最新Redis7 的十大数据类型(最全指令)
Redis 是一种高性能的键值存储系统,支持多种数据类型。以下是 Redis 的十大主要数据类型:
-
字符串 (String): 最简单的数据类型,可以包含任意数据,如文本、二进制数据等。
-
列表 (List): 有序的字符串元素集合,支持从两端进行插入和删除操作,可以用作队列或栈。
- 哈希 (Hash): 用于存储对象,类似于关联数组。每个哈希可以包含字段和与之相关联的值。
-
集合 (Set): 无序的字符串元素集合,不允许重复元素。支持集合间的交、并、差集运算。
-
有序集合 (Sorted Set): 类似于集合,但每个元素都有一个相关的分数,根据分数进行排序。
-
位图 (Bitmaps): 用于处理位操作的数据结构,支持对二进制位进行设置、清除和查询。
-
HyperLogLog: 用于估计集合中不重复元素的数量,占用固定的空间。
-
地理空间索引 (Geospatial Index): 存储地理空间位置信息,支持范围查询和附近位置搜索。
-
流 (Stream): 引入于 Redis 5.0,用于按时间顺序存储和处理事件。
-
带有过期时间的键 (Expiring Keys): 键可以设置过期时间,到期后自动删除。
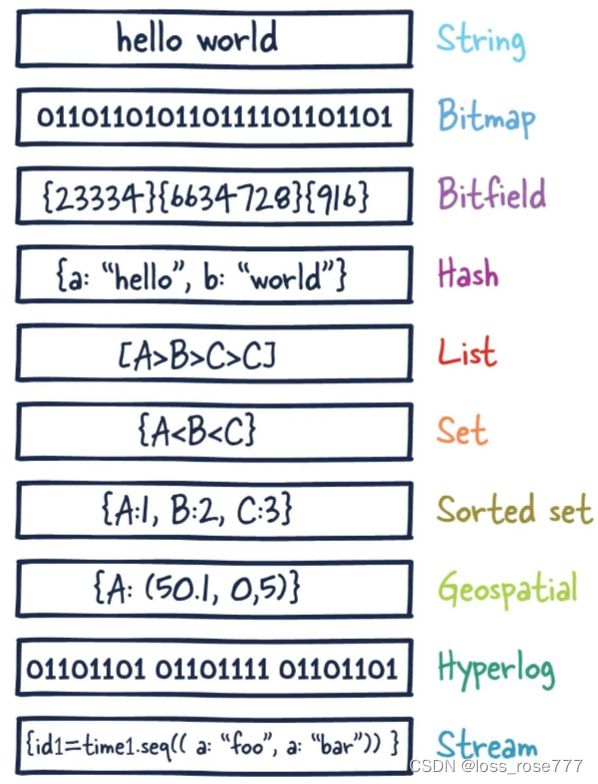
下面我将更加具体的分析一下这十个数据类型,并且和还有对应的redis操作:
字符串(String)
最常用的命令:
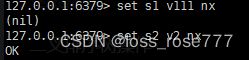
设置/获取键值对:set key value/get key value

其中还有一个参数就是nx 代表如果不存在s1就创建,否则不创建
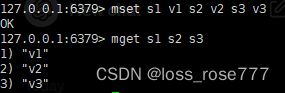
同时设置/获取多个键值对:mset key value key value...../mget key key.....
获取/设置指定区间范围内的值:getrange/setrange
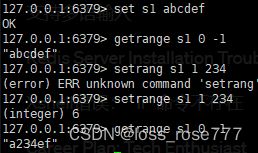
其中我们需要注意的是setrange的参数:
SETRANGE key offset value
key是要操作的键。offset是要替换的起始位置的偏移量。value是要插入的字符串。
数值增减:incr/decr key | incrby/decrby key increment/decrement

应用场景
比如抖音的视频点赞,就是incr key
是否喜欢该文章
阅读数:只要点击了rest地址,直接可以使用incr key 命令增加一个数字1,完成记录数字。
列表list
列表是一个双端链表组成的
左插入/右插入/查找:lpush/rpush/lrange
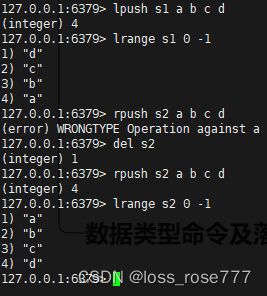
左删除/右删除:lpop/rpop
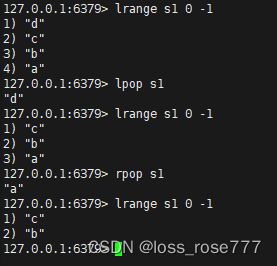
按照索引下标获取元素:lindex
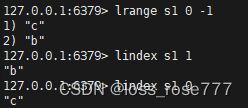
获取列表元素个数:llen
![]()
移除列表指定值的元素:lrem
LREM key count value:
key是要操作的列表的键。count是要移除的元素个数。有三种情况:- 如果
count大于 0,则从列表的头部开始向尾部移除值为value的元素,最多移除count个。 - 如果
count小于 0,则从列表的尾部开始向头部移除值为value的元素,最多移除count的绝对值个。 - 如果
count等于 0,则移除所有值为value的元素。
- 如果
value是要移除的元素的值。

移除列表除指定范围:ltrim

其他语句
去除尾部节点添加到头部:rpoploush
修改该索引的元素:lset key index value
在该索引前/后插入元素:linsert key before/after
哈希(Hash)
基础语句:hset/hget/hmset/hmget/hgetall/hdel

获取某个key内的全部数量:hlen

单独获取key/value:hkeys/hvals

增加value值:hincrby/hincrbyfloat

集合(Set)
添加/遍历元素:sadd/smembers key member
我们知道set是一个无重复元素的集合
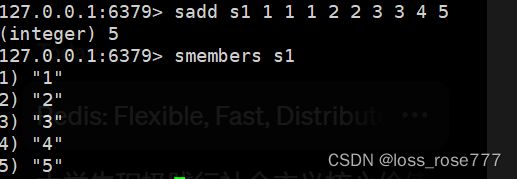
判断元素是否在集合中:sismember key member
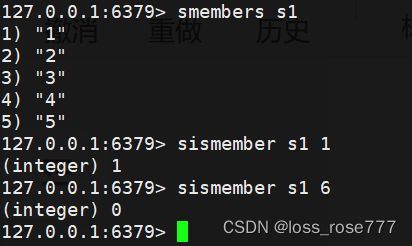
删除元素:srem key member

获取集合元素个数:scard

集合随机弹出一个元素不删除:srandmember key

集合随机弹出一个元素删除:spop key
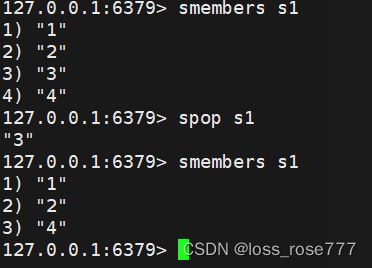
移动某元素到某集合:smove key1 key2
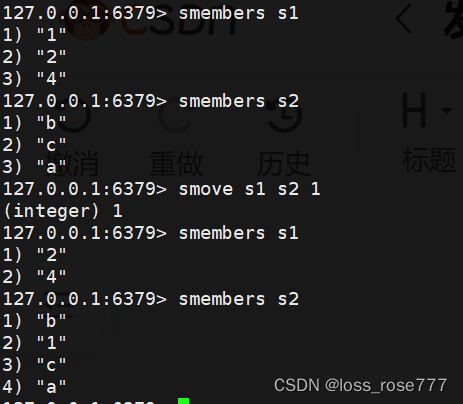
集合运算(重要):
并集:sunion/sunionstore
这两个命令的主要区别就是是否要创建一个新的集合存储他们的并集

交集:sinter/sinterstore
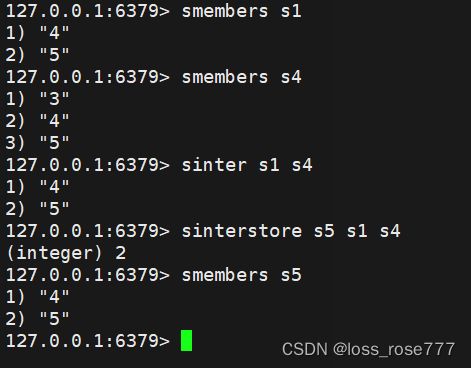
差集:sdiff/sdiffstore
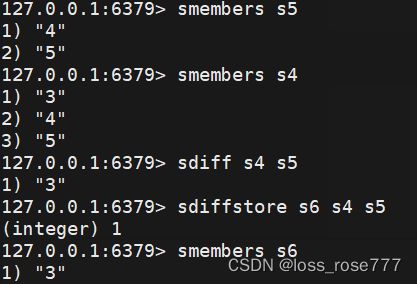
应用场景
微信抽奖小程序:

微信朋友圈点赞

抖音推送可能认识的人

有序集合(Zset)
在set基础上在val前加了一个score分数值,之气那set是k1 v1 v2 v3现在zset是k1 score1 v1 score2 v2
添加/打印/逆序打印元素:zadd/zrange/zrevrange

获取指定分数范围:zrangebyscore

获取分数:zscore

获取集合元素个数:zcard

删除元素:zrem

增加分数:zincrby
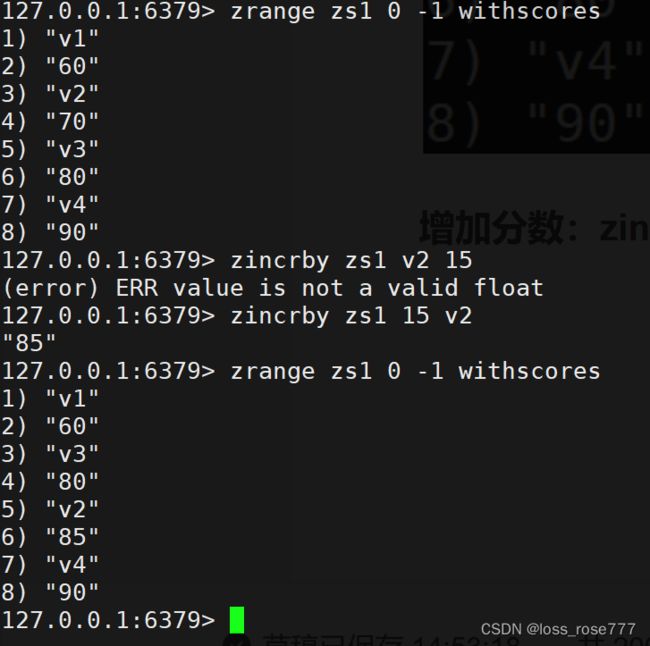
指定分数范围内的个数:zcount
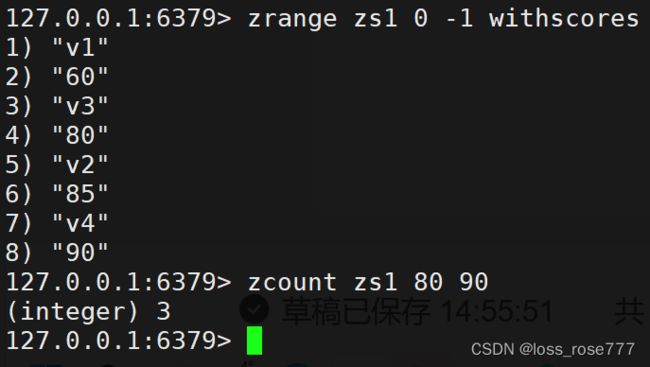
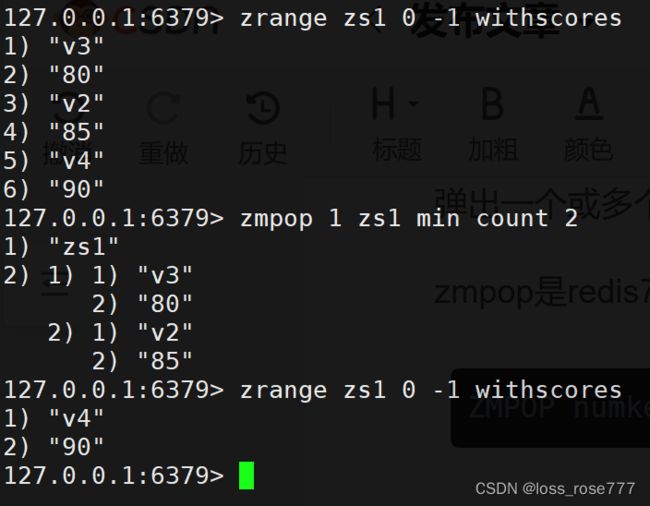
弹出一个或多个元素:zmpop
zmpop是redis7引入的新的命令:
ZMPOP numkeys key [key ...] [COUNT count]
numkeys是你想要检查的键的数量。key是你的有序集合键名。MIN)还是分数最高的元素(使用MAX)。[COUNT count]是可选的,用于指定要弹出的元素数量,默认为 1。
获取排名:zrank

应用场景:
根据商品销售堆商品进行排序显示

位图(bitmap)
一句话来说明白什么是位图:0和1状态表现得二进制位的bit数组
它的作用就是用来描述那些是或者否的事件比如签到

说明:用String类型作为底层数据结构实现的一种统计二值状态的数据类型
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们称之为一个索引)。
Bitmap支持的最大位数是2^32位,它可以极大的节约存储空间,使用512M内存就可以存储多达42.9亿的字节信息(2^32 = 4294967296)
设置/获取位图:setbit/getbit
SETBIT key offset value
key是位图的键。offset是要设置的位的偏移位置。value是要设置的值,可以是 0 或 1。

由此我们可以知道bitmap底层是string类型,在这里,十六进制的 "\x90" 对应的二进制是 "10010000",这是由于你设置了偏移为 0 和 3 的两个位。这说明 Redis 将位图存储为字符串,其中每个字符代表八个位。
占字节个数:strlen
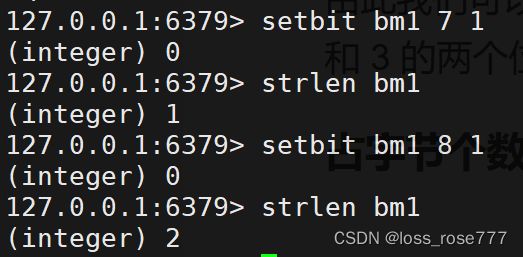
不是字符串长度而是占据几个字节,超过8位后自己按照8位一组一byte再扩容
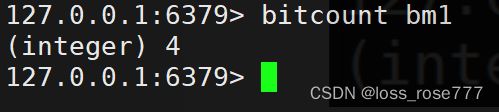
统计一个数:bitcount
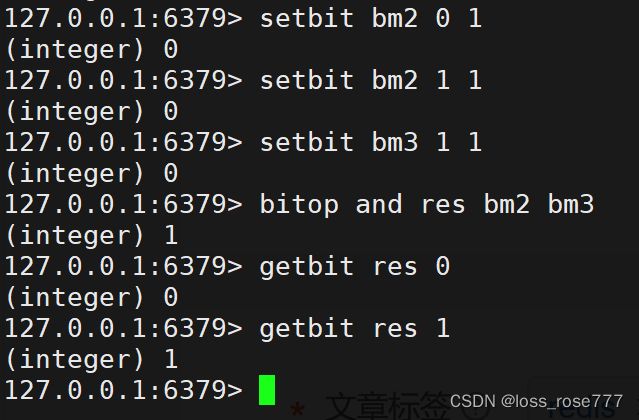
位运算:bitop
BITOP 是 Redis 中用于对多个位图进行位运算的命令。这个命令支持多种位运算操作,如 AND(与)、OR(或)、XOR(异或)和 NOT(非)。
BITOP operation destkey key [key ...]
operation是位运算的操作符,可以是 AND、OR、XOR 或 NOT。destkey是保存结果的目标键。key是要参与位运算的源键,可以是一个或多个。
应用场景:
获取连续签到人数

按年去存储一个用户的签到情况,365 天只需要 365 / 8 ≈ 46 Byte,1000W 用户量一年也只需要 44 MB 就足够了。
假如是亿级的系统,
每天使用1个1亿位的Bitmap约占12MB的内存(10^8/8/1024/1024),10天的Bitmap的内存开销约为120MB,内存压力不算太高。
此外,在实际使用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录以节省内存开销
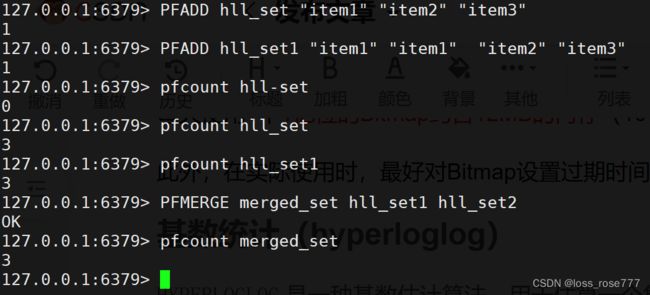
基数统计(hyperloglog)
HYPERLOGLOG 是一种基数估计算法,用于估算一个集合中不重复元素的数量。这个算法是用比特位的形式存储数据的,因此它占用的空间相对较小,尤其适用于处理大规模数据集合。
添加操作:pfadd
估计基数:pfcount
合并集合:pfmerge
地理空间(GEO)
添加/返回经纬度坐标:geoadd/geopos

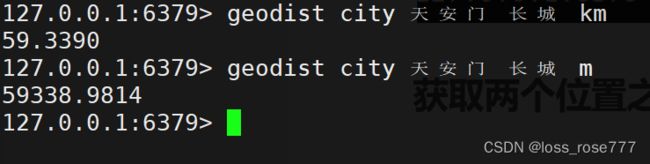
获取两个位置之间的距离:geodist
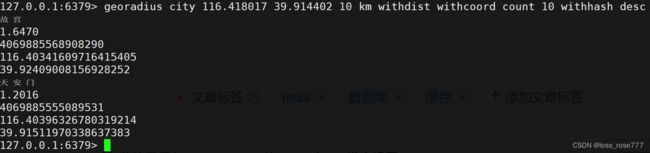
以半径查找:georadius
GEORADIUS key longitude latitude radius m|km|mi|ft [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
key是地理位置集合的键。longitude和latitude是中心点的经度和纬度。radius是搜索的半径距离,单位可以是米(m)、千米(km)、英里(mi)、或英尺(ft)。m|km|mi|ft是单位参数,用于指定radius的单位。
可选参数包括:
WITHCOORD:返回结果中包含地点的经度和纬度。WITHDIST:返回结果中包含地点与中心点之间的距离。WITHHASH:返回结果中包含地点的哈希值。COUNT count:指定返回的结果数量。ASC或DESC:指定返回结果的排序顺序。STORE key:将查询结果保存到指定键。STOREDIST key:将查询结果保存到指定键,并保存地点与中心点之间的距离。
应用场景:
各种地图的定位和推送位置
流(Stream)
我们可以用简洁的一句话概括Stream流:Redis版的MQ消息中间件+阻塞队列
底层结构和原理说明

特殊符号
在Redis Stream流中,特殊符号用于指定ID的范围或行为。以下是您提到的符号及其用途的详细说明:
-
最小(
-) 和 最大(+) 可能出现的ID:-表示Stream中可能的最小ID,通常用于 XRANGE 命令来获取从Stream开始的消息。+表示Stream中可能的最大ID,通常用于 XRANGE 命令来获取直到最新消息的范围查询。
-
$:表示只消费新的消息,当前流中最大的ID,可用于将要到来的信息。在 XREAD 或 XREADGROUP 命令中使用时,它告诉Redis只返回在执行命令之后添加到Stream的消息。 -
>:用于 XREADGROUP 命令,表示迄今还没有发送给组中消费者的信息,会更新消费者组的最后ID。这允许消费者组中的消费者只读取他们尚未确认的消息。 -
*:用于 XADD 命令中,让系统自动生成ID。这个自动生成的ID是基于时间的唯一序列,确保了消息的顺序和唯一性。
这些特殊符号在操作Redis Stream流时非常有用,因为它们提供了灵活的方式来引用和操作消息流中的数据。
队列相关命令:
添加消息到队伍末尾:xadd
添加规则:消息ID必须要比上一个ID大(默认使用星号表示自动生成规则)

这个ID "1702011189496-0" 是您使用 XADD 命令向Redis Stream流 stm1 添加消息时,Redis自动生成的唯一ID。这个ID由两部分组成:时间戳 1702011189496 和序列号 0。时间戳确保了消息的顺序,而序列号用于区分同一时间戳内的不同消息。
获取消息列表:xrange/xrevrange
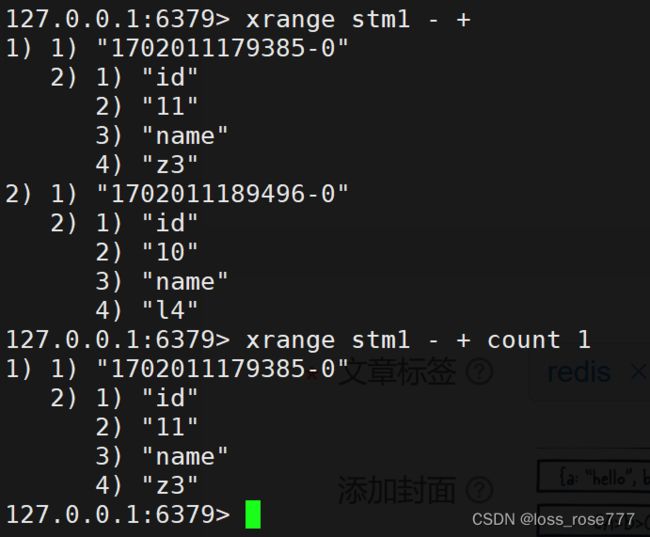
逆序查询

删除消息:xlen

获取队列长度:xlen

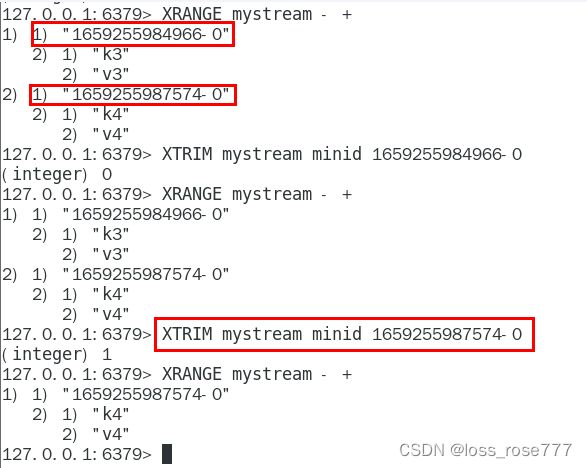
消息长度截取:xtrim
maxlen

minid
获取消息(阻塞/非阻塞):xread
非阻塞
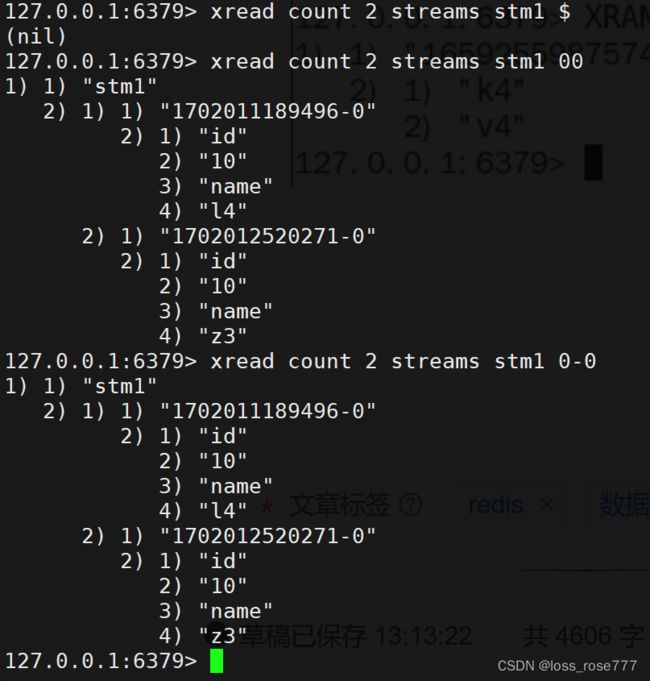
|
$代表特殊ID,表示以当前Stream已经存储的最大的ID作为最后一个ID,当前Stream中不存在大于当前最大ID的消息,因此此时返回nil
|
|
0-0代表从最小的ID开始获取Stream中的消息,当不指定count,将会返回Stream中的所有消息,注意也可以使用0(00/000也都是可以的……)
|
阻塞

消费组相关指令:
创建消费组:xgroup create

$代表从Stream尾部开始消费
0表示从Stream头部开始消费
创建消费者组的时候必须指定 ID, ID 为 0 表示从头开始消费,为 $ 表示只消费新的消息,队尾新来
读取消费者组:xreadgroup group
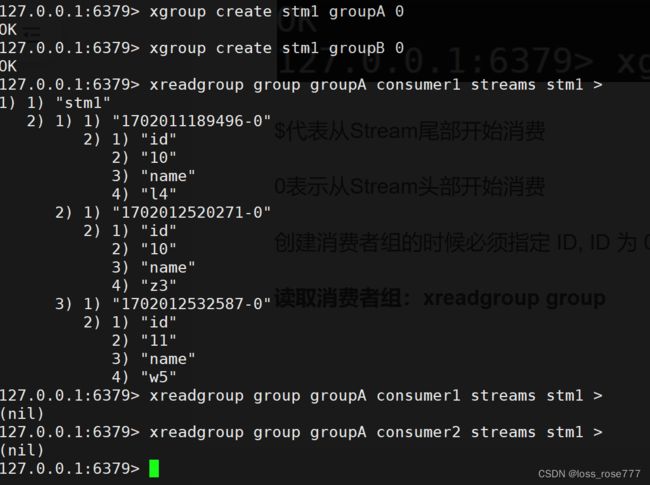
stream中的消息一但被消费者读取了,就不能在被消费组内的其他消费者读取了,即同一个消费组里的消费者不能消费同一条消息,所以第二、三次读的时候就是null
其中的“>“:表示多的是从第一条违背消费的消息开始读
但是不同的消费组的消费者可以读取同一条信息

那么消费组的目的是什么呢?
让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的
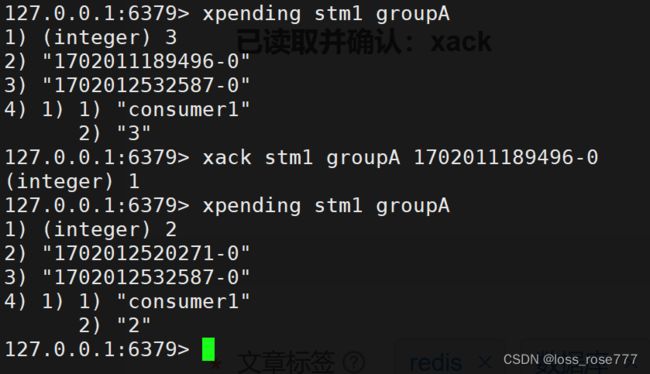
查询已读未回复的消息:xpending
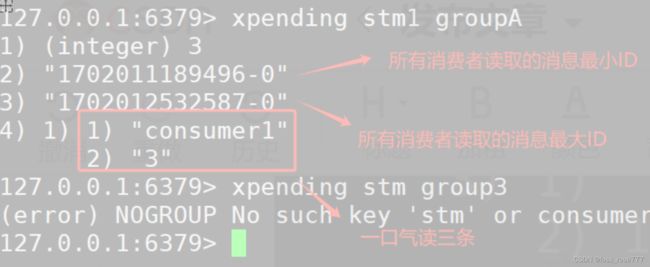
已读取并确认:xack
重点问题:

|
1问题
|
基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息?
|
|
2
|
Streams 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息保底措施,直到消费者使用 XACK 命令通知 Streams“消息已经处理完成”。
|
|
3
|
消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 XACK 命令确认消息已经被消费完成
|
位域(bitfield)(了解)
一句话概括:将一个Redis字符串看作是一个由二进制位组成的数组并能对变长位宽和任意没有字节对齐的指定整型位域进行寻址和修改
由于这个位域用处过于少这里就不仔细介绍了,可以到官网查看