U-ViT:A ViT Backbone for Diffusion Models

文章目录
-
- Abstract
- 1. Introduction
- 2. Background
- 3. Method
-
- 3.1. Implementation Details
- 3.2. Effect of Depth, Width and Patch Size
- 4. Related Work
- 5. Experiments
-
- 5.1. Experimental Setup
- 5.2. Unconditional and Class-Conditional Image Generation
- 5.3. Text-to-Image Generation on MS-COCO
- 6. Conclusion
Abstract
Vision transformers (ViT)在各种视觉任务中显现出了前景,而基于卷积神经网络(convolutional neural network, CNN)的U-Net在扩散模型中仍占主导地位。作者设计了一个简单而通用的基于ViT的架构(U-ViT),用于使用扩散模型(diffusion models)生成图像。U-ViT的特点是将包括时间(time)、条件(condition)和噪声图像补丁(noisy image patches)在内的所有输入作为token,并在浅层和深层之间采用长跳跃连接(long skip connections)。作者在无条件(unconditional)和类条件(class-conditional)图像生成以及文本到图像(text-to-image)生成任务中评估了U-ViT,其中U-ViT即使不优于类似大小的基于CNN的U-Net,也是具有可比性的。特别是,在生成模型训练过程中不需要访问大型外部数据集的方法中,使用U-ViT的潜在扩散模型在ImageNet 256x256上的类条件图像生成中获得了破纪录的FID分数2.29,在MS-COCO上的文本到图像生成中获得了5.48。
作者的研究结果表明,对于基于扩散的图像建模,长跳跃连接是至关重要的,而基于CNN的U-Net中的下采样和上采样算子并不总是必需的。作者相信,U-ViT可以为未来扩散模型的骨干(backbones)研究提供见解,有利于大规模跨模态数据集的生成建模。
1. Introduction
扩散模型是最近出现的用于高质量图像生成的强大的深度生成模型。它们发展迅速,并在文本到图像的生成、图像到图像的生成、视频生成、语音合成和3D合成中得到应用。
随着算法的发展,骨干(backbones)结构的变革在扩散模型中起着核心作用。一个典型的例子是基于卷积神经网络的U-Net。基于CNN的U-Net的特征是具有一组下采样块,一组上采样块以及两组之间的长跳跃连接,在图像生成任务的扩散模型中占主导地位。另一方面,ViT在各种视觉任务中已经显现出了前景,其中ViT的方法与基于CNN的方法相当,甚至优于基于CNN的方法。因此,一个很自然的问题就出现了:在扩散模型中是否有必要依赖基于CNN的U-Net ?
在本文中,作者设计了一个简单而通用的基于ViT的架构,称为U-ViT,如下图所示(Figure 1):
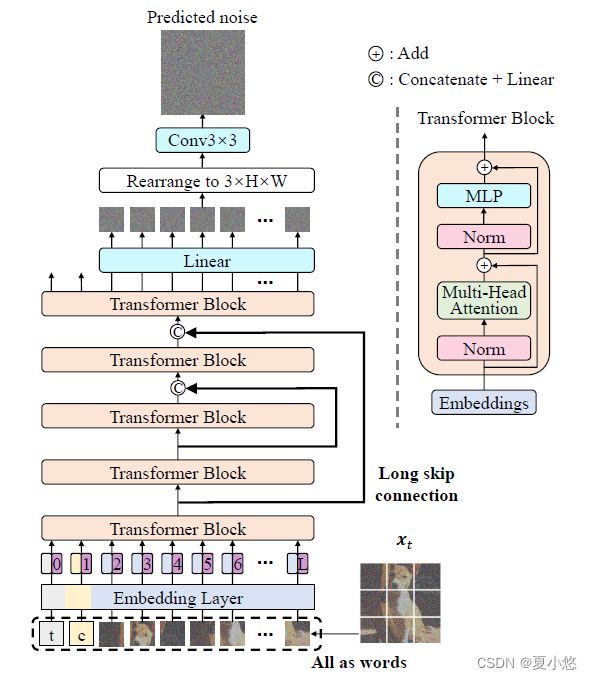
遵循transformers的设计原则,U-ViT将包括时间、条件和噪声图像补丁(patch)在内的所有输入视为token。最重要的是,受U-Net启发,U-ViT采用了浅层和深层之间的长跳跃连接。直观地说,在扩散模型中,低级(low-level)特征对于像素级(pixel-level)预测目标很重要,这种连接可以使相应预测网络的训练容易些。此外,U-ViT可选择在输出之前添加额外的3x3卷积块,以获得更好的视觉质量。参见图2中所有元素的系统消融研究。
作者在三个主流的任务中评估U-ViT:无条件图像生成、类条件图像生成和文本到图像生成。在所有设置中,U-ViT与类似大小的基于CNN的U-Net相比,即使不优于U-Net,也是相当的。特别是,在生成模型训练过程中不需要访问大型外部数据集的方法中,使用U-ViT的潜在扩散模型在ImageNet 256x256上的类条件图像生成中获得了破纪录的FID分数2.29,在MS-COCO上的文本到图像生成中获得了5.48。
作者的研究结果表明,长跳跃连接是至关重要的,而基于CNN的U-Net中的上下采样算子对于图像扩散模型并不总是必需的。作者相信,U-ViT可以为未来大规模跨模态数据集的扩散模型主干提供见解,有利于生成建模的研究。
2. Background
扩散模型(Diffusion models)逐渐向数据中注入噪声,然后将这一过程反过来,从噪声中生成数据。噪声注入(noise-injection)过程,也称为前向过程,马尔可夫链的形式为: q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(x_{1:T} | x_0) = \prod ^T _{t=1} q(x_t | x_{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1) 其中, x 0 x_0 x0是数据(data), q ( x t ∣ x t − 1 ) = N ( x t ∣ α t x t − 1 , β t I ) q(x_t | x_{t-1}) = \mathcal N (x_t | \sqrt {\alpha _t} x_{t-1}, \beta _t I) q(xt∣xt−1)=N(xt∣αtxt−1,βtI), α t \alpha _t αt和 β t \beta _t βt表示噪声调度(schedule), α t + β t = 1 \alpha _t + \beta _t = 1 αt+βt=1。为了逆转这一过程,采用高斯模型 q ( x t − 1 ∣ x t ) = N ( x t − 1 ∣ μ t ( x t ) , σ t 2 I ) q(x_{t-1} | x_t) = \mathcal N (x_{t-1} | \mu _t (x_t), \sigma _t ^2 I) q(xt−1∣xt)=N(xt−1∣μt(xt),σt2I)近似地逼近真实数据反向转换 q ( x t − 1 ∣ x t ) q(x_{t-1} | x_t) q(xt−1∣xt),最优均值为: μ t ∗ ( x t ) = 1 α t ( x t − β t 1 − α ˉ t E [ ϵ ∣ x t ] ) \mu _t ^ * (x_t) = \frac {1} {\sqrt {\alpha _t}} \bigg( x_t - \frac {\beta _t} {\sqrt {1 - \bar {\alpha} _t }} \mathbb E [\epsilon | x_t] \bigg) μt∗(xt)=αt1(xt−1−αˉtβtE[ϵ∣xt]) 其中, α ˉ t = ∏ i = 1 t α i \bar {\alpha} _t = \prod ^t _{i=1} \alpha _i αˉt=∏i=1tαi, ϵ \epsilon ϵ是注入到 x t x_t xt中的标准高斯噪声。因此,学习相当于噪声预测任务。形式上,采用噪声预测网络 ϵ θ ( x t , t ) \epsilon _{\theta} (x_t, t) ϵθ(xt,t),通过最小化噪声预测目标学习 E [ ϵ ∣ x t ] \mathbb E [\epsilon | x_t] E[ϵ∣xt],即 m i n θ E t , x 0 , ϵ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 2 \underset {\bm \theta} {min} \mathbb E _{t, x_0, \epsilon} || \epsilon - \epsilon _{\theta}(x_t, t) ||_2 ^2 θminEt,x0,ϵ∣∣ϵ−ϵθ(xt,t)∣∣22 其中, t t t在 [ 1 , T ] [1, T] [1,T]之间均匀采样。为了学习条件扩散模型,例如类条件模型或文本到图像模型,将条件信息进一步输入到噪声预测目标中:
m i n θ E t , x 0 , c , ϵ ∣ ∣ ϵ − ϵ θ ( x t , t , c ) ∣ ∣ 2 2 ( 1 ) \underset {\bm \theta} {min} \mathbb E _{t, x_0, c, \epsilon} || \epsilon - \epsilon _{\theta}(x_t, t, c) ||_2 ^2 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1) θminEt,x0,c,ϵ∣∣ϵ−ϵθ(xt,t,c)∣∣22 (1) 其中, c c c是条件或连续的embedding。在先前的图像建模工作中,扩散模型的成功在很大程度上依赖于基于CNN的U-Net,它是一个卷积主干,其特征是一组下采样块、一组上采样块以及两组之间的长跳跃连接, c c c通过自适应组归一化(adaptive group normalization)和交叉注意力(cross attention)等机制输入到U-Net中。
视觉Transformer(ViT)是一种纯transformer架构,它将图像视为一个tokens(words)序列。ViT将图像重新排列成平坦的小块(patch)序列。然后,ViT将可学习的1D位置嵌入(1D position embeddings)添加到这些补丁(patch)的线性嵌入(linear embeddings)中,然后将它们送入transformer encoder。ViT在各种视觉任务中已经显示出前景,但是否适用于基于扩散的图像建模尚不清楚。
3. Method
U-ViT是图像生成中扩散模型的简单而又通用的主干。特别是,U-ViT参数化了公式(1)中的噪声预测网络 ϵ θ ( x t , t , c ) \epsilon _{\theta}(x_t, t, c) ϵθ(xt,t,c),它以时间 t t t、条件 c c c和噪声图像 x t x_t xt作为输入,并预测注入到 x t x_t xt中的噪声。按照ViT的设计方法,将图像分割成小块,U-ViT将包括时间、条件和图像小块在内的所有输入作为tokens(words)。
受基于CNN的U-Net在扩散模型中成功的启发,U-ViT也在浅层和深层之间采用了类似的长跳跃连接。直观地看,公式(1)中的目标是一个像素级的预测任务,对底层特征很敏感。长跳跃连接为低阶特征提供了捷径,从而简化了噪声预测网络的训练。
此外,U-ViT可选择在输出之前添加一个3x3卷积块,这是为了防止transformers生成的图像中产生潜在的伪影。根据作者的实验,这个卷积块提高了U-ViT生成的样本的视觉质量。
3.1. Implementation Details
虽然U-ViT在概念上很简单,作者仍然仔细设计了它的实现。为此,作者对U-ViT的关键要素进行了系统的实验研究。特别地,作者在CIFAR10上进行了消融实验,在10K个生成的样本(而不是为了效率进行50K个样本)上每50K次训练迭代评估FID分数,并确定默认实现细节。
小悠博主注:
CIFAR10数据集中有50k个训练样本和10k个测试样本,共60k个样本。作者的意思是没训练一次(一个epoch)进行一次评估,评估时模型生成10k个样本(与测试集保持一致)。
The way to combine the long skip branch. 哪种long skip组合方法更好?
设 h m , h s ∈ R L × D h_m, h_s \in \mathbb R^{L\times D} hm,hs∈RL×D分别为主分支(main branch)和长跳跃分支(long skip branch)的embeddings。在将它们馈送到下一个transformer block之前,考虑了几种组合它们的方法:
(1) 将它们连接起来,然后执行如图1所示的线性投影,即 L i n e a r ( C o n c a t ( h m , h s ) ) Linear(Concat(h_m, h_s)) Linear(Concat(hm,hs));
(2) 直接相加,即 h m + h s h_m + h_s hm+hs;
(3) 对h_s进行线性投影后相加,即 h m + L i n e a r ( h s ) h_m + Linear(h_s) hm+Linear(hs);
(4) 将它们相加,然后进行线性投影,即 L i n e a r ( h m + h s ) Linear(h_m + h_s) Linear(hm+hs);
(5) 不使用长跳跃连接。
如下图所示(Figure 2a),直接将 h m h_m hm和 h s h_s hs相加并不会带来好处。由于transformer block通过其内部的加法运算符具有跳跃连接,因此h_m已经以线性形式包含了 h s h_s hs的信息,因此, h m + h s h_m + h_s hm+hs的唯一作用是以线性形式增加 h s h_s hs的系数,而不改变网络的性质。相比之下,与无长跳跃连接相比,所有其他组合 h s h_s hs的方法都在 h s h_s hs上执行线性投影,从而提高了性能。其中,第一种连接方式的性能最好。在附录D中,作者可视化了网络中表示之间的相似性,发现第一种方式的连接显著地改变了表征信息,这验证了其有效性。

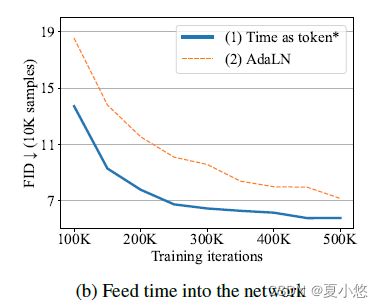
The way to feed the time into the network. 哪种将time送入网络的方法更好?
作者考虑两种将 t t t 输入网络的方法:
(1) 将时间 t t t 视为token,如图1所示;
(2) 将层归一化(layer normalization)后的时间合并到transformer block中,类似于U-Net中使用的自适应组归一化(adaptive group normalization)。
第二种方法称为自适应层归一化(AdaLN),在形式上: A d a L N ( h , y ) = y s L a y e r N o r m ( h ) + y b AdaLN(h, y) = y_s LayerNorm(h) + y_b AdaLN(h,y)=ysLayerNorm(h)+yb 其中 h h h为transformer block内的embedding, y s y_s ys和 y b y_b yb是由时间嵌入的线性投影得到的。如下图所示(Figure 2b),虽然简单,但将时间视为token的第一种方法比AdaLN执行得更好。
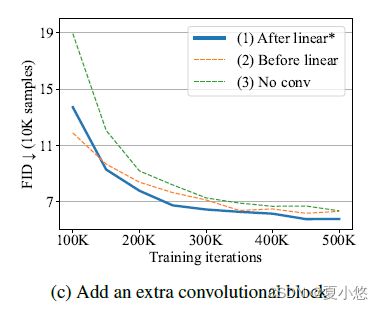
The way to add an extra convolutional block after the transformer. 这个额外的卷积块放在哪个位置更好?
作者考虑了两种方法在transformer后添加额外的卷积块:
(1) 在线性投影后添加一个3x3卷积块,将token embeddings映射到image patches,如图1所示;
(2) 在该线性投影前添加一个3x3卷积块,这需要将token embeddings h ∈ R L × D h \in \mathbb R^{L\times D} h∈RL×D的一维序列重新排列为形状为 H / P × W / P × D H / P \times W / P \times D H/P×W/P×D的二维特征,其中, P P P表示patch size;
(3) 不使用额外的卷积块。
如下图所示(Figure 2c),第一种方法中在线性投影后添加3x3卷积块的性能略好于其他两种选择:
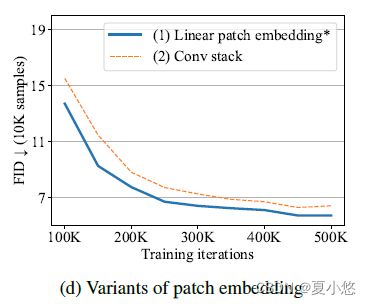
Variants of the patch embedding. 哪种patch embedding方式更好?
作者考虑了patch embedding的两种变体:
(1) 原始的patch embedding采用线性投影,将patch映射到一个token embedding,如图1所示;
(2) 使用3x3卷积块进行堆叠,后面跟着1x1卷积块,将image映射到token embedding。
如下图所示(Figure 2d),原始的patch embedding效果更好:
Variants of the position embedding. 哪种位置编码position embedding方式更好?
作者考虑了position embedding的两种变体:
(1) 原始的ViT中提出的一维可学习的position embedding,这是本文的默认设置;
(2) 二维正弦position embedding,patch的 p o s i t i o n ( i , j ) position(i, j) position(i,j) 可以由正弦编码的 i i i和 j j j拼接而成。
如下图所示(Figure 2e),一维可学习位置嵌入效果更好:

作者也尝试了不使用任何位置编码,发现模型不能生成有意义的图像,这说明位置信息在图像生成中是至关重要的。
3.2. Effect of Depth, Width and Patch Size
作者通过研究深度depth(即层数)、宽度width(即隐藏层尺寸D)和patch size对CIFAR10的影响来展示U-ViT的缩放特性。如图下图所示,性能随着深度(即层数)的增加而提高(depth=9, 13)。然而,在50K的训练迭代中,U-ViT不会从更大的深度(depth=17)中获益。类似地,将宽度(即隐藏层尺寸)增加也可以提高性能(width=256, 512),进一步增加到width=768不会带来任何增益;将patch size减小可以提高性能(patch-size=8, 2),再减小到patch-size=1则没有任何增益。需要注意的是,要获得良好的性能,需要像patch-size=2这样的小patch。作者猜测这是因为扩散模型中的噪声预测任务是低级别的,需要小的patch,与高级任务(例如分类)不同。由于使用小patch尺寸对于高分辨率图像代价较高,作者首先将它们转换为低维潜在表示,并使用U-ViT对这些潜在表示建模。

4. Related Work
Transformers in diffusion models. 一个相关的工作是GenViT,GenViT采用较小的ViT,不使用长跳跃连接和3x3卷积块,并且在图像扩散模型的归一化层之前并入时间。根据经验,经过仔细设计的实现细节,作者的U-ViT的性能比GenViT好得多(见表1)。另一个相关的工作是VQ-Diffusion及其变体,VQ-Diffusion首先通过VQ-GAN获得离散的图像tokens序列,然后使用以transformer为骨干的离散扩散模型对这些tokens进行建模,通过交叉注意力或自适应层归一化将时间和条件输入到transformer中。相比之下,作者的U-ViT简单地将所有输入视为tokens,并在浅层和深层之间使用长跳跃连接,从而实现了更好的FID(见表1和表4)。除了图像之外,扩散模型中的transformer还用于对文本进行编码(encode texts),解码文本(decode texts)及生成CLIP embeddings。
U-Net in diffusion models. Yang等人首先引入基于CNN的U-Net,对连续图像数据的对数似然函数的梯度进行建模,然后,对基于CNN的U-Net(连续)图像扩散模型进行改进,包括使用组归一化、多头注意力、改进残差块和交叉注意力。相比之下,作者的U-ViT是一个基于ViT的骨干网,其概念设计简单,同时与类似大小的基于CNN的U-Net性能相当(见表1和表4)。
Improvements of diffusion models. 除了主干之外,在其他方面也有改进,如快速采样(fast sampling)、改进训练方法和可控生成(controllable generation)。
5. Experiments
作者在无条件、类条件图像生成以及文本到图像生成中评估了本文提出的U-ViT,在给出这些结果之前,在下面列出了主要的实验设置,更多的细节,如采样超参数,在附录A中提供。
5.1. Experimental Setup
Datasets. 对于无条件学习,作者考虑包含50K训练图像的CIFAR10和包含162770张人脸训练图像的CelebA 64x64。对于类条件学习,考虑分辨率为64x64、256x256和512x512的ImageNet,其中包含来自1K个不同类的1281167张训练图像。对于文本到图像的学习,考虑分辨率为256x256的MS-COCO,其中包含82783张训练图像和40504张验证图像,每张图片都有5个注释说明文字。
High resolution image generation. 作者遵循256x256和512x512分辨率图像的潜在扩散模型(latent diffusion models, LDM)。首先使用Stable Diffusion提供的预训练图像自编码器(autoencoder)将它们分别转换为32x32和64x64分辨率的潜在表示,然后使用提出的U-ViT对这些潜在表征进行建模。
Text-to-image learning. 在MS-COCO上,作者使用Stable Diffusion的CLIP文本编码器将离散文本转换为embeddings序列,然后将这些embeddings作为tokens序列输入到U-ViT中。
CLIP,即Contrastive Language-Image Pre-Training。
U-ViT configurations. 作者在下表中确定了几种U-ViT配置。在本文的其余部分,使用简短的符号来表示U-ViT配置和输入patch大小。例如,U-ViT-H/2表示U-ViT-Huge配置的输入patch大小为2x2。
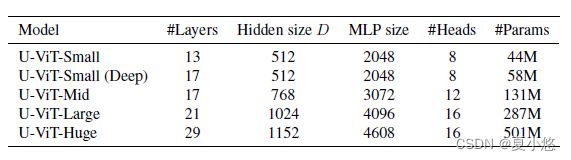
Training. 作者使用AdamW优化器,所有数据集的权重衰减为0.3(weight-decay=0.3)。对于大多数数据集,使用2e-4的学习率(learning-rate=2e-4),除了ImageNet 64x64使用的学习率为3e-4。在CIFAR10和CelebA 64x64上训练了500K次迭代,批大小为128(batch-size=128)。在ImageNet 64x64和ImageNet 256x256上训练了300K次迭代,在ImageNet 512x512上训练了500K次迭代,批处理大小为1024(batch-size=1024)。在MS-COCO上训练了1M次迭代,批大小为256(batch-size=256)。在ImageNet 256x256、ImageNet 512x512和MS-COCO上,作者采用无分类器引导跟随。在附录A中提供了更多的细节,比如训练时间和超参数的选择。
5.2. Unconditional and Class-Conditional Image Generation
作者将U-ViT与先前的基于U-Net的扩散模型进行了比较,还与GenViT进行了比较,用了50K生成样本的FID分数来衡量图像质量。
如下表所示,U-ViT在无条件CIFAR10和CelebA 64x64上的性能与U-Net相当,同时比GenViT要好得多:
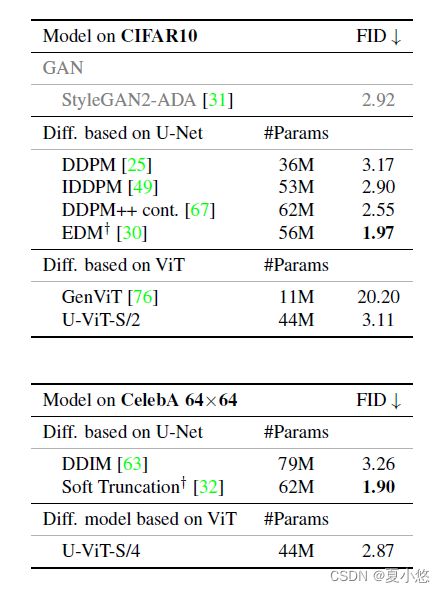
怎么说呢,前面部分写的很好啊,但看了这个结果之后,觉得很牵强啊。
44M的U-ViT-S/2能干的过11M的GenViT没什么可说的,毕竟参数量在这搁着呢,36M的DDPM却干不过,这是不是。。。
在类条件的ImageNet 64x64上,作者最初尝试使用131M参数的U-ViT-M配置,如下表所示,它的FID为5.85,优于100M参数的基于U-Net的IDDPM模型的6.92。为了进一步提高性能,作者采用了参数为287M的U-ViT-L配置,FID从5.85提高到4.26 :

是不是,
287M的U-ViT-L/4干不过270M的IDDPM,与参数量相近的296M的ADM也差很多。。。
同时,作者发现U-ViT在潜在空间中表现得特别好,在潜在空间中,图像在应用扩散模型之前首先转换为其潜在表示。在类条件ImageNet 256x256上,U-ViT获得了最先进的FID分数2.29,优于所有先前的扩散模型。
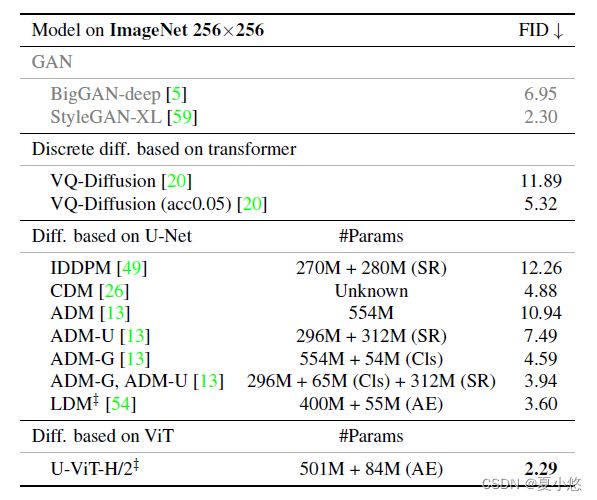
可以,这个指标目前是
SOTA。
下表进一步表明,在使用相同采样器,不同采样步数下,U-ViT优于LDM。

需要注意的是,U-ViT也优于VQ-Diffusion,后者是采用transformer作为主干的离散扩散模型。作者还尝试用具有相似参数和计算成本的U-Net替换U-ViT,其中U-ViT仍然优于U-Net(详见附录E)。在类条件ImageNet 512x512上,U-ViT优于直接对图像像素建模的ADM-G。在下图中,作者在ImageNet 256x256和ImageNet 512x512上提供了精选样本,在其他数据集上提供了随机样本,这些样本具有良好的质量和清晰的语义。在附录F中提供了更多的生成样本,包括类条件样本和随机样本。

在3.1节中,已经展示了长跳跃连接在小规模数据集(CIFAR10)上的重要性。下图进一步显示了它对于像ImageNet这样的大规模数据集也是至关重要的:
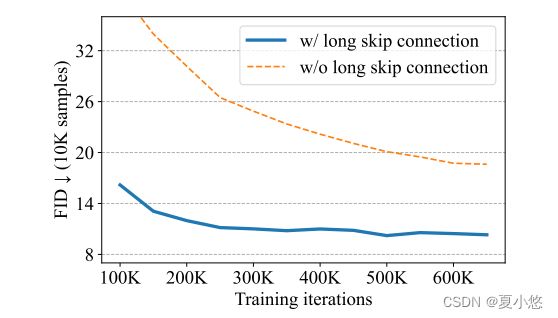
在附录C中,作者给出了其他指标的结果(sFID,inception score,precision和recall)以及在ImageNet上使用更多U-ViT配置的计算成本(GFLOPs)。作者指出,他们的的U-ViT在其他指标上仍然可以与最先进的扩散模型相媲美,同时具有可比较的GFLOPs(如果不是更小的话)。
5.3. Text-to-Image Generation on MS-COCO
作者在标准基准数据集MS-COCO上评估了U-ViT的文本到图像生成。在图像的潜在空间中训练了U-ViT,详见5.1节,此外,作者还训练了另一个潜在扩散模型,该模型使用了与U-ViT-S模型大小相当的U-Net,其他部分保持不变,其超参数和训练细节见附录B。作者使用FID分数来衡量图像质量。与之前的文献一致,从MS-COCO验证集中随机抽取30K个提示语(prompts),并在这些提示上生成样本来计算FID。
如下表所示,在生成模型的训练过程中,U-ViT-S在不访问大型外部数据集的情况下,已经达到了最先进方法的FID。通过进一步将层数从13层增加到17层,U-ViT-S (Deep)甚至可以达到5.48的更好FID。

下图显示了使用相同的随机种子生成的U-Net和U-ViT的样本,以便进行公平的比较。作者发现U-ViT生成了更多高质量的样本,同时语义与文本的匹配更好。例如,给定文本"a baseball player swinging a bat at a ball",U-Net既不生成球棒也不生成球。相比之下,U-ViT-S生成的球参数更少,U-ViT-S (Deep)进一步生成了球棒。作者猜测这是因为文本和图像在U-ViT的每一层都相互作用,这比只在交叉注意层相互作用的U-Net更频繁。作者在附录F中提供了更多的样例。
6. Conclusion
这项工作提出了U-ViT,一个简单和通用的基于ViT的架构,用于图像生成与扩散模型。U-ViT处理所有输入,包括时间,条件和噪声图像补丁作为标记,并在浅层和深层之间使用长跳跃连接。作者在包括无条件和类别条件图像生成以及文本到图像生成在内的任务中评估U-ViT。实验表明,U-ViT与类似大小的基于CNN的U-Net相比,即使不是优于U-Net,也是相当的。这些结果表明,对于基于扩散的图像建模,长跳跃连接是至关重要的,而基于CNN的U-Net中的上下采样算子并不总是必需的。作者相信,U-ViT可以为未来扩散模型的骨干研究提供简洁见解,有利于大规模跨模态数据集的生成建模。