文献阅读:重新审视池化:你的感受野不是最理想的
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 文献阅读:重新审视池化:你的感受野不是最理想的
-
- 1、研究背景
- 2、感受野存在的问题
-
- 2.1、不对称分布的信息
- 2.2、密集分布或稀疏分布信息
- 3、提出方法
-
- 3.1、动态优化池(DynOPool)
- 3.2、模型复杂性约束
- 4、试验结果
- 5、结论
- 一、GAN理论复习
-
- 1、GAN训练目标
- 2、Divergence的概念
- 3、Divergence的作用
- 4、Discriminator的作用
- 5、Discriminator的问题,Optimization的解法
- 二、GAN的算法实现
-
- 1、算法过程
- 2、算法实现
- 总结
摘要
本周主要阅读了2022CVPR的文章,重新审视池化:你的感受野不是最理想的,在文章中讲解了当前用于卷积和池化运算的内核大小和步长,会影响感受野的配置,使其不理想,于是提出了一种动态优化池方法来解决,其主要思路就是这是一个可学习的调整大小模块,可以替代标准的调整大小操作,在最终的几个测试下,都取得比较好的成绩。除此之外,我还学习复习了GAN的相关知识,用于了解其与Stable Diffusion之间差别。
Abstract
This week I mainly read articles from CVPR 2022, and revisited pooling. I found that the receptive field is not the most ideal. In the article, it is explained that the kernel size and step size currently used for convolution and pooling operations can affect the configuration of the receptive field, making it less ideal. Therefore, a dynamic optimization pooling method is proposed to solve this problem. The main idea is that this is a learnable resizing module that can replace the standard resizing operation. In the final few tests, it achieved good results. In addition, I also reviewed the related knowledge of GAN to understand the differences between it and Stable Diffusion.
提示:以下是本篇文章正文内容,下面案例可供参考
文献阅读:重新审视池化:你的感受野不是最理想的
Title:Pooling Revisited: Your Receptive Field is Suboptimal
Author:Dong-Hwan Jang ,Sanghyeok Chu ,Joonhyuk Kim , Bohyung Han
From:2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、研究背景
尽管深度神经网络在计算机视觉、自然语言处理、机器人、生物信息学等各种应用中取得了前所未有的成功,但最优网络结构的设计仍然是一个具有挑战性的问题。而感受野的大小和形状决定了网络如何聚集本地信息,并对模型的整体性能产生显著影响。神经网络中的许多组成部分,例如用于卷积和池化运算的内核大小和步长,都会影响感受野的配置。然而,它们仍然依赖于超参数,现有模型的感受野会导致形状和大小不理想。
2、感受野存在的问题
2.1、不对称分布的信息
最佳感受野形状会根据数据集中固有的空间信息不对称性而改变。而大多数情况下固有的不对称性是不可测量的。此外,通常用于预处理的输入大小调整有时也会导致信息不对称。在人工设计的网络中,图像的长宽比经常被调整以满足模型的输入规格。然而,这种网络中的感受野不是用来处理操作的。为了验证所提出的方法,作者在CIFAR-stretch-V上进行实验,如下图 a 所示,相较于人工设计模型,形状通过DynOPool动态优化的特征映射通过在水平方向上提取更具有价值的信息提高性能。

2.2、密集分布或稀疏分布信息
局部性是设计最优模型的组成部分。CNN通过级联的方式聚合局部信息来学习图像的复杂表示。而局部信息的重要性很大程度上取决于每个图像的属性。例如,当一个图像被模糊化时,大多数有意义的微观模式,如物体的纹理,都会被抹去。在这种情况下,最好在早期层中扩展感受野,集中于全局信息。另一方面,如果一幅图像在局部细节中包含大量类特定的信息,例如纹理,则识别局部信息将会更加重要。为了验证假设,作者构建了CIFAR-100数据集的两个变体,CIFAR-tile和CIFAR-large,如上图 b 和 c 所示。作者模型在很大程度上优于人工设计的模型。
3、提出方法
为了缓解人工构建的体系结构和操作的次优性,作者提出了动态优化池操作(DynOPool),这是一个可学习的调整大小模块,可以替代标准的调整大小操作。该模块为在数据集上学习的操作找到感受野的最佳比例因子,从而将网络中的中间特征图调整为适当的大小和形状。

3.1、动态优化池(DynOPool)
模块通过优化一对输入和输出特征映射之间的比例因子r来优化查询点q的位置以及获得中间特征映射的最佳分辨率。DynOPool在不影响其他算子的情况下,自适应控制较深层接收域的大小和形状,过程如下图所示。

针对比例因子r梯度不稳定,会产生梯度爆炸导致训练过程中分辨率发生显著变化的问题,使用a重新参数化r如下:

3.2、模型复杂性约束
为了最大化模型的精度,DynOPool有时会有较大的比例因子,增加了中间特征图的分辨率。因此,为了约束计算代价,减少模型规模,引入了一个额外的损失项LGMACs,它由每次训练迭代t的分层GMACs计数的简单加权和给出,如下所示:
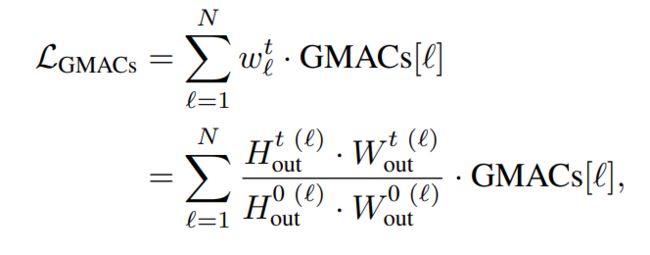
4、试验结果
通过使用FGVC-aircraft、CIFAR-100、ImageNet三种数据集在VGG-16、ResNet-50及MBN-V2三种模型使用动态优化池(DynOPool)方法来与原方法进行对比,从下图可以看出DynOPool-B性能对比原方法的提升。

5、结论
作者提出了一种简单而有效的动态优化池操作(DynOPool),它通过学习每个层中感受野的理想大小和形状来优化端到端的特征映射的比例因子,调整中间特征图的大小和形状,有效提取局部细节信息,从而优化模型的整体性能;DynOPool还通过引入一个额外的损失项来限制计算成本,从而控制模型的复杂性。实验表明,在多个数据集上,该模型在图像分类和语义分割方面均优于基线网络。
一、GAN理论复习
1、GAN训练目标
由已经学习到的GAN内容可以知道,GNN是为了生成与符合实际要求的内容的模型,所以当GAN中训练出来的内容与实际要求越符合,就越满足训练目标。那应该如何判断训练出来的内容是否满足实际要求呢?这里便引入上次学习的Distribution,从普通的Distribution中抽取sample向量,并将其导入到Generator里面,这样会产生一个新的Distribution PG。同样的步骤从真实数据集中也抽取sample也形成了一个Distribution Pdata , 当两者越接近便越接近目标。
2、Divergence的概念
Divergence在GNN中庸符号表示为Div(PG,Pdata),其是衡量PG和Pdata两个Distribution相似度的一个指标。当Divergence值越大就代表这两个Distribution的相似度越低,相反当Divergence的值越小就代表这两个Distribution相似度越高。
3、Divergence的作用
每个神经网络的训练都需要一个指标去进行优化,在普通的神经网络的训练当中,Loss Function便是这样的一个指标,通过不断迭代来找到某一参数值,使得最终的Loss Function的值最小,这样就能都够得到一个性能不错的神经网络模型。在GNN的训练中则是通过Divergence来判断其训练的好坏,因此其与Loss Function一样充当了一个优化标准定义器的角色。
4、Discriminator的作用
由前面的学习可以知道计算Divergence的重要性,但是应该如何计算出Divergence呢?这就需要到Discriminator,Discriminator 就是要尽量把从PG里sample的数据与从Pdata里sample的数据分开,这样让两者有明显的界限,从而让Discriminator在PG中发现Pdata的数据便能给其一个较高的分数,这样能获得一个更好的评分“机制”,让后续工作更加地顺利进行。
5、Discriminator的问题,Optimization的解法
既然Discriminator所需要处理的问题是辨别后进行的评分,那么下面的Optimization便更好地能帮助Discriminator完成辨别评分工作。log(D(y))表示的是从Pdata里取出的sample经过Discriminator辨别后的分数,log(1-D(y))表示的是从PG里取出的sample经过Discriminator辨别后的分数。有了这两个概念,就希望能找出合适的D来使V(G,D)最小,该值V是与JS divergence相关联的,只要通过Optimization方法不断地优化该值,便能顺利地解决Discriminator的问题。

二、GAN的算法实现
1、算法过程
-
首先随机初始化的判别器和生成器
-
在每一个迭代(iteration)中进行以下步骤:
1)固定Generator的参数,去调节Discriminator的参数:判别器要通过学习参数来给真实的目标打高分,给Generator生成的目标打低分
2)固定Discriminator的参数,调节 Generator参数:不断优化它生成的image,使得Discriminator给它的分数提高
2、算法实现
- 然后从数据集中抽取m个真实图片{ x1,x2,x3,…,xn};
- 从任意一个分布中抽取m个vector{ z1,z2,z3,…,zn},它的维度是超参数,自己设定;
- 使用m个vector通过生成器产生m个image{x11,x12,x13,…,x1n}, x1i=G(zi)
- 调整判别器:首先把m张真实图片都拿出来,经过判别器得到分数,然后经过log再统统平均起来(因为希望真实的图片得分高,所以希望这个越大越好);对于生成器生成的m张图片,希望值越小越好,因此用1-D(xi);
- 使用梯度上升的方法,调节判别器参数。
-重新生成m张图片G(zi), 就是一张图片,把它丢到判别器中D(G(zi))再对所有的生成的求平均,在D不改变的情况下,希望这个值越大越好。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。