neo4j查询语言Cypher详解(四)--索引
索引维护
索引类型:
- Range index.
- Lookup index.
- Text index.
- Point index.
- Full-text index.
Cypher允许在给定标签或关系类型的所有节点或关系的一个或多个属性上创建范围索引:
为任何给定的标签或关系类型在单个属性上创建的索引称为单属性索引。为任何给定标签或关系类型在多个属性上创建的索引称为复合索引。
复合索引和单属性索引在使用模式上的差异将在复合索引限制中描述。
此外,文本索引和点索引是一种单属性索引,它们的限制是只能分别识别字符串和点值的属性。具有索引标签或关系类型的节点或关系(其中索引属性为另一个值类型)不包括在索引中。
以下是索引的真实情况:
最佳实践是在创建索引时为其指定一个名称。如果索引没有显式命名,它将获得一个自动生成的名称。
索引名在索引和约束中必须是唯一的。
创建索引
创建索引是通过CREATE…INDEX…命令。如果create命令中没有指定索引类型,则创建一个范围索引。
创建索引需要
CREATE index权限。新的索引不是立即可用的,而是在后台创建的。
范围索引
语法
CREATE [RANGE] INDEX [index_name] [IF NOT EXISTS]
FOR (n:LabelName) //节点
ON (n.propertyName_1[,
n.propertyName_2,
...
n.propertyName_n]
)
CREATE [RANGE] INDEX [index_name] [IF NOT EXISTS]
FOR ()-"["r:TYPE_NAME"]"-() //关系
ON (r.propertyName_1[,
r.propertyName_2,
...
r.propertyName_n])
示例
CREATE INDEX node_range_index_name FOR (n:Person) ON (n.surname) //单属性索引
CREATE INDEX rel_range_index_name FOR ()-[r:KNOWS]-() ON (r.since)
CREATE INDEX composite_range_node_index_name FOR (n:Person) ON (n.age, n.country) //复合索引
CREATE INDEX composite_range_rel_index_name FOR ()-[r:PURCHASED]-() ON (r.date, r.amount)
text 索引
语法
CREATE TEXT INDEX [index_name] [IF NOT EXISTS]
FOR (n:LabelName)
ON (n.propertyName)
[OPTIONS "{" option: value[, ...] "}"]
CREATE TEXT INDEX [index_name] [IF NOT EXISTS]
FOR ()-"["r:TYPE_NAME"]"-()
ON (r.propertyName)
[OPTIONS "{" option: value[, ...] "}"]
仅支持字符串类型,不支持多属性。
示例
CREATE TEXT INDEX text_index_with_indexprovider FOR ()-[r:TYPE]-() ON (r.prop1)
OPTIONS {indexProvider: 'text-2.0'}
lookup 索引
语法
CREATE LOOKUP INDEX [index_name] [IF NOT EXISTS]
FOR (n)
ON EACH labels(n)
CREATE LOOKUP INDEX [index_name] [IF NOT EXISTS]
FOR ()-"["r"]"-()
ON [EACH] type(r)
一次只能存在一个节点标签查找索引。一次只能存在一个关系类型查找索引。
示例
CREATE LOOKUP INDEX node_label_lookup_index FOR (n) ON EACH labels(n)
CREATE LOOKUP INDEX rel_type_lookup_index FOR ()-[r]-() ON EACH type(r)
查看索引
SHOW [ALL \| FULLTEXT \| LOOKUP \| POINT \| RANGE \| TEXT] INDEX[ES]
[YIELD { * \| field[, ...] } [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]
[WHERE expression]
[RETURN field[, ...] [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]
删除索引
DROP INDEX index_name [IF EXISTS]
复合索引限制
与单属性范围索引一样,复合范围索引支持所有谓词:
-
相等性检查:
n.prop = value -
列表成员检查:
n.prop IN LIST -
存在检查:
n.prop IS NOT NULL -
范围搜索:
n.prop > value -
前缀搜索:
STARTS WITH
但是,可以将谓词规划为存在性检查和过滤器。对于大多数谓词,可以通过遵循以下限制来避免这种情况:
- 如果存在相等性检查和列表成员关系检查谓词,则需要针对索引定义的第一个属性。
- 最多可以有一个范围搜索或前缀搜索谓词。
- 存在性检查谓词可以有任意数量。
- 范围搜索、前缀搜索或存在性检查谓词之后的任何谓词都必须是存在性检查谓词。
索引使用
调优任务会根据查询的情况调用不同的索引。因此,对索引如何运作有一个基本的了解是很重要的。节点索引和关系索引的操作方式相同。因此,节点索引和关系索引在本节中可以互换使用。
索引类型和谓词兼容性
Neo4j中有不同类型的索引,但它们并不都与相同的属性谓词兼容。索引通常用于组合标签谓词和属性谓词的MATCH和OPTIONAL MATCH子句。因此,了解不同的索引可以解决什么样的谓词是很重要的。
BTREE
BTREE索引支持所有类型的谓词:
| Predicate | Syntax |
|---|---|
| equality check | n.prop = value |
| list membership check | n.prop IN list |
| existence check | n.prop IS NOT NULL |
| range search | n.prop > value |
| prefix search | STARTS WITH |
| suffix search | ENDS WITH |
| substring search | CONTAINS |
TEXT
TEXT索引只适用于在字符串上操作的谓词。这意味着只有当已知谓词对所有非字符串值的计算结果为null时,才使用TEXT索引。仅对字符串操作的谓词总是可以通过TEXT索引解决:
STARTS WITHENDS WITHCONTAINS
其他谓词仅在已知属性是与字符串进行比较时使用:
n.prop = "string"n.prop IN ["a", "b", "c"]n.prop > "string"
索引选择
当多个索引可用并且能够匹配一个谓词时,将定义一个顺序来决定使用哪个索引。它的定义如下:
-
对于
CONTAINS和ENDS WITH,TEXT索引优先于BTREE索引。 -
在所有其他情况下,
BTREE索引优先于TEXT索引。
更多索引示例见:index
Profile查询
基础profile
PROFILE
MATCH (p {name: 'Tom Hanks'})
RETURN p
+--------------------------------------------------------------------------------------------------------+
| Plan | Statement | Version | Planner | Runtime | Time | DbHits | Rows | Memory (Bytes) |
+--------------------------------------------------------------------------------------------------------+
| "PROFILE" | "READ_ONLY" | "CYPHER 4.3" | "COST" | "PIPELINED" | 26 | 406 | 1 | 136 |
+--------------------------------------------------------------------------------------------------------+
+-----------------------+------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| Operator | Details | Estimated Rows | Rows | DB Hits | Memory (Bytes) | Page Cache Hits/Misses | Time (ms) | Other |
+-----------------------+------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +ProduceResults@neo4j | p | 8 | 1 | 3 | | | | Fused in Pipeline 0 |
| | +------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +Filter@neo4j | p.name = $autostring_0 | 8 | 1 | 239 | | | | Fused in Pipeline 0 |
| | +------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +AllNodesScan@neo4j | p | 163 | 163 | 164 | 72 | 4/0 | 1.705 | Fused in Pipeline 0 |
+-----------------------+------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
1 row
在阅读执行计划时要记住的第一件事是,您需要从下往上阅读。
按照这种思路,从最后一行开始,您注意到的第一件事是,如果数据库中只有一个节点的名称属性为“Tom Hanks”,那么Rows列中的值似乎很高。如果您查看Operator列,您将看到AllNodesScan已被使用,这意味着查询规划器扫描了数据库中的所有节点。
Filter操作符,它将检查AllNodesScan通过的每个节点的name属性。无论何时查找节点,都应该指定一个标签,以帮助查询规划器缩小搜索空间。
PROFILE
MATCH (p:Person {name: 'Tom Hanks'}) //增加了一个节点 Lable
RETURN p
+--------------------------------------------------------------------------------------------------------+
| Plan | Statement | Version | Planner | Runtime | Time | DbHits | Rows | Memory (Bytes) |
+--------------------------------------------------------------------------------------------------------+
| "PROFILE" | "READ_ONLY" | "CYPHER 4.3" | "COST" | "PIPELINED" | 33 | 379 | 1 | 136 |
+--------------------------------------------------------------------------------------------------------+
+------------------------+------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| Operator | Details | Estimated Rows | Rows | DB Hits | Memory (Bytes) | Page Cache Hits/Misses | Time (ms) | Other |
+------------------------+------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +ProduceResults@neo4j | p | 6 | 1 | 3 | | | | Fused in Pipeline 0 |
| | +------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +Filter@neo4j | p.name = $autostring_0 | 6 | 1 | 250 | | | | Fused in Pipeline 0 |
| | +------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +NodeByLabelScan@neo4j | p:Person | 125 | 125 | 126 | 72 | 4/0 | 0.901 | Fused in Pipeline 0 |
+------------------------+------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
1 row
最后一行的Rows值减少了,这样就不用像以前那样扫描一些节点了。NodeByLabelScan操作符表明,首先对数据库中的所有Person节点进行线性扫描,从而实现了这一点。在Person标签的name属性上创建一个索引,会看到更好的性能:
CREATE INDEX FOR (p:Person)
ON (p.name)
+-----------------------+-------------------------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| Operator | Details | Estimated Rows | Rows | DB Hits | Memory (Bytes) | Page Cache Hits/Misses | Time (ms) | Other |
+-----------------------+-------------------------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +ProduceResults@neo4j | p | 1 | 1 | 3 | | | | Fused in Pipeline 0 |
| | +-------------------------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
| +NodeIndexSeek@neo4j | p:Person(name) WHERE name = $autostring_0 | 1 | 1 | 2 | 72 | 2/1 | 0.494 | Fused in Pipeline 0 |
+-----------------------+-------------------------------------------+----------------+------+---------+----------------+------------------------+-----------+---------------------+
1 row
执行计划
执行查询的任务被分解为操作符,每个操作符实现一个特定的工作。这些操作符被组合成一个树形结构,称为执行计划。执行计划中的每个操作符都表示为树中的一个节点。每个运算符以零或多行作为输入,并产生零或多行作为输出。这意味着一个操作符的输出将成为下一个操作符的输入。连接树中的两个分支的操作符将来自两个传入流的输入合并并产生单个输出。
执行计划的评估从树的叶节点开始。叶节点没有输入行,通常包含扫描和查找等操作符。这些操作符直接从存储引擎获取数据,从而导致数据库命中。然后,叶子节点产生的任何行都被管道输送到它们的父节点,而父节点又将它们的输出行管道输送到它们的父节点,以此类推,一直到根节点。根节点生成查询的最终结果。
一般来说,查询求值是惰性的:大多数操作符一旦产生输出行,就将它们的输出行管道到它们的父操作符。这意味着在父操作符开始使用子操作符生成的输入行之前,子操作符可能不会完全耗尽。
但是,有些操作符(例如用于聚合和排序的操作符)需要在生成输出之前聚合它们的所有行。这些操作符需要在将任何行作为输入发送给父行之前完整地完成执行。这些操作符被称为 eager 操作符,并在执行计划操作符中这样表示。eager可能导致高内存使用量,因此可能是导致查询性能问题的原因。
每个操作符都有统计信息:
Rows:运算符产生的行数。这只有在对查询进行了概要分析时才可用。EstimatedRows:操作符预计产生的行数的估计值DbHits:Page Cache Hits,Page Cache Misses,Page Cache Hit Ratio:页面缓存命中,页面缓存未命中,页面缓存命中率。Time:以毫秒为单位的执行给定操作符所花费的时间
为了为查询生成一个有效的计划,Cypher查询规划器需要关于Neo4j数据库的信息。这些信息包括可用的索引和约束,以及数据库维护的各种统计信息。Cypher查询规划器使用这些信息来确定哪些访问模式将产生最佳的执行计划。
Neo4j维护的统计信息如下:
-
具有某个标签的节点数。
-
按类型划分的关系数量。
-
每个索引的选择性。
-
按类型划分的关系数量,以具有特定标签的节点结束或开始。
有关如何保持统计信息的最新信息,以及管理查询重新规划和缓存的配置选项,参考: Statistics and execution plans
查询调优描述如何调优Cypher查询。参考:Profile a query,Planner hints and the USING keyword
Database hits
每个操作符将向存储引擎发送请求,以执行检索或更新数据等工作。DBHits是该存储引擎工作的抽象单元。
触发一个或多个DBHits的操作:
- 创建操作
- 删除操作
- 更新操作
- 节点操作
- 关系操作
- 通用操作
- Schema 操作
- Call a procedure.
- Call a user-defined function.
更多细节见:DBHits
执行计划操作符
在大多数情况下,叶子操作符定位执行查询所需的起始节点和关系。更新操作符用于更新图的查询。eager操作符在将它们传递给下一个操作符之前,先累积它们的所有行。
All Nodes Scan
AllNodesScan操作符从节点存储中读取所有节点。性能会有严重问题
DirectedRelationshipIndexScan
DirectedRelationshipIndexScan操作符检查存储在索引中的所有值,返回具有特定关系类型和指定属性的所有关系及其开始和结束节点。
DirectedRelationshipIndexSeek
根据Whre条件 Seek 关系索引。
DirectedRelationshipByIdSeek
通过elementId查找关系
DirectedRelationshipIndexContainsScan
使用CONTAINS 的索引扫描,比 DirectedRelationshipIndexSeek 慢,但是比DirectedRelationshipIndexScan 快。
DirectedRelationshipIndexEndsWithScan
使用Ends With的索引扫描。比 DirectedRelationshipIndexSeek 慢,但是比NodeByLabelScan 快
DirectedRelationshipIndexSeekByRange
使用 STARTS WITH,> ,< 等的语句
UndirectedRelationshipIndexScan
UndirectedRelationshipIndexScan操作符检查存储在索引中的所有值,返回具有特定关系类型和指定属性的所有关系及其开始和结束节点。 检查的是没有方向的关系。
UndirectedRelationshipIndexSeek
根据Whre条件 Seek 关系索引。
UndirectedRelationshipByIdSeek
UndirectedRelationshipIndexContainsScan
UndirectedRelationshipIndexEndsWithScan
更多操作符细节见:operators
Profile
当想通过查看查询的执行计划来分析查询时,有两个选项可供选择:
EXPLAIN:如果想查看执行计划,但不想运行语句,可以在Cypher语句前加上EXPLAIN。该语句将始终返回空结果,并且不对数据库进行任何更改。PROFILE:如果希望运行语句并查看哪些操作符执行了大部分工作,使用PROFILE。这将运行语句并跟踪通过每个操作符的行数,以及每个操作符需要与存储层交互多少行以检索必要的数据。分析查询会使用更多的资源。
索引执行计划示例
通过属性查找节点
节点具有Label:BO,test_01_01_01_03 属性:id。
仅在Label BO 上创建了索引,Label test_01_01_01_03未创建索引
CREATE INDEX idx_bo_id IF NOT EXISTS
FOR (n:BO)
ON (n.id)
;
1、没有索引
EXPLAIN
Match(n:`test_01_01_01_03` {id:'000153b1940fcfae3417a66001368df5'})
return n ;
PROFILE
Match(n:`test_01_01_01_03` {id:'000153b1940fcfae3417a66001368df5'})
return n ;

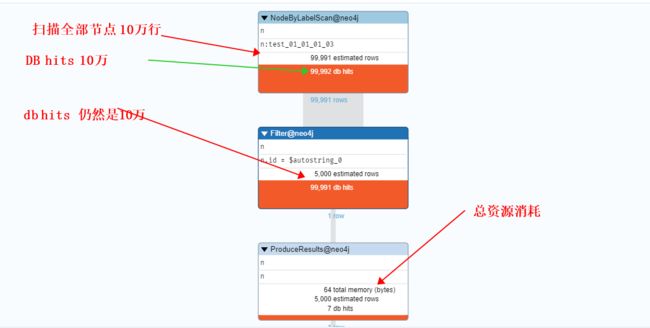
2、有索引
EXPLAIN
Match(n:BO {id:'000153b1940fcfae3417a66001368df5'})
return n ;
PROFILE
Match(n:BO {id:'000153b1940fcfae3417a66001368df5'})
return n ;

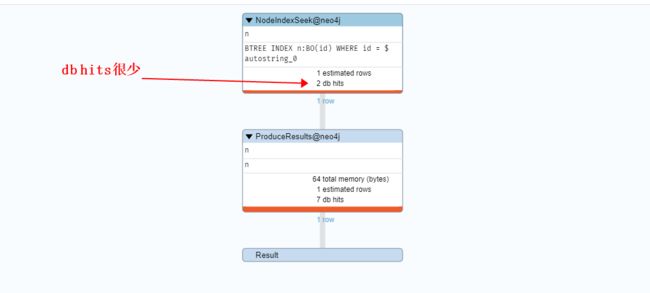
3、部分Label有索引
// Label 不分先后
EXPLAIN
Match(n:`test_01_01_01_03`:BO {id:'000153b1940fcfae3417a66001368df5'})
return n ;
PROFILE
Match(n:`test_01_01_01_03`:BO {id:'000153b1940fcfae3417a66001368df5'})
return n ;
EXPLAIN
Match(n:BO:`test_01_01_01_03` {id:'000153b1940fcfae3417a66001368df5'})
return n ;

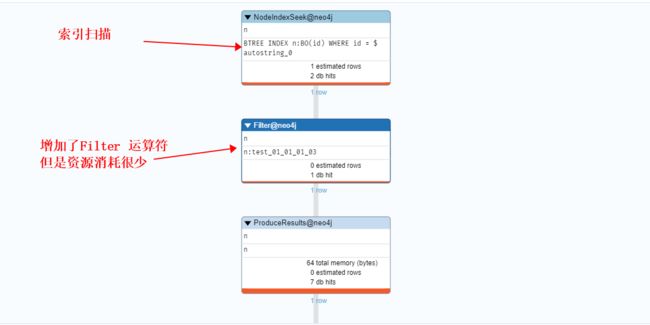
附录
参考
https://neo4j.com/docs/cypher-manual/current/indexes-for-search-performance/
https://neo4j.com/docs/cypher-manual/current/execution-plans/