关键词: Data Preprocessing、zero-centered、normalization、PCA、白化
神经网络的训练步骤
训练过程操作总览
Activation Function
做了一章的激活函数的单独整理 请点击查看
Data Preprocessing
3个常用的符号:数据矩阵X,假设其尺寸是[N x D](N是数据样本的数量,D是数据的维度)。
均值减法(Mean subtraction),预处理最常用的形式。
它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点。在numpy中,该操作可以通过代码X - = np.mean(X, axis=0)实现。而对于图像,更常用的是对所有像素都减去一个值,可以用X - = np.mean(X)实现,也可以在3个颜色通道上分别操作。
归一化(Normalization)是指将数据的所有维度都归一化,使其数值范围都近似相等。有两种常用方法可以实现归一化。
第一种是先对数据做零中心化(zero-centered)处理,然后每个维度都除以其标准差。它的实现代码为X /= np.std(X, axis=0)。
第二种方法是对每个维度都做归一化,使得每个维度的最大和最小值是1和-1。这个预处理操作只有在确信不同的输入特征有不同的数值范围(或计量单位)时才有意义,但要注意预处理操作的重要性几乎等同于学习算法本身。在图像处理中,由于像素的数值范围几乎是一致的(都在0-255之间),所以进行这个额外的预处理步骤并不是很必要。
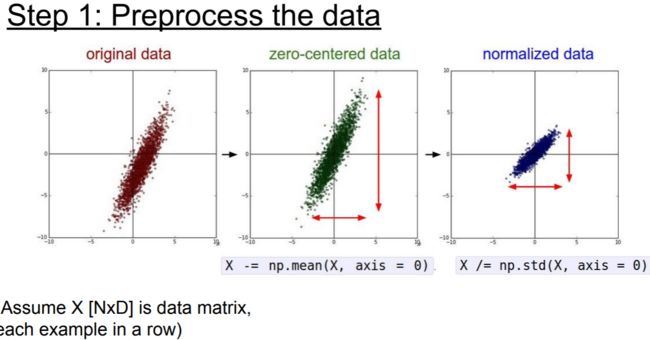
注:上图中红色的线指出了数据各维度的数值范围,在中间的图中不同列数据的数值范围不同,但在右边归一化数据中数值范围相同。
实践操作
对图片数据常进行的预处理操作:零中心化操作、对每个像素进行归一化。
常见错误。进行预处理很重要的一点是:任何预处理策略(比如数据均值)都只能在训练集数据上进行计算,算法训练完毕后再应用到验证集或者测试集上。例如,如果先计算整个数据集图像的平均值然后每张图片都减去平均值,最后将整个数据集分成训练/验证/测试集,那么这个做法是错误的。应该怎么做呢?应该先分成训练/验证/测试集,只是从训练集中求图片平均值,然后各个集(训练/验证/测试集)中的图像再减去这个平均值。
译者注:此处确为初学者常见错误,请务必注意!

PCA and Whitening
实际上在对图片处理时中并不会采用PCA或者白化的变换。这里只是为了解释的完整性
PCA和白化(Whitening)是另一种预处理形式。在这种处理中,先对数据进行zero-centered处理,然后计算协方差矩阵,它展示了数据中的相关性结构。
通常使用PCA降维过的数据训练线性分类器和神经网络会达到非常好的性能效果,同时还能节省时间和存储器空间。
白化(whitening)
白化操作的输入是特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。
该变换的几何解释是:如果数据服从多变量的高斯分布,那么经过白化后,数据的分布将会是一个均值为零,且协方差相等的矩阵。该操作的代码如下:
# 对数据进行白化操作:# 除以特征值 Xwhite=Xrot/np.sqrt(S+1e-5)
警告:夸大的噪声。注意分母中添加了1e-5(或一个更小的常量)来防止分母为0。该变换的一个缺陷是在变换的过程中可能会夸大数据中的噪声,这是因为它将所有维度都拉伸到相同的数值范围,这些维度中也包含了那些只有极少差异性(方差小)而大多是噪声的维度。在实际操作中,这个问题可以用更强的平滑来解决(例如:采用比1e-5更大的值)。
详细内容:http://blog.csdn.net/llp1992/article/details/45640527
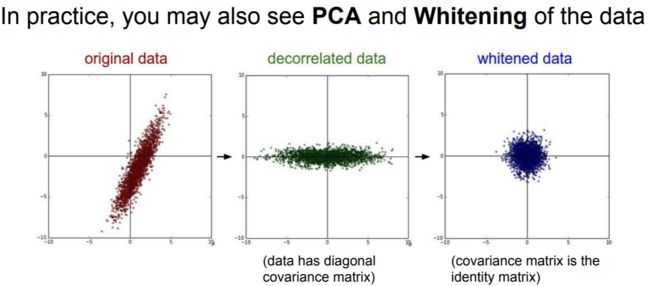
注:左边是二维的原始数据。
中间:经过PCA操作的数据。可以看出数据首先是zero-centered的,然后变换到了数据协方差矩阵的基准轴上。这样就对数据进行了解相关(协方差矩阵变成对角阵)。
右边:每个维度都被特征值调整数值范围,将数据协方差矩阵变为单位矩阵。从几何上看,就是对数据在各个方向上拉伸压缩,使之变成服从高斯分布的一个数据点分布。
后续:
- Weight Initialization
- Batch Normalization
- Babysitting the Learning Process
- Hyperparameter Optimization