slow = nums[slow]
if find == slow:
break
return find
三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]]
你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。
这道题说是可以用双指针来完成,但说实话我觉得算是三指针,可以通过排序并判断是否能实现三数之和减少循环次数
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
n=len(nums)
res=[]
# 特殊值处理
if(not nums or n<3):
return []
# 排序,因为都是正数时候就不存在三数之和等于0了
nums.sort()
res=[]
# 遍历每一个目标
for i in range(n):
if(nums[i]>0):
return res
# 跳过重复的值防止出现重复的结果
if(i>0 and nums[i]==nums[i-1]):
continue
# 定义左指针与右指针
L=i+1
R=n-1
while(L<R):
if(nums[i]+nums[L]+nums[R]==0):
res.append([nums[i],nums[L],nums[R]])
# 跳过重复值,防止答案重复
while(L<R and nums[L]==nums[L+1]):
L=L+1
while(L<R and nums[R]==nums[R-1]):
R=R-1
# 移动指针
L=L+1
R=R-1
# 移动指针
elif(nums[i]+nums[L]+nums[R]>0):
R=R-1
else:
L=L+1
return res